
Se você usa Linux há algum tempo, já conhece o grep — Global Regular Expression Print, uma ferramenta de processamento de texto que pode ser usada para pesquisar arquivos e diretórios. É muito útil nas mãos de um usuário avançado do Linux. No entanto, usá-lo sem regex pode limitar seus recursos.
Mas o que é Regex?
Regex são expressões regulares que você pode usar para melhorar a funcionalidade de pesquisa grep. Regex, por definição, é um padrão avançado de filtragem de saída. Com a prática, você pode usar o regex de forma eficaz, pois também pode usá-lo com outros comandos do Linux.
Em nosso tutorial, aprenderemos como usar Grep e Regex de forma eficaz.
últimas postagens
Pré-requisito
O uso do grep com regex requer um bom conhecimento do Linux. Se você é iniciante, confira nossos guias do Linux.
Você também precisa de acesso a um laptop ou computador executando o sistema operacional Linux. Você pode usar qualquer distribuição Linux de sua escolha. E, se você tiver uma máquina Windows, ainda poderá usar o Linux com WSL2. Confira nossa visão detalhada sobre isso aqui.
O acesso à linha de comando/terminal permite que você execute todos os comandos fornecidos em nosso tutorial grep/regex.
Além disso, você também precisa acessar um ou mais arquivos de texto necessários para executar os exemplos. Usei o ChatGPT para gerar uma parede de texto, dizendo para escrever sobre tecnologia. O prompt que usei é o seguinte.
“Gere 400 palavras sobre tecnologia. Deve incluir a maior parte da tecnologia. Além disso, certifique-se de repetir os nomes das tecnologias no texto.”
Assim que gerou o texto, copiei e colei e salvei no arquivo tech.txt, que usaremos ao longo do tutorial.
Por fim, um entendimento básico do comando grep é obrigatório. Você pode conferir 16 exemplos de comandos grep para atualizar seu conhecimento. Também apresentaremos brevemente o comando grep para você começar.
Sintaxe e exemplos do comando grep
A sintaxe do comando grep é simples.
$ grep -options [regex/pattern] [files]
Como você pode perceber, ele espera um padrão e a lista de arquivos que você deseja executar o comando.
Existem muitas opções grep disponíveis que modificam sua funcionalidade. Esses incluem:
- – i: ignorar casos
- -r: faz busca recursiva
- -w: realiza uma pesquisa para encontrar apenas palavras inteiras
- -v: exibe todas as linhas não correspondentes
- -n: exibe todos os números de linha correspondentes
- -l: imprime os nomes dos arquivos
- –color: saída de resultado colorido
- -c: mostra a contagem de correspondências para o padrão usado
#1. Pesquisar uma palavra inteira
Você precisará usar o argumento -w com grep para uma pesquisa de palavras inteiras. Ao usá-lo, você ignora quaisquer strings que correspondam ao padrão fornecido.
$ grep -w ‘tech\|5G’ tech.txt
Como você pode ver, o comando resulta em uma saída onde procura duas palavras, “5G” e “tech”, ao longo do texto. Em seguida, marca-os com a cor vermelha.
Aqui, o | o símbolo de pipe é escapado para que o grep não o processe como um metacaractere.
#2. Pesquisa que não diferencia maiúsculas de minúsculas
Para fazer uma pesquisa que não diferencia maiúsculas de minúsculas, use grep com o argumento -i.
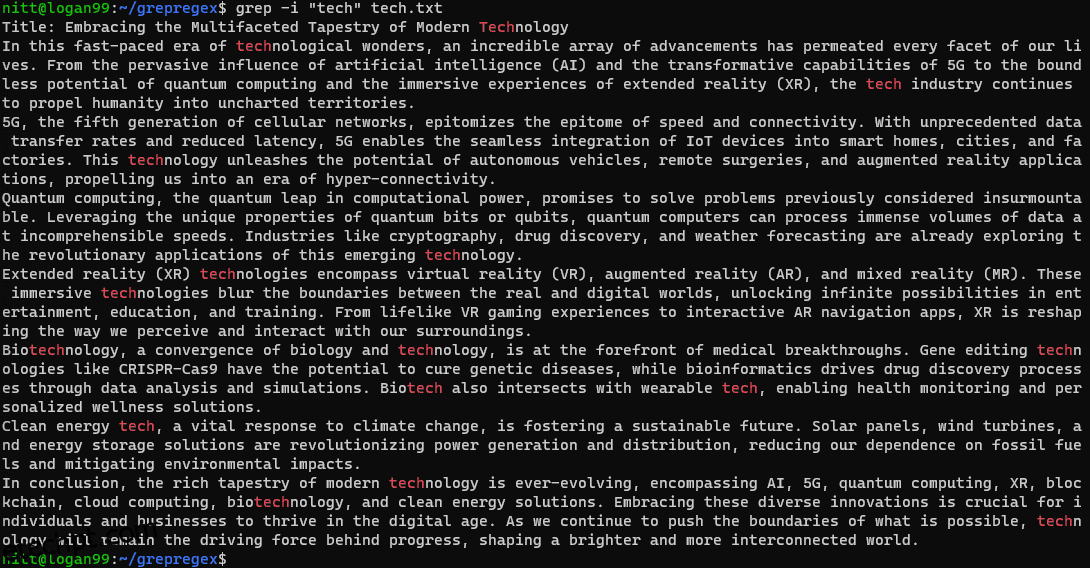
$ grep -i ‘tech’ tech.txt
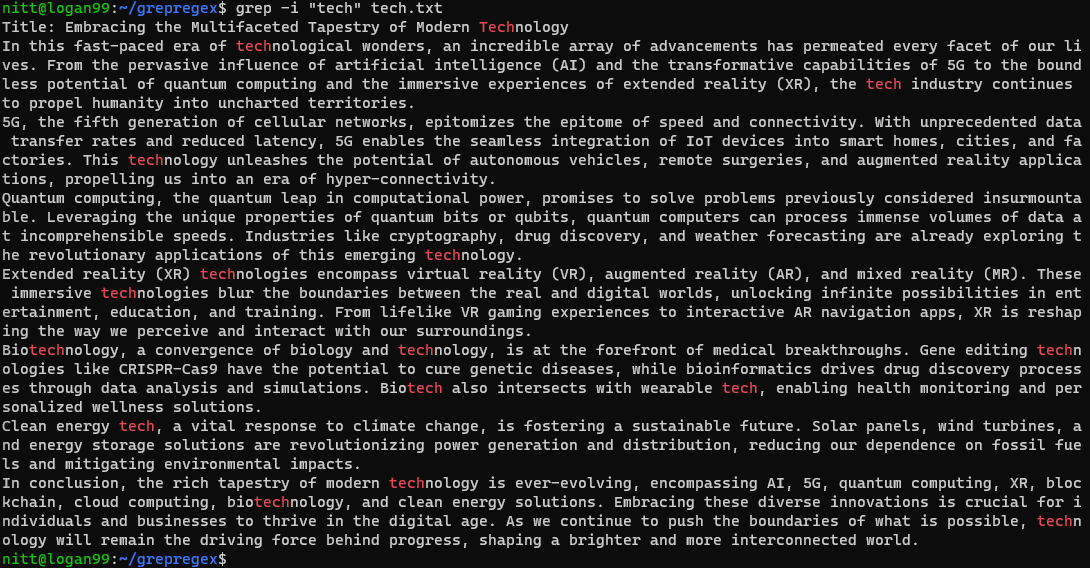
O comando procura por qualquer instância que não diferencie maiúsculas de minúsculas da string “tech”, seja uma palavra completa ou parte dela.
#3. Faça uma pesquisa de linha não correspondente
Para exibir todas as linhas que não contêm um determinado padrão, você precisará usar o argumento -v.
$ grep -v ‘tech’ tech.txt

