
A fragmentação de banco de dados é uma técnica para obter escalabilidade horizontal em sistemas de grande escala.
Quase todos os sistemas do mundo real consistem em um servidor de banco de dados que recebe muitas solicitações de leitura e uma quantidade não desprezível de solicitações de gravação. Isso pode sobrecarregar o servidor e prejudicar o desempenho do sistema.
Para mitigar tais impactos e melhorar o desempenho de um sistema, existem abordagens como replicação de banco de dados e sharding de banco de dados. Neste guia, primeiro exploraremos as técnicas para melhorar o desempenho do sistema, incluindo:
- Escalando o servidor de banco de dados
- Replicação de banco de dados
- particionamento horizontal
Depois de discutir essas técnicas, aprenderemos como funciona a fragmentação do banco de dados e também veremos as vantagens e limitações dessa abordagem.
Vamos começar!
últimas postagens
Técnicas para melhorar o desempenho do sistema
Vamos começar discutindo técnicas para melhorar o desempenho do sistema quando há gargalos devido ao servidor de banco de dados:
#1. Escalando o servidor de banco de dados
Aumentar a instância do servidor de banco de dados pode parecer uma abordagem direta para melhorar o desempenho do sistema. Isso inclui aumentar o poder de processamento, adicionar mais RAM e coisas do gênero.
