

Principais conclusões
- As plataformas de redes sociais estão a vender dados de utilizadores a empresas de IA para formação de modelos generativos de IA, apesar das preocupações com a privacidade.
- Plataformas como Meta, Reddit, Tumblr e WordPress.com estão ativamente envolvidas nesses acordos de licenciamento de dados para treinamento em IA.
- Os usuários podem tomar algumas pequenas medidas para proteger seus dados, como ajustar as configurações de privacidade, cancelar o compartilhamento e ser cautelosos com o que publicam online.
Uma das maneiras mais recentes pelas quais as empresas de mídia social estão monetizando os dados dos usuários é por meio de acordos com empresas de IA. Mas há algo que os usuários comuns possam fazer para proteger seus dados e conteúdo?
Usar dados de mídia social para treinar modelos generativos de IA tem sido uma medida controversa – mas isso não parece impedir as empresas de mídia social de distribuir dados de usuários.
Meta já usa dados de mídia social para treinar os recursos generativos de IA anunciados no Meta Connect em 2023. Isso inclui Meta AI e recursos como a criação de adesivos gerados por IA no WhatsApp.
Como Mike Clark, Diretor de Gerenciamento de Produto da Meta, afirmou em um Postagem da Meta Redação:
“Postagens compartilhadas publicamente do Instagram e do Facebook – incluindo fotos e texto – faziam parte dos dados usados para treinar os modelos generativos de IA subjacentes aos recursos que anunciamos no Connect.”
Esta tendência não parece estar a abrandar em 2024. De acordo com Reuterso Reddit chegou a um acordo com o Google para disponibilizar o conteúdo da plataforma de mídia social para treinamento de modelos de IA.
Arquivamento S-1 do Reddit para seu IPO, protocolado em 22 de fevereiro de 2024, confirma que a empresa está explorando acordos de licenciamento. O arquivamento afirma:
“Os dados do Reddit são uma peça fundamental para a construção da tecnologia atual de IA e de muitos LLMs. Acreditamos que o enorme corpus de dados e conhecimento de conversação do Reddit continuará a desempenhar um papel no treinamento e na melhoria dos LLMs.”
Ele especifica que o Reddit está “nos estágios iniciais para permitir que terceiros licenciem o acesso para pesquisar, analisar e exibir dados históricos e em tempo real de nossa plataforma” para treinar LLMs.
E embora Meta e Reddit sejam alguns dos maiores nomes das redes sociais, eles não são as únicas plataformas envolvidas no uso de dados de redes sociais para treinar IA. De acordo com um relatório da 404 MediaTumblr e WordPress.com estão se preparando para vender dados de usuários para Midjourney e OpenAI.
Provavelmente, se você usa Facebook, Instagram, Reddit, Tumblr ou WordPress.com, seu conteúdo disponível publicamente já tenha sido usado no treinamento de LLMs.
Por exemplo, se você usar o Ferramenta de busca do Washington Post para ver quais sites foram incluídos no conjunto de dados C4 do Google, que foi usado como parte do treinamento de Bard, você verá que o Reddit.com é responsável por 7,9 milhões de tokens.

Tumblr.com é responsável por 1,6 milhão de tokens. Meu próprio pequeno site, que usa o WordPress.com, foi responsável por 14 mil tokens – portanto, pequenos blogs pessoais podem ter sido incluídos no conjunto de dados.
Com os acordos em curso entre empresas de IA e empresas de redes sociais, os acordos de licenciamento significarão que estes dados serão ativamente vendidos, em vez de apenas serem retirados da web.
Mas quando se trata de processamento futuro, o que você pode fazer a respeito? Meta introduziu um formulário para direitos do titular dos dados de IA generativa que permite que você se oponha ou restrinja o processamento de seus dados pessoais de terceiros para treinar os modelos de IA generativos da Meta.
Notavelmente, esta opção não permite que você se oponha ao processamento primário de seus dados pelo próprio Meta para treinar IA generativa. Além disso, quando enviei um ticket para me opor ao uso dos meus dados pessoais usando o formulário, o ticket de suporte exigia que eu provasse que minhas informações pessoais já estavam aparecendo nos resultados de IA generativos do Meta.
