

Observando o desenvolvimento de software corporativo desde a primeira linha por duas décadas, a tendência inegável dos últimos anos é clara – mover bancos de dados para a nuvem.
Já participei de alguns projetos de migração, onde o objetivo era trazer o banco de dados on-premise existente para o banco de dados Amazon Web Services (AWS) Cloud. Embora com os materiais de documentação da AWS você aprenda como isso pode ser fácil, estou aqui para dizer que a execução de tal plano nem sempre é fácil e há casos em que pode falhar.
Neste post, abordarei a experiência do mundo real para o seguinte caso:
- A fonte: embora, em teoria, não importe realmente qual é a sua fonte (você pode usar uma abordagem muito semelhante para a maioria dos bancos de dados mais populares), o Oracle foi o sistema de banco de dados escolhido em grandes empresas por muitos anos e é aí que estará o meu foco.
- O Alvo: Não há razão para ser específico neste lado. Você pode escolher qualquer banco de dados de destino na AWS e a abordagem ainda será adequada.
- O Modo: Você pode ter uma atualização completa ou atualização incremental. Um carregamento de dados em lote (os estados de origem e destino são atrasados) ou (quase) carregamento de dados em tempo real. Ambos serão abordados aqui.
- A frequência: você pode querer uma migração única seguida de uma mudança completa para a nuvem ou exigir algum período de transição e ter os dados atualizados em ambos os lados simultaneamente, o que implica no desenvolvimento de sincronização diária entre o local e a AWS. O primeiro é mais simples e faz muito mais sentido, mas o último é solicitado com mais frequência e tem muito mais pontos de interrupção. Vou cobrir os dois aqui.
últimas postagens
Descrição do Problema
O requisito geralmente é simples:
Queremos começar a desenvolver serviços dentro da AWS, então copie todos os nossos dados para o banco de dados “ABC”. De forma rápida e simples. Precisamos usar os dados dentro da AWS agora. Mais tarde, descobriremos quais partes dos projetos de banco de dados devem ser alteradas para corresponder às nossas atividades.
Antes de prosseguir, há algo a considerar:
- Não pule para a ideia de “apenas copiar o que temos e lidar com isso depois” muito rápido. Quero dizer, sim, isso é o mais fácil que você pode fazer e será feito rapidamente, mas isso tem o potencial de criar um problema arquitetônico tão fundamental que será impossível corrigir posteriormente sem uma refatoração séria da maior parte da nova plataforma de nuvem . Imagine que o ecossistema da nuvem é completamente diferente do local. Vários novos serviços serão introduzidos ao longo do tempo. Naturalmente, as pessoas começarão a usar o mesmo de maneira muito diferente. Quase nunca é uma boa ideia replicar o estado local na nuvem de maneira 1:1. Pode ser no seu caso particular, mas certifique-se de verificar isso.
- Questione o requisito com algumas dúvidas significativas como:
- Quem será o usuário típico que utilizará a nova plataforma? Enquanto estiver no local, pode ser um usuário comercial transacional; na nuvem, pode ser um cientista de dados ou analista de data warehouse, ou o usuário principal dos dados pode ser um serviço (por exemplo, Databricks, Glue, modelos de aprendizado de máquina, etc.).
- Espera-se que os trabalhos regulares do dia a dia permaneçam mesmo após a transição para a nuvem? Se não, como se espera que eles mudem?
- Você planeja um crescimento substancial de dados ao longo do tempo? Provavelmente, a resposta é sim, já que esse costuma ser o motivo mais importante para migrar para a nuvem. Um novo modelo de dados deve estar pronto para isso.
- Espere que o usuário final pense em algumas consultas gerais antecipadas que o novo banco de dados receberá dos usuários. Isso definirá o quanto o modelo de dados existente deve mudar para permanecer relevante para o desempenho.
Configurando a migração
Depois que o banco de dados de destino é escolhido e o modelo de dados é discutido satisfatoriamente, a próxima etapa é familiarizar-se com o AWS Schema Conversion Tool. São várias as áreas em que esta ferramenta pode servir:
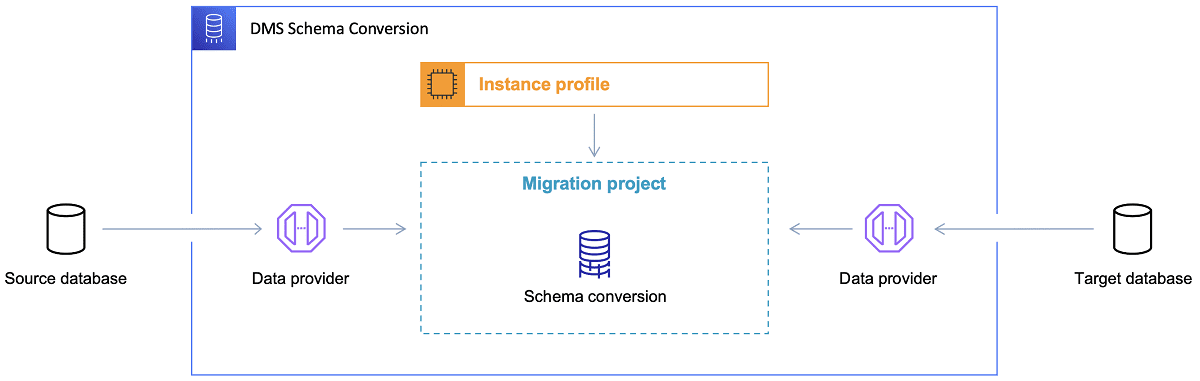 Referência: Documentação da AWS
Referência: Documentação da AWS
Agora, existem algumas dicas para usar a ferramenta de conversão de esquema.
