
Llama 2 é um modelo de linguagem grande (LLM) de código aberto desenvolvido pela Meta. É um modelo de linguagem grande de código aberto competente, sem dúvida melhor do que alguns modelos fechados como GPT-3.5 e PaLM 2. Consiste em três tamanhos de modelo de texto generativo pré-treinados e ajustados, incluindo 7 bilhões, 13 bilhões e 70 bilhões de modelos de parâmetros.
Você explorará os recursos de conversação do Llama 2 construindo um chatbot usando Streamlit e Llama 2.
últimas postagens
Compreendendo o Llama 2: recursos e benefícios
Quão diferente é o Llama 2 de seu modelo de linguagem grande antecessor, o Llama 1?
- Tamanho de modelo maior: O modelo é maior, com até 70 bilhões de parâmetros. Isso permite aprender associações mais complexas entre palavras e frases.
- Habilidades de conversação aprimoradas: O Aprendizado por Reforço com Feedback Humano (RLHF) melhora as habilidades de aplicação de conversação. Isso permite que o modelo gere conteúdo semelhante ao humano, mesmo em interações complicadas.
- Inferência mais rápida: introduz um novo método chamado atenção de consulta agrupada para acelerar a inferência. Isso resulta na capacidade de construir aplicativos mais úteis, como chatbots e assistentes virtuais.
- Mais eficiente: É mais eficiente em termos de memória e recursos computacionais do que seu antecessor.
- Licença de código aberto e não comercial: É de código aberto. Pesquisadores e desenvolvedores podem usar e modificar o Llama 2 sem restrições.
Llama 2 supera significativamente seu antecessor em todos os aspectos. Essas características o tornam uma ferramenta potente para diversas aplicações, como chatbots, assistentes virtuais e compreensão de linguagem natural.