A saída mostra todas as linhas que não contêm a palavra “tech”. Além disso, você verá linhas vazias também. Essas linhas são as linhas que estão depois de um parágrafo.
#4. Faça uma busca recursiva
Para fazer uma pesquisa recursiva, use o argumento -r com grep.
$ grep -R ‘error\|warning’ /var/log/*.log
#output /var/log/bootstrap.log:2023-01-03 21:40:18 URL:http://ftpmaster.internal/ubuntu/pool/main/libg/libgpg-error/libgpg-erro 0_1.43-3_amd64.deb [69684/69684] -> "/build/chroot//var/cache/apt/archives/partial/libgpg-error0_1.43-3_amd64.deb" [1] /var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 5 package 'dpkg': /var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 5 package 'dpkg': /var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 24 package 'dpkg': /var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 24 package 'dpkg': /var/log/bootstrap.log:dpkg: warning: ignoring pre-dependency problem!
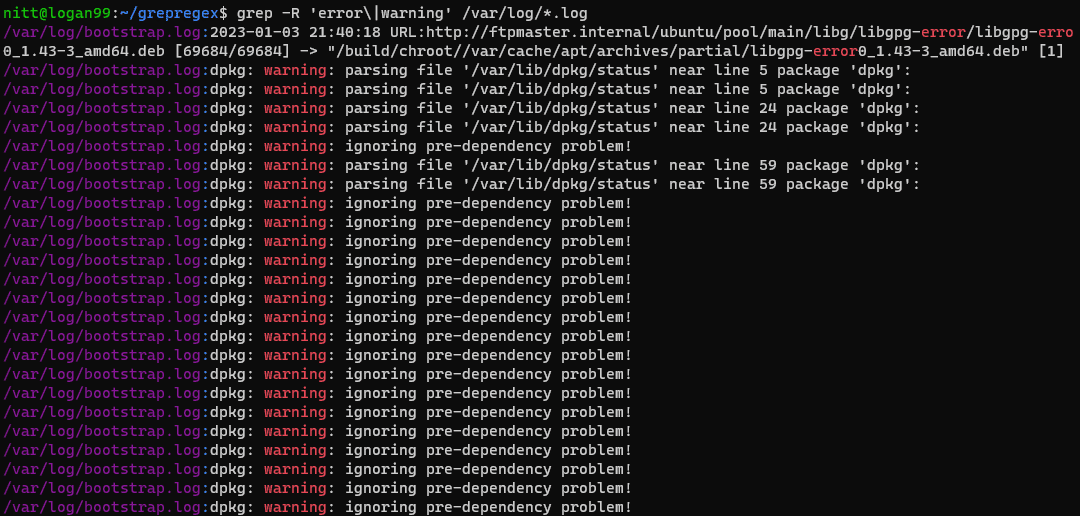
O comando grep procura recursivamente por duas palavras, “error” e “warning”, no diretório /var/log. Este é um comando útil para aprender sobre quaisquer avisos e erros nos arquivos de log.
Grep e Regex: o que é e exemplos
Como estamos trabalhando com regex, você precisa saber que regex oferece três opções de sintaxe. Esses incluem:
- Expressões Regulares Básicas (BRE)
- Expressões Regulares Estendidas (ERE)
- Expressões regulares compatíveis com Pearl (PCRE)
O comando grep usa BRE como opção padrão. Portanto, se você quiser usar outros modos regex, precisará mencioná-los. O comando grep também trata os metacaracteres como eles são. Portanto, se você usar metacaracteres como ?, +, ), precisará escapá-los com o comando de barra invertida (\).
A sintaxe do grep com regex é a seguinte.
$ grep [regex] [filenames]
Vamos ver grep e regex em ação com os exemplos abaixo.
#1. Correspondências de palavras literais
Para fazer uma correspondência de palavra literal, você precisará fornecer uma string como regex. Afinal, uma palavra também é um regex.
$ grep "technologies" tech.txt

