

Web scraping permite coletar com eficiência grandes quantidades de dados da Internet de maneira muito rápida e é particularmente útil nos casos em que os sites não expõem seus dados de forma estruturada por meio do uso de Interfaces de Programação de Aplicativos (API).
Por exemplo, imagine que você está criando um aplicativo que compara preços de itens em sites de comércio eletrônico. Como você faria isso? Uma maneira é verificar manualmente o preço dos itens em todos os sites e registrar suas descobertas. No entanto, esta não é uma forma inteligente, pois existem milhares de produtos em plataformas de comércio eletrônico e levaria uma eternidade para extrair dados relevantes.
A melhor maneira de fazer isso é através do web scraping. Web scraping é o processo de extração automática de dados de páginas da web e sites por meio do uso de software.
Scripts de software, conhecidos como web scrapers, são usados para acessar sites e recuperar dados deles. Os dados recuperados, geralmente de forma não estruturada, podem então ser analisados e armazenados de forma estruturada que seja significativa para os usuários.
Web scraping é muito valioso na extração de dados, pois fornece acesso a uma riqueza de dados e permite a automação, de modo que você pode agendar seu script de web scraping para ser executado em determinados momentos ou em resposta a determinados gatilhos. Web scraping também permite que você obtenha atualizações em tempo real e facilita a realização de pesquisas de mercado.

Muitas empresas dependem de web scraping para extrair dados para análise. Empresas especializadas em recursos humanos, comércio eletrônico, finanças, imóveis, viagens, mídias sociais e pesquisa usam web scraping para extrair dados relevantes de sites.
O próprio Google usa web scraping para indexar sites na Internet para que possa fornecer resultados de pesquisa relevantes aos usuários.
No entanto, é importante ter cuidado ao descartar a web. Embora a eliminação de dados acessíveis ao público não seja ilegal, alguns sites não permitem a eliminação. Isso pode ocorrer porque eles possuem informações confidenciais do usuário, seus termos de serviço proíbem explicitamente o descarte da Web ou estão protegendo a propriedade intelectual.
Além disso, alguns sites não permitem web scraping, pois isso pode sobrecarregar o servidor do site e aumentar os custos de largura de banda, especialmente quando o web scraping é feito em grande escala.
Para verificar se um site pode ser descartado, anexe robots.txt ao URL do site. robots.txt é usado para indicar aos bots quais partes do site podem ser copiadas. Por exemplo, para verificar se você consegue raspar o Google, acesse google.com/robots.txt
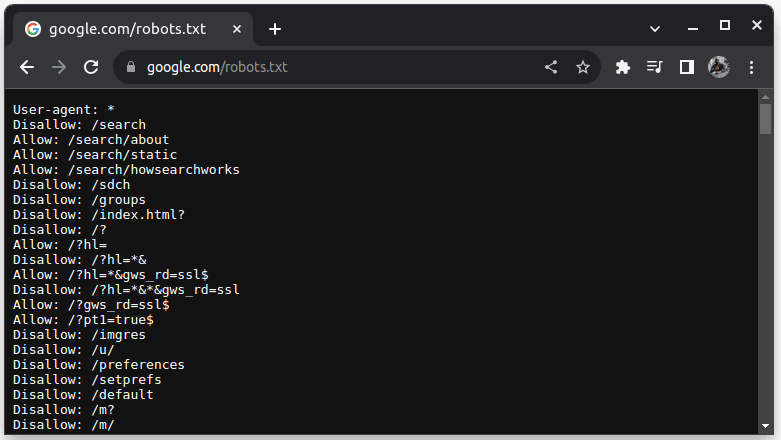
Agente do usuário: * refere-se a todos os bots ou scripts de software e rastreadores. Disallow é usado para informar aos bots que eles não podem acessar nenhuma URL em um diretório, por exemplo, /search. Permitir indica diretórios de onde eles podem acessar URLs.