Configurando um ambiente Streamlit para desenvolvimento de chatbot
Para começar a construir seu aplicativo, você precisa configurar um ambiente de desenvolvimento. Isso isola seu projeto dos projetos existentes em sua máquina.
Primeiro, comece criando um ambiente virtual usando a biblioteca Pipenv da seguinte forma:
pipenv shell
A seguir, instale as bibliotecas necessárias para construir o chatbot.
pipenv install streamlit replicate
Streamlit: é uma estrutura de aplicativo da web de código aberto que renderiza aplicativos de aprendizado de máquina e ciência de dados rapidamente.
Replicar: é uma plataforma em nuvem que fornece acesso a grandes modelos de aprendizado de máquina de código aberto para implantação.
Obtenha seu token de API Llama 2 da replicação
Para obter uma chave de token replicado, você deve primeiro registrar uma conta no Replicar usando sua conta GitHub.
Depois de acessar o painel, navegue até o botão Explorar e pesquise Llama 2 chat para ver o modelo llama-2–70b-chat.
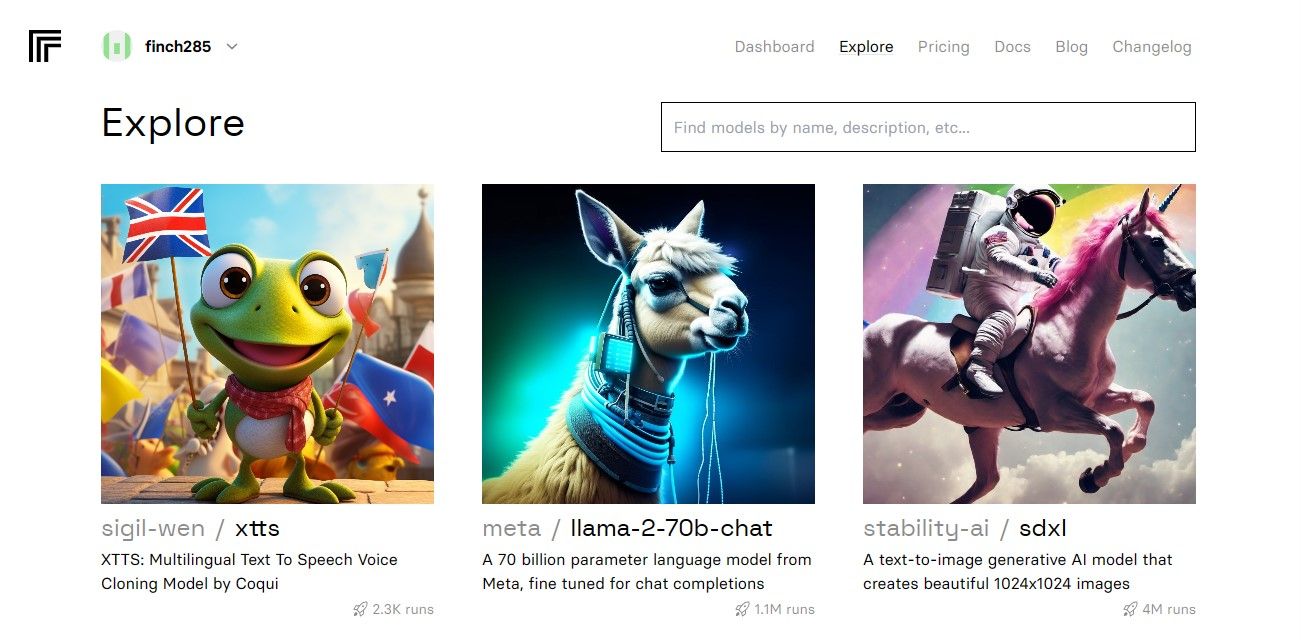
Clique no modelo llama-2–70b-chat para visualizar os endpoints da API Llama 2. Clique no botão API na barra de navegação do modelo llama-2–70b-chat. No lado direito da página, clique no botão Python. Isso fornecerá acesso ao token API para aplicativos Python.
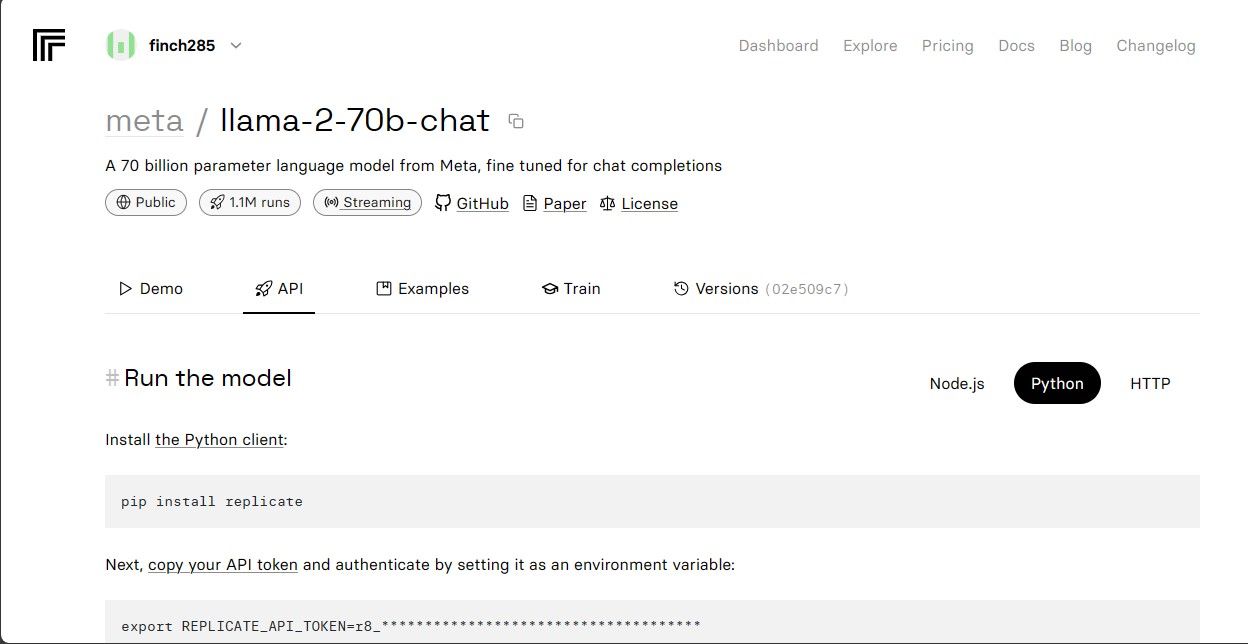
Copie o REPLICATE_API_TOKEN e guarde-o em segurança para uso futuro.
Construindo o Chatbot
Primeiro, crie um arquivo Python chamado llama_chatbot.py e um arquivo env (.env). Você escreverá seu código em llama_chatbot.py e armazenará suas chaves secretas e tokens de API no arquivo .env.
