

Existem terabytes e petabytes de dados nesta era da Internet, com crescimento exponencial na mesma. Mas como consumimos esses dados e os traduzimos em informações úteis para melhorar a disponibilidade do serviço?
Dados válidos, novos e compreensíveis são tudo o que as empresas precisam para seus modelos de descoberta de conhecimento.
Por esse motivo, as empresas estão aplicando análises de muitas maneiras diferentes para descobrir dados de qualidade.
Mas onde tudo começa? A resposta é disputa de dados.
Vamos começar!
últimas postagens
O que é disputa de dados?
A disputa de dados é o ato de limpar, estruturar e transformar dados brutos em formatos que simplificam os processos de análise de dados. A disputa de dados geralmente envolve trabalhar com conjuntos de dados confusos e complexos que não estão prontos para processos de pipeline de dados. A disputa de dados move os dados brutos para um estado refinado ou os dados refinados para o estado otimizado e o nível pronto para produção.
Algumas das tarefas conhecidas na disputa de dados incluem:
- Mesclar vários conjuntos de dados em um grande conjunto de dados para análise.
- Examinando faltas/lacunas nos dados.
- Remoção de outliers ou anomalias em conjuntos de dados.
- Padronização de insumos.
Os grandes armazenamentos de dados envolvidos nos processos de manipulação de dados geralmente estão além do ajuste manual, exigindo métodos automatizados de preparação de dados para produzir dados mais precisos e de qualidade.
Objetivos da disputa de dados
Além de preparar os dados para análise como o objetivo maior, outros objetivos incluem:
- Criando dados válidos e inovadores a partir de dados confusos para impulsionar a tomada de decisões nas empresas.
- Padronização de dados brutos em formatos que os sistemas de Big Data podem ingerir.
- Reduzindo o tempo gasto pelos analistas de dados ao criar modelos de dados apresentando dados ordenados.
- Criando consistência, integridade, usabilidade e segurança para qualquer conjunto de dados consumido ou armazenado em um data warehouse.
Abordagens comuns ao Data Wrangling
Descobrindo
Antes de os engenheiros de dados iniciarem as tarefas de preparação de dados, eles precisam entender como eles são armazenados, o tamanho, quais registros são mantidos, os formatos de codificação e outros atributos que descrevem qualquer conjunto de dados.
Estruturação
Esse processo envolve a organização de dados para obter formatos prontamente utilizáveis. Os conjuntos de dados brutos podem precisar de estruturação em como as colunas aparecem, o número de linhas e o ajuste de outros atributos de dados para simplificar a análise.
Limpeza
Os conjuntos de dados estruturados precisam ser eliminados de erros inerentes e de qualquer coisa que possa distorcer os dados. A limpeza, portanto, envolve remover várias entradas de células com dados semelhantes, excluir células vazias e dados discrepantes, padronizar entradas, renomear atributos confusos e muito mais.
Enriquecimento
Uma vez que os dados tenham passado pelos estágios de estruturação e limpeza, é necessário avaliar a utilidade dos dados e aumentá-los com valores de outros conjuntos de dados que faltam para fornecer a qualidade de dados desejada.
Validando
O processo de validação envolve aspectos de programação iterativa que esclarecem a qualidade, consistência, usabilidade e segurança dos dados. A fase de validação garante que todas as tarefas de transformação sejam cumpridas e sinaliza os conjuntos de dados como prontos para as fases de análise e modelagem.
Apresentando
Depois que todos os estágios são passados, os conjuntos de dados em Wrangle são apresentados/compartilhados dentro de uma organização para análise. A documentação das etapas de preparação e os metadados gerados ao longo do processo de negociação também são compartilhados nesta etapa.
Talend
Talend é uma plataforma unificada de gerenciamento de dados envolta em 3 malhas de dados para fornecer dados confiáveis e íntegros. Talend apresenta integração de dados, aplicativos e integração e integridade e governança de dados. A disputa de dados no Talend é feita por meio de uma ferramenta de apontar e clicar baseada em navegador que permite preparações de dados em lote, em massa e ao vivo – criação de perfil de dados, limpeza e documentação.
A malha de dados do Talend lida com todas as etapas do ciclo de vida dos dados, equilibrando cuidadosamente a disponibilidade, usabilidade, segurança e integridade de todos os dados de negócios.
