

Você está pronto para aprender engenharia de recursos para aprendizado de máquina e ciência de dados? Você está no lugar certo!
A engenharia de recursos é uma habilidade crítica para extrair insights valiosos dos dados e, neste guia rápido, vou dividi-los em partes simples e digeríveis. Então, vamos mergulhar de cabeça e começar sua jornada para dominar a extração de recursos!
últimas postagens
O que é engenharia de recursos?

Ao criar um modelo de aprendizado de máquina relacionado a um problema comercial ou experimental, você fornece dados de aprendizado em colunas e linhas. No domínio da ciência de dados e do desenvolvimento de ML, as colunas são conhecidas como atributos ou variáveis.
Dados granulares ou linhas abaixo dessas colunas são conhecidos como observações ou instâncias. As colunas ou atributos são os recursos de um conjunto de dados brutos.
Esses recursos brutos não são suficientes ou ideais para treinar um modelo de ML. Para reduzir o ruído dos metadados coletados e maximizar sinais exclusivos dos recursos, você precisa transformar ou converter colunas de metadados em recursos funcionais por meio da engenharia de recursos.
Exemplo 1: Modelagem Financeira
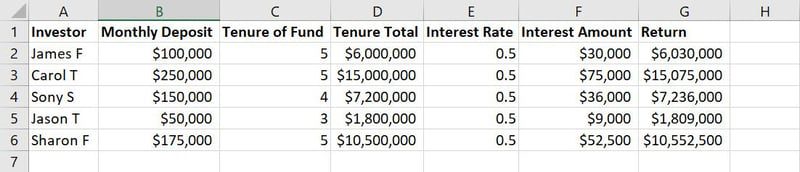 Dados brutos para treinamento de modelo de ML
Dados brutos para treinamento de modelo de ML
Por exemplo, na imagem acima de um conjunto de dados de exemplo, as colunas de A a G são recursos. Valores ou sequências de texto em cada coluna ao longo das linhas, como nomes, valor do depósito, anos de depósito, taxas de juros, etc., são observações.
Na modelagem de ML, você deve excluir, adicionar, combinar ou transformar dados para criar recursos significativos e reduzir o tamanho do banco de dados geral de treinamento do modelo. Isso é engenharia de recursos.
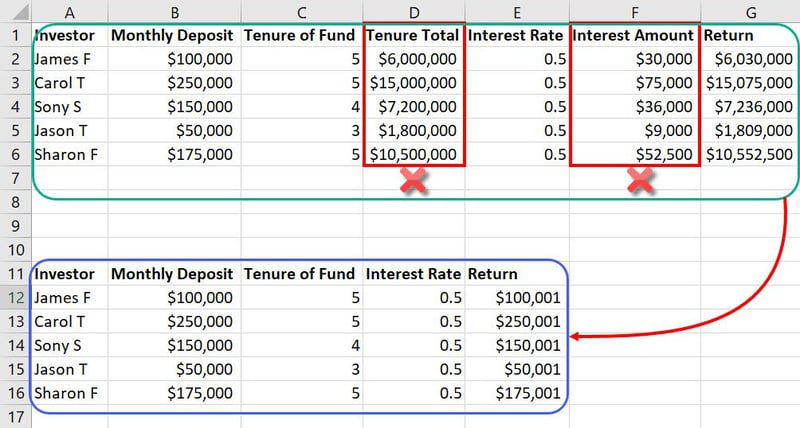 Exemplo de engenharia de recursos
Exemplo de engenharia de recursos
No mesmo conjunto de dados mencionado anteriormente, recursos como Posse Total e Valor de Juros são entradas desnecessárias. Isso simplesmente ocupará mais espaço e confundirá o modelo de ML. Portanto, você pode reduzir dois recursos de um total de sete recursos.
Como os bancos de dados nos modelos de ML contêm milhares de colunas e milhões de linhas, a redução de dois recursos impacta muito o projeto.
Exemplo 2: Criador de lista de reprodução de música AI
Às vezes, você pode criar um recurso totalmente novo a partir de vários recursos existentes. Suponha que você esteja criando um modelo de IA que criará automaticamente uma playlist de músicas e músicas de acordo com evento, gosto, modo, etc.
