Imagine que você possui uma vasta infraestrutura com diversos tipos de equipamentos que necessitam de manutenção regular ou, ainda, que precisam ser monitorados para garantir que não representem riscos ao ambiente circundante.
Uma forma de realizar isso seria enviar equipes para inspecionar cada local, verificando se tudo está em ordem. Embora viável, essa abordagem demanda tempo e recursos consideráveis. Em infraestruturas extensas, a cobertura completa em um ano pode se tornar impraticável.
Uma alternativa eficaz é automatizar este processo, utilizando serviços na nuvem para realizar as inspeções. Para isso, você precisará implementar:
👉 Um método eficiente para capturar imagens dos dispositivos. Esta etapa pode ser realizada por pessoas, que tiram fotos com mais agilidade do que realizando verificações completas, ou através de veículos e drones, automatizando a coleta de fotos.
👉 O envio dessas fotos para um local centralizado na nuvem.
👉 Um processo automatizado na nuvem que analise as fotos, utilizando modelos de aprendizado de máquina treinados para identificar danos ou anomalias nos equipamentos.
👉 A disponibilização dos resultados aos usuários responsáveis, permitindo agendar os reparos necessários.
Vamos explorar como identificar anomalias em imagens usando a nuvem da AWS. A Amazon oferece modelos de aprendizado de máquina pré-construídos que podem ser utilizados para este fim.
Como criar um modelo para detecção de anomalias visuais
O desenvolvimento de um modelo para detecção de anomalias visuais envolve algumas etapas essenciais:
Etapa 1: Defina claramente o problema a ser resolvido e os tipos de anomalias que se deseja detectar. Essa definição orientará a escolha do conjunto de dados adequado para treinar o modelo.
Etapa 2: Colete um amplo conjunto de imagens que representem condições normais e anômalas. Rotule as imagens, indicando quais são normais e quais contêm anomalias.
Etapa 3: Selecione uma arquitetura de modelo adequada para a tarefa. É possível ajustar um modelo pré-treinado ou criar um modelo personalizado do zero.
Etapa 4: Treine o modelo utilizando o conjunto de dados preparado e o algoritmo escolhido, empregando técnicas como aprendizado por transferência ou redes neurais convolucionais (CNNs).
Como treinar um modelo de aprendizado de máquina
Fonte: aws.amazon.com
O treinamento de modelos de machine learning na AWS para detecção de anomalias visuais geralmente inclui as seguintes etapas:
#1. Coletar os dados
Inicialmente, é necessário coletar e rotular um grande conjunto de imagens representando condições normais e anômalas. Quanto maior o conjunto de dados, melhor será o desempenho do modelo, embora isso implique maior tempo de treinamento.
Geralmente, um conjunto de dados com aproximadamente 1.000 fotos é um bom ponto de partida para o treinamento.
#2. Preparar os Dados
As imagens devem ser pré-processadas para que os modelos de aprendizado de máquina possam analisá-las. Esse pré-processamento pode incluir:
- Organizar as imagens em subpastas, corrigir metadados, etc.
- Redimensionar as imagens para atender aos requisitos de resolução do modelo.
- Dividir as imagens em partes menores para permitir o processamento paralelo eficiente.
#3. Selecione o modelo
Escolha o modelo adequado para a tarefa. Opte por um modelo pré-treinado ou crie um modelo personalizado para detecção de anomalias visuais.
#4. Avalie os resultados
Após o modelo processar o conjunto de dados, valide o seu desempenho e verifique se os resultados atendem às necessidades. Por exemplo, os resultados podem precisar estar corretos em mais de 99% dos casos.
#5. Implantar o modelo
Se estiver satisfeito com os resultados e o desempenho, implante o modelo em sua conta AWS para que ele possa ser utilizado por seus processos e serviços.
#6. Monitorar e Melhorar
Monitore o desempenho do modelo em diferentes testes e conjuntos de dados, avaliando constantemente sua precisão. Se necessário, treine novamente o modelo, incluindo novos dados que geraram resultados incorretos.
Modelos de aprendizado de máquina da AWS
A seguir, apresentamos alguns modelos concretos que podem ser utilizados na nuvem da Amazon.
AWS Rekognition
Fonte: aws.amazon.com
O Rekognition é um serviço de análise de imagem e vídeo versátil, aplicável a diversos casos de uso, como reconhecimento facial, detecção de objetos e reconhecimento de texto. Geralmente, utiliza-se o Rekognition para gerar resultados iniciais que formarão um “data lake” de anomalias identificadas.
