Preparado para explorar a arte da engenharia de recursos para aprendizado de máquina e ciência de dados? Você chegou ao lugar certo!
A engenharia de recursos é uma competência fundamental para extrair informações valiosas dos dados. Neste guia conciso, vamos desmembrar este tópico em partes simples e fáceis de entender. Embarque nesta jornada e domine a arte de modelar recursos!
O que é Engenharia de Recursos?
Ao desenvolver um modelo de aprendizado de máquina para resolver um problema empresarial ou experimental, você alimenta o modelo com dados organizados em colunas e linhas. No contexto da ciência de dados e desenvolvimento de ML, as colunas são denominadas atributos ou variáveis.
Os dados granulares ou linhas abaixo dessas colunas são conhecidos como observações ou instâncias. As colunas ou atributos constituem os recursos de um conjunto de dados bruto.
Esses recursos brutos podem não ser suficientes ou ideais para treinar um modelo de ML. Para minimizar o ruído nos metadados coletados e potencializar os sinais únicos dos recursos, é necessário transformar ou converter as colunas de metadados em recursos funcionais através da engenharia de recursos.
Exemplo 1: Modelagem Financeira
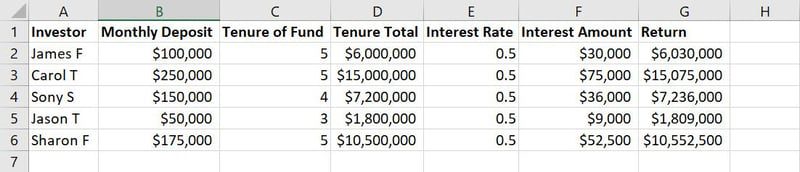
No exemplo ilustrado acima, em um conjunto de dados, as colunas de A a G representam os recursos. Os valores ou textos em cada coluna, ao longo das linhas (como nomes, valor do depósito, anos de depósito, taxas de juros etc.), são as observações.
Na modelagem de ML, o processo de excluir, adicionar, combinar ou transformar dados para construir recursos relevantes e reduzir o tamanho geral do banco de dados de treinamento é chamado de engenharia de recursos.
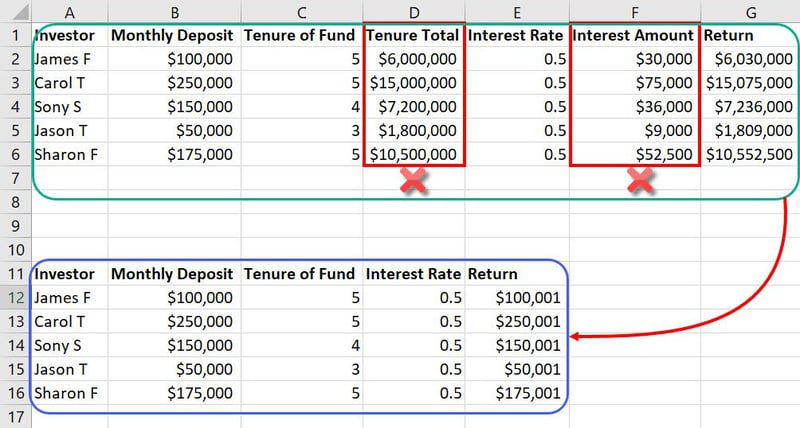
No mesmo conjunto de dados, recursos como “Posse Total” e “Valor de Juros” podem ser redundantes, ocupando espaço desnecessário e confundindo o modelo de ML. Portanto, é possível reduzir de sete para cinco o número total de recursos.
Em modelos de ML que lidam com bancos de dados extensos, com milhares de colunas e milhões de linhas, a redução de dois recursos pode ter um grande impacto no projeto.
Exemplo 2: Criador de Playlist Musical com IA
Em certas situações, é possível criar um recurso totalmente novo a partir de múltiplos recursos existentes. Imagine que você está construindo um modelo de IA que cria automaticamente playlists musicais personalizadas com base no evento, gosto musical, humor etc.
