
Vamos descobrir como você pode manter sua produção confiável com a ajuda das ferramentas da Chaos Engineering.
A engenharia do caos é uma disciplina em que você experimenta em seu sistema ou aplicativo para revelar suas fraquezas e falhas de capacidade. Estes são algo que você não pensou que poderia acontecer ao criá-lo. Assim, você causaria algumas falhas de propósito em seu sistema para mostrar suas fraquezas para fazer as correções e tornar seu sistema e seu aplicativo mais resilientes.
Muitas organizações populares como Netflix, LinkedIn e Facebook realizam engenharia de caos para entender melhor sua arquitetura de microsserviços e sistemas distribuídos. Ele ajuda a encontrar novos problemas antes das reclamações reais dos usuários e a tomar as medidas necessárias para corrigi-los. É assim que essas organizações podem atender milhões de usuários, aumentar sua produtividade e economizar milhões de dólares 🤑.
Benefícios da Engenharia do Caos:
- Controle as perdas de receita encontrando problemas críticos
- Redução na falha do sistema ou aplicativo
- Melhor experiência do usuário com menos interrupções e alta disponibilidade de serviço
- Ele ajuda você a aprender sobre o sistema e ganhar confiança.
Quão confiante você está sobre sua confiabilidade de produção? É realmente à prova de desastres?
Vamos descobrir com a ajuda das seguintes ferramentas populares de teste de caos.
últimas postagens
Malha do Caos
Malha do Caos é uma solução de gerenciamento de engenharia de caos que injeta falhas em todas as camadas de um sistema Kubernetes. Isso inclui pods, a rede, E/S do sistema e o kernel. O Chaos Mesh pode matar automaticamente os pods do Kubernetes e simular latências. Ele pode interromper a comunicação entre os pods e simular erros de leitura/gravação. Ele pode agendar regras para os experimentos e definir seu escopo. Esses experimentos são especificados usando arquivos YAML.
O Chaos Mesh tem um painel para visualizar análises sobre experimentos. Ele é executado em cima do Kubernetes e suporta a maior parte da plataforma de nuvem. É de código aberto e foi recentemente aceito como um projeto sandbox CNCF. Usando princípios de engenharia do caos, você pode adicionar Chaos Mesh ao seu fluxo de trabalho DevOps para criar aplicativos resilientes.
Recursos de engenharia do caos:
- Facilmente implantável em clusters do Kubernetes sem modificação na lógica de implantação
- Nenhuma dependência exclusiva é necessária para implantação
- Define objetos de caos usando CustomResourceDefinitions (CRD)
- Fornece um painel para rastrear todos os experimentos
Kit de ferramentas do caos é uma ferramenta simples e de código aberto para automação de experimentos de engenharia de caos.
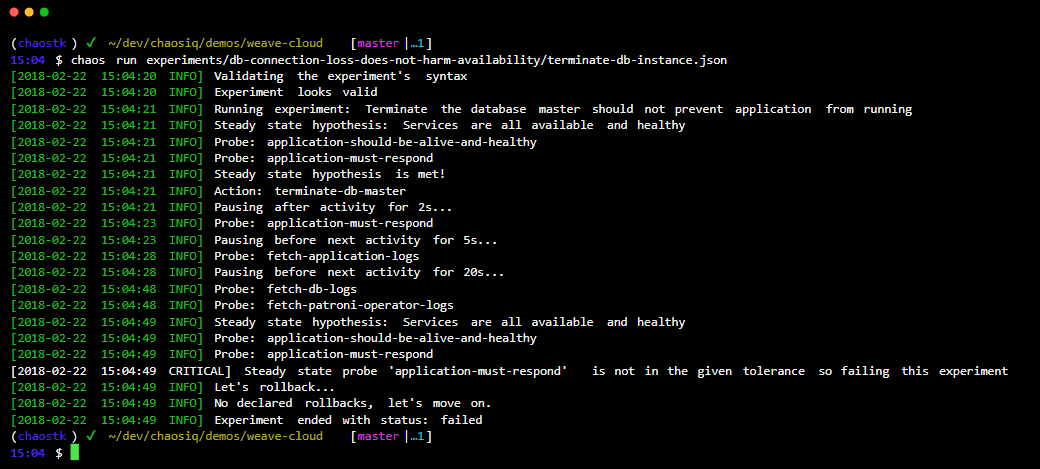
Você integra o Chaos ToolKit ao seu sistema usando um conjunto de drivers ou plugins compatíveis com AWS, Google Cloud, Slack, Prometheus, etc.