No arquivo llama_chatbot.py, importe as bibliotecas da seguinte maneira.
import streamlit as st
import os
import replicate
A seguir, defina as variáveis globais do modelo llama-2–70b-chat.
REPLICATE_API_TOKEN = os.environ.get('REPLICATE_API_TOKEN', default="")
LLaMA2_7B_ENDPOINT = os.environ.get('MODEL_ENDPOINT7B', default="")
LLaMA2_13B_ENDPOINT = os.environ.get('MODEL_ENDPOINT13B', default="")
LLaMA2_70B_ENDPOINT = os.environ.get('MODEL_ENDPOINT70B', default="")
No arquivo .env, adicione o token de replicação e os endpoints do modelo no seguinte formato:
REPLICATE_API_TOKEN='Paste_Your_Replicate_Token'
MODEL_ENDPOINT7B='a16z-infra/llama7b-v2-chat:4f0a4744c7295c024a1de15e1a63c880d3da035fa1f49bfd344fe076074c8eea'
MODEL_ENDPOINT13B='a16z-infra/llama13b-v2-chat:df7690f1994d94e96ad9d568eac121aecf50684a0b0963b25a41cc40061269e5'
MODEL_ENDPOINT70B='replicate/llama70b-v2-chat:e951f18578850b652510200860fc4ea62b3b16fac280f83ff32282f87bbd2e48'
Cole seu token de replicação e salve o arquivo .env.
Projetando o fluxo conversacional do chatbot
Crie um pré-prompt para iniciar o modelo Llama 2 dependendo da tarefa que você deseja que ele execute. Nesse caso, você deseja que o modelo atue como assistente.
PRE_PROMPT = "You are a helpful assistant. You do not respond as " \
"'User' or pretend to be 'User'." \
" You only respond once as Assistant."
Defina a configuração da página do seu chatbot da seguinte forma:
st.set_page_config(
page_title="LLaMA2Chat",
page_icon=":volleyball:",
layout="wide"
)
Escreva uma função que inicialize e configure variáveis de estado de sessão.
LLaMA2_MODELS = {
'LLaMA2-7B': LLaMA2_7B_ENDPOINT,
'LLaMA2-13B': LLaMA2_13B_ENDPOINT,
'LLaMA2-70B': LLaMA2_70B_ENDPOINT,
}
DEFAULT_TEMPERATURE = 0.1
DEFAULT_TOP_P = 0.9
DEFAULT_MAX_SEQ_LEN = 512
DEFAULT_PRE_PROMPT = PRE_PROMPTdef setup_session_state():
st.session_state.setdefault('chat_dialogue', [])
selected_model = st.sidebar.selectbox(
'Choose a LLaMA2 model:', list(LLaMA2_MODELS.keys()), key='model')
st.session_state.setdefault(
'llm', LLaMA2_MODELS.get(selected_model, LLaMA2_70B_ENDPOINT))
st.session_state.setdefault('temperature', DEFAULT_TEMPERATURE)
st.session_state.setdefault('top_p', DEFAULT_TOP_P)
st.session_state.setdefault('max_seq_len', DEFAULT_MAX_SEQ_LEN)
st.session_state.setdefault('pre_prompt', DEFAULT_PRE_PROMPT)
A função define as variáveis essenciais como chat_dialogue, pre_prompt, llm, top_p, max_seq_len e temperatura no estado da sessão. Também trata da seleção do modelo Llama 2 de acordo com a escolha do usuário.
Escreva uma função para renderizar o conteúdo da barra lateral do aplicativo Streamlit.
def render_sidebar():
st.sidebar.header("LLaMA2 Chatbot")
st.session_state['temperature'] = st.sidebar.slider('Temperature:',
min_value=0.01, max_value=5.0, value=DEFAULT_TEMPERATURE, step=0.01)
st.session_state['top_p'] = st.sidebar.slider('Top P:', min_value=0.01,
max_value=1.0, value=DEFAULT_TOP_P, step=0.01)
st.session_state['max_seq_len'] = st.sidebar.slider('Max Sequence Length:',
min_value=64, max_value=4096, value=DEFAULT_MAX_SEQ_LEN, step=8)
new_prompt = st.sidebar.text_area(
'Prompt before the chat starts. Edit here if desired:',
DEFAULT_PRE_PROMPT,height=60)
if new_prompt != DEFAULT_PRE_PROMPT and new_prompt != "" and
new_prompt is not None:
st.session_state['pre_prompt'] = new_prompt + "\n"
else:
st.session_state['pre_prompt'] = DEFAULT_PRE_PROMPT
A função exibe o cabeçalho e as variáveis de configuração do chatbot Llama 2 para ajustes.
