
Regressão e classificação são duas das áreas mais fundamentais e significativas do aprendizado de máquina.
Pode ser complicado distinguir entre algoritmos de regressão e classificação quando você está apenas entrando no aprendizado de máquina. Compreender como esses algoritmos funcionam e quando usá-los pode ser crucial para fazer previsões precisas e decisões eficazes.
Primeiro, vamos ver sobre aprendizado de máquina.
últimas postagens
O que é aprendizado de máquina?
O aprendizado de máquina é um método de ensinar computadores a aprender e tomar decisões sem serem explicitamente programados. Envolve o treinamento de um modelo de computador em um conjunto de dados, permitindo que o modelo faça previsões ou decisões com base em padrões e relacionamentos nos dados.
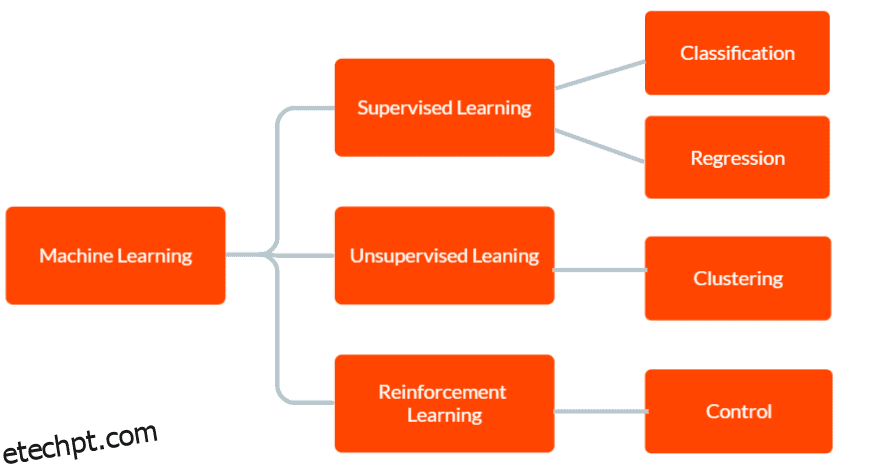
Existem três tipos principais de aprendizado de máquina: aprendizado supervisionado, aprendizado não supervisionado e aprendizado por reforço.
No aprendizado supervisionado, o modelo é fornecido com dados de treinamento rotulados, incluindo dados de entrada e a saída correta correspondente. O objetivo é que o modelo faça previsões sobre a saída de dados novos e não vistos com base nos padrões aprendidos com os dados de treinamento.
No aprendizado não supervisionado, o modelo não recebe nenhum dado de treinamento rotulado. Em vez disso, resta descobrir padrões e relacionamentos nos dados de forma independente. Isso pode ser usado para identificar grupos ou clusters nos dados ou para encontrar anomalias ou padrões incomuns.
E no Reinforcement Learning, um agente aprende a interagir com seu ambiente para maximizar uma recompensa. Envolve treinar um modelo para tomar decisões com base no feedback que recebe do ambiente.
O aprendizado de máquina é usado em várias aplicações, incluindo reconhecimento de imagem e fala, processamento de linguagem natural, detecção de fraudes e carros autônomos. Tem o potencial de automatizar muitas tarefas e melhorar a tomada de decisões em vários setores.
Este artigo se concentra principalmente nos conceitos de Classificação e Regressão, que estão sob o aprendizado de máquina supervisionado. Vamos começar!
Classificação em aprendizado de máquina

A classificação é uma técnica de aprendizado de máquina que envolve o treinamento de um modelo para atribuir um rótulo de classe a uma determinada entrada. É uma tarefa de aprendizado supervisionado, o que significa que o modelo é treinado em um conjunto de dados rotulado que inclui exemplos dos dados de entrada e os rótulos de classe correspondentes.
O modelo visa aprender a relação entre os dados de entrada e os rótulos de classe para prever o rótulo de classe para novas entradas não vistas.