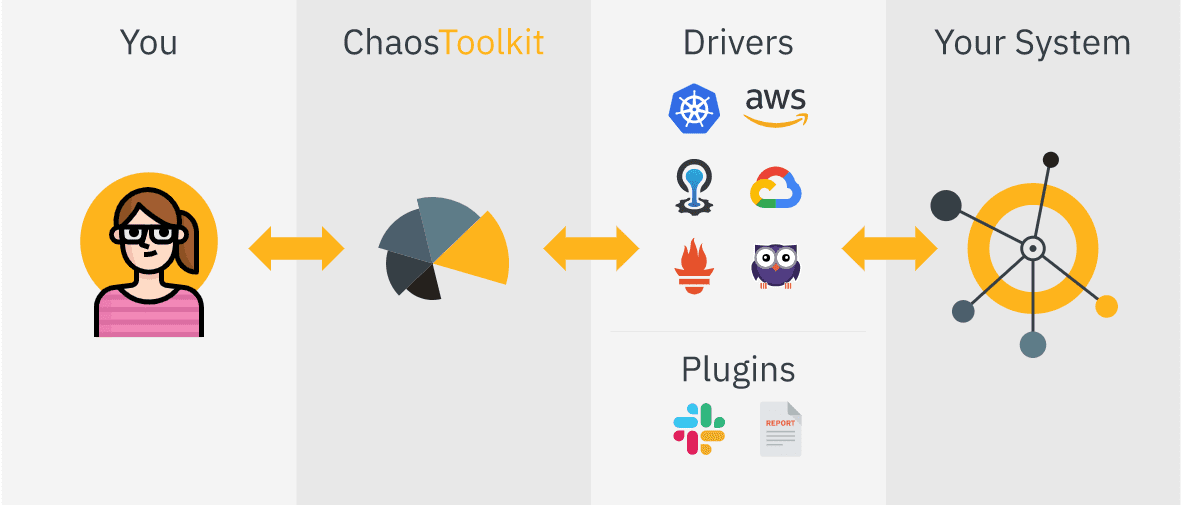
Recursos do Chaos ToolKit:
- Fornece API aberta declarativa para criar experimentos de caos independente de um fornecedor ou tecnologia
- Pode ser facilmente incorporado em pipelines CICD para automação
- Fornece suporte comercial e empresarial também através de ChaosIQ
ChaosKubeGenericName
Como você pode adivinhar pelo nome, é para Kubernetes.
Chaoskube é uma ferramenta de caos de código aberto que mata pods aleatórios periodicamente no cluster Kubernetes. Ele ajuda você a entender como seu sistema reagirá quando o pod falhar. Por padrão, ele mata um pod em qualquer namespace a cada 10 minutos. Você pode filtrar os pods de destino no Chaoskube usando namespaces, rótulos, anotações, etc. Ele pode ser facilmente instalado usando o Chaoskube.

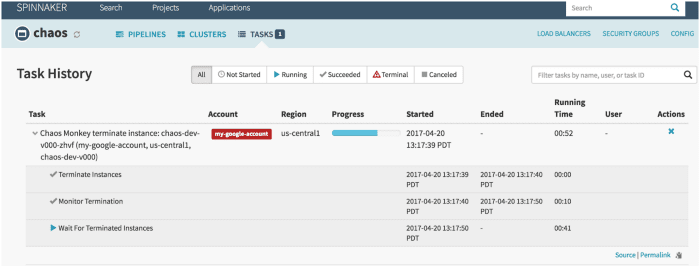
Macaco do Caos
Macaco do Caos é uma ferramenta usada para verificar a resiliência dos sistemas em nuvem, criando propositalmente falhas para que esses sistemas entendam sua reação. A Netflix o criou para testar a resiliência e a capacidade de recuperação da infraestrutura da AWS. Foi nomeado Chaos Monkey porque cria destruição como um macaco selvagem e armado para testar as falhas.
