
Este artigo menciona e expõe algumas das melhores bibliotecas python para cientistas de dados e a equipe de aprendizado de máquina.
Python é uma linguagem ideal usada nestes dois campos principalmente pelas bibliotecas que oferece.
Isso se deve aos aplicativos das bibliotecas Python, como E/S de entrada/saída de dados e análise de dados, entre outras operações de manipulação de dados que cientistas de dados e especialistas em aprendizado de máquina usam para manipular e explorar dados.
últimas postagens
Bibliotecas Python, o que são?
Uma biblioteca Python é uma extensa coleção de módulos internos contendo código pré-compilado, incluindo classes e métodos, eliminando a necessidade do desenvolvedor de implementar o código do zero.
Importância do Python na Ciência de Dados e Aprendizado de Máquina
Python tem as melhores bibliotecas para uso por especialistas em aprendizado de máquina e ciência de dados.
Sua sintaxe é fácil, tornando eficiente a implementação de algoritmos complexos de aprendizado de máquina. Além disso, a sintaxe simples reduz a curva de aprendizado e facilita o entendimento.
O Python também suporta o desenvolvimento rápido de protótipos e testes suaves de aplicativos.
A grande comunidade do Python é útil para os cientistas de dados buscarem prontamente soluções para suas consultas quando necessário.
Quão úteis são as bibliotecas Python?
As bibliotecas Python são fundamentais para a criação de aplicativos e modelos em aprendizado de máquina e ciência de dados.
Essas bibliotecas ajudam muito o desenvolvedor com a reutilização de código. Portanto, você pode importar uma biblioteca relevante que implemente um recurso específico em seu programa, além de reinventar a roda.
Bibliotecas Python usadas em Machine Learning e Data Science
Especialistas em ciência de dados recomendam várias bibliotecas Python com as quais os entusiastas da ciência de dados devem estar familiarizados. Dependendo de sua relevância no aplicativo, os especialistas em aprendizado de máquina e ciência de dados aplicam diferentes bibliotecas Python categorizadas em bibliotecas para implantação de modelos, mineração e extração de dados, processamento de dados e visualização de dados.
Este artigo identifica algumas bibliotecas Python comumente usadas em ciência de dados e aprendizado de máquina.
Vamos olhar para eles agora.
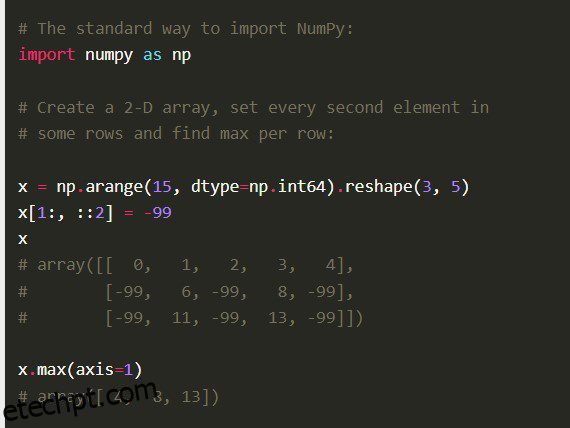
Numpy
A biblioteca Numpy Python, também Numerical Python Code na íntegra, é construída com código C bem otimizado. Os Cientistas de Dados o preferem por seus profundos cálculos matemáticos e cálculos científicos.
Características
O Numpy vem com outros recursos abrangentes, como vetorização de operações matemáticas, indexação e conceitos-chave na implementação de matrizes e matrizes.
Pandas
O Pandas é uma famosa biblioteca em Machine Learning que fornece estruturas de dados de alto nível e várias ferramentas para analisar conjuntos de dados massivos com facilidade e eficácia. Com muito poucos comandos, esta biblioteca pode traduzir operações complexas com dados.
Vários métodos embutidos que podem agrupar, indexar, recuperar, dividir, reestruturar dados e filtrar conjuntos antes de inseri-los em tabelas únicas e multidimensionais; compõe esta biblioteca.
Principais recursos da biblioteca Pandas
É altamente eficiente por sua boa funcionalidade de análise de dados e alta flexibilidade.