Ele oferece diversos modelos pré-construídos que podem ser usados sem treinamento adicional. Além disso, realiza análises em tempo real de imagens e vídeos com alta precisão e baixa latência.
Alguns casos de uso típicos onde o Rekognition é uma boa opção para detecção de anomalias incluem:
- Detecção geral de anomalias em imagens ou vídeos.
- Realização de detecção de anomalias em tempo real.
- Integração do modelo de detecção de anomalias com outros serviços da AWS como Amazon S3, Amazon Kinesis ou AWS Lambda.
Exemplos de anomalias detectáveis usando o Rekognition:
- Anomalias em rostos, como expressões faciais ou emoções fora do comum.
- Objetos ausentes ou mal posicionados em uma cena.
- Palavras com erros ortográficos ou padrões de texto incomuns.
- Condições de iluminação incomuns ou objetos inesperados em uma cena.
- Conteúdo impróprio ou ofensivo em imagens ou vídeos.
- Mudanças repentinas de movimento ou padrões inesperados.
AWS Lookout for Vision
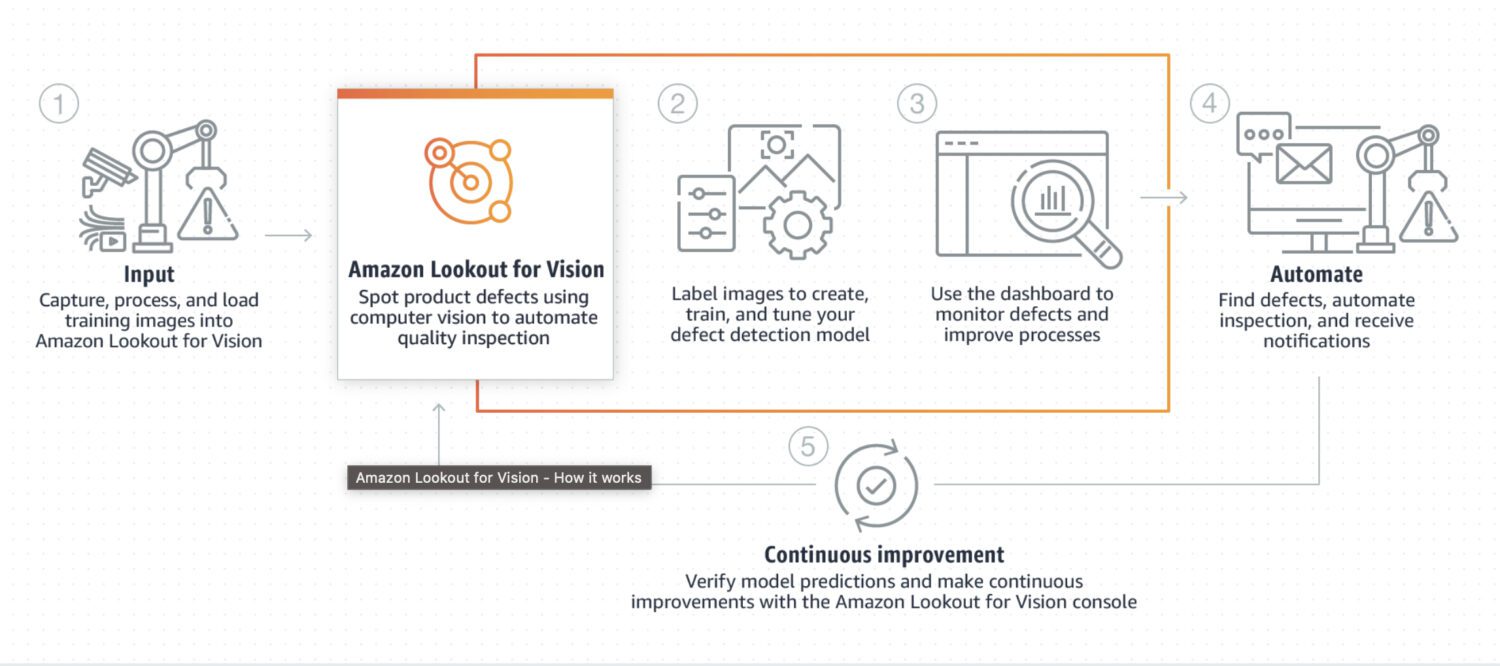
Fonte: aws.amazon.com
O Lookout for Vision é um modelo especificamente projetado para detecção de anomalias em processos industriais, como linhas de produção. Normalmente, requer algum pré-processamento e pós-processamento personalizado, frequentemente em Python. Ele é especializado em problemas muito específicos em imagens.