Existem muitos algoritmos diferentes que podem ser usados para classificação, incluindo regressão logística, árvores de decisão e máquinas de vetores de suporte. A escolha do algoritmo dependerá das características dos dados e do desempenho desejado do modelo.
Alguns aplicativos de classificação comuns incluem detecção de spam, análise de sentimento e detecção de fraude. Em cada um desses casos, os dados de entrada podem incluir texto, valores numéricos ou uma combinação de ambos. Os rótulos de classe podem ser binários (por exemplo, spam ou não spam) ou multiclasse (por exemplo, sentimento positivo, neutro, negativo).
Por exemplo, considere um conjunto de dados de avaliações de clientes sobre um produto. Os dados de entrada podem ser o texto da revisão e o rótulo da classe pode ser uma classificação (por exemplo, positivo, neutro, negativo). O modelo seria treinado em um conjunto de dados de revisões rotuladas e, então, seria capaz de prever a classificação de uma nova revisão que não tinha visto antes.
Tipos de algoritmos de classificação de ML
Existem vários tipos de algoritmos de classificação em aprendizado de máquina:
Regressão Logística
Este é um modelo linear usado para classificação binária. É usado para prever a probabilidade de um determinado evento ocorrer. O objetivo da regressão logística é encontrar os melhores coeficientes (pesos) que minimizem o erro entre a probabilidade prevista e o resultado observado.
Isso é feito usando um algoritmo de otimização, como gradiente descendente, para ajustar os coeficientes até que o modelo se ajuste aos dados de treinamento da melhor maneira possível.
Árvores de decisão
Esses são modelos semelhantes a árvores que tomam decisões com base nos valores dos recursos. Eles podem ser usados para classificação binária e multiclasse. As árvores de decisão têm várias vantagens, incluindo sua simplicidade e interoperabilidade.
Eles também são rápidos para treinar e fazer previsões e podem lidar com dados numéricos e categóricos. No entanto, eles podem ser propensos a overfitting, especialmente se a árvore for profunda e tiver muitos galhos.
Classificação Aleatória da Floresta
A Random Forest Classification é um método de conjunto que combina as previsões de várias árvores de decisão para fazer uma previsão mais precisa e estável. É menos propenso a superajuste do que uma única árvore de decisão porque as previsões das árvores individuais são calculadas em média, o que reduz a variância no modelo.
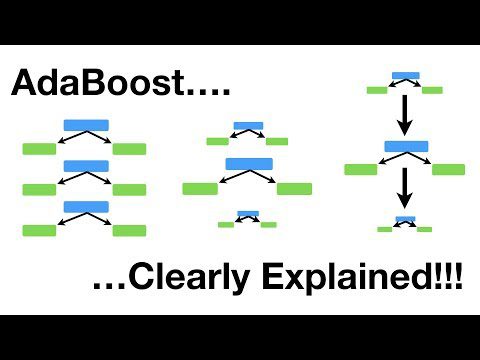
AdaBoostGenericName
Este é um algoritmo de reforço que altera de forma adaptativa o peso de exemplos mal classificados no conjunto de treinamento. É frequentemente usado para classificação binária.
Baías ingénuas
Naïve Bayes é baseado no teorema de Bayes, que é uma forma de atualizar a probabilidade de um evento com base em novas evidências. É um classificador probabilístico frequentemente usado para classificação de texto e filtragem de spam.
K-vizinho mais próximo
K-Nearest Neighbors (KNN) é usado para tarefas de classificação e regressão. É um método não paramétrico que classifica um ponto de dados com base na classe de seus vizinhos mais próximos. KNN tem várias vantagens, incluindo sua simplicidade e facilidade de implementação. Ele também pode lidar com dados numéricos e categóricos e não faz nenhuma suposição sobre a distribuição de dados subjacentes.
Aumento de Gradiente
Estes são conjuntos de aprendizes fracos que são treinados sequencialmente, com cada modelo tentando corrigir os erros do modelo anterior. Eles podem ser usados tanto para classificação quanto para regressão.