Agora, você coletou dados sobre canções e músicas de diversas fontes e criou o seguinte banco de dados:
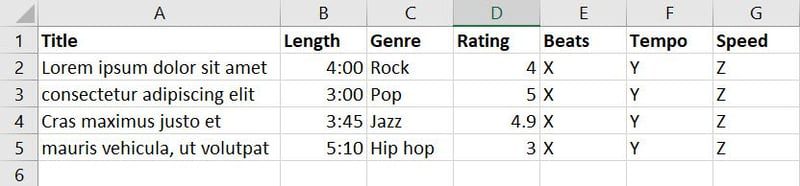
Existem sete recursos no banco de dados acima. No entanto, como seu objetivo é treinar o modelo de ML para decidir qual música é adequada para qual evento, você pode agrupar recursos como gênero, classificação, batidas, andamento e velocidade em um novo recurso chamado Aplicabilidade.
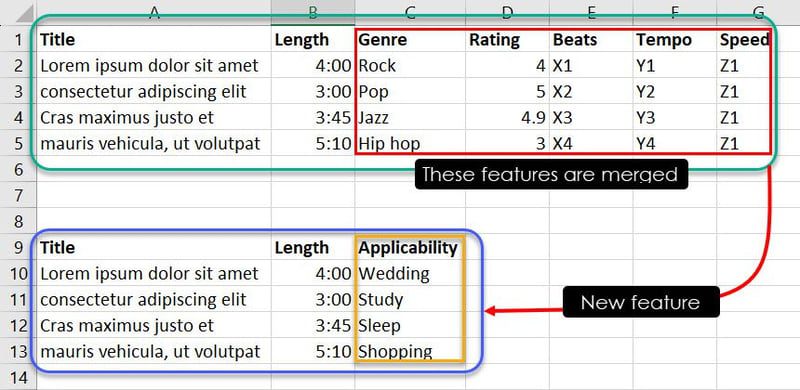
Agora, seja por meio de experiência ou identificação de padrões, você pode combinar certas instâncias de recursos para determinar qual música é adequada para qual evento. Por exemplo, observações como Jazz, 4.9, X3, Y3 e Z1 informam ao modelo ML que a música Cras maximus justo et deve estar na playlist do usuário se ele estiver procurando uma música para dormir.
Tipos de recursos em aprendizado de máquina
Recursos categóricos
Estes são atributos de dados que representam categorias ou rótulos distintos. Você deve usar esse tipo para marcar conjuntos de dados qualitativos.
#1. Recursos categóricos ordinais
Os recursos ordinais possuem categorias com uma ordem significativa. Por exemplo, níveis de ensino como Ensino Médio, Bacharelado, Mestrado, etc., possuem uma distinção clara nos padrões, mas não há diferenças quantitativas.
#2. Características categóricas nominais
Características nominais são categorias sem qualquer ordem inerente. Os exemplos podem ser cores, países ou tipos de animais. Além disso, existem apenas diferenças qualitativas.
Recursos de matriz
Este tipo de recurso representa dados organizados em matrizes ou listas. Cientistas de dados e desenvolvedores de ML costumam usar Array Features para lidar com sequências ou incorporar dados categóricos.
#1. Incorporando recursos de array
A incorporação de matrizes converte dados categóricos em vetores densos. É comumente usado em processamento de linguagem natural e sistemas de recomendação.
#2. Listar recursos de matriz
Matrizes de lista armazenam sequências de dados, como listas de itens em um pedido ou o histórico de ações.
Recursos Numéricos
Esses recursos de treinamento de ML são usados para realizar operações matemáticas, pois representam dados quantitativos.
#1. Recursos numéricos de intervalo
Os recursos de intervalo têm intervalos consistentes entre valores, mas nenhum ponto zero verdadeiro – por exemplo, dados de monitoramento de temperatura. Aqui, zero significa temperatura de congelamento, mas o atributo ainda está lá.
#2. Recursos Numéricos de Razão
Os recursos de proporção têm intervalos consistentes entre valores e um ponto zero verdadeiro. Os exemplos incluem idade, altura e renda.
Importância da engenharia de recursos em ML e ciência de dados
A seguir, exploraremos o processo passo a passo da engenharia de recursos.
Processo de engenharia de recursos passo a passo

A seguir, discutiremos métodos de engenharia de recursos.