Você já se preocupou com suas diversas fontes de dados? A abordagem unificada da Talend fornece integração rápida de dados de todas as suas fontes de dados (bancos de dados, armazenamentos em nuvem e terminais de API) – permitindo a transformação e o mapeamento de todos os dados com verificações de qualidade perfeitas.
A integração de dados no Talend é habilitada por meio de ferramentas de autoatendimento, como conectores, que permitem aos desenvolvedores ingerir dados de qualquer fonte de forma automática e categorizar adequadamente os dados.
Características do Talend
Integração universal de dados
O Talend permite que as empresas negociem qualquer tipo de dados de várias fontes de dados – ambientes em nuvem ou no local.
Flexível
A Talend vai além do fornecedor ou da plataforma ao criar pipelines de dados a partir de seus dados integrados. Depois de criar pipelines de dados a partir de seus dados ingeridos, o Talend permite que você execute os pipelines em qualquer lugar.
Qualidade dos dados
Com recursos de aprendizado de máquina, como desduplicação de dados, validação e padronização, o Talend limpa os dados ingeridos automaticamente.
Suporte para integrações de aplicativos e APIs
Depois que o significado dos seus dados for feito por meio das ferramentas de autoatendimento da Talend, você poderá compartilhar seus dados por meio de APIs amigáveis. Os endpoints da API Talend podem expor seus ativos de dados a plataformas SaaS, JSON, AVRO e B2B por meio de ferramentas avançadas de mapeamento e transformação de dados.
R

R é uma linguagem de programação bem desenvolvida e eficaz para lidar com a análise exploratória de dados para aplicativos científicos e de negócios.
Construído como software livre para computação estatística e gráficos, o R é uma linguagem e um ambiente para manipulação de dados, modelagem e visualização. O ambiente R fornece um conjunto de pacotes de software, enquanto a linguagem R integra uma série de técnicas estatísticas, de agrupamento, classificação, análise e gráficas que ajudam a manipular dados.
Características do R
Rico conjunto de pacotes
Os engenheiros de dados têm mais de 10.000 pacotes e extensões padronizados para selecionar na Comprehensive R Archive Network (CRAN). Isso simplifica a discussão e a análise de dados.
Extremamente Poderoso
Com pacotes de computação distribuídos disponíveis, o R pode realizar manipulações complexas e diretas (matemáticas e estatísticas) em objetos de dados e conjuntos de dados em questão de segundos.
Suporte multiplataforma
R é independente de plataforma, capaz de rodar em muitos sistemas operacionais. Também é compatível com outras linguagens de programação que auxiliam na manipulação de tarefas computacionalmente pesadas.
Aprender R é fácil.
Trifacta

Trifacta é um ambiente de nuvem interativo para dados de perfil que são executados em modelos de aprendizado de máquina e análise. Essa ferramenta de engenharia de dados visa criar dados compreensíveis, independentemente de quão confusos ou complexos sejam os conjuntos de dados. Os usuários podem remover entradas duplas e preencher células em branco em conjuntos de dados por meio de deduplicação e transformações de transformação linear.
Essa ferramenta de organização de dados está atenta a discrepâncias e dados inválidos em qualquer conjunto de dados. Com apenas um clique e arrastar, os dados em mãos são classificados e transformados de forma inteligente usando sugestões fornecidas pelo aprendizado de máquina para acelerar a preparação de dados.
A disputa de dados na Trifacta ocorre por meio de perfis visuais atraentes que podem acomodar equipes não técnicas e técnicas. Com as transformações visualizadas e inteligentes, a Trifacta se orgulha de seu design para os usuários em mente.
Seja ingerindo dados de data marts, data warehouses ou data lakes, os usuários estão protegidos das complexidades das preparações de dados.
Características do Trifacta
Integrações perfeitas na nuvem
Suporta cargas de trabalho de preparação em qualquer nuvem ou ambiente híbrido para permitir que os desenvolvedores ingerem conjuntos de dados para disputas, não importa onde eles morem.
Vários métodos de padronização de dados
O Trifacta wrangler possui vários mecanismos para identificar padrões nos dados e padronizar as saídas. Os engenheiros de dados podem escolher a padronização por padrão, por função ou misturar e combinar.
Fluxo de trabalho simples
A Trifacta organiza os trabalhos de preparação de dados sob a forma de fluxos. Um fluxo contém um ou mais conjuntos de dados mais suas receitas associadas (etapas definidas que transformam dados).