Regressão em aprendizado de máquina
No aprendizado de máquina, a regressão é um tipo de aprendizado supervisionado em que o objetivo é prever uma variável dependente ac com base em um ou mais recursos de entrada (também chamados de preditores ou variáveis independentes).
Algoritmos de regressão são usados para modelar a relação entre as entradas e a saída e fazer previsões com base nessa relação. A regressão pode ser usada para variáveis dependentes contínuas e categóricas.
Em geral, o objetivo da regressão é construir um modelo que possa prever com precisão a saída com base nos recursos de entrada e entender o relacionamento subjacente entre os recursos de entrada e a saída.
A análise de regressão é usada em vários campos, incluindo economia, finanças, marketing e psicologia, para entender e prever as relações entre diferentes variáveis. É uma ferramenta fundamental na análise de dados e aprendizado de máquina e é usada para fazer previsões, identificar tendências e entender os mecanismos subjacentes que impulsionam os dados.
Por exemplo, em um modelo de regressão linear simples, o objetivo pode ser prever o preço de uma casa com base em seu tamanho, localização e outros recursos. O tamanho da casa e sua localização seriam as variáveis independentes, e o preço da casa seria a variável dependente.
O modelo seria treinado com dados de entrada que incluem o tamanho e a localização de várias casas, junto com seus preços correspondentes. Depois que o modelo é treinado, ele pode ser usado para fazer previsões sobre o preço de uma casa, considerando seu tamanho e localização.
Tipos de algoritmos de regressão de ML
Os algoritmos de regressão estão disponíveis em várias formas, e o uso de cada algoritmo depende do número de parâmetros, como o tipo de valor do atributo, o padrão da linha de tendência e o número de variáveis independentes. Técnicas de regressão que são frequentemente usadas incluem:
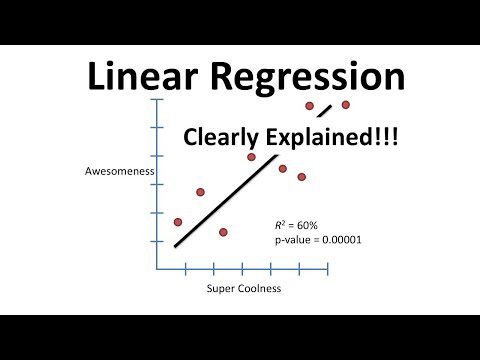
Regressão linear
Este modelo linear simples é usado para prever um valor contínuo com base em um conjunto de recursos. Ele é usado para modelar o relacionamento entre os recursos e a variável de destino ajustando uma linha aos dados.
regressão polinomial
Este é um modelo não linear usado para ajustar uma curva aos dados. É usado para modelar relacionamentos entre os recursos e a variável de destino quando o relacionamento não é linear. Baseia-se na ideia de adicionar termos de ordem superior ao modelo linear para capturar relações não lineares entre as variáveis dependentes e independentes.
Regressão Ridge
Este é um modelo linear que aborda o overfitting na regressão linear. É uma versão regularizada da regressão linear que adiciona um termo de penalidade à função de custo para reduzir a complexidade do modelo.
Regressão de vetor de suporte
Assim como os SVMs, o Support Vector Regression é um modelo linear que tenta ajustar os dados encontrando o hiperplano que maximiza a margem entre as variáveis dependentes e independentes.
No entanto, ao contrário dos SVMs, que são usados para classificação, o SVR é usado para tarefas de regressão, onde o objetivo é prever um valor contínuo em vez de um rótulo de classe.
Regressão de laço
Este é outro modelo linear regularizado usado para evitar o overfitting na regressão linear. Ele adiciona um termo de penalidade à função de custo com base no valor absoluto dos coeficientes.
Regressão Linear Bayesiana
A Regressão Linear Bayesiana é uma abordagem probabilística da regressão linear baseada no teorema de Bayes, que é uma forma de atualizar a probabilidade de um evento com base em novas evidências.
Este modelo de regressão visa estimar a distribuição posterior dos parâmetros do modelo dados os dados. Isso é feito definindo uma distribuição a priori sobre os parâmetros e, em seguida, usando o teorema de Bayes para atualizar a distribuição com base nos dados observados.