Além disso, foi o Chaos Monkey, que deu origem à nova prática de engenharia Chaos Engineering. Ele foi criado com base no princípio de que é melhor falhar repetidamente para evitar qualquer falha significativa repentinamente.
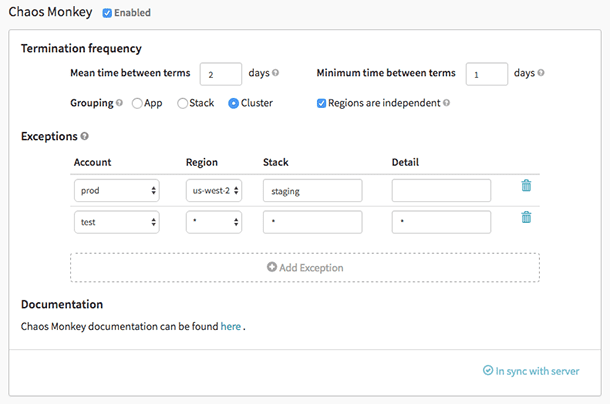
Recursos do Macaco do Caos:
- Ele ajuda você a se preparar para falhas de instância aleatórias.
- Incentiva a redundância para falhas inesperadas
- Usa o Spinnaker para habilitar a compatibilidade entre nuvens
- Fornece programação configurável para simular falhas
- Integrado com governador para adicionar novas dependências ao macaco do caos
Simmy
Simmy é uma ferramenta de caos de injeção de falhas que se integra ao projeto de resiliência Polly para .NET. Ele permite que você crie políticas de injeção de caos por meio do Polly, onde você executa seus códigos. Ele oferece diferentes políticas, como política de exceções para injetar exceções no sistema, política de comportamento para injetar qualquer novo comportamento, etc. Essas políticas são projetadas para injetar o comportamento aleatoriamente.