Da mesma forma, você também pode usar correspondências literais para encontrar usuários atuais. Para isso, corra,
$ grep bash /etc/passwd
#output root:x:0:0:root:/root:/bin/bash nitt:x:1000:1000:,,,:/home/nitt:/bin/bash
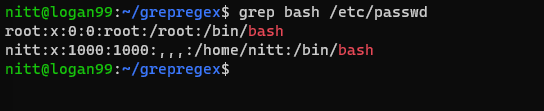
Isso exibe os usuários que podem acessar o bash.
#2. Correspondência de âncora
A correspondência de âncora é uma técnica útil para pesquisas avançadas usando caracteres especiais. No regex, existem diferentes caracteres âncora que você pode usar para representar posições específicas em um texto. Esses incluem:
- Símbolo de circunflexo ‘^’: O símbolo de circunflexo corresponde ao início da string ou linha de entrada e procura por uma string vazia.
- Símbolo do dólar ‘$’: O símbolo do dólar corresponde ao final da string ou linha de entrada e procura uma string vazia.
Os outros dois caracteres de correspondência de âncora incluem o limite de palavra ‘\ b’ e o limite de não palavra ‘\ B’.
- Limite de palavra ‘\ b’: Com \b, você pode afirmar a posição entre uma palavra e um caractere não-palavra. Em palavras simples, permite combinar palavras completas. Dessa forma, você pode evitar correspondências parciais. Você também pode usá-lo para substituir palavras ou contar ocorrências de palavras em uma string.
- \B limite de não-palavra: é o oposto do \b limite de palavra em regex, pois afirma uma posição que não está entre caracteres de duas palavras ou não-palavra.
Vamos ver exemplos para ter uma ideia clara.
$ grep ‘^From’ tech.txt