Um exemplo de site que não permite scraping é o LinkedIn. Para verificar se você consegue raspar o LinkedIn, acesse linkedin.com/robots.txt
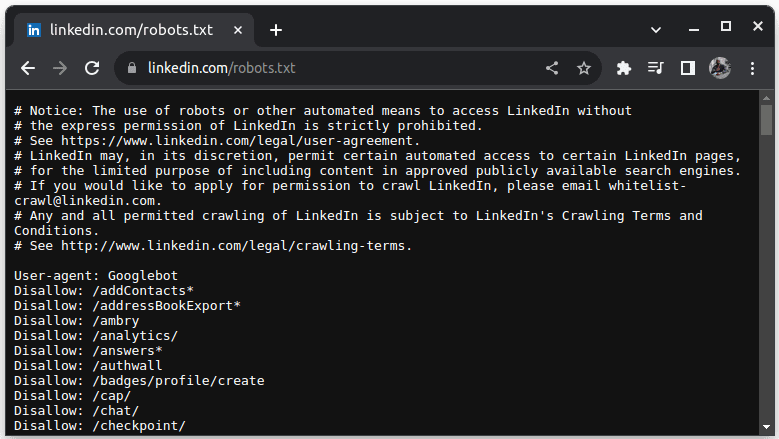
Como você pode ver, você não tem permissão para acessar o LinkedIn sem a permissão deles. Sempre verifique se um site permite scraping para evitar problemas legais.
últimas postagens
Por que Java é uma linguagem adequada para web scraping
Embora você possa criar um web scraper com uma variedade de linguagens de programação, Java é particularmente ideal para esse trabalho por vários motivos. Primeiro, Java tem um ecossistema rico e uma grande comunidade e fornece uma variedade de bibliotecas de web scraping, como JSoup, WebMagic e HTMLUnit, que facilitam a escrita de web scrapers.

Ele também fornece bibliotecas de análise HTML para simplificar o processo de extração de dados de documentos HTML e bibliotecas de rede, como HttpURLConnection, para fazer solicitações a diferentes URLs de sites.
O forte suporte do Java para simultaneidade e multithreading também é benéfico no web scrapping, pois permite o processamento paralelo e o tratamento de tarefas de web scraping com múltiplas solicitações, permitindo a raspagem de várias páginas simultaneamente. Sendo a escalabilidade um ponto forte do Java, você pode raspar sites confortavelmente em grande escala usando um web scraper escrito em Java.
O suporte multiplataforma do Java também é útil, pois permite escrever um web scraper e executá-lo em qualquer sistema que tenha uma Java Virtual Machine compatível. Portanto, você pode escrever um web scraper em um sistema operacional ou dispositivo e executá-lo em um sistema operacional diferente sem a necessidade de modificar o web scraper.
Java também pode ser usado com navegadores headless, como Headless Chrome, HTML Unit, Headless Firefox e PhantomJs, entre outros. Um navegador headless é um navegador sem interface gráfica de usuário. Navegadores headless podem simular interações do usuário e são muito úteis ao copiar sites que exigem interações do usuário.
Para completar, Java é uma linguagem muito popular e amplamente usada que é suportada e pode ser facilmente integrada a uma variedade de ferramentas, como bancos de dados e estruturas de processamento de dados. Isso é benéfico porque garante que, à medida que você coleta dados, todas as ferramentas necessárias para extrair, processar e armazenar os dados provavelmente suportam Java.
Vamos ver como podemos usar Java para web scrapping.
Java para Web Scraping: Pré-requisitos
Para usar Java em web scraping, os seguintes pré-requisitos devem ser atendidos:
1. Java – você deve ter o Java instalado, de preferência a versão mais recente com suporte de longo prazo. Caso você não tenha o Java instalado, acesse instalar o Java para saber como instalar o Java na sua máquina
2. Ambiente de Desenvolvimento Integrado (IDE) – Você deve ter um IDE instalado em sua máquina. Neste tutorial, usaremos o IntelliJ IDEA, mas você pode usar qualquer IDE que conheça.
3. Maven – será usado para gerenciamento de dependências e para instalar uma biblioteca de web scraping.
Caso você não tenha o Maven instalado, você pode instalá-lo abrindo o terminal e executando:
sudo apt install maven
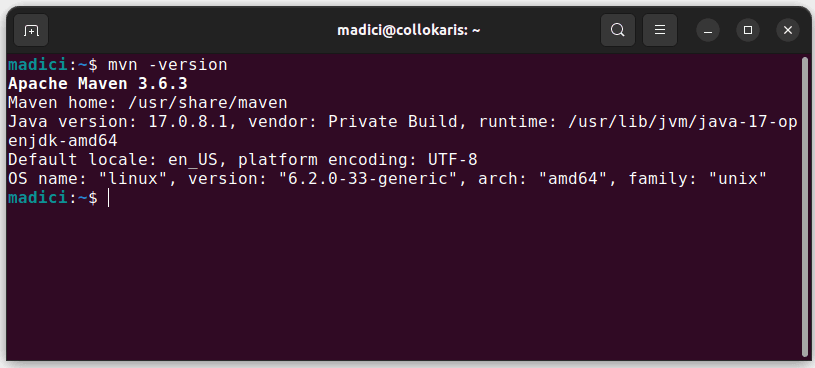
Isso instala o Maven do repositório oficial. Você pode confirmar que o Maven foi instalado com sucesso executando:
mvn -version
Caso a instalação tenha sido bem-sucedida, você deverá obter a seguinte saída:
Configurando o Ambiente
Para configurar seu ambiente:
1. Abra o IntelliJ IDEA. Na barra de menu esquerda, clique em Projetos e selecione Novo Projeto.
2. Na janela Novo Projeto que se abre, preencha-o conforme mostrado abaixo. Certifique-se de que a linguagem esteja definida como Java e o sistema de compilação como Maven. Você pode dar ao projeto o nome que preferir e usar Local para especificar a pasta onde deseja que o projeto seja criado. Feito isso, clique em Criar.
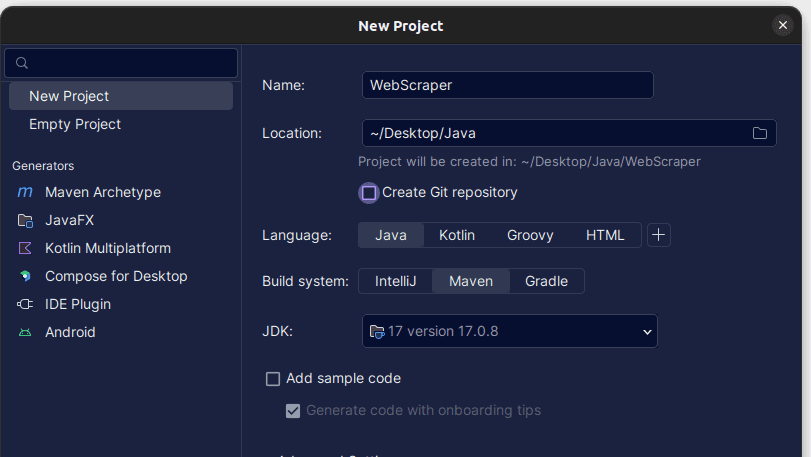
3. Depois que seu projeto for criado, você deverá ter um pom.xml em seu projeto, conforme mostrado abaixo.
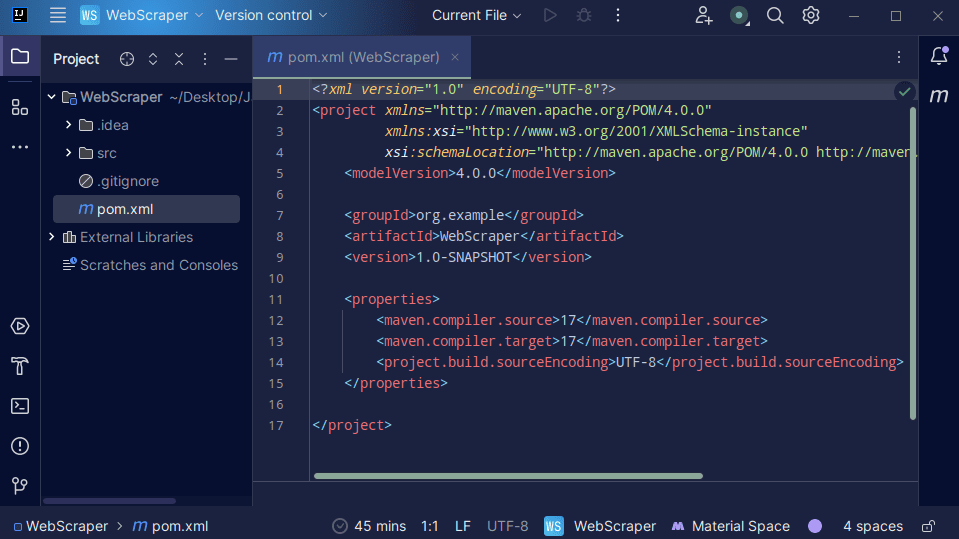
O arquivo pom.xml é criado pelo Maven e contém informações sobre o projeto e detalhes de configuração usados pelo Maven para construir o projeto. É este arquivo que também utilizamos para indicar que utilizaremos bibliotecas externas.