Regressão vs. Classificação
Regressão e classificação são dois tipos de aprendizado supervisionado, o que significa que são usados para prever uma saída com base em um conjunto de recursos de entrada. No entanto, existem algumas diferenças importantes entre os dois:
RegressãoClassificaçãoDefiniçãoUm tipo de aprendizado supervisionado que prevê um valor contínuoUm tipo de aprendizado supervisionado que prevê um valor categóricoTipo de saídaContínuoDiscretoMétricas de avaliaçãoErro quadrático médio (MSE), erro quadrático médio da raiz (RMSE)Precisão, precisão, recuperação, pontuação F1AlgoritmosRegressão linear, Lasso, Ridge, KNN, Árvore de decisãoRegressão logística, SVM, Naïve Bayes, KNN, Árvore de decisão Complexidade do modeloModelos menos complexosModelos mais complexosSuposiçõesRelação linear entre recursos e destinoSem suposições específicas sobre o relacionamento entre recursos e destinoDesequilíbrio de classeNão aplicávelPode ser um problemaOutliersPode afetar o desempenho do modeloNão costuma ser um problemaImportância do recursoRecursos são classificados por importânciaRecursos não são classificados por importânciaExemplos de aplicativosPrevisão de preços, temperaturas, quantidadesPrevisão de spam por e-mail, previsão de rotatividade de clientes
Recursos de aprendizagem
Pode ser um desafio escolher os melhores recursos online para entender os conceitos de aprendizado de máquina. Examinamos os cursos populares fornecidos por plataformas confiáveis para apresentar nossas recomendações para os melhores cursos de ML sobre regressão e classificação.
#1. Bootcamp de classificação de aprendizado de máquina em Python
Este é um curso oferecido na plataforma Udemy. Abrange uma variedade de algoritmos e técnicas de classificação, incluindo árvores de decisão e regressão logística, e oferece suporte a máquinas vetoriais.

Você também pode aprender sobre tópicos como overfitting, tradeoff de viés-variância e avaliação de modelo. O curso usa bibliotecas Python, como sci-kit-learn e pandas, para implementar e avaliar modelos de aprendizado de máquina. Portanto, é necessário conhecimento básico de python para começar este curso.
#2. Masterclass de regressão de aprendizado de máquina em Python
Neste curso da Udemy, o instrutor aborda os fundamentos e a teoria subjacente de vários algoritmos de regressão, incluindo regressão linear, regressão polinomial e técnicas de regressão Lasso e Ridge.
Ao final deste curso, você será capaz de implementar algoritmos de regressão e avaliar o desempenho de modelos de aprendizado de máquina treinados usando vários indicadores-chave de desempenho.
Empacotando
Os algoritmos de aprendizado de máquina podem ser muito úteis em muitos aplicativos e podem ajudar a automatizar e simplificar muitos processos. Os algoritmos de ML usam técnicas estatísticas para aprender padrões em dados e fazer previsões ou decisões com base nesses padrões.
Eles podem ser treinados em grandes quantidades de dados e podem ser usados para executar tarefas que seriam difíceis ou demoradas para os humanos fazerem manualmente.
Cada algoritmo de ML tem seus pontos fortes e fracos, e a escolha do algoritmo depende da natureza dos dados e dos requisitos da tarefa. É importante escolher o algoritmo apropriado ou combinação de algoritmos para o problema específico que você está tentando resolver.
É importante escolher o tipo certo de algoritmo para o seu problema, pois usar o tipo errado de algoritmo pode levar a um desempenho insatisfatório e a previsões imprecisas. Se você não tiver certeza de qual algoritmo usar, pode ser útil tentar os algoritmos de regressão e classificação e comparar seu desempenho em seu conjunto de dados.
Espero que você tenha achado este artigo útil para aprender Regressão vs. Classificação em Aprendizado de Máquina. Você também pode estar interessado em aprender sobre os principais modelos de aprendizado de máquina.