Em primeiro lugar, quase nunca deve ser o caso de usar a saída diretamente. Eu consideraria mais como resultados de referência, de onde você fará seus ajustes com base no seu entendimento e finalidade dos dados e na forma como os dados serão usados na nuvem.
Em segundo lugar, anteriormente, as tabelas provavelmente foram selecionadas por usuários que esperavam resultados curtos e rápidos sobre alguma entidade de domínio de dados concreta. Mas agora, os dados podem ser selecionados para fins analíticos. Por exemplo, os índices de banco de dados que funcionavam anteriormente no banco de dados local agora serão inúteis e definitivamente não melhorarão o desempenho do sistema de banco de dados relacionado a esse novo uso. Da mesma forma, você pode querer particionar os dados de forma diferente no sistema de destino, como era antes no sistema de origem.
Além disso, pode ser bom considerar fazer algumas transformações de dados durante o processo de migração, o que basicamente significa alterar o modelo de dados de destino para algumas tabelas (para que não sejam mais cópias 1:1). Posteriormente, as regras de transformação precisarão ser implementadas na ferramenta de migração.
Se os bancos de dados de origem e destino forem do mesmo tipo (por exemplo, Oracle on-premise vs. Oracle in AWS, PostgreSQL vs. Aurora Postgresql, etc.), então é melhor usar uma ferramenta de migração dedicada que o banco de dados concreto suporte nativamente ( por exemplo, exportações e importações de data pump, Oracle Goldengate, etc.).
No entanto, na maioria dos casos, os bancos de dados de origem e destino não serão compatíveis e, então, a ferramenta óbvia de escolha será o AWS Database Migration Service.
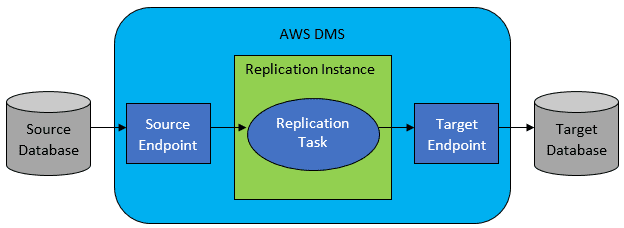 Referência: Documentação da AWS
Referência: Documentação da AWS
O AWS DMS basicamente permite configurar uma lista de tarefas no nível da tabela, que definirá:
- Qual é o banco de dados de origem exato e a tabela para se conectar?
- Especificações de instrução que serão usadas para obter os dados para a tabela de destino.
- Ferramentas de transformação (se houver), definindo como os dados de origem devem ser mapeados nos dados da tabela de destino (se não for 1:1).
- Qual é o banco de dados e a tabela de destino exatos para carregar os dados?
A configuração das tarefas DMS é feita em algum formato amigável como JSON.
Agora, no cenário mais simples, tudo o que você precisa fazer é executar os scripts de implantação no banco de dados de destino e iniciar a tarefa DMS. Mas há muito mais nisso.
Migração completa de dados única

O caso mais fácil de executar é quando a solicitação é mover todo o banco de dados uma vez para o banco de dados de nuvem de destino. Então, basicamente, tudo o que é necessário fazer será o seguinte:
Se a configuração do DMS for bem feita, nada de ruim acontecerá neste cenário. Cada tabela de origem será selecionada e copiada para o banco de dados de destino da AWS. A única preocupação será com o desempenho da atividade e com o dimensionamento correto em todas as etapas para que não haja falhas por falta de espaço de armazenamento.
Sincronização diária incremental

É aqui que as coisas começam a ficar complicadas. Quero dizer, se o mundo fosse ideal, provavelmente funcionaria bem o tempo todo. Mas o mundo nunca é ideal.
O DMS pode ser configurado para operar em dois modos:
- Carga total – modo padrão descrito e usado acima. As tarefas do DMS são iniciadas quando você as inicia ou quando são agendadas para iniciar. Depois de concluídas, as tarefas do DMS são concluídas.
- Change Data Capture (CDC) – neste modo, a tarefa DMS é executada continuamente. O DMS examina o banco de dados de origem em busca de uma alteração no nível da tabela. Se a alteração ocorrer, ele imediatamente tenta replicar a alteração no banco de dados de destino com base na configuração dentro da tarefa DMS relacionada à tabela alterada.