Métodos de engenharia de recursos
#1. Análise de Componentes Principais (PCA)
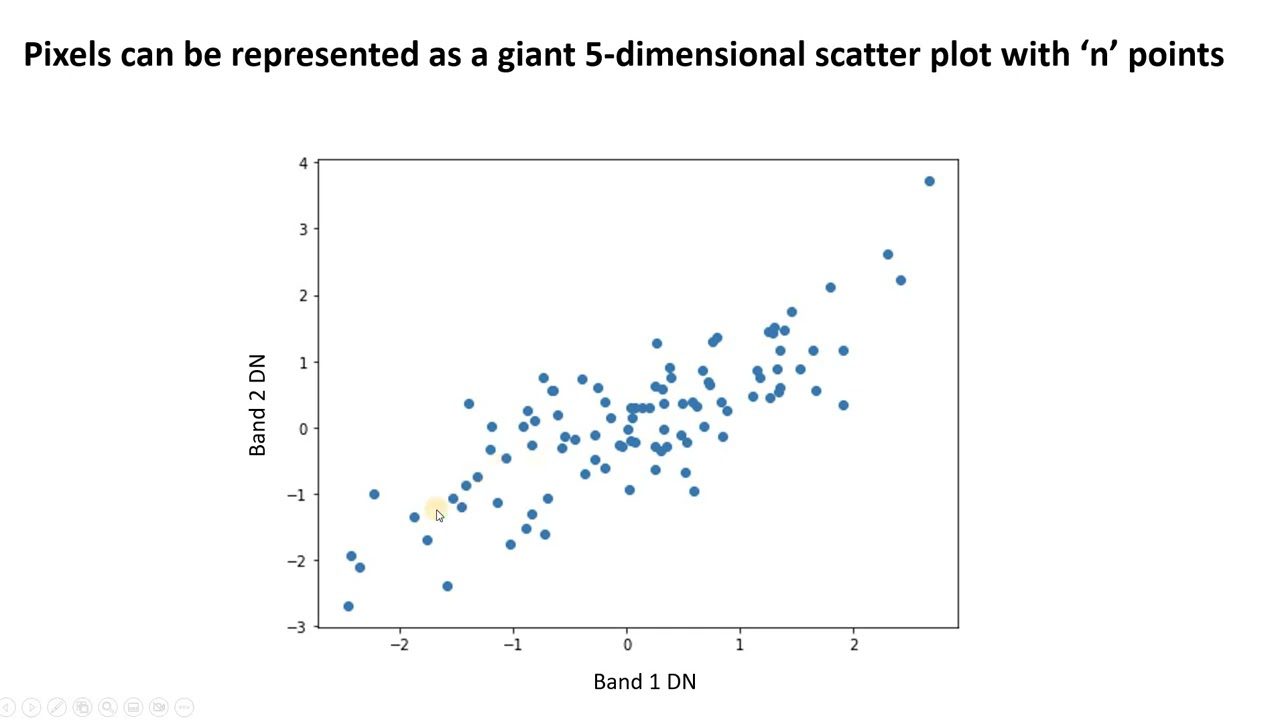
O PCA simplifica dados complexos ao encontrar novos recursos não correlacionados. Estes são chamados de componentes principais. Você pode usá-lo para reduzir a dimensionalidade e melhorar o desempenho do modelo.
#2. Recursos polinomiais
Criar recursos polinomiais significa adicionar poderes de recursos existentes para capturar relacionamentos complexos em seus dados. Ajuda seu modelo a compreender padrões não lineares.
#3. Tratamento de valores discrepantes
Outliers são pontos de dados incomuns que podem afetar o desempenho dos seus modelos. Você deve identificar e gerenciar valores discrepantes para evitar resultados distorcidos.
#4. Transformação de registro
A transformação logarítmica pode ajudá-lo a normalizar dados com uma distribuição distorcida. Reduz o impacto de valores extremos para tornar os dados mais adequados para modelagem.