Ao construir um web scraper, usaremos a biblioteca jsoup. Precisamos, portanto, adicioná-lo como uma dependência no arquivo pom.xml para que o Maven possa disponibilizá-lo em nosso projeto.
4. Adicione a dependência jsoup no arquivo pom.xml copiando o código abaixo e adicionando-o ao seu arquivo pom.xml
<dependencies>
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.16.1</version>
</dependency>
</dependencies>
O resultado deverá ser conforme mostrado abaixo:
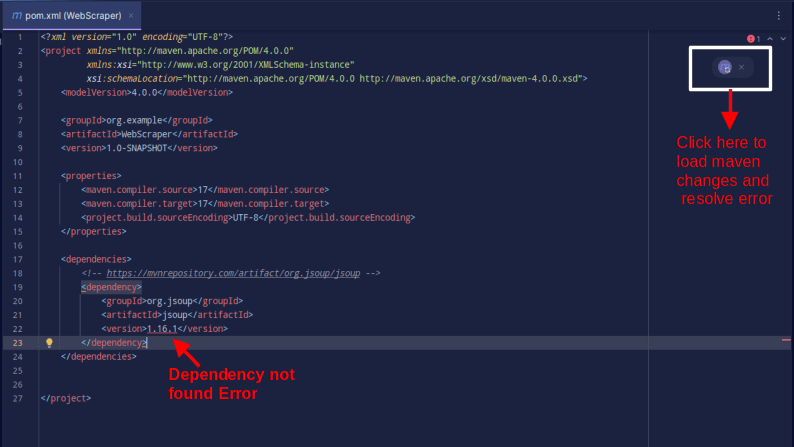
Caso você encontre um erro dizendo que a dependência não pode ser encontrada, clique no ícone indicado para que o Maven carregue as alterações feitas, carregue a dependência e remova o erro.
Com isso, seu ambiente está totalmente configurado.
Raspagem da Web com Java
Para web scraping, vamos extrair dados de Raspe este siteque fornece uma área restrita onde os desenvolvedores podem praticar web scraping sem enfrentar problemas legais.
Para raspar um site usando Java
1. Na barra de menu esquerda do IntelliJ, abra o diretório src e, em seguida, o diretório principal, que está dentro do diretório src. O diretório principal contém um diretório chamado java; clique com o botão direito nele e selecione Novo e depois Classe Java
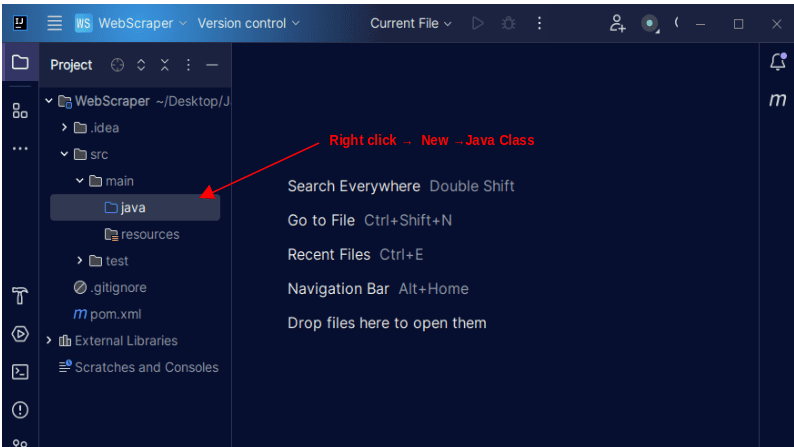
Dê à classe o nome que desejar, como WebScraper, e pressione Enter para criar uma nova classe Java.
Abra o arquivo recém-criado que contém as classes Java que você acabou de criar.
2. Web scraping envolve a obtenção de dados de sites. Portanto, precisamos especificar o URL do qual queremos extrair os dados. Depois de especificarmos o URL, precisamos nos conectar ao URL e fazer uma solicitação GET para buscar o conteúdo HTML da página.