Características do Simmy:
- Fornece políticas Monkey ou políticas Chaos para injetar caos
- Fácil de testar quaisquer falhas de dependência
- Ajuda a reverter para o modelo de trabalho rapidamente e controla o raio de explosão.
- Está pronto para produção.
- Ele também pode definir falhas com base em fatores externos (por exemplo, falhas devido à configuração global)
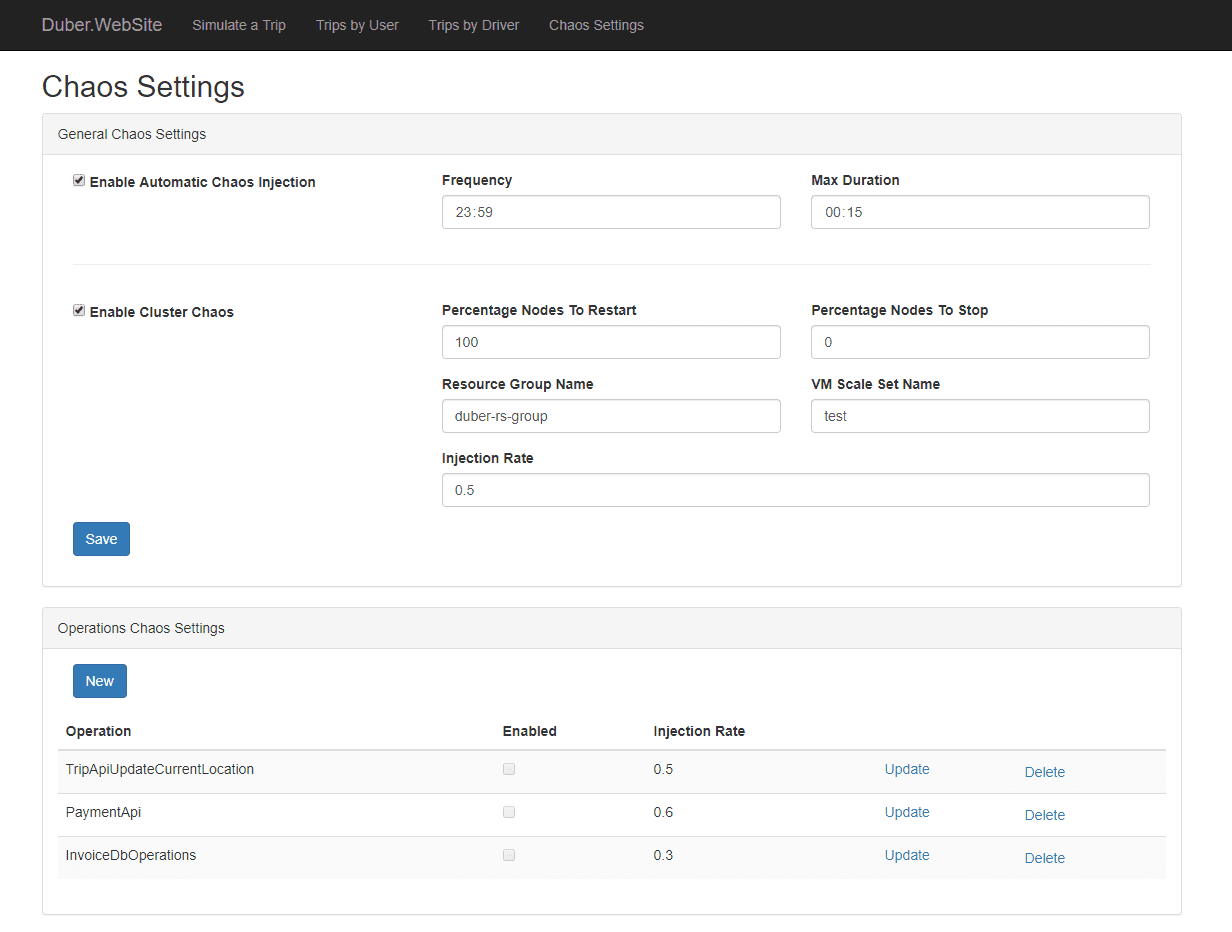
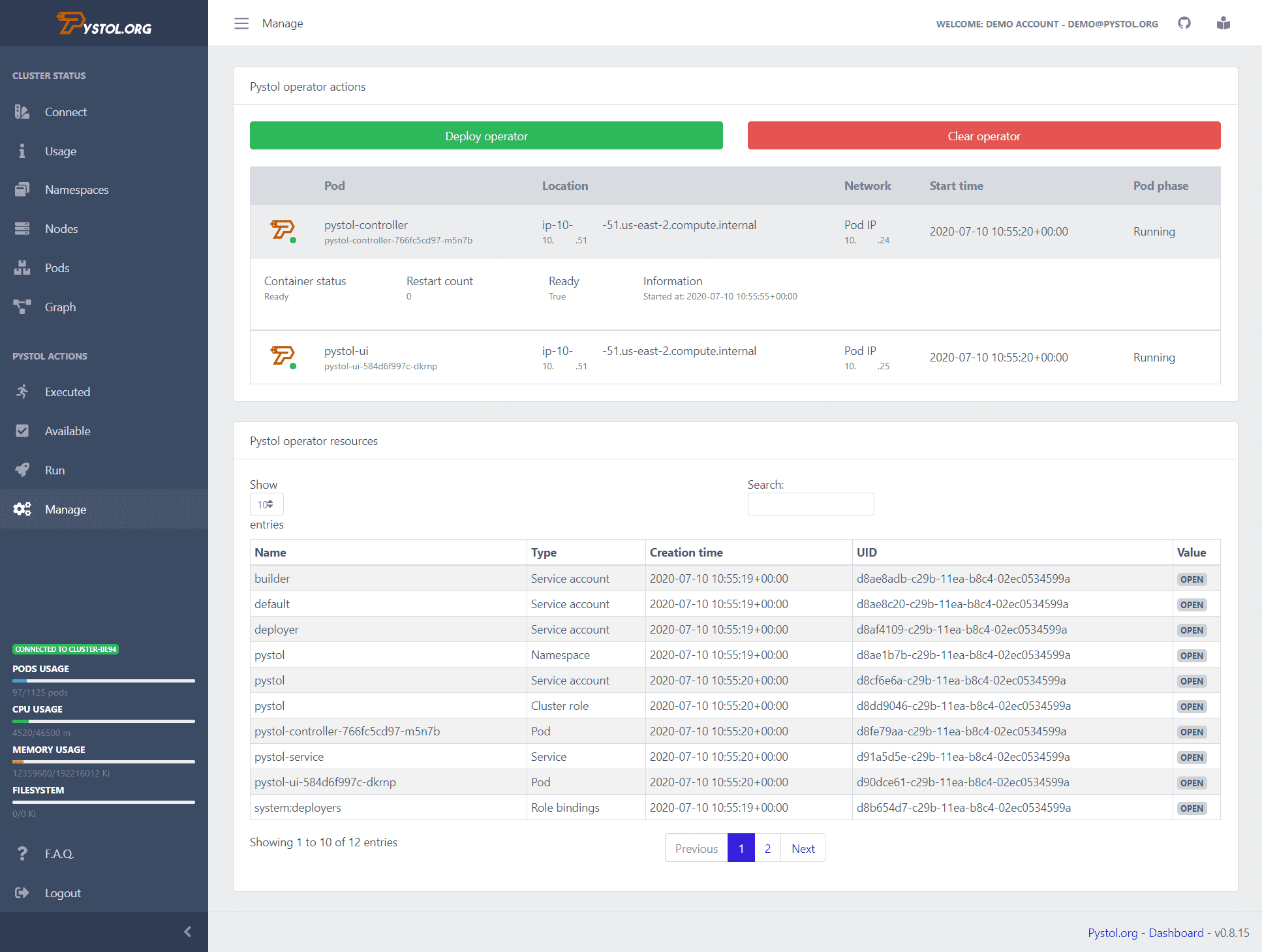
Pistola
Pistola é uma ferramenta usada para injetar injeções defeituosas em ambientes nativos da nuvem. Ele assiste a eventos no ETCD por meio de operadores do Kubernetes. Quando uma ação de injeção de falha é executada, os operadores criam os pods e executam algumas coleções do Ansible. Assim, os desenvolvedores não precisam escrever suas próprias ações para executar.