Ele demanda treinamento personalizado em um conjunto de dados de imagens normais e anômalas para criar um modelo específico. Não é ideal para análise em tempo real; em vez disso, ele é projetado para processamento em lote, com foco em exatidão e precisão.
O Lookout for Vision é uma boa opção quando se deseja detectar:
- Defeitos em produtos ou falhas em equipamentos em linhas de produção.
- Anomalias em grandes conjuntos de dados de imagens ou outros tipos de dados.
- Anomalias em tempo real em processos industriais.
- Anomalias integradas com outros serviços da AWS, como Amazon S3 ou AWS IoT.
Exemplos de anomalias detectáveis com o Lookout for Vision:
- Defeitos em produtos manufaturados, como arranhões, amassados ou outras imperfeições que afetem a qualidade.
- Falhas em equipamentos, como máquinas quebradas ou com mau funcionamento, que podem causar atrasos ou riscos.
- Problemas de controle de qualidade, como produtos que não atendem às especificações ou tolerâncias.
- Riscos de segurança, como objetos ou materiais perigosos para os trabalhadores ou equipamentos.
- Anomalias em processos, como mudanças inesperadas no fluxo de materiais ou produtos.
AWS Sagemaker
Fonte: aws.amazon.com
O Sagemaker é uma plataforma totalmente gerenciada para criação, treinamento e implantação de modelos personalizados de aprendizado de máquina.
É uma solução robusta que permite conectar e executar vários processos em sequência, de forma similar ao AWS Step Functions.
Como o Sagemaker utiliza instâncias EC2 para processamento, não há limite de 15 minutos por trabalho, como nas funções Lambda do AWS Step Functions.
O Sagemaker permite também o ajuste automático de modelos, o que o torna uma opção atraente. Por fim, ele facilita a implantação de modelos em ambientes de produção.
O Sagemaker é uma boa opção para detecção de anomalias quando:
- Um caso de uso específico não é coberto por modelos ou APIs pré-construídas, sendo necessário criar um modelo personalizado.
- Você possui um grande conjunto de dados. O Sagemaker consegue processar esses dados sem necessidade de pré-processamento.
- É necessário realizar a detecção de anomalias em tempo real.
- É necessário integrar o modelo com outros serviços da AWS como Amazon S3, Amazon Kinesis ou AWS Lambda.
Exemplos de detecções de anomalias que o Sagemaker pode realizar:
- Detecção de fraude em transações financeiras, como padrões de gastos incomuns.
- Análise de segurança cibernética no tráfego de rede, como padrões incomuns de transferência de dados.
- Diagnóstico médico em imagens, como a detecção de tumores.
