
O pipeline de agregação é a forma recomendada para executar consultas complexas no MongoDB. Se você estiver usando o MapReduce do MongoDB, é melhor mudar para o pipeline de agregação para obter cálculos mais eficientes.
últimas postagens
O que é agregação no MongoDB e como funciona?
O pipeline de agregação é um processo de vários estágios para executar consultas avançadas no MongoDB. Ele processa dados por meio de diferentes estágios chamados pipeline. Você pode usar os resultados gerados em um nível como modelo de operação em outro.
Por exemplo, você pode passar o resultado de uma operação de correspondência para outro estágio para classificação nessa ordem até obter a saída desejada.
Cada estágio de um pipeline de agregação apresenta um operador MongoDB e gera um ou mais documentos transformados. Dependendo da sua consulta, um nível pode aparecer várias vezes no pipeline. Por exemplo, talvez seja necessário usar os estágios do operador $count ou $sort mais de uma vez no pipeline de agregação.
Os estágios do pipeline de agregação
O pipeline de agregação passa dados por vários estágios em uma única consulta. Existem várias etapas e você pode encontrar seus detalhes no Documentação do MongoDB.
Vamos definir alguns dos mais comumente usados a seguir.
O estágio $match
Este estágio ajuda a definir condições de filtragem específicas antes de iniciar os outros estágios de agregação. Você pode usá-lo para selecionar os dados correspondentes que deseja incluir no pipeline de agregação.
A fase de grupos $
A fase de grupo separa os dados em diferentes grupos com base em critérios específicos usando pares de valores-chave. Cada grupo representa uma chave no documento de saída.
Por exemplo, considere os seguintes dados de amostra de vendas:
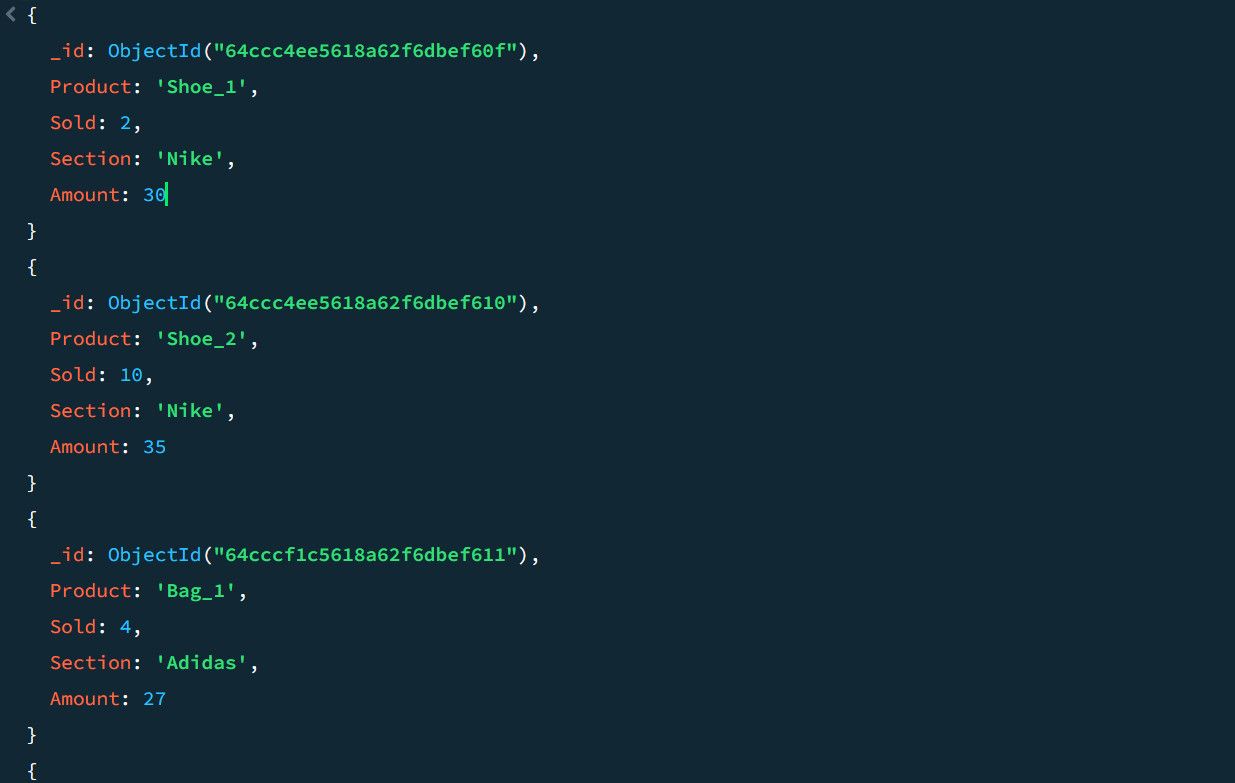
Usando o pipeline de agregação, você pode calcular a contagem total de vendas e as principais vendas para cada seção de produto:
{
$group: {
_id: $Section,
total_sales_count: {$sum : $Sold},
top_sales: {$max: $Amount},
}
}
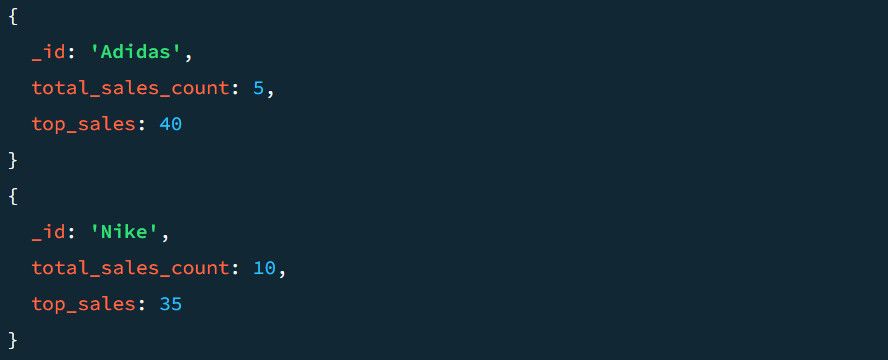