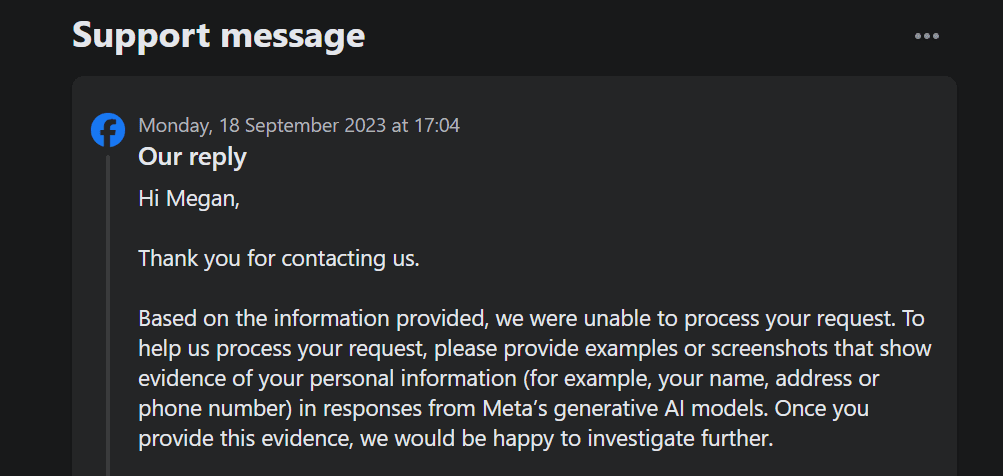
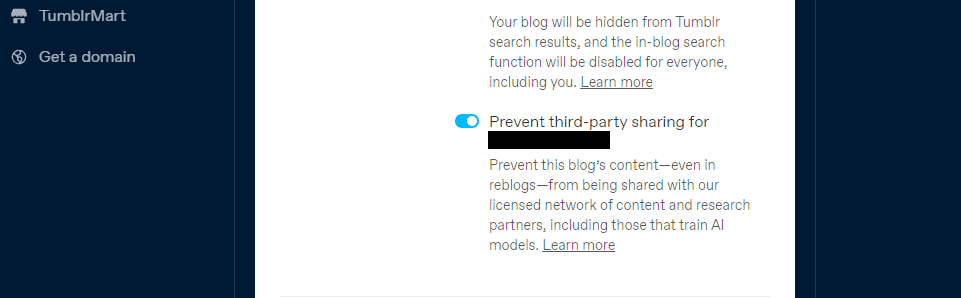
O Tumblr também introduziu uma opção para cancelar o compartilhamento do conteúdo de seus blogs públicos com terceiros usando as configurações do seu blog. Você pode encontrá-lo em suas configurações clicando em seu blog e rolando para baixo até as configurações de Visibilidade. Em seguida, escolha Impedir o compartilhamento de terceiros em seu blog.
Quando se trata de uma plataforma como o Instagram, você pode tentar mudar sua conta do Instagram para privada para evitar o uso de seus dados. Isto não garante que os seus dados não serão utilizados, mas como a recolha de dados para LLMs parece concentrar-se em dados públicos, pode ser uma potencial salvaguarda.
Você também pode tornar sua conta X (Twitter) privada, mas mais uma vez, isso é apenas uma proteção potencial e não garante que seus dados permaneçam privados.
A declaração conjunta por vários comissários nacionais de informação e especialistas em todo o mundo também sugeriu algumas ações para indivíduos que buscam minimizar o risco de privacidade da coleta de dados por empresas de IA. O conselho inclui:
- Leia os termos e a política de privacidade de um site para ver como ele compartilha suas informações pessoais.
- Limite as informações que você publica online, especialmente informações confidenciais.
- Gerencie suas configurações de privacidade.
- Pense a longo prazo nas informações que você compartilha online.
- Entre em contato com a empresa de mídia social ou site se achar que seus dados foram copiados indevidamente. Se você não estiver satisfeito com a resposta deles, registre uma reclamação junto à autoridade de proteção de dados relevante.
Você também pode excluir certas informações on-line se não se sentir confortável com o acesso de terceiros a elas, embora as informações publicamente disponíveis em seus perfis possam já ter sido coletadas.
Infelizmente, nós, como usuários regulares, não podemos fazer muito para proteger nossos dados das empresas de IA. O verdadeiro controlo sobre esta informação provavelmente só virá com a ajuda dos reguladores.