Pystol fornece ações prontas para testar o sistema. Ainda assim, se um desenvolvedor quiser criar uma nova ação, isso pode ser feito usando GoLang e Python.
Ele fornece um painel de integração contínua para fornecer uma visão resumida de todas as operações de trabalho. Você pode executar o Pystol localmente ou implantá-lo em um contêiner usando sua imagem docker. O Pystol fornece duas interfaces, uma é a interface do usuário da Web e a outra é por meio da CLI. Obviamente, a interface do usuário da Web é uma opção melhor.
Muxy
Muxy é um proxy para testar seus padrões de resiliência e tolerância a falhas para falhas de sistema distribuído do mundo real. Ele pode adulterar o nível de transporte (camada 4), nível de sessão TCP (camada 5) e nível de protocolo HTTP (camada 7).
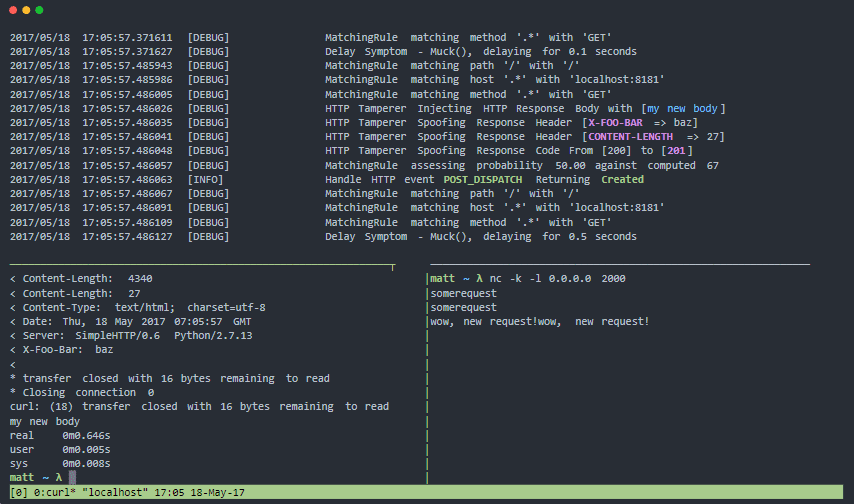
Características do Muxy:
- Arquitetura modular e facilmente extensível
- Possui contêiner docker oficial
- Fácil de instalar, sem dependências necessárias.