Escreva a função que renderiza o histórico de bate-papo na área de conteúdo principal do aplicativo Streamlit.
def render_chat_history():
response_container = st.container()
for message in st.session_state.chat_dialogue:
with st.chat_message(message["role"]):
st.markdown(message["content"])
A função itera através do chat_dialogue salvo no estado da sessão, exibindo cada mensagem com a função correspondente (usuário ou assistente).
Lide com a entrada do usuário usando a função abaixo.
def handle_user_input():
user_input = st.chat_input(
"Type your question here to talk to LLaMA2"
)
if user_input:
st.session_state.chat_dialogue.append(
{"role": "user", "content": user_input}
)
with st.chat_message("user"):
st.markdown(user_input)
Esta função apresenta ao usuário um campo de entrada onde ele pode inserir suas mensagens e dúvidas. A mensagem é adicionada ao chat_dialogue no estado da sessão com a função do usuário assim que o usuário envia a mensagem.
Escreva uma função que gere respostas do modelo Llama 2 e as exiba na área de chat.
def generate_assistant_response():
message_placeholder = st.empty()
full_response = ""
string_dialogue = st.session_state['pre_prompt']
for dict_message in st.session_state.chat_dialogue:
speaker = "User" if dict_message["role"] == "user" else "Assistant"
string_dialogue += f"{speaker}: {dict_message['content']}\n"
output = debounce_replicate_run(
st.session_state['llm'],
string_dialogue + "Assistant: ",
st.session_state['max_seq_len'],
st.session_state['temperature'],
st.session_state['top_p'],
REPLICATE_API_TOKEN
)
for item in output:
full_response += item
message_placeholder.markdown(full_response + "▌")
message_placeholder.markdown(full_response)
st.session_state.chat_dialogue.append({"role": "assistant",
"content": full_response})
A função cria uma sequência de histórico de conversa que inclui mensagens do usuário e do assistente antes de chamar a função debounce_replicate_run para obter a resposta do assistente. Ele modifica continuamente a resposta na IU para proporcionar uma experiência de bate-papo em tempo real.
Escreva a função principal responsável por renderizar todo o aplicativo Streamlit.
def render_app():
setup_session_state()
render_sidebar()
render_chat_history()
handle_user_input()
generate_assistant_response()
Ele chama todas as funções definidas para configurar o estado da sessão, renderizar a barra lateral, histórico de bate-papo, manipular a entrada do usuário e gerar respostas do assistente em uma ordem lógica.
Escreva uma função para invocar a função render_app e iniciar o aplicativo quando o script for executado.
def main():
render_app()if __name__ == "__main__":
main()
Agora seu aplicativo deve estar pronto para execução.
Tratamento de solicitações de API
Crie um arquivo utils.py no diretório do seu projeto e adicione a função abaixo:
import replicate
import time
last_call_time = 0
debounce_interval = 2def debounce_replicate_run(llm, prompt, max_len, temperature, top_p,
API_TOKEN):
global last_call_time
print("last call time: ", last_call_time)current_time = time.time()
elapsed_time = current_time - last_call_timeif elapsed_time < debounce_interval:
print("Debouncing")
return "Hello! Your requests are too fast. Please wait a few" \
" seconds before sending another request."last_call_time = time.time()
output = replicate.run(llm, input={"prompt": prompt + "Assistant: ",
"max_length": max_len, "temperature":
temperature, "top_p": top_p,
"repetition_penalty": 1}, api_token=API_TOKEN)
return output
A função executa um mecanismo de rejeição para evitar consultas de API frequentes e excessivas a partir da entrada de um usuário.