O uso do cursor requer inserir a palavra ou padrão no caso correto. Isso porque é sensível a maiúsculas e minúsculas. Portanto, se você executar o seguinte comando, ele não retornará nada.
$ grep ‘^from’ tech.txt
Da mesma forma, você pode usar o símbolo $ para encontrar a frase que corresponde a um determinado padrão, string ou palavra.
$ grep ‘technology.$' tech.txt

Você também pode combinar os símbolos ^ e $. Vejamos o exemplo abaixo.
$ grep “^From \| technology.$” tech.txt
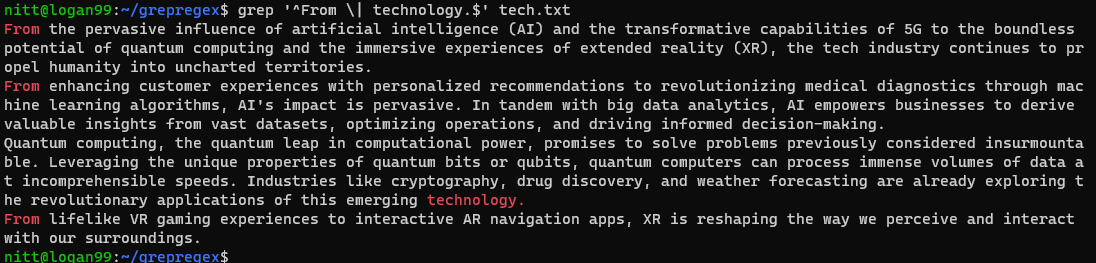
Como você pode ver, a saída contém frases que começam com “From” e terminam com “technology”.
#3. Agrupamento
Se você deseja pesquisar vários padrões de uma só vez, precisará usar o Agrupamento. Ele ajuda você a criar pequenos grupos de caracteres e padrões que você pode tratar como uma única unidade. Por exemplo, você pode criar um grupo (tech) que inclua o termo ‘t’, ‘e’,’ c’,’ h.’
Para ter uma ideia clara, vamos verificar um exemplo.
$ grep 'technol\(ogy\)\?' tech.txt

Com o agrupamento, você pode combinar padrões repetidos, capturar grupos e procurar alternativas.
Pesquisa alternativa com agrupamento
Vejamos um exemplo de uma pesquisa alternativa.
$ grep "\(tech\|technology\)" tech.txt
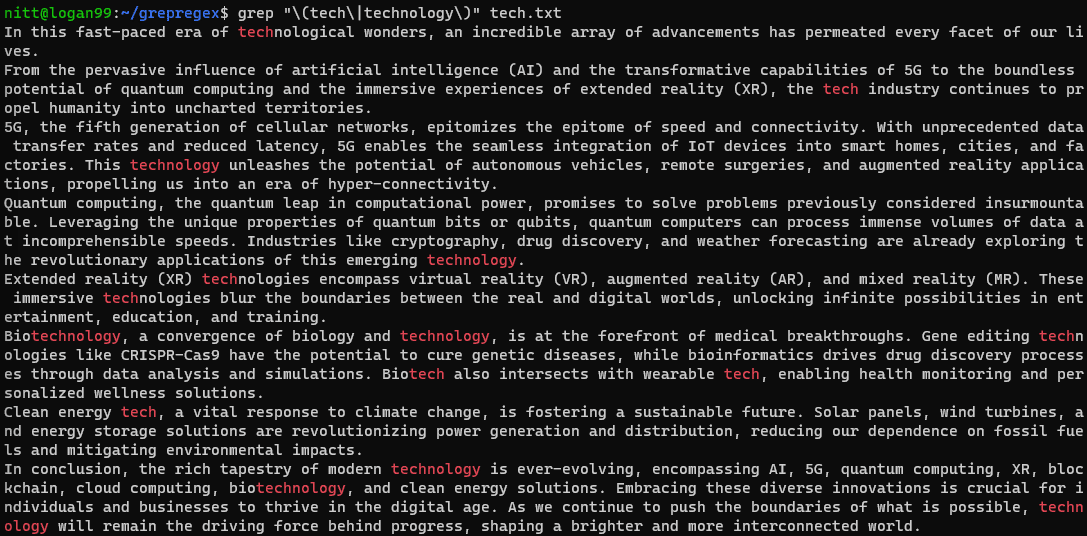
Se você deseja realizar uma pesquisa em uma string, precisará passá-la com o símbolo de barra vertical. Vejamos no exemplo abaixo.
$ echo “tech technological technologies technical” | grep "\(tech\|technology\)"
#output “tech technological technologies technical”

