
O Apache Parquet oferece vários benefícios para armazenamento e recuperação de dados quando comparado a métodos tradicionais como CSV.
O formato Parquet foi projetado para processamento de dados mais rápido de tipos complexos. Neste artigo, falamos sobre como o formato Parquet é adequado para as crescentes necessidades de dados atuais.
Antes de nos aprofundarmos nos detalhes do formato Parquet, vamos entender o que são os dados CSV e os desafios que eles representam para o armazenamento de dados.
últimas postagens
O que é armazenamento CSV?
Todos nós já ouvimos muito sobre CSV (Comma Separated Values) – uma das formas mais comuns de organizar e formatar dados. O armazenamento de dados CSV é baseado em linhas. Os arquivos CSV são armazenados com extensão .csv. Podemos armazenar e abrir dados CSV usando Excel, Planilhas Google ou qualquer editor de texto. Os dados são facilmente visualizados assim que o arquivo é aberto.
Bem, isso não é bom – definitivamente não para um formato de banco de dados.
Além disso, à medida que o volume de dados cresce, torna-se difícil consultar, gerenciar e recuperar.
Aqui está um exemplo de dados armazenados em um arquivo .CSV:
EmpId,First name,Last name, Division 2012011,Sam,Butcher,IT 2013031,Mike,Johnson,Human Resource 2010052,Bill,Matthew,Architect 2010079,Jose,Brian,IT 2012120,Adam,James,Solutions
Se o visualizarmos no Excel, podemos ver uma estrutura linha-coluna como abaixo:
Desafios com armazenamento CSV
Os armazenamentos baseados em linha, como CSV, são adequados para operações de criação, atualização e exclusão.
E o Read in CRUD, então?
Imagine um milhão de linhas no arquivo .csv acima. Levaria um tempo razoável para abrir o arquivo e pesquisar os dados que você está procurando. Não tão legal. A maioria dos provedores de nuvem, como a AWS, cobra das empresas com base na quantidade de dados digitalizados ou armazenados – novamente, os arquivos CSV consomem muito espaço.
O armazenamento CSV não tem uma opção exclusiva para armazenar metadados, tornando a verificação de dados uma tarefa tediosa.
Então, qual é a solução econômica e ideal para realizar todas as operações CRUD? Vamos explorar.
O que é o armazenamento de dados Parquet?
Parquet é um formato de armazenamento de código aberto para armazenar dados. É amplamente utilizado nos ecossistemas Hadoop e Spark. Os arquivos Parquet são armazenados como extensão .parquet.
Parquet é um formato altamente estruturado. Ele também pode ser usado para otimizar dados brutos complexos presentes em massa em data lakes. Isso pode reduzir significativamente o tempo de consulta.
O Parquet torna o armazenamento de dados eficiente e a recuperação mais rápida devido a uma combinação de formatos de armazenamento baseados em linhas e colunas (híbridos). Nesse formato, os dados são particionados horizontalmente e verticalmente. O formato Parquet também elimina em grande parte a sobrecarga de análise.
O formato restringe o número geral de operações de E/S e, em última análise, o custo.
O Parquet também armazena os metadados, que armazenam informações sobre dados como o esquema de dados, número de valores, localização das colunas, valor mínimo, valor máximo número de grupos de linhas, tipo de codificação, etc. Os metadados são armazenados em diferentes níveis no arquivo , tornando o acesso aos dados mais rápido.
No acesso baseado em linha, como CSV, a recuperação de dados leva tempo, pois a consulta precisa navegar por cada linha e obter os valores de coluna específicos. Com o armazenamento Parquet, todas as colunas necessárias podem ser acessadas de uma só vez.
Resumindo,
- Parquet é baseado na estrutura colunar para armazenamento de dados
- É um formato de dados otimizado para armazenar dados complexos em massa em sistemas de armazenamento
- O formato Parquet inclui vários métodos para compactação e codificação de dados
- Reduz significativamente o tempo de verificação de dados e o tempo de consulta e ocupa menos espaço em disco em comparação com outros formatos de armazenamento, como CSV
- Minimiza o número de operações de E/S, reduzindo o custo de armazenamento e execução de consultas
- Inclui metadados que facilitam a localização de dados
- Fornece suporte de código aberto
Formato de dados do parquet
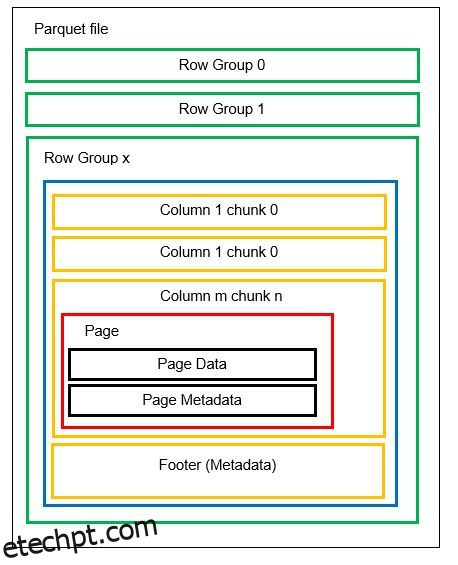
Antes de entrar em um exemplo, vamos entender mais detalhadamente como os dados são armazenados no formato Parquet:
Podemos ter várias partições horizontais conhecidas como grupos de linhas em um arquivo. Dentro de cada grupo de linhas, o particionamento vertical é aplicado. As colunas são divididas em vários blocos de coluna. Os dados são armazenados como páginas dentro dos blocos de coluna. Cada página contém os valores de dados codificados e metadados. Como mencionamos anteriormente, os metadados de todo o arquivo também são armazenados no rodapé do arquivo no nível do grupo Row.