Matplotlib
A biblioteca Python gráfica 2D do Matplotlib pode manipular facilmente dados de várias fontes. As visualizações que ele cria são estáticas, animadas e interativas que o usuário pode ampliar, tornando-o eficiente para visualizações e criação de gráficos. Também permite a personalização do layout e estilo visual.
Sua documentação é de código aberto e oferece uma coleção profunda de ferramentas necessárias para implementação.
O Matplotlib importa classes auxiliares para implementar ano, mês, dia e semana, tornando eficiente a manipulação de dados de séries temporais.
Scikit-learn
Se você está considerando uma biblioteca para ajudá-lo a trabalhar com dados complexos, o Scikit-learn deve ser sua biblioteca ideal. Especialistas em aprendizado de máquina usam amplamente o Scikit-learn. A biblioteca está associada a outras bibliotecas como NumPy, SciPy e matplotlib. Ele oferece algoritmos de aprendizado supervisionado e não supervisionado que podem ser usados para aplicações de produção.

Recursos da biblioteca Python Scikit-learn
A biblioteca Scikit-learn é eficiente na extração de recursos de conjuntos de dados de texto e imagem. Além disso, é possível verificar a precisão dos modelos supervisionados em dados não vistos. Seus inúmeros algoritmos disponíveis possibilitam a mineração de dados e outras tarefas de aprendizado de máquina.
SciPy
SciPy (Scientific Python Code) é uma biblioteca de aprendizado de máquina que fornece módulos aplicados a funções matemáticas e algoritmos amplamente aplicáveis. Seus algoritmos resolvem equações algébricas, interpolação, otimização, estatística e integração.
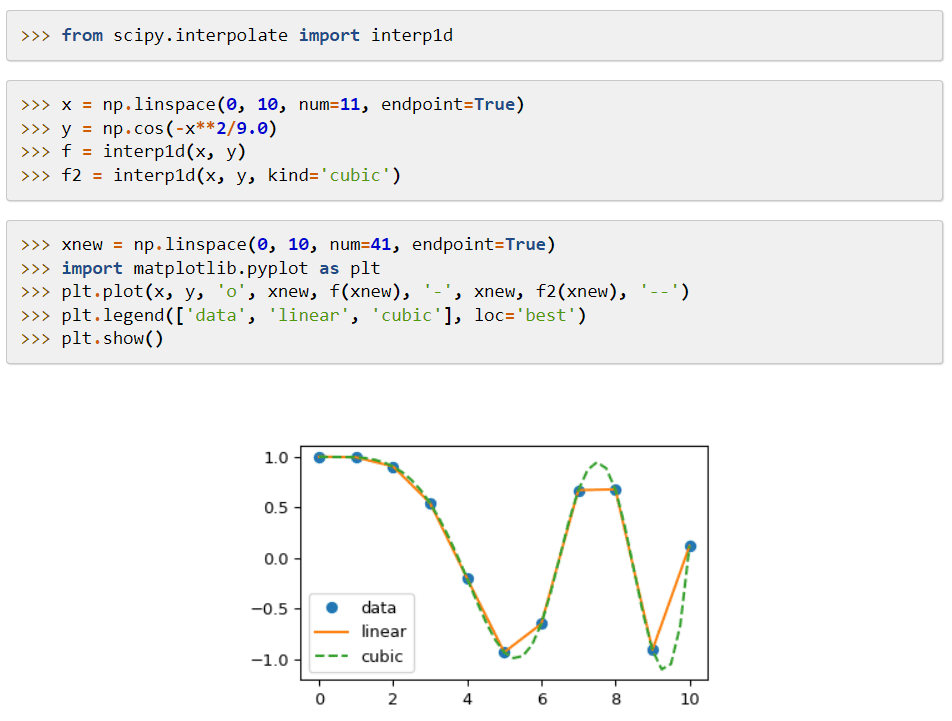
Sua principal característica é sua extensão ao NumPy, que adiciona ferramentas para resolver as funções matemáticas e fornece estruturas de dados como matrizes esparsas.
O SciPy usa comandos e classes de alto nível para manipular e visualizar dados. Seus sistemas de processamento de dados e protótipos o tornam uma ferramenta ainda mais eficaz.
Além disso, a sintaxe de alto nível do SciPy facilita o uso de programadores de qualquer nível de experiência.