- Anomalias no desempenho de equipamentos, como mudanças na vibração ou temperatura.
- Controle de qualidade em processos de fabricação, como a detecção de defeitos em produtos.
- Padrões incomuns de uso de energia.
Como incorporar os modelos na arquitetura sem servidor
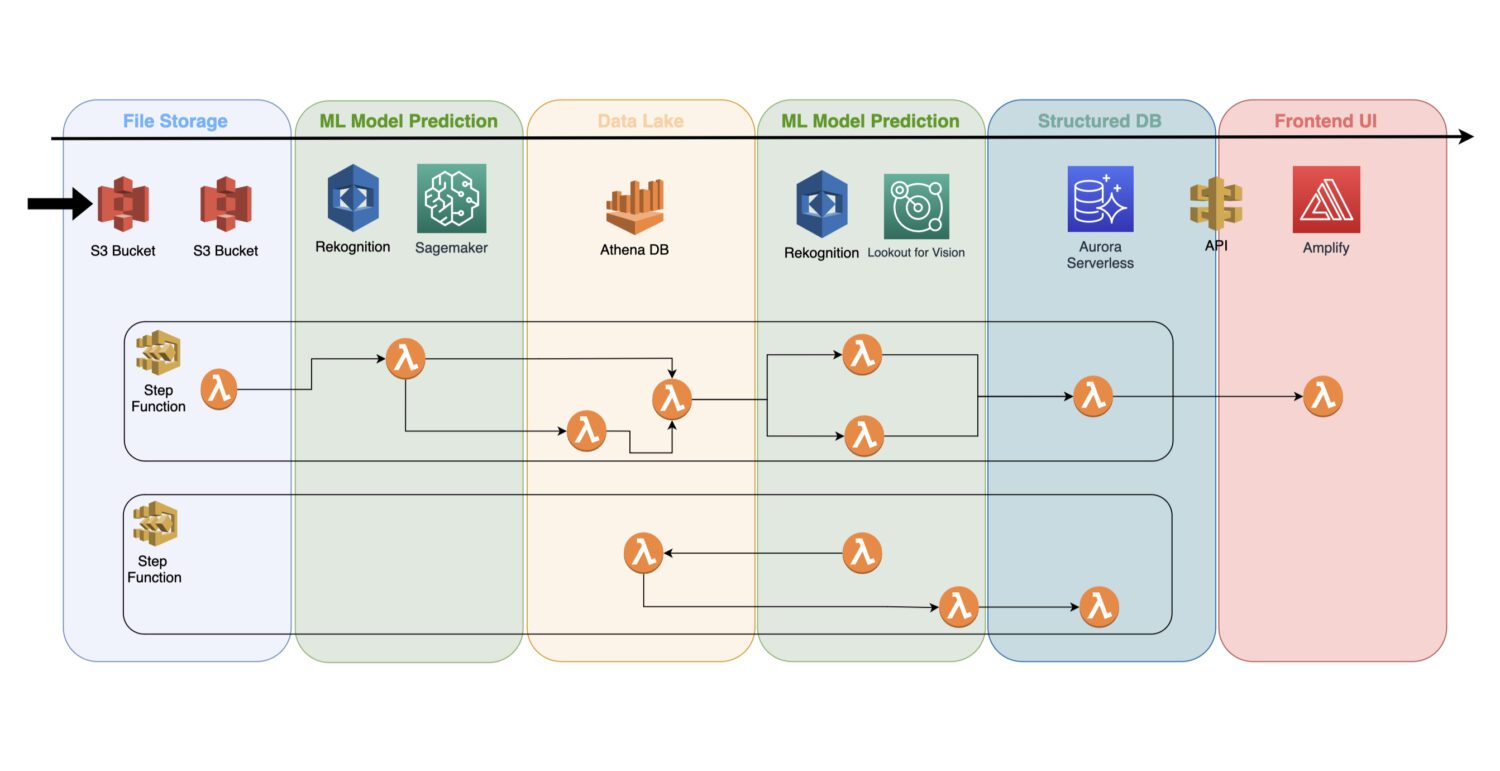
Um modelo de aprendizado de máquina treinado é um serviço de nuvem que não usa servidores de cluster, podendo ser facilmente integrado em arquiteturas sem servidor.
A automação é realizada por meio de funções Lambda da AWS, integradas a um fluxo de várias etapas no serviço AWS Step Functions.
Normalmente, é necessário realizar uma detecção inicial logo após a coleta e o pré-processamento das imagens no bucket S3. Nessa etapa, você gera a detecção de anomalias e salva os resultados em um data lake, como o banco de dados Athena.
Em alguns casos, essa detecção inicial pode não ser suficiente. Você pode precisar de uma análise mais detalhada. Por exemplo, o modelo inicial (Rekognition) pode identificar um problema no dispositivo, mas sem especificar exatamente qual.
Nesse caso, você pode usar outro modelo (Lookout for Vision) para analisar o subconjunto de imagens onde o problema foi detectado pelo primeiro modelo.
Essa abordagem permite economizar recursos, já que o segundo modelo não precisa ser executado em todas as imagens. Ele é acionado apenas nos casos necessários.
As funções AWS Lambda gerenciam todo este processo utilizando código Python ou JavaScript. O limite de tempo de 15 minutos para uma função Lambda irá determinar quantas etapas esse processo precisará conter.
Palavras Finais
Trabalhar com modelos de aprendizado de máquina em nuvem é um desafio muito interessante. Ao analisar as competências e tecnologias envolvidas, percebe-se a necessidade de uma equipe com um amplo leque de habilidades.
A equipe precisa entender como treinar um modelo, seja ele pré-construído ou criado do zero. Isso envolve conhecimentos de matemática e álgebra para garantir a confiabilidade e o desempenho dos resultados.
Também são necessárias habilidades avançadas de programação em Python ou JavaScript, além de conhecimentos em bancos de dados e SQL. Após o desenvolvimento do modelo, a equipe de DevOps irá integrá-lo a um pipeline para automatizar a implantação e execução.
Definir anomalias e treinar o modelo é apenas uma parte do processo. Integrar todas as etapas em uma equipe funcional, capaz de processar os resultados e salvar os dados de forma eficaz e automatizada para os usuários finais, é o grande desafio.
A seguir, confira mais sobre reconhecimento facial para empresas.