No entanto, esta técnica vem com a seguinte limitação. Não podemos ter um servidor com capacidade infinita de armazenamento e processamento. E além de um certo limite, obtemos retornos decrescentes.
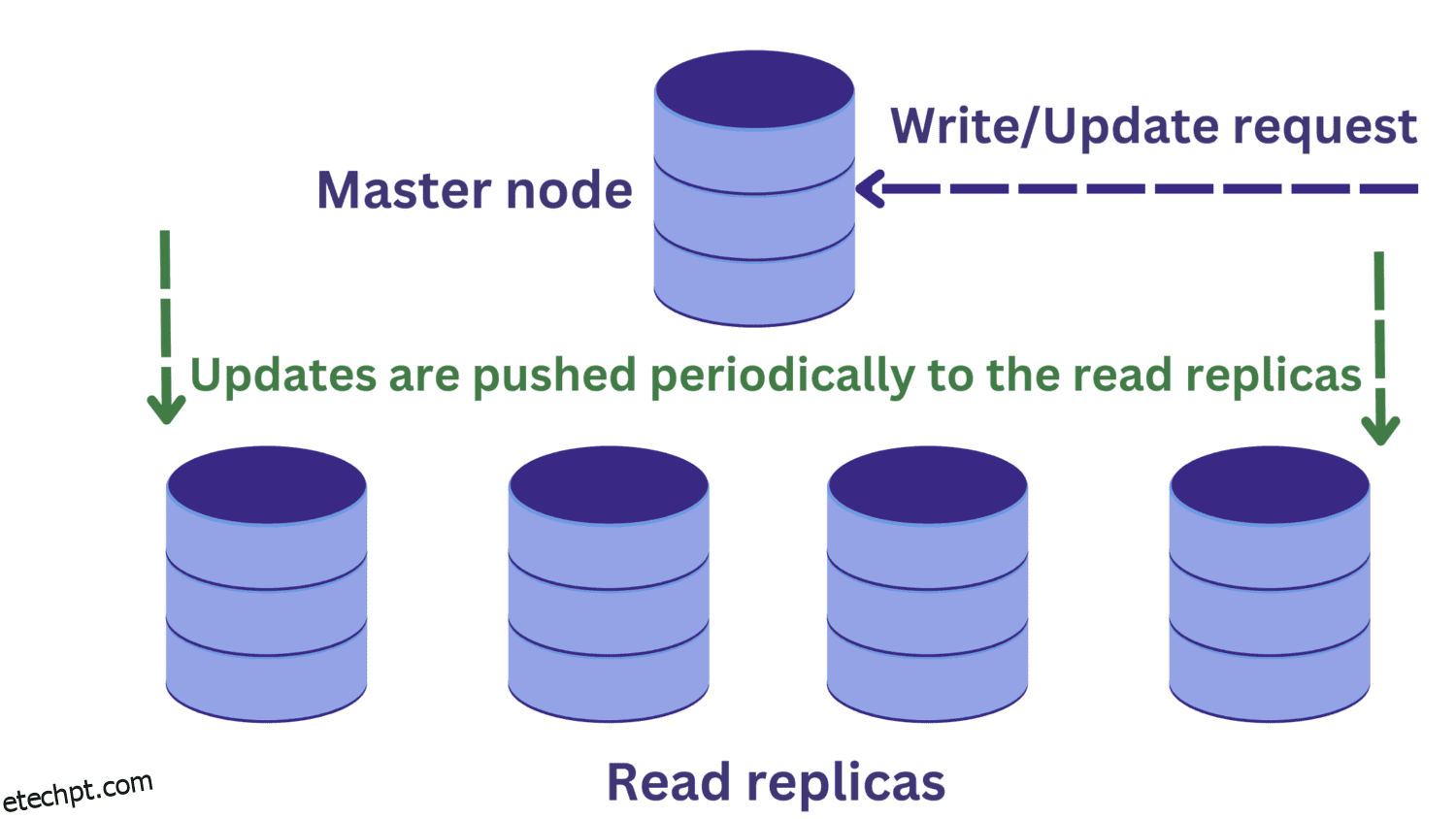
#2. Replicação de banco de dados
Quando a sobrecarga da instância do servidor de banco de dados ocorre devido a solicitações recebidas, podemos considerar a replicação do banco de dados.
Na replicação do banco de dados, temos um nó mestre que normalmente recebe solicitações de gravação. Existem várias réplicas de leitura.
Isso melhora a disponibilidade e reduz a sobrecarga do sistema. Agora podemos processar várias consultas em paralelo, pois as solicitações de leitura podem ser roteadas para uma das réplicas de leitura.
Mas isso introduz outro problema. As solicitações de gravação para o nó principal podem alterar os dados e essas atualizações são periodicamente propagadas para as réplicas de leitura.
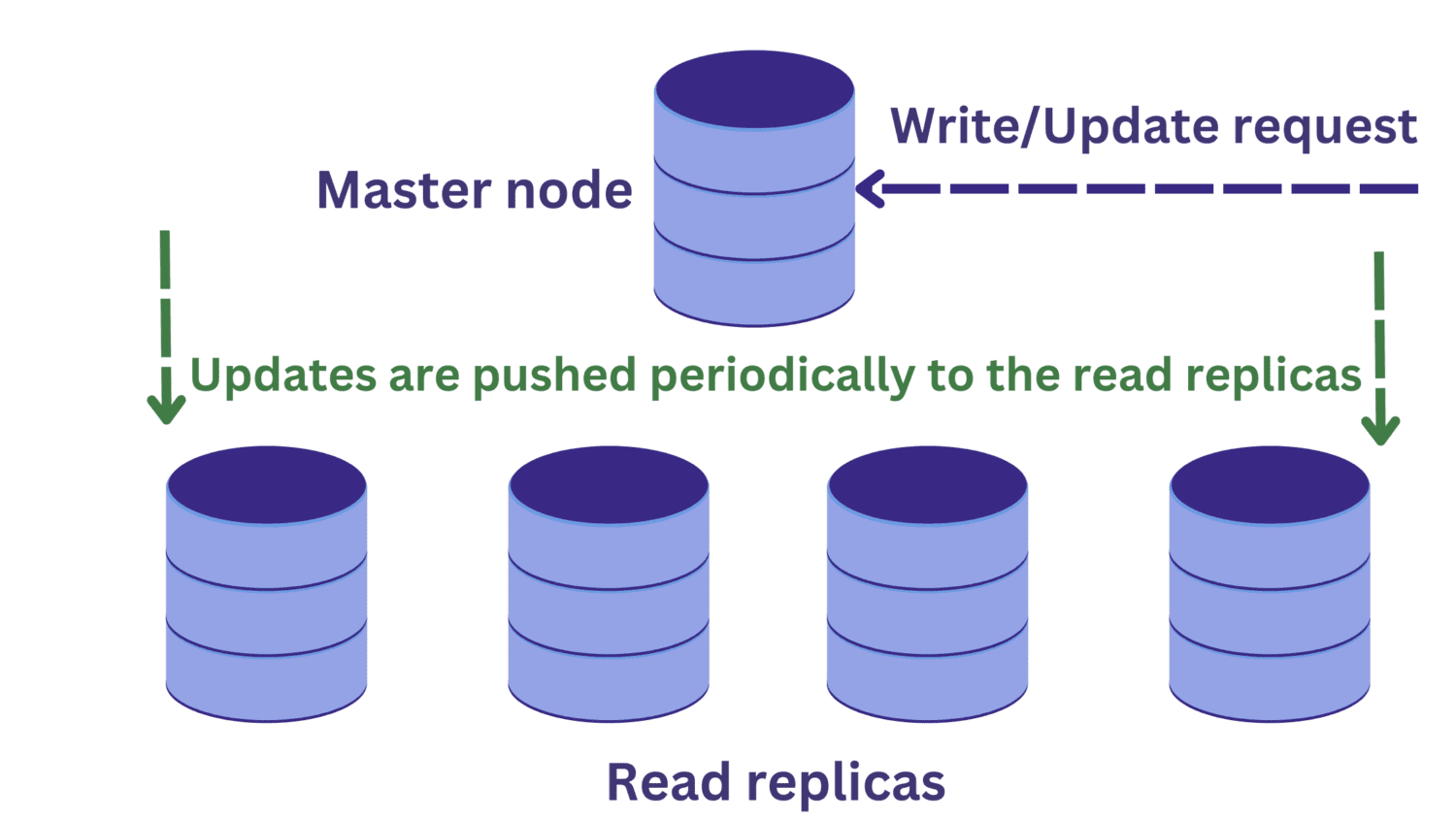
Suponha que haja uma solicitação de leitura para uma das réplicas de leitura ao mesmo tempo em que uma operação de gravação está em andamento no nó mestre.
As alterações no nó mestre ainda não terão se propagado para as réplicas de leitura. Nesse caso, podemos estar lendo dados desatualizados, o que não é desejável.
#3. Particionamento horizontal
O particionamento horizontal é outra técnica para otimizar o desempenho do sistema. Podemos ter uma única tabela grande com bilhões de linhas (como uma tabela de clientes e dados de transações).
As operações de leitura de tal tabela de banco de dados são mais lentas. Mas usando o particionamento horizontal, a única tabela grande agora é dividida em várias partições (ou tabelas menores) das quais podemos ler. Bancos de dados relacionais, como o PostgreSQL, oferecem suporte nativo ao particionamento.
No entanto, todas as partições ainda estão dentro de uma única instância do servidor de banco de dados. A única diferença é que agora podemos ler as partições em vez de uma única tabela grande.
Portanto, quando há um aumento no número de solicitações recebidas, o servidor pode não ser capaz de suportar o aumento da demanda.
Como funciona a fragmentação do banco de dados?
Agora que discutimos as abordagens para melhorar o desempenho do sistema e suas limitações, vamos entender como funciona a fragmentação do banco de dados.
Na fragmentação, dividimos o único banco de dados grande em vários bancos de dados menores, cada um executando em uma instância do servidor de banco de dados. Cada um desses bancos de dados menores é chamado de fragmento. E cada fragmento contém um subconjunto exclusivo dos dados.