O código que faz isso é mostrado abaixo:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import java.io.IOException;
public class WebScraper {
public static void main(String[] args) {
String url = "https://www.scrapethissite.com/pages/simple/";
try {
Document doc = Jsoup.connect(url).get();
System.out.println(doc);
} catch (IOException e) {
System.out.println("An IOException occurred. Please try again.");
}
}
}
Saída:
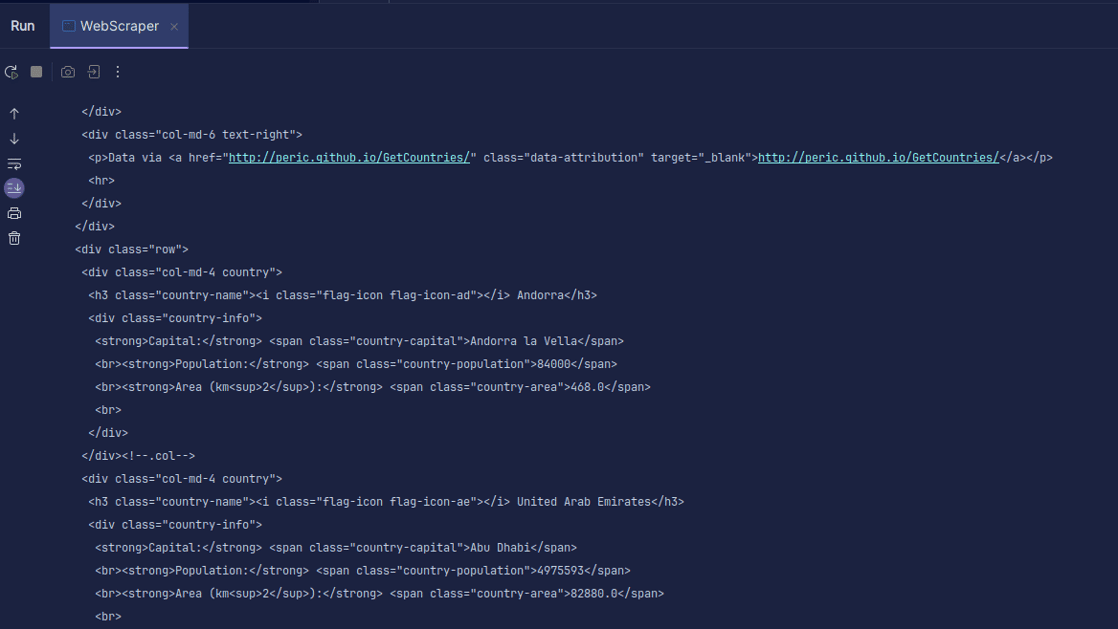
Como você pode ver, o HTML da página é retornado e é o que estamos imprimindo. Ao extrair, o URL especificado pode conter um erro e o recurso que você está tentando extrair pode não existir. É por isso que é importante agrupar nosso código em uma instrução try-catch.
A linha:
Document doc = Jsoup.connect(url).get();
É usado para conectar-se ao URL que você deseja extrair. O método get() é usado para fazer uma solicitação GET e buscar o HTML na página. O resultado retornado é então armazenado em um objeto JSOUP Document, denominado doc. Armazenar o resultado em um documento JSOUP permite usar a API JSOUP para manipular o HTML retornado.
3. Vá para Raspe este site e inspecione a página. No HTML, você deverá ver a estrutura mostrada abaixo:
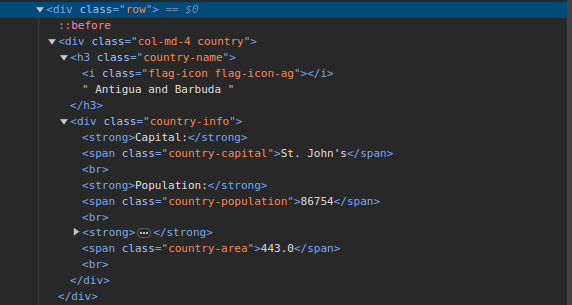
Observe que todos os países da página estão armazenados em uma estrutura semelhante. Existe uma div com uma classe chamada country com um elemento h3 com uma classe country-name contendo o nome de cada país na página.
Dentro da div principal, há outra div com uma classe de informações do país e contém informações como capital, população e área do país. Podemos usar esses nomes de classes para selecionar os elementos HTML e extrair informações deles.
4. Extraia o conteúdo específico do HTML da página usando as seguintes linhas:
Elements countries = doc.select(".country");
for (Element country : countries) {
String countryName = country.select(".country-name").text();
String capitalCity = country.select(".country-capital").text();
String population = country.select(".country-population").text();
System.out.println(countryName + " - " + capitalCity + " Population - " + population);
}
Estamos usando o método select() para selecionar elementos do HTML da página que correspondem ao seletor CSS específico que passamos. Em nosso caso, passamos os nomes das classes. Ao inspecionar a página, vimos que todas as informações do país na página são armazenadas em uma div com uma classe de país.