Em seguida, importe a função de resposta debounce para seu arquivo llama_chatbot.py da seguinte maneira:
from utils import debounce_replicate_run
Agora execute o aplicativo:
streamlit run llama_chatbot.py
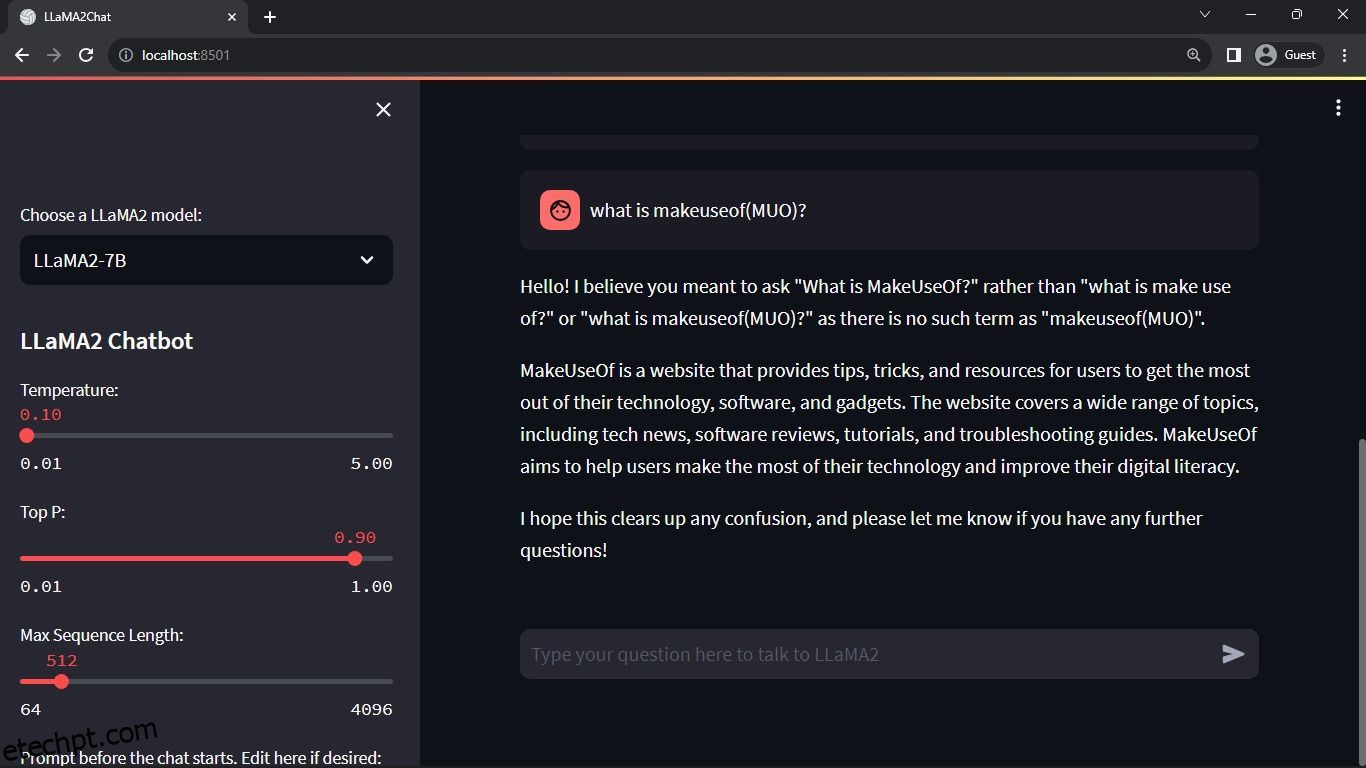
Resultado esperado:
A saída mostra uma conversa entre o modelo e um humano.
Aplicações do mundo real de Chatbots Streamlit e Llama 2
Alguns exemplos reais de aplicações do Llama 2 incluem:
- Chatbots: Seu uso se aplica à criação de chatbots de resposta humana que podem manter conversas em tempo real sobre diversos temas.
- Assistentes virtuais: Seu uso se aplica à criação de assistentes virtuais que entendem e respondem às consultas da linguagem humana.
- Tradução de idiomas: Seu uso se aplica a tarefas de tradução de idiomas.
- Sumarização de texto: Seu uso é aplicável na sumarização de textos grandes em textos curtos para fácil compreensão.
- Pesquisa: você pode aplicar o Llama 2 para fins de pesquisa, respondendo a perguntas sobre uma variedade de tópicos.
O futuro da IA
Com modelos fechados como GPT-3.5 e GPT-4, é muito difícil para pequenos players construir algo substancial usando LLMs, uma vez que acessar a API do modelo GPT pode ser bastante caro.
Abrir modelos avançados de linguagem de grande porte, como o Llama 2, para a comunidade de desenvolvedores é apenas o começo de uma nova era de IA. Isso levará a uma implementação mais criativa e inovadora dos modelos em aplicações do mundo real, levando a uma corrida acelerada rumo à superinteligência artificial (ASI).