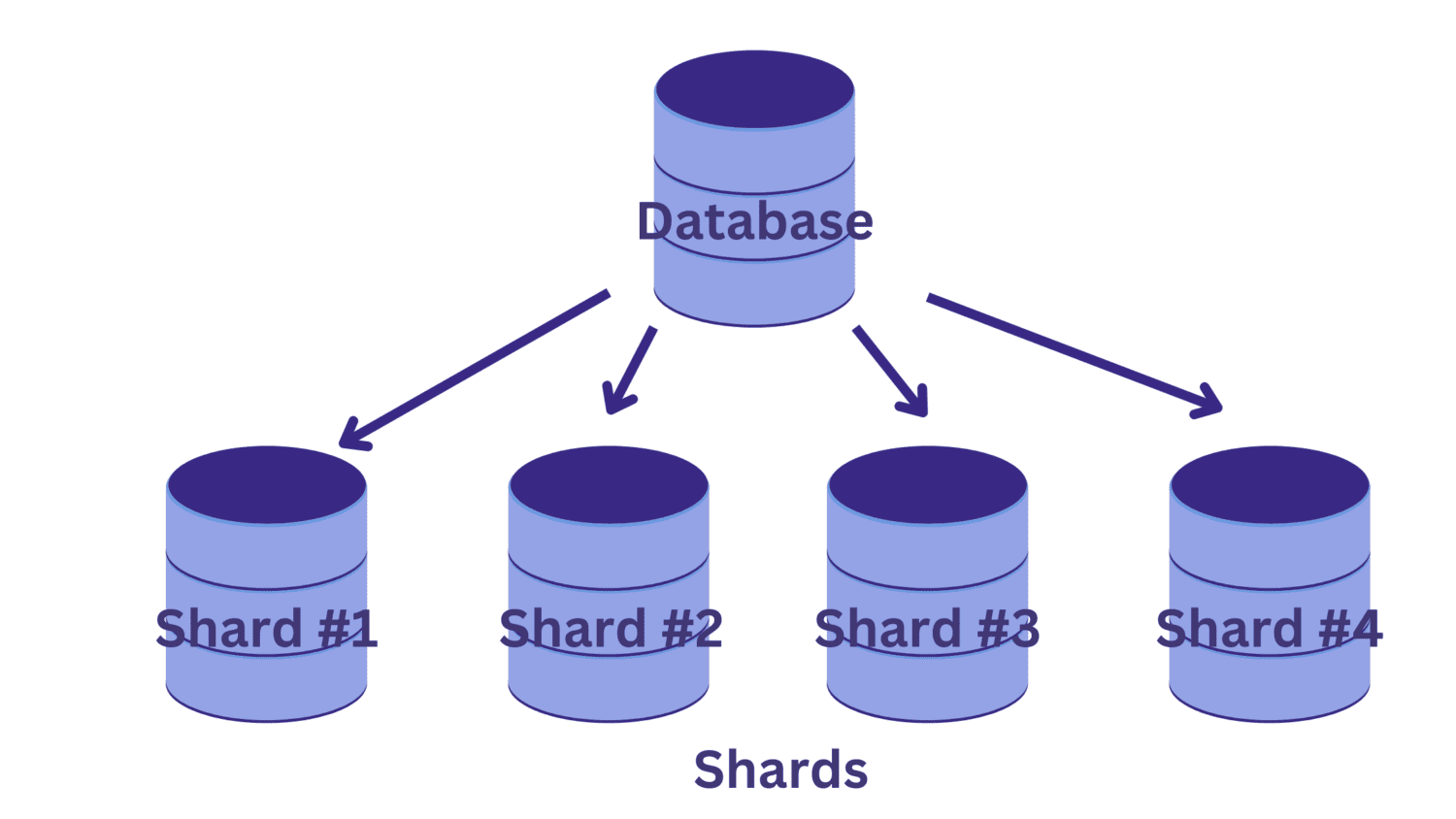
Mas como particionamos o banco de dados em fragmentos? E como determinamos quais das linhas vão para qual dos fragmentos?
🔑 Digite a chave de fragmentação.
Compreendendo a chave de fragmentação
Vamos entender o papel da chave de fragmentação.
A chave de fragmentação, que geralmente é uma coluna (ou uma combinação de colunas) na tabela do banco de dados, deve ser escolhida de forma que a distribuição dos dados seja uniforme entre vários fragmentos. Porque não queremos que um shard específico seja muito maior do que os outros shards.