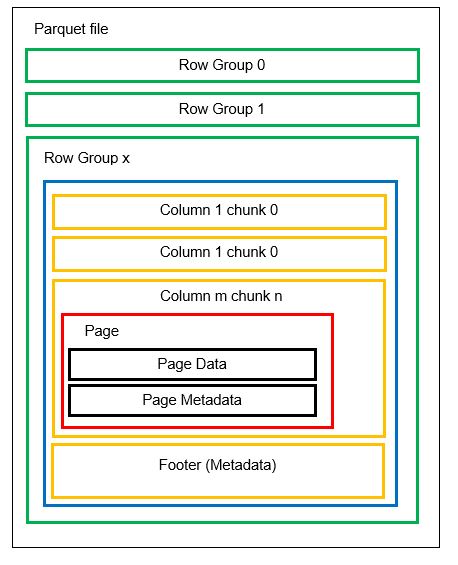
Como os dados são divididos em blocos de coluna, também é fácil adicionar novos dados codificando os novos valores em um novo bloco e arquivo. Os metadados são atualizados para os arquivos e grupos de linhas afetados. Assim, podemos dizer que o Parquet é um formato flexível.
O Parquet oferece suporte nativo à compactação de dados usando técnicas de compactação de página e codificação de dicionário. Vejamos um exemplo simples de compactação de dicionário:
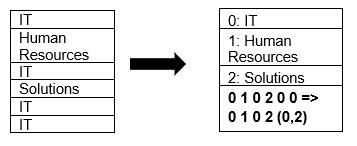
Observe que no exemplo acima, vemos a divisão de TI 4 vezes. Assim, ao armazenar no dicionário, o formato codifica os dados com outro valor fácil de armazenar (0,1,2…) junto com o número de vezes que é repetido continuamente – IT, IT é alterado para 0,2 para salvar mais espaço. Consultar dados compactados leva menos tempo.
Comparação direta
Agora que temos uma boa ideia de como são os formatos CSV e Parquet, é hora de algumas estatísticas para comparar os dois formatos:
CSV
Parquet
Formato de armazenamento baseado em linha.
Um híbrido de formatos de armazenamento baseado em linha e em coluna.
Ele consome muito espaço, pois nenhuma opção de compactação padrão está disponível. Por exemplo, um arquivo de 1 TB ocupará o mesmo espaço quando armazenado no Amazon S3 ou em qualquer outra nuvem.
Compacta os dados durante o armazenamento, consumindo assim menos espaço. Um arquivo de 1 TB armazenado no formato Parquet ocupará apenas 130 GB de espaço.
O tempo de execução da consulta é lento devido à pesquisa baseada em linha. Para cada coluna, cada linha de dados deve ser recuperada.
O tempo de consulta é cerca de 34 vezes mais rápido devido ao armazenamento baseado em colunas e à presença de metadados.
Mais dados devem ser verificados por consulta.
Cerca de 99% menos dados são verificados para a execução da consulta, otimizando assim o desempenho.
A maioria dos dispositivos de armazenamento cobra com base no espaço de armazenamento, portanto, o formato CSV significa alto custo de armazenamento.
Menor custo de armazenamento, pois os dados são armazenados em formato compactado e codificado.
O esquema de arquivo deve ser inferido (levando a erros) ou fornecido (tedioso).
O esquema de arquivo é armazenado nos metadados.
O formato é adequado para tipos de dados simples.
Parquet é adequado mesmo para tipos complexos como esquemas aninhados, matrizes, dicionários.
Conclusão 👩💻
Vimos através de exemplos que o Parquet é mais eficiente que o CSV em termos de custo, flexibilidade e desempenho. É um mecanismo eficaz para armazenar e recuperar dados, especialmente quando o mundo inteiro está se movendo em direção ao armazenamento em nuvem e à otimização do espaço. Todas as principais plataformas, como Azure, AWS e BigQuery, são compatíveis com o formato Parquet.