Após coletar dados de diversas fontes, você criou o seguinte banco de dados de músicas:
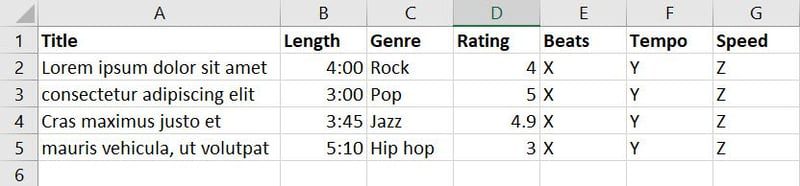
O banco de dados acima contém sete recursos. Para treinar o modelo para determinar qual música é mais adequada para um evento específico, você pode combinar os recursos “Gênero”, “Classificação”, “Batidas”, “Andamento” e “Velocidade” em um novo recurso chamado “Aplicabilidade”.
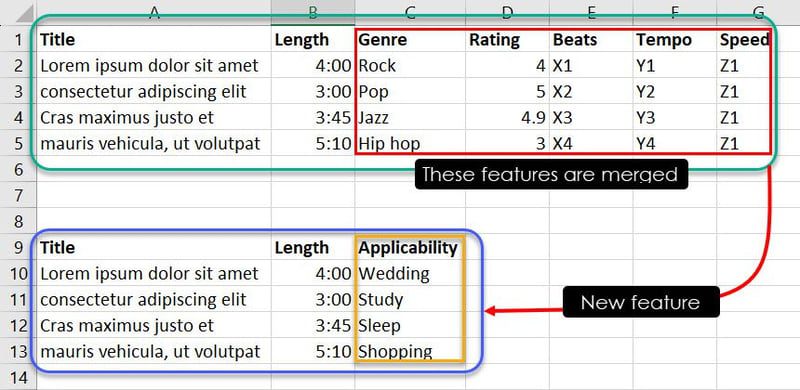
Com base em sua experiência ou na identificação de padrões, você pode combinar determinadas instâncias dos recursos para determinar qual música se encaixa melhor em qual evento. Por exemplo, as observações “Jazz”, “4.9”, “X3”, “Y3” e “Z1” podem indicar ao modelo de ML que a música “Cras maximus justo et” é adequada para um usuário que busca músicas para dormir.
Tipos de Recursos no Aprendizado de Máquina
Recursos Categóricos
Estes atributos representam categorias ou rótulos distintos. Eles são usados para identificar conjuntos de dados qualitativos.
#1. Recursos Categóricos Ordinais
Os recursos ordinais possuem categorias com uma ordem significativa. Por exemplo, níveis de escolaridade (Ensino Médio, Bacharelado, Mestrado etc.) possuem uma clara hierarquia, mas não diferenças quantitativas.
#2. Recursos Categóricos Nominais
Recursos nominais são categorias sem ordem inerente, como cores, países ou tipos de animais. Nesses casos, existem apenas diferenças qualitativas.
Recursos de Matriz (Array Features)
Esses recursos representam dados organizados em matrizes ou listas. Cientistas de dados e desenvolvedores de ML utilizam-nos para manipular sequências ou incorporar dados categóricos.
#1. Incorporação de Recursos de Matriz
A incorporação de matrizes converte dados categóricos em vetores densos, sendo comum em processamento de linguagem natural e sistemas de recomendação.
#2. Listagem de Recursos de Matriz
Matrizes de lista armazenam sequências de dados, como itens em um pedido ou o histórico de ações.
Recursos Numéricos
Esses recursos de treinamento de ML são usados para realizar operações matemáticas, pois representam dados quantitativos.
#1. Recursos Numéricos de Intervalo
Recursos de intervalo possuem intervalos consistentes entre valores, mas não um ponto zero real. Um exemplo são os dados de monitoramento de temperatura. Aqui, o zero indica a temperatura de congelamento, mas o atributo ainda existe.
#2. Recursos Numéricos de Razão
Recursos de razão têm intervalos consistentes entre valores e um ponto zero real. Exemplos incluem idade, altura e renda.