Em um banco de dados que armazena dados sobre clientes e transações, o customer_ID é um bom candidato para a chave de fragmentação.
Depois de decidirmos a chave de fragmentação, podemos criar uma função de hash que determina qual das linhas vai para qual dos fragmentos.
Neste exemplo, digamos que precisamos dividir o banco de dados em cinco fragmentos (fragmento nº 0 ao fragmento nº 4) usando customer_ID como chave de fragmentação. Nesse caso, uma função de hashing simples é customer_ID % 5.
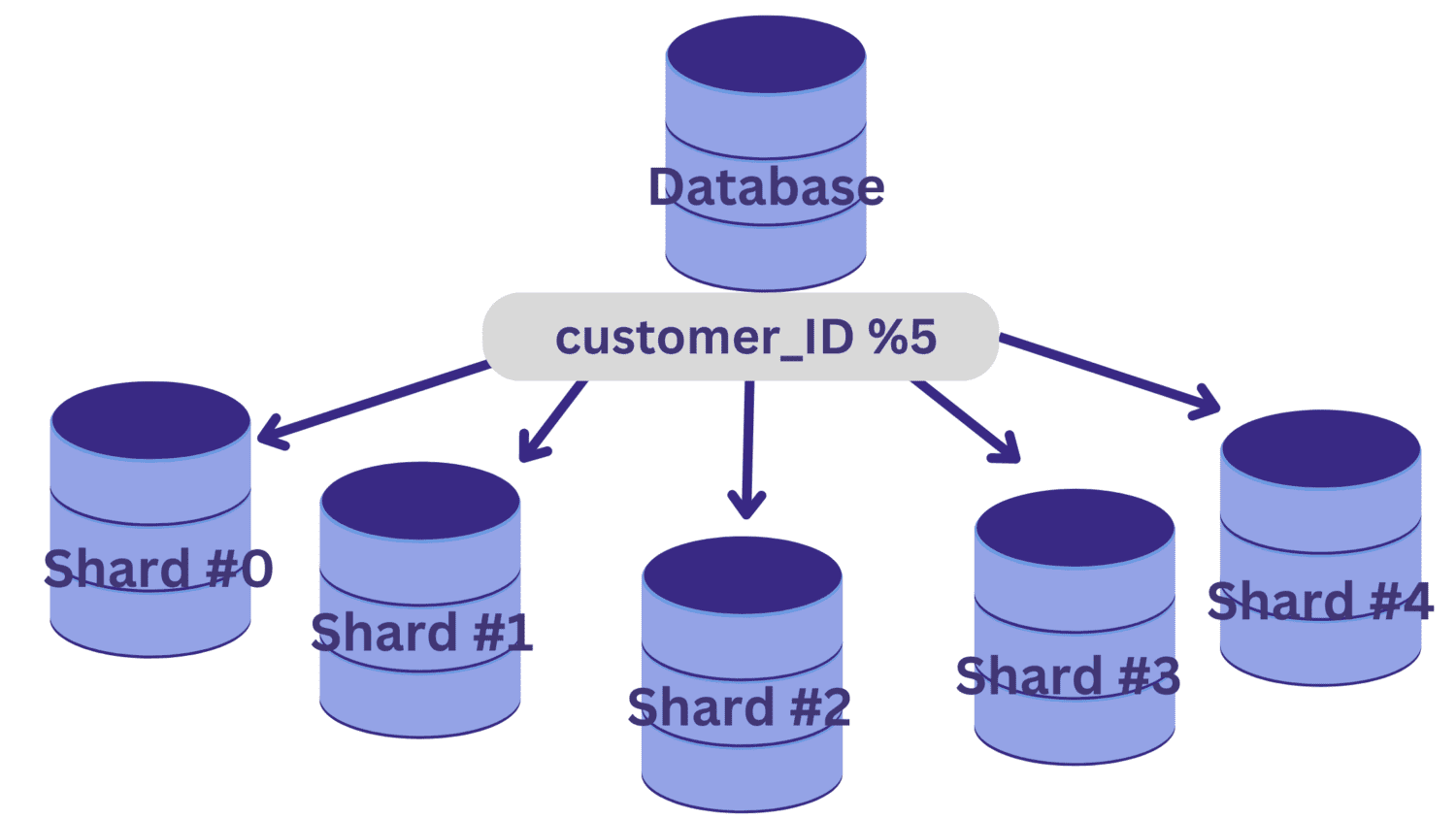
Todos os valores de customer_ID que deixam um resto de zero quando divididos por 5 serão mapeados para o estilhaço nº 0. E os valores de customer_ID que deixam restos de 1 a 4 serão mapeados para o estilhaço nº 1 ao estilhaço nº 4, respectivamente.