Cada país tem seu próprio div com uma classe de país e o div contém informações como nome do país, capital e população.
Portanto, primeiro selecionamos todos os países da página usando a classe .country. Em seguida, armazenamos isso em uma variável chamada países do tipo Elementos, que funciona como uma lista. Em seguida, usamos um loop for para percorrer os países e extrair o nome do país, a capital e a população e imprimir o que for encontrado.
Toda a nossa base de código é mostrada abaixo:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
import org.jsoup.nodes.Element;
import java.io.IOException;
public class WebScraper {
public static void main(String[] args) {
String url = "https://www.scrapethissite.com/pages/simple/";
try {
Document doc = Jsoup.connect(url).get();
Elements countries = doc.select(".country");
for (Element country : countries) {
String countryName = country.select(".country-name").text();
String capitalCity = country.select(".country-capital").text();
String population = country.select(".country-population").text();
System.out.println(countryName + " - " + capitalCity + " - Population - " + population);
}
} catch (IOException e) {
System.out.println("An IOException occurred. Please try again.");
}
}
}
Saída:
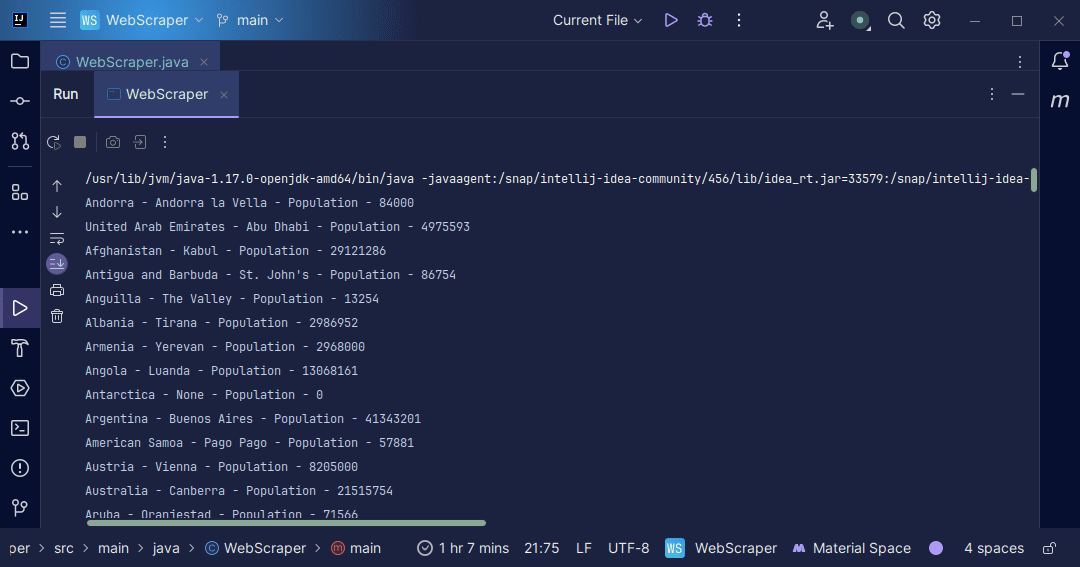
Com as informações que obtemos da página, podemos fazer uma variedade de coisas, como imprimi-las como acabamos de fazer ou armazená-las em um arquivo, caso queiramos fazer processamento adicional de dados.
Conclusão
Web scraping é uma excelente maneira de extrair dados não estruturados de sites, armazenar os dados de forma estruturada e processá-los para extrair informações significativas. No entanto, é importante ter cuidado ao fazer web scraping, pois alguns sites não permitem web scraping.
Por segurança, use sites que fornecem sandboxes para praticar o desmantelamento. Caso contrário, sempre inspecione o robots.txt de cada site que você deseja copiar para descobrir se o site permite a remoção.
ao escrever web scrapper, Java é uma linguagem excelente, pois fornece bibliotecas que tornam o web scraping mais fácil e eficiente. Como desenvolvedor Java, construir um web scraper o ajudará a desenvolver ainda mais suas habilidades de programação. Então vá em frente e escreva seu próprio web scrapper ou modifique aquele usado no artigo para extrair diferentes tipos de informações. Boa codificação!
Você também pode explorar algumas soluções populares de web scraping baseadas em nuvem.