O par _id: $Section agrupa o documento de saída com base nas seções. Ao especificar os campos top_sales_count e top_sales, o MongoDB cria novas chaves com base na operação definida pelo agregador; pode ser $sum, $min, $max ou $avg.
O estágio $skip
Você pode usar o estágio $skip para omitir um número específico de documentos na saída. Geralmente acontece depois da fase de grupos. Por exemplo, se você espera dois documentos de saída, mas ignora um, a agregação produzirá apenas o segundo documento.
Para adicionar um estágio de salto, insira a operação $skip no pipeline de agregação:
...,
{
$skip: 1
},
O estágio $sort
O estágio de classificação permite organizar os dados em ordem decrescente ou crescente. Por exemplo, podemos classificar ainda mais os dados no exemplo de consulta anterior em ordem decrescente para determinar qual seção tem as vendas mais altas.
Adicione o operador $sort à consulta anterior:
...,
{
$sort: {top_sales: -1}
},
O estágio $limit
A operação limit ajuda a reduzir o número de documentos de saída que você deseja que o pipeline de agregação mostre. Por exemplo, use o operador $limit para obter a seção com as vendas mais altas retornadas pela etapa anterior:
...,
{
$sort: {top_sales: -1}
},{"$limit": 1}
O acima retorna apenas o primeiro documento; esta é a seção com maiores vendas, pois aparece no topo da saída classificada.
O estágio $project
O estágio $project permite moldar o documento de saída como desejar. Usando o operador $project, você pode especificar qual campo incluir na saída e personalizar seu nome de chave.
Por exemplo, um exemplo de saída sem o estágio $project se parece com isto:
Vamos ver como fica o estágio $project. Para adicionar o $project ao pipeline:
...,{
"$project": {
"_id": 0,
"Section": "$_id",
"TotalSold": "$total_sales_count",
"TopSale": "$top_sales",}
}
Como agrupamos anteriormente os dados com base nas seções do produto, o texto acima inclui cada seção do produto no documento de saída. Ele também garante que a contagem de vendas agregadas e as principais vendas apareçam na saída como TotalSold e TopSale.