#5. Incorporação estocástica de vizinho t-distribuída (t-SNE)
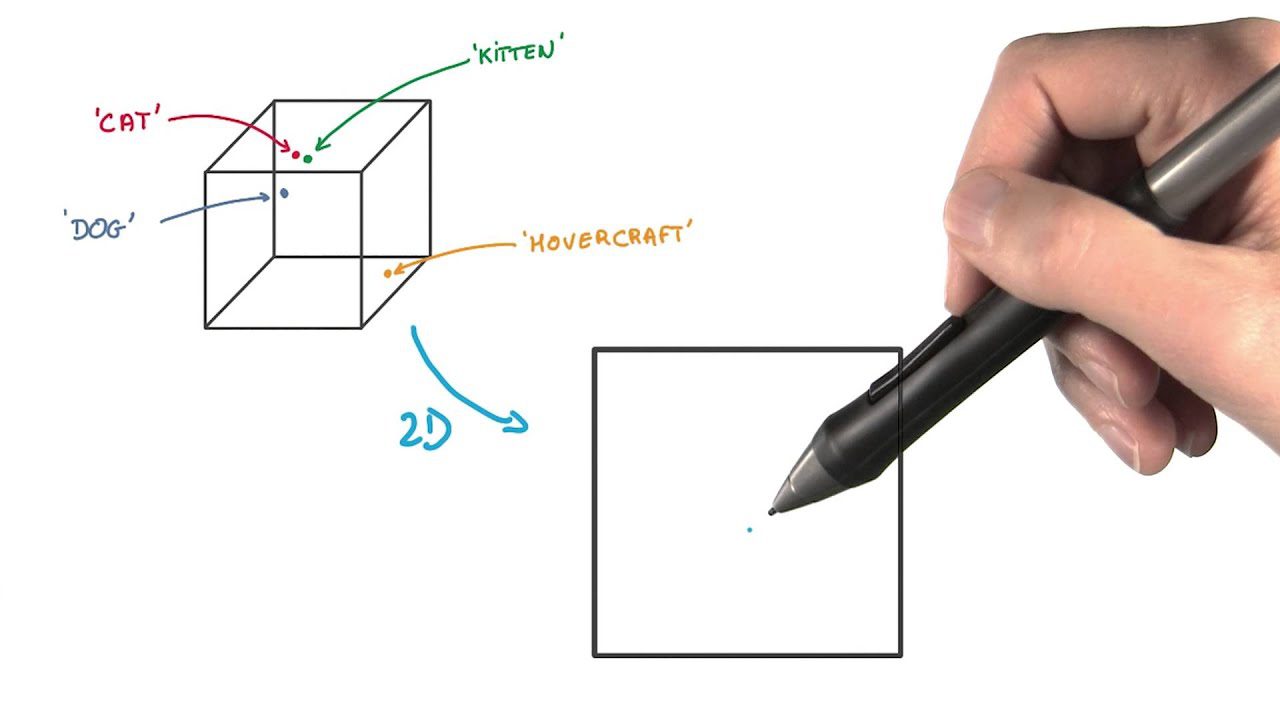
t-SNE é útil para visualizar dados de alta dimensão. Reduz a dimensionalidade e torna os clusters mais aparentes, preservando a estrutura dos dados.
Neste método de extração de recursos, você representa pontos de dados como pontos em um espaço de dimensão inferior. Em seguida, você coloca os pontos de dados semelhantes no espaço original de alta dimensão e são modelados para ficarem próximos uns dos outros na representação de menor dimensão.
Difere de outros métodos de redução de dimensionalidade por preservar a estrutura e as distâncias entre os pontos de dados.
#6. Codificação One-Hot
A codificação one-hot transforma variáveis categóricas em formato binário (0 ou 1). Assim, você obtém novas colunas binárias para cada categoria. A codificação one-hot torna os dados categóricos adequados para algoritmos de ML.
#7. Codificação de contagem
A codificação de contagem substitui valores categóricos pelo número de vezes que aparecem no conjunto de dados. Ele pode capturar informações valiosas de variáveis categóricas.
Neste método de engenharia de recursos, você usa a frequência ou contagem de cada categoria como um novo recurso numérico em vez de usar os rótulos de categoria originais.
#8. Padronização de recursos

As características de valores maiores geralmente dominam as características de valores pequenos. Assim, o modelo de ML pode facilmente ser tendencioso. A padronização evita tais causas de preconceitos em um modelo de aprendizado de máquina.
O processo de padronização normalmente envolve as duas técnicas comuns a seguir:
- Padronização Z-Score: Este método transforma cada recurso para que tenha uma média (média) de 0 e um desvio padrão de 1. Aqui, você subtrai a média do recurso de cada ponto de dados e divide o resultado pelo desvio padrão.
- Escala Mín-Máx: A escala Mín-Máx transforma os dados em um intervalo específico, normalmente entre 0 e 1. Você pode fazer isso subtraindo o valor mínimo do recurso de cada ponto de dados e dividindo pelo intervalo.
#9. Normalização
Por meio da normalização, os recursos numéricos são dimensionados para um intervalo comum, geralmente entre 0 e 1. Ela mantém as diferenças relativas entre os valores e garante que todos os recursos estejam em condições de igualdade.

#1. Ferramentas de recursos
Ferramentas de recursos é uma estrutura Python de código aberto que cria recursos automaticamente a partir de conjuntos de dados temporais e relacionais. Ele pode ser usado com ferramentas que você já usa para desenvolver pipelines de ML.
A solução usa Deep Feature Synthesis para automatizar a engenharia de recursos. Possui uma biblioteca de funções de baixo nível para criação de recursos. Featuretools também possui uma API, que também é ideal para tratamento preciso do tempo.
#2. CatBoost
Se você está procurando uma biblioteca de código aberto que combine múltiplas árvores de decisão para criar um modelo preditivo poderoso, escolha CatBoost. Esta solução oferece resultados precisos com parâmetros padrão, para que você não precise gastar horas ajustando os parâmetros.