- Ideal para testes contínuos de resiliência
- Simula problemas de conectividade de rede para sistemas distribuídos e dispositivos móveis
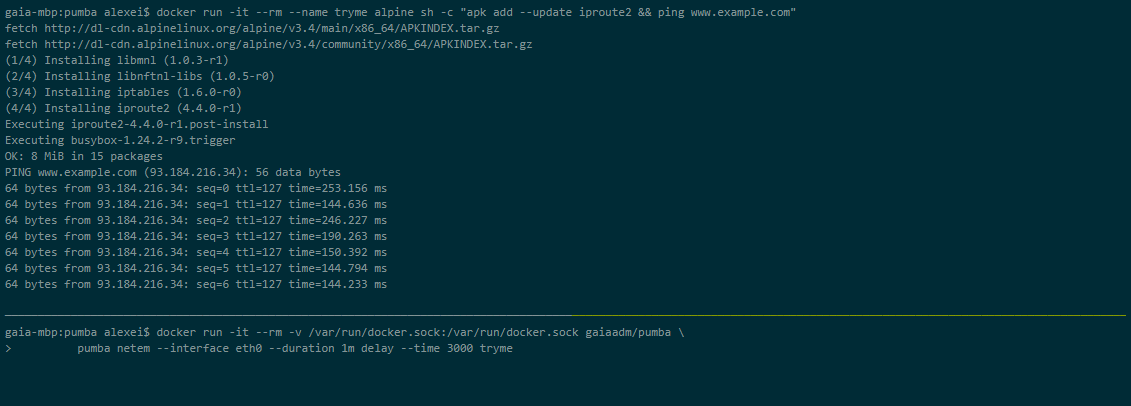
Pumba
Pumba é uma ferramenta de linha de comando que realiza testes de caos para contêineres docker. Com o Pumba, você trava propositalmente os contêineres do docker do aplicativo para ver como o sistema reage. Você também pode realizar testes de estresse nos recursos do contêiner, como CPU, memória, sistema de arquivos, entrada/saída, etc.
Você também pode executar o Pumba em um cluster Kubernetes. Você precisa usar DaemonSets para implantar o Pumba em nós do Kubernetes. Você pode usar vários contêineres Pumba para executar vários comandos Pumba no mesmo DaemonSet.
ChaosBlade
ChaosBlade é uma ferramenta de código aberto para injetar experimentos nos sistemas do Alibaba. Ele testa todas as falhas que o Alibaba enfrentou nos últimos dez anos e aplica as melhores práticas para evitá-las. Segue princípios de engenharia do caos para verificar a tolerância a falhas de sistemas distribuídos.