O resultado final é muito mais limpo em comparação com o anterior:

O palco $descontrair
O estágio $unwind divide uma matriz dentro de um documento em documentos individuais. Considere os seguintes dados de pedidos, por exemplo:
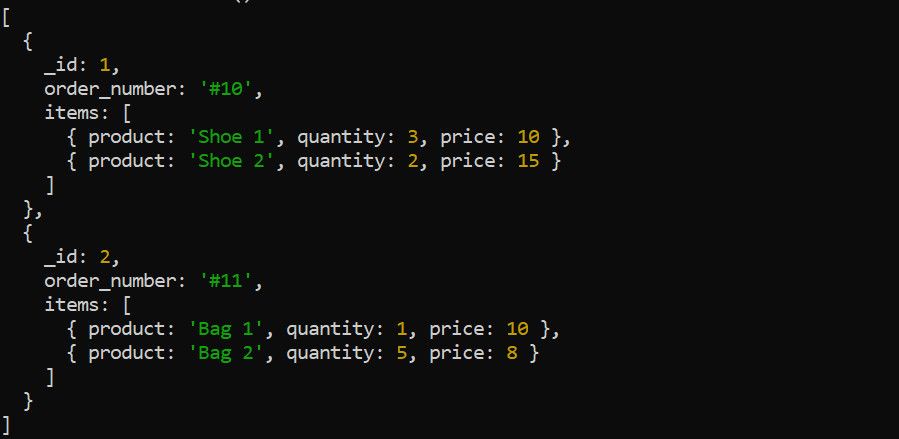
Use o estágio $unwind para desconstruir a matriz de itens antes de aplicar outros estágios de agregação. Por exemplo, desenrolar a matriz de itens faz sentido se você quiser calcular a receita total de cada produto:
db.Orders.aggregate(
[
{
"$unwind": "$items"
},
{
"$group": {
"_id": "$items.product",
"total_revenue": { "$sum": { "$multiply": ["$items.quantity", "$items.price"] } }
}
},
{
"$sort": { "total_revenue": -1 }
},{
"$project": {
"_id": 0,
"Product": "$_id",
"TotalRevenue": "$total_revenue",}
}
])
Aqui está o resultado da consulta de agregação acima:

Como criar um pipeline de agregação no MongoDB
Embora o pipeline de agregação inclua diversas operações, os estágios apresentados anteriormente dão uma ideia de como aplicá-los no pipeline, incluindo a consulta básica de cada uma.
Usando a amostra de dados de vendas anterior, vamos reunir alguns dos estágios discutidos acima para uma visão mais ampla do pipeline de agregação:
db.sales.aggregate([{
"$match": {
"Sold": { "$gte": 5 }
}
},{
"$group": {
"_id": "$Section",
"total_sales_count": { "$sum": "$Sold" },
"top_sales": { "$max": "$Amount" },
}},
{
"$sort": { "top_sales": -1 }
},{"$skip": 0},
{
"$project": {
"_id": 0,
"Section": "$_id",
"TotalSold": "$total_sales_count",
"TopSale": "$top_sales",}
}
])
O resultado final se parece com algo que você viu anteriormente:
Pipeline de agregação vs. MapReduce
Até sua descontinuação a partir do MongoDB 5.0, a forma convencional de agregar dados no MongoDB era via MapReduce. Embora o MapReduce tenha aplicações mais amplas além do MongoDB, ele é menos eficiente que o pipeline de agregação, exigindo scripts de terceiros para escrever o mapa e reduzir funções separadamente.
O pipeline de agregação, por outro lado, é específico apenas do MongoDB. Mas fornece uma maneira mais limpa e eficiente de executar consultas complexas. Além da simplicidade e escalabilidade da consulta, os estágios do pipeline apresentados tornam a saída mais personalizável.
Existem muitas outras diferenças entre o pipeline de agregação e o MapReduce. Você os verá ao mudar do MapReduce para o pipeline de agregação.
Torne as consultas de Big Data eficientes no MongoDB
Sua consulta deve ser o mais eficiente possível se você quiser executar cálculos detalhados em dados complexos no MongoDB. O pipeline de agregação é ideal para consultas avançadas. Em vez de manipular dados em operações separadas, o que muitas vezes reduz o desempenho, a agregação permite agrupá-los todos em um único pipeline de desempenho e executá-los uma vez.
Embora o pipeline de agregação seja mais eficiente que o MapReduce, você pode tornar a agregação mais rápida e eficiente indexando seus dados. Isso limita a quantidade de dados que o MongoDB precisa verificar durante cada estágio de agregação.