Importância da Engenharia de Recursos em ML e Ciência de Dados
- A extração eficaz de recursos aprimora a precisão do modelo, tornando as previsões mais confiáveis e valiosas para a tomada de decisões.
- A seleção criteriosa de recursos elimina atributos irrelevantes ou redundantes, simplificando os modelos e economizando recursos computacionais.
- Recursos bem elaborados revelam padrões nos dados, ajudando os cientistas de dados a compreender relações complexas dentro do conjunto de dados.
- A adaptação de recursos a algoritmos específicos pode otimizar o desempenho do modelo em diversas abordagens de aprendizado de máquina.
- Recursos bem projetados resultam em treinamento de modelo mais rápido e custos computacionais reduzidos, agilizando o fluxo de trabalho de ML.
A seguir, vamos explorar o processo passo a passo da engenharia de recursos.
Processo de Engenharia de Recursos Passo a Passo

- Coleta de dados: A fase inicial envolve a coleta de dados brutos de fontes variadas, como bancos de dados, arquivos ou APIs.
- Limpeza de dados: Após obter os dados, é necessário limpá-los, identificando e corrigindo erros, inconsistências ou outliers.
- Tratamento de valores ausentes: Valores ausentes podem gerar ruído no armazenamento de recursos do modelo de ML, causando vieses. É essencial imputar os valores ausentes ou omiti-los cuidadosamente para não afetar o modelo.
- Codificação de variáveis categóricas: É crucial converter variáveis categóricas em formato numérico para que algoritmos de aprendizado de máquina possam utilizá-las.
- Dimensionamento e normalização: O dimensionamento garante que os recursos numéricos estejam em uma escala consistente, evitando que recursos com valores grandes dominem o modelo.
- Seleção de recursos: Esta etapa auxilia na identificação e retenção dos recursos mais relevantes, reduzindo a dimensionalidade e melhorando a eficiência do modelo.
- Criação de recursos: Em alguns casos, é possível criar novos recursos a partir dos existentes para capturar informações valiosas.