A única desvantagem do SciPy é seu foco exclusivo em objetos numéricos e algoritmos; portanto, incapaz de oferecer qualquer função de plotagem.
PyTorch
Essa biblioteca diversificada de aprendizado de máquina implementa com eficiência cálculos de tensor com aceleração de GPU, criando gráficos computacionais dinâmicos e cálculos automáticos de gradientes. A biblioteca Torch, uma biblioteca de aprendizado de máquina de código aberto desenvolvida em C, cria a biblioteca PyTorch.

Os principais recursos incluem:
Você pode usar o PyTorch no desenvolvimento de aplicativos de PNL.
Keras
Keras é uma biblioteca Python de aprendizado de máquina de código aberto usada para experimentar redes neurais profundas.
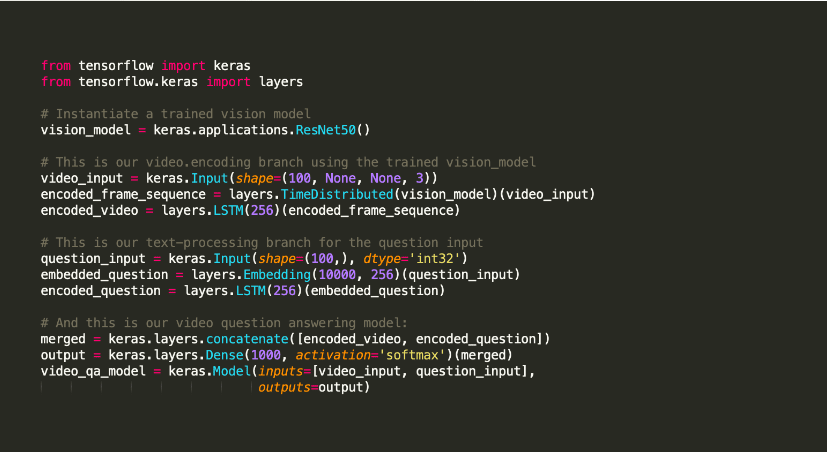
É famoso por oferecer utilitários que suportam tarefas como compilação de modelos e visualizações de gráficos, entre outras. Ele aplica o Tensorflow para seu back-end. Alternativamente, você pode usar Theano ou redes neurais como CNTK no back-end. Essa infraestrutura de back-end ajuda a criar gráficos computacionais usados para implementar operações.
Principais recursos da biblioteca
As aplicações do Keras incluem blocos de construção de redes neurais como camadas e objetivos, entre outras ferramentas que facilitam o trabalho com imagens e dados de texto.
marinho
Seaborn é outra ferramenta valiosa na visualização de dados estatísticos.
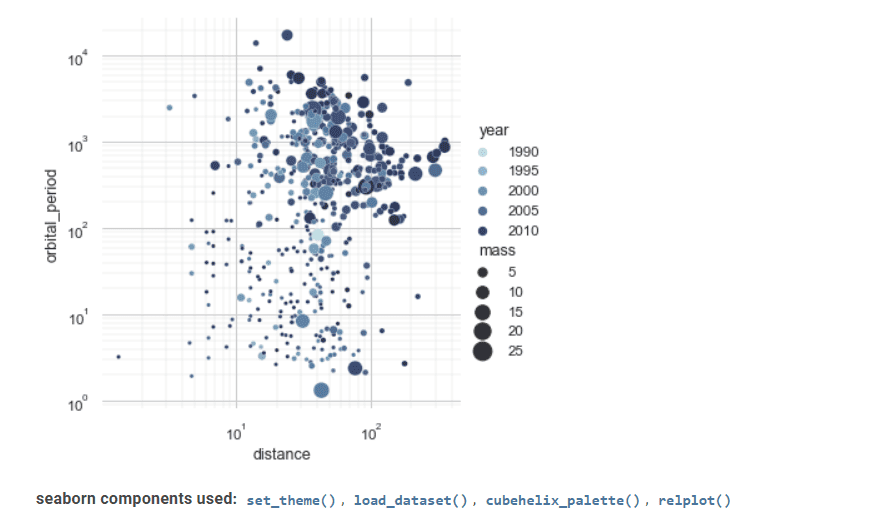
Sua interface avançada pode implementar desenhos gráficos estatísticos atraentes e informativos.