Grupos de captura, grupos de não captura e padrões repetidos
E os grupos de captura e não captura?
Você precisará criar um grupo no regex e passá-lo para a string ou um arquivo para capturar grupos.
$ echo 'tech655 tech655nical technologies655 tech655-oriented 655' | grep "\(tech\)\(655\)"
#output tech655 tech655nical technologies655 tech655-oriented 655

E, para grupos sem captura, você precisará usar o ?: entre parênteses.
Por último, temos padrões repetidos. Você precisará modificar o regex para verificar padrões repetidos.
$ echo ‘teach tech ttrial tttechno attest’ | grep '\(t\+\)'
#output ‘teach tech ttrial tttechno attest’
Aqui, o regex procura uma ou mais instâncias do caractere ‘t’.
#4. Classes de personagens
Com classes de caracteres, você pode escrever expressões regex facilmente. Essas classes de caracteres usam colchetes. Algumas das classes de personagens bem conhecidas incluem:
- [:digit:] – 0 a 9 dígitos
- [:alpha:] – caracteres alfabéticos
- [:alnum:] – caracteres alfanuméricos
- [:lower:] – letras minúsculas
- [:upper:] – letras maiúsculas
- [:xdigit:] – dígitos hexadecimais, incluindo 0-9, AF, af
- [:blank:] – caracteres em branco, como tabulação ou espaço
E assim por diante!
Vamos verificar alguns deles em ação.
$ grep [[:digit]] tech.txt

$ grep [[:alpha:]] tech.txt
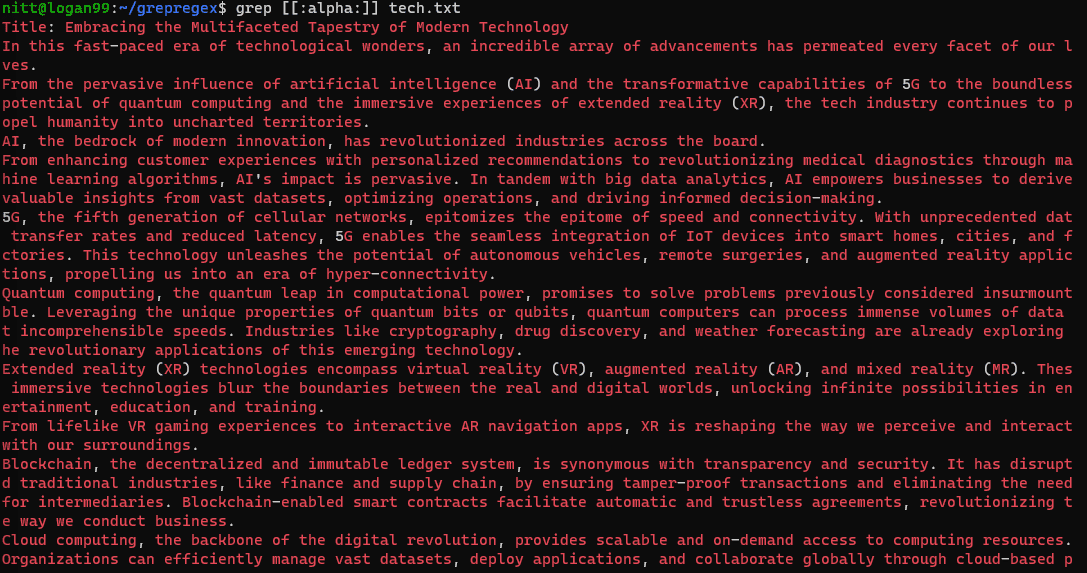
$ grep [[:xdigit:]] tech.txt
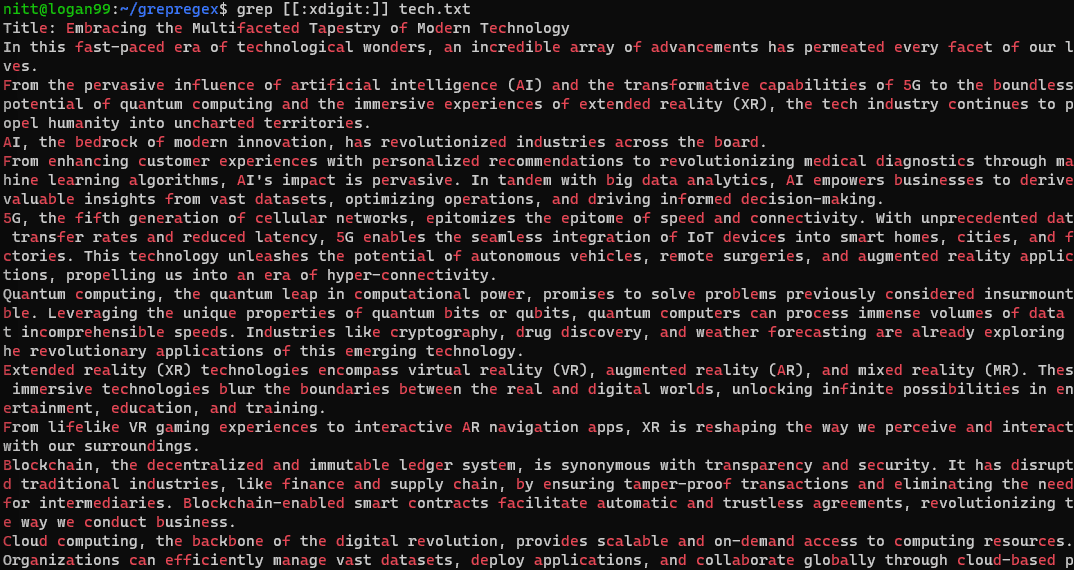
#5. Quantificadores
Quantificadores são metacaracteres e estão no centro do regex. Estes permitem que você combine aparências exatas. Vamos vê-los abaixo.
- * → Zero ou mais correspondências
- + → uma ou mais correspondências
- ? → Zero ou um corresponde
- {x} → x correspondências
- {x,} → x ou mais correspondências
- {x,z} → de x a z corresponde
- {, z} → até z correspondências
$ echo ‘teach tech ttrial tttechno attest’ | grep -E 't+'
#output ‘teach tech ttrial tttechno attest’
Aqui, ele procura as instâncias do caractere ‘t’ para uma ou mais correspondências. Aqui -E significa regex estendido (que discutiremos mais tarde).