CatBoost também permite usar fatores não numéricos para melhorar os resultados do seu treinamento. Com ele, você também pode obter resultados mais precisos e previsões rápidas.
#3. Mecanismo de recursos
Mecanismo de recursos é uma biblioteca Python com vários transformadores e recursos selecionados que você pode usar para modelos de ML. Os transformadores incluídos podem ser usados para transformação de variáveis, criação de variáveis, recursos de data e hora, pré-processamento, codificação categórica, limite ou remoção de valores discrepantes e imputação de dados ausentes. É capaz de reconhecer variáveis numéricas, categóricas e de data e hora automaticamente.
Recursos de aprendizagem de engenharia de recursos
Cursos Online e Aulas Virtuais

#1. Engenharia de recursos para aprendizado de máquina em Python: Datacamp
Este Datacamp curso de engenharia de recursos para aprendizado de máquina em Python permite criar novos recursos que melhoram o desempenho do modelo de aprendizado de máquina. Ele ensinará você a realizar engenharia de recursos e processamento de dados para desenvolver aplicativos sofisticados de ML.
#2. Engenharia de recursos para aprendizado de máquina: Udemy
De Curso de Engenharia de Recursos para Aprendizado de Máquinavocê aprenderá tópicos como imputação, codificação de variáveis, extração de recursos, discretização, funcionalidade de data e hora, outliers, etc. Os participantes também aprenderão a trabalhar com variáveis distorcidas e a lidar com categorias pouco frequentes, invisíveis e raras.
#3. Engenharia de recursos: Pluralsight
Esse Visão Plural O caminho de aprendizagem tem um total de seis cursos. Esses cursos ajudarão você a aprender a importância da engenharia de recursos no fluxo de trabalho de ML, maneiras de aplicar suas técnicas e extração de recursos de texto e imagens.
#4. Seleção de recursos para aprendizado de máquina: Udemy
Com a ajuda deste Udemy No curso, os participantes podem aprender embaralhamento de recursos, filtro, wrapper e métodos incorporados, eliminação recursiva de recursos e pesquisa exaustiva. Ele também discute técnicas de seleção de recursos, incluindo aquelas com Python, Lasso e árvores de decisão. Este curso contém 5,5 horas de vídeo sob demanda e 22 artigos.
#5. Engenharia de recursos para aprendizado de máquina: ótimo aprendizado
Este curso de Ótimo aprendizado irá apresentá-lo à engenharia de recursos enquanto ensina sobre sobreamostragem e subamostragem. Além disso, permitirá que você realize exercícios práticos de ajuste de modelos.
#6. Engenharia de recursos: Coursera
Junte-se a Curso curso para usar BigQuery ML, Keras e TensorFlow para realizar engenharia de recursos. Este curso de nível intermediário também cobre práticas avançadas de engenharia de recursos.
Livros digitais ou de capa dura

#1. Engenharia de recursos para aprendizado de máquina
Este livro ensina como transformar recursos em formatos para modelos de aprendizado de máquina.
Ele também ensina princípios de engenharia e aplicação prática por meio de exercícios.
#2. Engenharia e seleção de recursos
Ao ler este livro, você aprenderá os métodos de desenvolvimento de modelos preditivos em diferentes estágios.
Com ele, você pode aprender técnicas para encontrar as melhores representações de preditores para modelagem.
#3. Engenharia de recursos facilitada
O livro é um guia para aumentar o poder de previsão dos algoritmos de ML.
Ele ensina você a projetar e criar recursos eficientes para aplicativos baseados em ML, oferecendo insights de dados detalhados.
#4. Bookcamp de engenharia de recursos
Este livro trata de estudos de caso práticos para ensinar técnicas de engenharia de atributos para melhores resultados de ML e organização de dados atualizada.
A leitura disso garantirá que você obtenha resultados melhores sem gastar muito tempo ajustando os parâmetros de ML.
#5. A arte da engenharia de recursos
O recurso funciona como um elemento essencial para qualquer cientista de dados ou engenheiro de aprendizado de máquina.
O livro usa uma abordagem de vários domínios para discutir gráficos, textos, séries temporais, imagens e estudos de caso.
Conclusão
Então, é assim que você pode realizar a engenharia de recursos. Agora que você conhece a definição, o processo passo a passo, os métodos e os recursos de aprendizagem, pode implementá-los em seus projetos de ML e ver o sucesso!
A seguir, confira o artigo sobre aprendizagem por reforço.