Ao optar pelo CDC, você precisa fazer outra escolha – ou seja, como o CDC extrairá as alterações delta do banco de dados de origem.
#1. Leitor de Redo Logs da Oracle
Uma opção é escolher o leitor de redo logs de banco de dados nativo da Oracle, que o CDC pode utilizar para obter os dados alterados e, com base nas alterações mais recentes, replicar as mesmas alterações no banco de dados de destino.
Embora isso possa parecer uma escolha óbvia ao lidar com o Oracle como fonte, há um problema: o leitor de redo logs do Oracle utiliza o cluster Oracle de origem e, portanto, afeta diretamente todas as outras atividades em execução no banco de dados (na verdade, ele cria sessões ativas diretamente no o banco de dados).
Quanto mais Tarefas DMS você tiver configurado (ou quanto mais clusters DMS em paralelo), mais você provavelmente precisará aumentar o tamanho do cluster Oracle – basicamente, ajuste a escala vertical de seu cluster primário de banco de dados Oracle. Isso com certeza influenciará nos custos totais da solução, ainda mais se a sincronização diária estiver prestes a ficar com o projeto por um longo período de tempo.
#2. Mineiro de log do AWS DMS
Ao contrário da opção acima, esta é uma solução nativa da AWS para o mesmo problema. Nesse caso, o DMS não afeta o banco de dados Oracle de origem. Em vez disso, ele copia os redo logs do Oracle para o cluster DMS e faz todo o processamento lá. Embora economize recursos do Oracle, é a solução mais lenta, pois envolve mais operações. E também, como se pode supor facilmente, o leitor personalizado para redo logs do Oracle provavelmente é mais lento em seu trabalho como o leitor nativo do Oracle.
Dependendo do tamanho do banco de dados de origem e do número de alterações diárias, na melhor das hipóteses, você pode acabar com uma sincronização incremental quase em tempo real dos dados do banco de dados Oracle local para o banco de dados da nuvem AWS.
Em qualquer outro cenário, ainda não estará perto da sincronização em tempo real, mas você pode tentar chegar o mais próximo possível do atraso aceito (entre a origem e o destino) ajustando a configuração de desempenho e o paralelismo dos clusters de origem e destino ou experimentando a quantidade de tarefas do DMS e sua distribuição entre as instâncias do CDC.
E talvez você queira saber quais alterações na tabela de origem são suportadas pelo CDC (como a adição de uma coluna, por exemplo), porque nem todas as alterações possíveis são suportadas. Em alguns casos, a única maneira é fazer a alteração da tabela de destino manualmente e reiniciar a tarefa do CDC do zero (perdendo todos os dados existentes no banco de dados de destino ao longo do caminho).
Quando as coisas dão errado, não importa o que aconteça

Aprendi isso da maneira mais difícil, mas há um cenário específico conectado ao DMS em que a promessa de replicação diária é difícil de alcançar.
O DMS pode processar os redo logs apenas com alguma velocidade definida. Não importa se há mais instâncias de DMS executando suas tarefas. Ainda assim, cada instância do DMS lê os redo logs apenas com uma única velocidade definida, e cada uma delas deve lê-los inteiros. Não importa se você usa redo logs da Oracle ou o minerador de logs da AWS. Ambos têm esse limite.
Se o banco de dados de origem incluir um grande número de alterações em um dia em que os logs de redo do Oracle ficam muito grandes (como 500 GB ou mais) todos os dias, o CDC simplesmente não funcionará. A replicação não será concluída antes do final do dia. Ele trará algum trabalho não processado para o dia seguinte, onde já está esperando um novo conjunto de alterações a serem replicadas. A quantidade de dados não processados só aumentará de dia para dia.
Neste caso particular, o CDC não era uma opção (depois de muitos testes de desempenho e tentativas que executamos). A única maneira de garantir que pelo menos todas as alterações delta do dia atual sejam replicadas no mesmo dia era abordá-lo assim:
- Separe tabelas realmente grandes que não são usadas com tanta frequência e replique-as apenas uma vez por semana (por exemplo, durante os finais de semana).
- Configure a replicação de tabelas não tão grandes, mas ainda grandes, para serem divididas entre várias tarefas do DMS; uma tabela acabou sendo migrada por 10 ou mais tarefas DMS separadas em paralelo, garantindo que a divisão de dados entre as tarefas DMS seja distinta (codificação personalizada envolvida aqui) e execute-as diariamente.
- Adicione mais (até 4 neste caso) instâncias do DMS e divida as tarefas do DMS entre elas uniformemente, o que significa não apenas pelo número de tabelas, mas também pelo tamanho.
Basicamente, usamos o modo de carga total do DMS para replicar dados diários porque essa era a única maneira de obter pelo menos a conclusão da replicação de dados no mesmo dia.
Não é uma solução perfeita, mas ainda existe e, mesmo depois de muitos anos, ainda funciona da mesma maneira. Então, talvez não seja uma solução tão ruim, afinal. 😃