#6. Regex estendido
Se você não gosta de adicionar caracteres de escape no padrão regex, deve usar regex estendido. Ele remove a necessidade de adicionar caracteres de escape. Para fazer isso, você precisará usar o sinalizador -E.
$ grep -E 'in+ovation' tech.txt

#7. Usando PCRE para fazer pesquisas complexas
PCRE (Perl Compatible Regular Expression) permite fazer muito mais do que escrever expressões básicas. Por exemplo, você pode escrever “\d” que denota [0-9].
Por exemplo, você pode usar o PCRE para pesquisar endereços de e-mail.
echo "Contact me at [email protected]" | grep -P "\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,}\b"
#output Contact me at [email protected]

Aqui, o PCRE garante que o padrão seja correspondido. Da mesma forma, você também pode usar um padrão PCRE para verificar os padrões de data.
$ echo "The Sparkain site launched on 2023-07-29" | grep -P "\b\d{4}-\d{2}-\d{2}\b"
#output The Sparkain site launched on 2023-07-29

O comando localiza a data no formato AAAA-MM-DD. Você também pode modificá-lo para corresponder a outro formato de data.
#8. Alternância
Se desejar correspondências alternativas, você pode usar os caracteres pipe de escape (\|).
$ grep -L ‘warning\|error’ /var/log/*.log
#output /var/log/alternatives.log /var/log/bootstrap.log /var/log/dpkg.log /var/log/fontconfig.log /var/log/ubuntu-advantage.log /var/log/upgrade-policy-changed.log
A saída lista os nomes de arquivo contendo “aviso” ou “erro”.
Palavras Finais
Isso nos leva ao final do nosso guia grep e regex. Você pode usar grep com regex extensivamente para refinar as pesquisas. Com o uso correto, você pode economizar muito tempo e ajudar a automatizar muitas tarefas, especialmente se você estiver usando-os para escrever scripts ou usar o regex na realização de pesquisas no texto.
A seguir, confira as perguntas e respostas mais frequentes sobre entrevistas sobre o Linux.