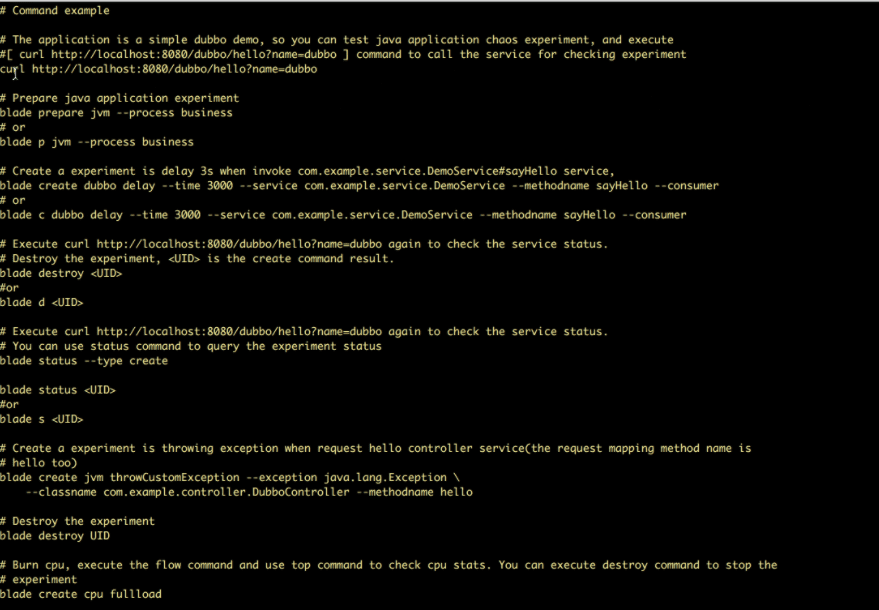
Características do ChaosBlade:
- Fornece cenários experimentais para vários recursos, como CPU, rede, memória, disco, etc.
- Fornece cenários experimentais para nós, redes e pods na plataforma Kubernetes
- Fornece comandos CLI fáceis de usar para executar experimentos
tornassol
tornassol segue os princípios de engenharia do caos nativos da nuvem. A missão da ferramenta de tornassol é fornecer uma estrutura completa para encontrar pontos fracos em seus sistemas Kubernetes e seus aplicativos em execução no Kubernetes.
Ele possui um operador de caos e os CRDs (CustomResourceDefinitions) em torno dele, permitindo capacidade plug-and-play. Trata-se de colocar sua lógica de caos em uma imagem do docker, jogá-la em uma estrutura de tornassol e orquestrá-la usando os CRDs.

Características de tornassol:
- Ajuda os engenheiros e desenvolvedores de confiabilidade do site a encontrar pontos fracos no sistema Kubernetes
- Fornece experimentos genéricos prontos para uso
- Fornece API de caos para gerenciamento de fluxo de trabalho de caos
- Litmus SDK suporta Go, Python e Ansible para criar seus próprios experimentos.
Gremlin
Gremlin ajuda os engenheiros a construir softwares mais resilientes. Ele fornece uma plataforma para executar experimentos de engenharia do caos de forma segura e direta.

Você pode injetar falhas em hosts ou contêineres com gremlin, independentemente de onde eles estejam, seja na nuvem pública ou em seu próprio data center.
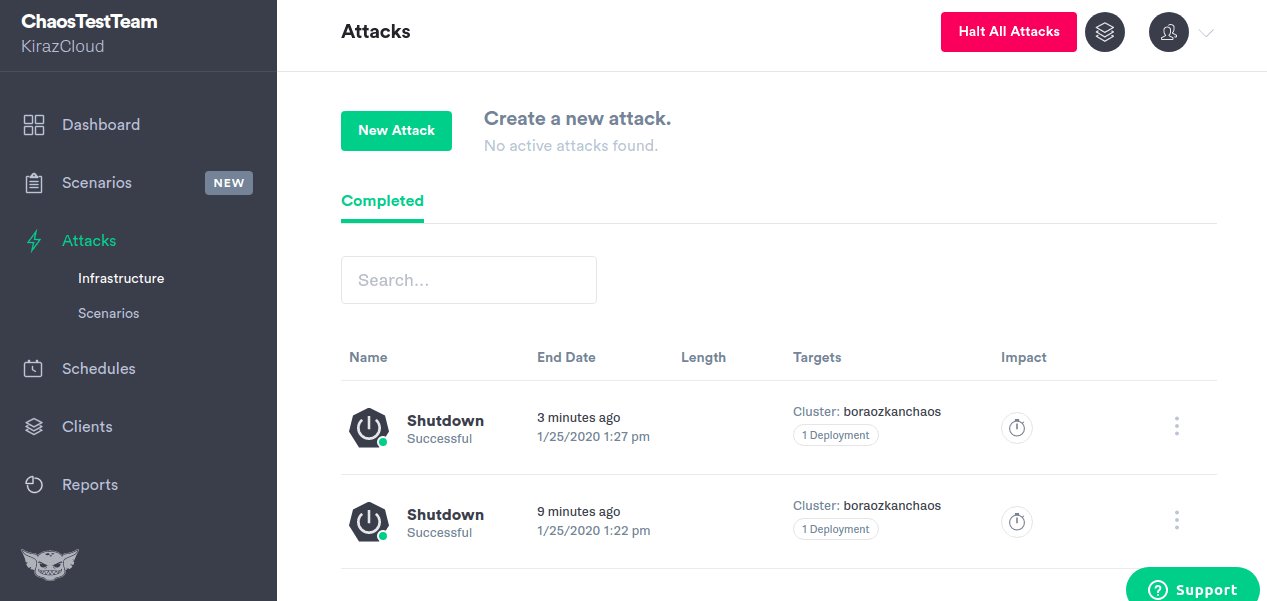