- Transformação de recursos: Técnicas como logaritmos ou transformações de potência podem tornar os dados mais adequados para modelagem.
A seguir, vamos discutir métodos de engenharia de recursos.
Métodos de Engenharia de Recursos
#1. Análise de Componentes Principais (PCA)
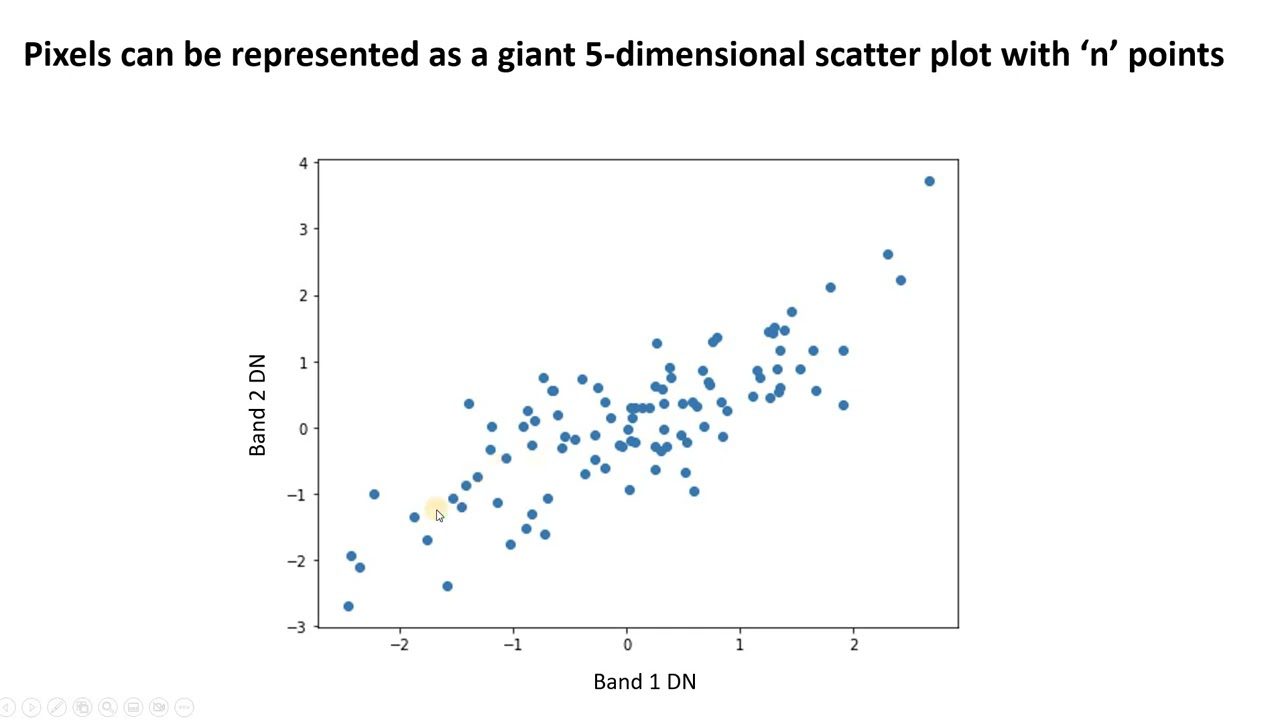
O PCA simplifica dados complexos encontrando novos recursos não correlacionados, chamados de componentes principais. Ele pode ser usado para reduzir a dimensionalidade e melhorar o desempenho do modelo.
#2. Recursos Polinomiais
A criação de recursos polinomiais envolve a adição de potências de recursos existentes para capturar relações complexas. Isso permite que seu modelo compreenda padrões não lineares.
#3. Tratamento de Outliers
Outliers são pontos de dados incomuns que podem afetar o desempenho dos modelos. É necessário identificar e tratar os outliers para evitar resultados distorcidos.
#4. Transformação Logarítmica
A transformação logarítmica auxilia na normalização de dados com distribuição assimétrica, reduzindo o impacto de valores extremos para tornar os dados mais adequados para modelagem.
#5. Incorporação Estocástica de Vizinhos t-Distribuída (t-SNE)
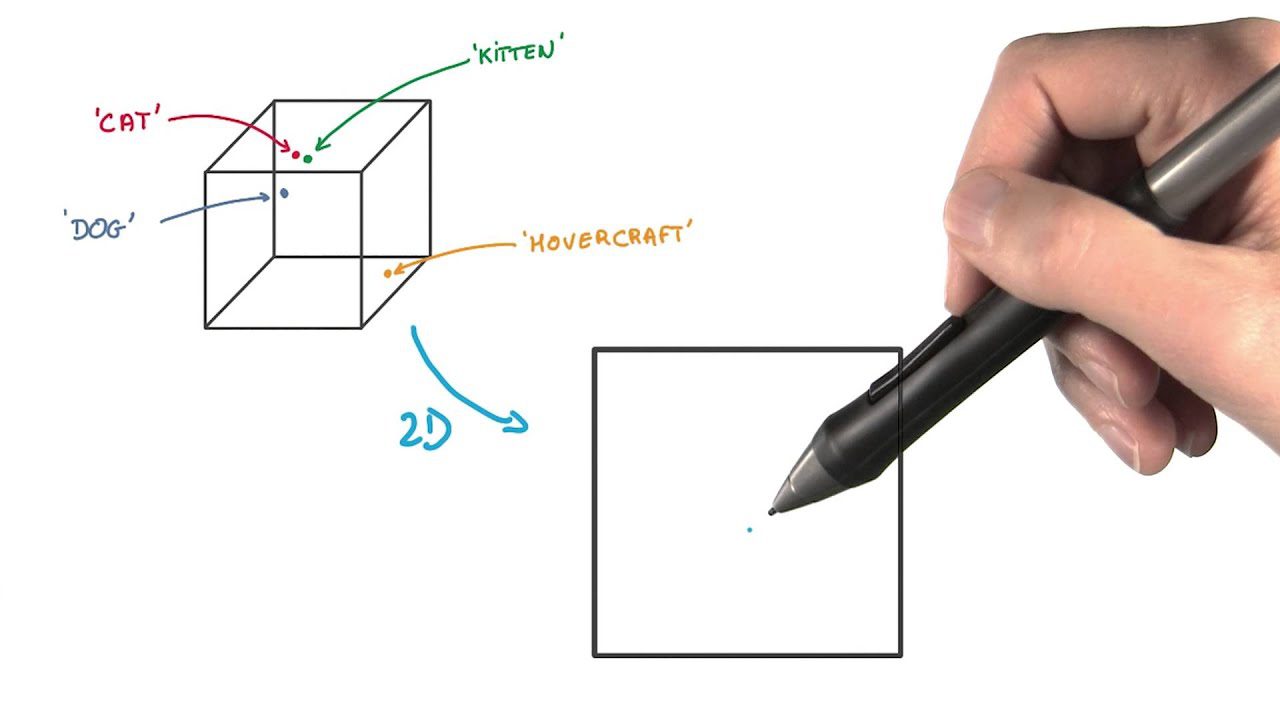
O t-SNE é útil para visualizar dados de alta dimensão. Ele reduz a dimensionalidade e torna os agrupamentos mais evidentes, preservando a estrutura dos dados.
Neste método, os pontos de dados são representados como pontos em um espaço de dimensão inferior. Pontos semelhantes no espaço original de alta dimensão são posicionados próximos na representação de menor dimensão.
Ele se diferencia de outros métodos de redução de dimensionalidade por preservar a estrutura e as distâncias entre os pontos de dados.
#6. Codificação One-Hot
A codificação one-hot transforma variáveis categóricas em um formato binário (0 ou 1), criando novas colunas binárias para cada categoria. Isso torna os dados categóricos adequados para algoritmos de ML.
#7. Codificação de Contagem