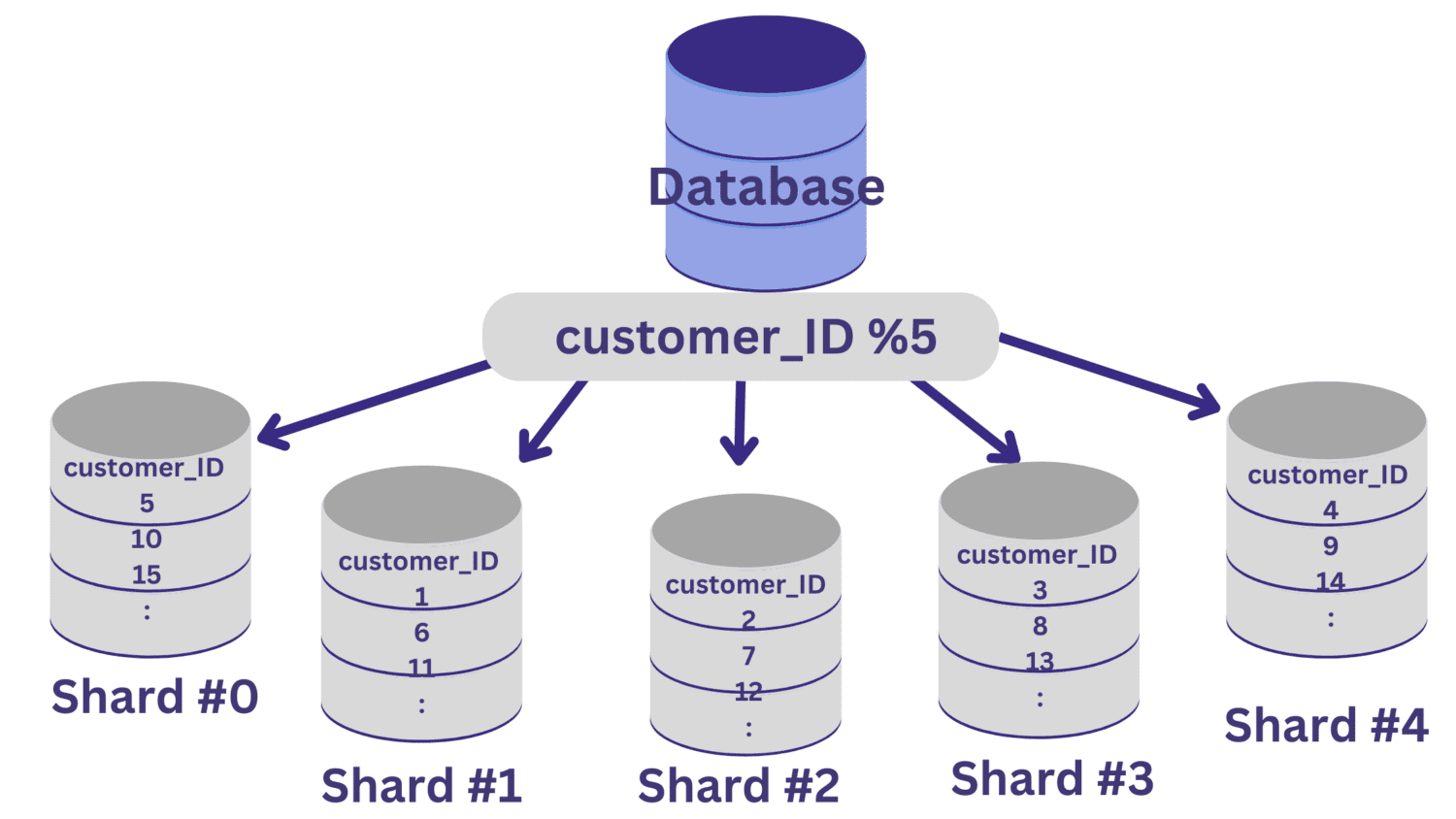
Após a fragmentação do banco de dados ser implementada dessa maneira, é importante ter uma camada de roteamento que roteie as solicitações recebidas para a fragmentação correta do banco de dados.