Características do Gremlin:
- Instala o agente leve em seus hosts ou contêineres para injetar falhas
- Fornece mais de 10 modos de ataque de infraestrutura diferentes
- Os gremlins de estado permitem que você manipule a hora do sistema, desligue ou reinicie hosts e elimine processadores.
- Os gremlins de rede podem injetar latência para introduzir perda de pacotes ou descartar o tráfego.
- Os ataques da biblioteca Alfi do Gremlin podem ser configurados, iniciados e interrompidos por meio do aplicativo da web. API ou CLI
- Permite que você alveje o raio de explosão que deseja atacar com precisão
- Permite interromper todos os ataques e reverter o sistema para um estado estável
Steadybit
Steadybit visa reduzir o tempo de inatividade de forma proativa e fornece visibilidade dos problemas do sistema. Você pode executar essa ferramenta localmente em sua infraestrutura ou nuvem como serviço (SaaS).
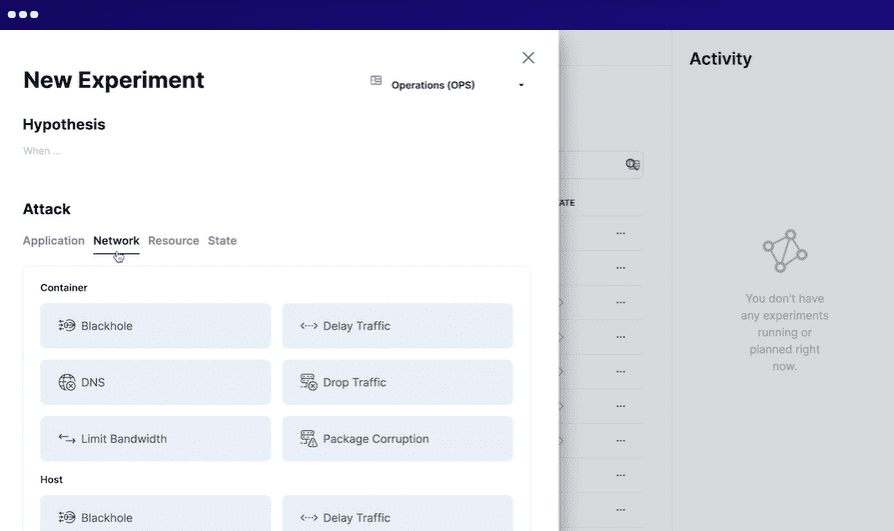
Para usar o Steadybit, você define a situação, simula os experimentos, executa os experimentos simulados na produção e automatiza todos os experimentos. Ele executa agentes inteligentes em seu sistema para descobrir possíveis problemas e pontos fracos. Integra-se com vários sistemas com facilidade.
Conclusão
Vá em frente e seja corajoso o suficiente para aplicar os princípios da engenharia do caos e testar sua produção com as ferramentas mencionadas acima. Essas ferramentas ajudarão você a encontrar vários pontos fracos não identificados em seu sistema e o ajudarão a tornar seu sistema mais resiliente.