A codificação de contagem substitui valores categóricos pelo número de vezes que aparecem no conjunto de dados, capturando informações relevantes das variáveis categóricas.
Neste método, a frequência ou contagem de cada categoria é usada como um novo recurso numérico, em vez dos rótulos originais.
#8. Padronização de Recursos

Recursos com valores maiores podem dominar os de menor valor, causando viés no modelo de ML. A padronização evita tais vieses.
O processo de padronização envolve duas técnicas comuns:
- Padronização Z-Score: Transforma cada recurso para que tenha uma média de 0 e um desvio padrão de 1. Para isso, a média do recurso é subtraída de cada ponto de dados e o resultado é dividido pelo desvio padrão.
- Escala Min-Max: Transforma os dados em um intervalo específico, geralmente entre 0 e 1. Isso é feito subtraindo o valor mínimo do recurso de cada ponto de dados e dividindo pelo intervalo.
#9. Normalização
Através da normalização, os recursos numéricos são dimensionados para um intervalo comum, geralmente entre 0 e 1. Ela mantém as diferenças relativas entre os valores, garantindo que todos os recursos estejam em condições de igualdade.

#1. Featuretools
Featuretools é uma estrutura Python de código aberto que cria recursos automaticamente a partir de conjuntos de dados temporais e relacionais. Pode ser integrado com ferramentas já existentes para desenvolver pipelines de ML.
A solução utiliza Deep Feature Synthesis para automatizar a engenharia de recursos, contando com uma biblioteca de funções de baixo nível para criação de recursos e uma API ideal para tratamento preciso do tempo.
#2. CatBoost
Para quem procura uma biblioteca de código aberto que combine diversas árvores de decisão para criar um modelo preditivo robusto, CatBoost é uma ótima opção. Esta solução oferece resultados precisos com parâmetros padrão, dispensando horas de ajuste manual.
CatBoost também possibilita a utilização de fatores não numéricos para aprimorar os resultados do treinamento, oferecendo maior precisão e previsões rápidas.