Tradicionalmente
Plotly é uma ferramenta de visualização 3D baseada na web construída na biblioteca Plotly JS. Ele tem amplo suporte para vários tipos de gráficos, como gráficos de linhas, gráficos de dispersão e minigráficos de tipos de caixa.
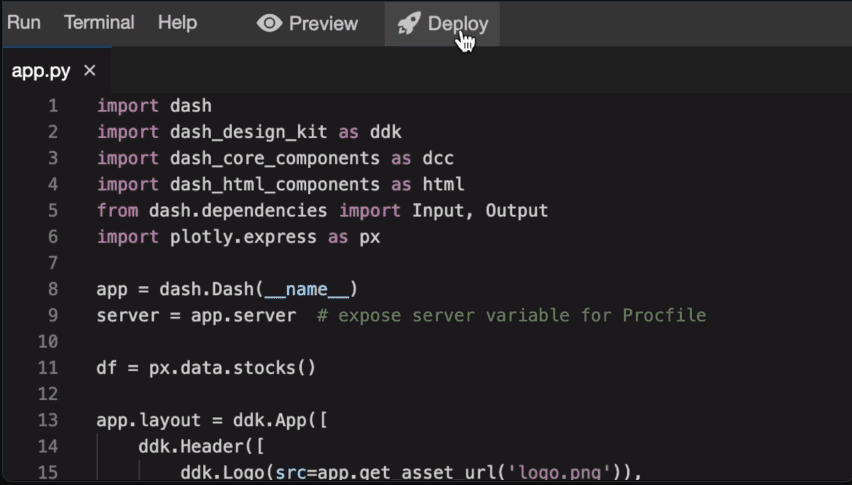
Sua aplicação inclui a criação de visualizações de dados baseadas na web em notebooks Jupyter.
Plotly é adequado para visualização porque pode apontar valores discrepantes ou anormalidades no gráfico com sua ferramenta de foco. Você também pode personalizar os gráficos de acordo com sua preferência.
No lado negativo do Plotly, sua documentação está desatualizada; portanto, usá-lo como guia pode ser difícil para o usuário. Além disso, possui inúmeras ferramentas que o usuário deve aprender. Pode ser um desafio manter o controle de todos eles.
Recursos da biblioteca Plotly Python
Simples ITK
SimpleITK é uma biblioteca de análise de imagens que oferece uma interface para o Insight Toolkit(ITK). É baseado em C++ e é de código aberto.
Recursos da biblioteca SimpleITK
Sua interface simplificada está disponível em várias linguagens de programação como R, C#, C++, Java e Python.
Modelo de estatísticas
O Statsmodel estima modelos estatísticos, implementa testes estatísticos e explora dados estatísticos usando classes e funções.
A especificação de modelos usa fórmulas no estilo R, matrizes NumPy e quadros de dados Pandas.
Scrapy
Este pacote de código aberto é a ferramenta preferida para recuperar (scraping) e rastrear dados de um site. É assíncrono e, portanto, relativamente rápido. O Scrapy possui arquitetura e recursos que o tornam eficiente.
Por outro lado, sua instalação difere para diferentes sistemas operacionais. Além disso, você não pode usá-lo em sites construídos em JS. Além disso, só pode funcionar com Python 2.7 ou versões posteriores.
Especialistas em ciência de dados o aplicam em mineração de dados e testes automatizados.
Características
Travesseiro
Pillow é uma biblioteca de imagens Python que manipula e processa imagens.
Ele adiciona aos recursos de processamento de imagem do interpretador Python, suporta vários formatos de arquivo e oferece uma excelente representação interna.
Os dados armazenados em formatos de arquivo básicos podem ser facilmente acessados graças ao Pillow.
Encerrando💃
Isso resume nossa exploração de algumas das melhores bibliotecas Python para cientistas de dados e especialistas em aprendizado de máquina.
Como este artigo mostra, o Python tem pacotes de aprendizado de máquina e ciência de dados mais úteis. Python tem outras bibliotecas que você pode aplicar em outras áreas.
Você pode querer saber sobre alguns dos melhores notebooks de ciência de dados.
Feliz aprendizado!