Um fluxo, portanto, reduz o tempo que os desenvolvedores gastam ao importar, organizar, criar perfis e exportar dados.
OpenRefine
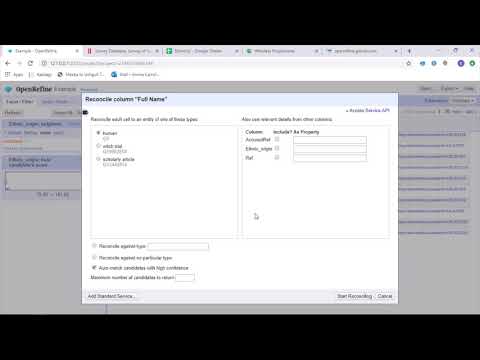
OpenRefine é uma ferramenta madura e de código aberto para trabalhar com dados confusos. Como uma ferramenta de limpeza de dados, o OpenRefine explora conjuntos de dados em questão de segundos enquanto aplica transformações complexas de células para apresentar os formatos de dados desejados.
O OpenRefine aborda a disputa de dados por meio de filtros e partições em conjuntos de dados usando expressões regulares. Usando a General Refine Expression Language incorporada, os engenheiros de dados podem aprender e visualizar dados usando facetas, filtros e técnicas de classificação antes de realizar operações de dados avançadas para extrações de entidade.
O OpenRefine permite que os usuários trabalhem em dados como projetos em que conjuntos de dados de vários arquivos de computador, URLs da Web e bancos de dados podem ser inseridos em tais projetos com a capacidade de executar localmente nas máquinas dos usuários.
Por meio de expressões, os desenvolvedores podem estender a limpeza e transformação de dados para tarefas como dividir/juntar células de vários valores, personalizar facetas e buscar dados em colunas usando URLs externos.
Características do OpenRefine
Ferramenta multiplataforma
O OpenRefine foi desenvolvido para funcionar com os sistemas operacionais Windows, Mac e Linux por meio de configurações do instalador para download.
Conjunto avançado de APIs
Apresenta API OpenRefine, API de extensão de dados, API de reconciliação e outras APIs que suportam a interação dos usuários com os dados.
Datameer

O Datameer é uma ferramenta de transformação de dados SaaS criada para simplificar o processamento e a integração de dados por meio de processos de engenharia de software. O Datameer permite extração, transformação e carregamento de conjuntos de dados para data warehouses na nuvem, como o Snowflake.
Essa ferramenta de organização de dados funciona bem com formatos de conjuntos de dados padrão, como CSV e JSON, permitindo que os engenheiros importem dados em formatos variados para agregação.
O Datameer apresenta documentação de dados semelhante a catálogo, perfil de dados profundo e descoberta para atender a todas as necessidades de transformação de dados. A ferramenta mantém um perfil de dados visual profundo que permite aos usuários rastrear campos e valores inválidos, ausentes ou distantes e a forma geral dos dados.
Executado em um data warehouse escalável, o Datameer transforma dados para análises significativas por meio de pilhas de dados eficientes e funções semelhantes ao Excel.
O Datameer apresenta uma interface de usuário híbrida, com código e sem código, para acomodar equipes amplas de análise de dados que podem criar pipelines ETL complexos facilmente.
Características do Datameer
Ambientes de vários usuários
Apresenta ambientes de transformação de dados de várias pessoas – código baixo, código e híbrido, para dar suporte a pessoas com e sem tecnologia.
Espaços de trabalho compartilhados
O Datameer permite que as equipes reutilizem e colaborem em modelos para acelerar projetos.
Documentação rica em dados
O Datameer suporta documentação de dados gerada pelo sistema e pelo usuário por meio de metadados e descrições, tags e comentários no estilo wiki.
Palavras finais 👩🏫
A análise de dados é um processo complexo, que exige que os dados sejam organizados adequadamente para fazer inferências significativas e fazer previsões. As ferramentas de Data Wrangling ajudam você a formatar grandes quantidades de dados brutos para ajudá-lo a realizar análises avançadas. Escolha a melhor ferramenta que atenda às suas necessidades e torne-se um profissional do Analytics!
Você pode gostar:
Melhores ferramentas CSV para converter, formatar e validar.