#3. Feature-engine
Feature-engine é uma biblioteca Python com transformadores e recursos selecionados que podem ser usados em modelos de ML. Seus transformadores são capazes de realizar transformações de variáveis, criação de variáveis, tratamento de data e hora, pré-processamento, codificação categórica, tratamento de outliers e imputação de dados faltantes. Além disso, a biblioteca reconhece automaticamente variáveis numéricas, categóricas e de data e hora.
Recursos de Aprendizagem em Engenharia de Recursos
Cursos Online e Aulas Virtuais

#1. Engenharia de Recursos para Aprendizado de Máquina em Python: Datacamp
Este curso do Datacamp sobre engenharia de recursos para aprendizado de máquina em Python permite que você crie novos recursos que melhoram o desempenho do modelo de aprendizado de máquina. Ele ensina engenharia de recursos e processamento de dados para o desenvolvimento de aplicativos sofisticados de ML.
#2. Engenharia de Recursos para Aprendizado de Máquina: Udemy
No curso de Engenharia de Recursos para Aprendizado de Máquina, você aprenderá tópicos como imputação, codificação de variáveis, extração de recursos, discretização, funcionalidades de data e hora, outliers etc. Também aprenderá a trabalhar com variáveis assimétricas e a lidar com categorias raras e invisíveis.
#3. Engenharia de Recursos: Pluralsight
Este caminho de aprendizado do Pluralsight possui um total de seis cursos. Eles o ajudarão a entender a importância da engenharia de recursos no fluxo de trabalho de ML, a aplicar suas técnicas e a extrair recursos de texto e imagens.
#4. Seleção de Recursos para Aprendizado de Máquina: Udemy
Com a ajuda deste curso da Udemy, você aprenderá técnicas como embaralhamento de recursos, filtro, wrapper e métodos incorporados, eliminação recursiva de recursos e pesquisa exaustiva. Ele também aborda técnicas de seleção de recursos, incluindo aquelas com Python, Lasso e árvores de decisão, com 5,5 horas de vídeo sob demanda e 22 artigos.
#5. Engenharia de Recursos para Aprendizado de Máquina: Great Learning
Este curso do Great Learning irá apresentá-lo à engenharia de recursos, ao mesmo tempo que aborda sobreamostragem e subamostragem, permitindo que você realize exercícios práticos de ajuste de modelos.
#6. Engenharia de Recursos: Coursera
Junte-se ao curso do Coursera para usar BigQuery ML, Keras e TensorFlow na engenharia de recursos. Este curso de nível intermediário também cobre práticas avançadas.
Livros Digitais ou de Capa Dura

#1. Engenharia de Recursos para Aprendizado de Máquina
Este livro aborda como transformar recursos para formatos adequados para modelos de aprendizado de máquina.
Ele também oferece os princípios da engenharia e aplicação prática por meio de exercícios.
#2. Engenharia e Seleção de Recursos
Este livro apresenta os métodos para desenvolver modelos preditivos em diferentes fases.
Com ele, você pode aprender as técnicas para encontrar as melhores representações de preditores para modelagem.
#3. Engenharia de Recursos Facilitada
Este livro é um guia para potencializar o poder de previsão dos algoritmos de ML.
Ele ensina a projetar e criar recursos eficientes para aplicativos baseados em ML, oferecendo insights de dados detalhados.
#4. Bookcamp de Engenharia de Recursos
Este livro aborda estudos de caso práticos para ensinar técnicas de engenharia de atributos, visando melhores resultados de ML e organização atualizada dos dados.
Com ele, você obterá resultados melhores sem gastar tempo excessivo no ajuste de parâmetros de ML.
#5. A Arte da Engenharia de Recursos
O recurso funciona como um elemento essencial para qualquer cientista de dados ou engenheiro de aprendizado de máquina.
O livro adota uma abordagem de vários domínios para discutir gráficos, textos, séries temporais, imagens e estudos de caso.
Conclusão
Assim se realiza a engenharia de recursos. Agora que você conhece a definição, o processo passo a passo, os métodos e os recursos de aprendizado, pode implementá-los em seus projetos de ML e alcançar o sucesso!
A seguir, confira o artigo sobre aprendizado por reforço.