Vantagens da fragmentação de banco de dados
Aqui estão algumas das vantagens da fragmentação do banco de dados:
#1. Alta escalabilidade
Sempre é possível dividir um banco de dados maior em vários fragmentos menores. Portanto, a fragmentação do banco de dados nos permite escalar horizontalmente.
#2. Alta disponibilidade
Quando há uma única instância do servidor de banco de dados que lida com todas as solicitações recebidas, temos um único ponto de falha. Se o servidor de banco de dados estiver inativo, todo o aplicativo estará inativo.
Com a fragmentação do banco de dados, a probabilidade de todos os fragmentos do banco de dados ficarem inoperantes em um determinado instante é relativamente baixa. Portanto, se um fragmento específico estiver inativo, não poderemos processar solicitações de leitura para esse fragmento. Mas os outros estilhaços ainda podem processar as solicitações recebidas. Isso resulta em alta disponibilidade e maior tolerância a falhas.
Limitações da fragmentação do banco de dados
Agora vamos examinar algumas das limitações da fragmentação do banco de dados:
#1. Complexidade
Embora o sharding tenha vantagens em termos de escalabilidade e tolerância a falhas, ele introduz complexidade ao sistema.
Desde o mapeamento de registros para partições até a implementação da camada de roteamento para rotear consultas para os respectivos estilhaços, há uma complexidade considerável envolvida na fragmentação de bancos de dados.
#2. Resharding
Outra limitação do sharding é a necessidade de resharding.
Embora usemos a função hash para obter uma distribuição uniforme dos registros de dados, é possível que um dos fragmentos seja muito maior que os outros fragmentos e se esgote mais cedo. Nesse caso, temos que levar em conta o resharding (ou reshuffling), e isso vem com uma sobrecarga substancial.
#3. Executando consultas complexas
Quando você precisa executar consultas para análise que envolvem junções, você precisa usar registros de vários shards em oposição a um único banco de dados. Portanto, isso pode ser um desafio quando você precisa executar muitas consultas analíticas. Você pode contornar isso desnormalizando os bancos de dados, mas ainda requer algum esforço!
Conclusão
Vamos encerrar a discussão com um resumo do que aprendemos.
Ampliar o hardware nem sempre é ideal. Portanto, reforçar a instância do servidor não é recomendado. Também revisamos técnicas como replicação de banco de dados e particionamento horizontal e suas limitações.
Em seguida, aprendemos como a fragmentação do banco de dados funciona dividindo um grande banco de dados em fragmentos menores e fáceis de gerenciar. Discutimos como a chave de fragmentação deve ser escolhida com cuidado para obter partições uniformes e a necessidade de uma camada de roteamento para rotear as solicitações recebidas para o fragmento de banco de dados correto.
A fragmentação de banco de dados tem vantagens como alta disponibilidade e escalabilidade. Algumas das desvantagens incluem a complexidade de configurar o sharding e resharding quando um ou mais shards se esgotam.
Portanto, você pode considerar a fragmentação quando achar que as vantagens superam a complexidade introduzida pela fragmentação. A seguir, confira a comparação dos vários bancos de dados relacionais da AWS.