É chegada a hora de selecionar o banco de dados *serverless* mais apropriado para o seu aplicativo moderno.
Bancos de dados *serverless* foram concebidos para lidar com cargas de trabalho que flutuam e mudam rapidamente. Como resultado, inúmeras organizações adotaram arquiteturas *serverless* para desenvolver sistemas modernos orientados a eventos. Isso resultou em um aumento da popularidade dentro do ecossistema de tecnologias *serverless*.
Introdução aos Bancos de Dados *Serverless*
A computação *serverless* exige um banco de dados *serverless*. Esses bancos de dados são projetados para lidar com cargas de trabalho imprevisíveis que se transformam rapidamente. E mais?
Você paga somente pelos recursos de banco de dados que usar, com cobrança por segundo. Além disso, bancos de dados na nuvem, como o Amazon Aurora, compatíveis com MySQL e PostgreSQL, podem ser totalmente gerenciados e escalados até 64 TB.
É possível criar um banco de dados ao escolher o tamanho da instância. Isso funciona bem quando há uma carga de trabalho, taxa de solicitação e necessidades de processamento previsíveis.
Pode ser complicado planejar a quantidade exata de capacidade nos casos em que a carga de trabalho é irregular e há um volume alto de solicitações durante poucos minutos por semana ou em apenas um dia. No entanto, pode não ser vantajoso pagar por essa capacidade de forma contínua.
É nesse cenário que o banco de dados *serverless* entra em ação.
Características de Bancos de Dados *Serverless*

Confira as principais características dos bancos de dados *serverless*:
- Acesso em tempo real: o acesso aos seus dados é excelente. Ele indexa automaticamente os dados e os disponibiliza imediatamente. Isso possibilita consultar, ler, atualizar e adicionar elementos ao seu banco de dados *serverless* de forma contínua. E mais? Você poderá acessá-lo instantaneamente por meio de funções.
- Escalabilidade infinita: você pode aumentar ou diminuir a capacidade dos bancos de dados *serverless* a qualquer momento. Eles iniciam e desligam de acordo com as necessidades do aplicativo. O sistema escalará as unidades de computação (ACUs no caso do Aurora *Serverless*) para processar suas consultas, leitura e gravação no mesmo cluster de dados. Essa automação permitirá que você execute todas as suas funções simultaneamente e garanta que seus dados permaneçam consistentes.
- Alta segurança: aplicativos modernos podem ser expostos a públicos mal-intencionados e não confiáveis em escala global. O sistema garante que todos os aplicativos que interagem com o mesmo banco de dados sigam o mesmo protocolo de controle de acesso. Isso reduz a superfície de ataque, que é um risco crítico para as empresas.
- Disponibilidade: o banco de dados *serverless* oferece a capacidade de reduzir a latência. Essa abordagem possibilita que os dados das funções orientadas a eventos sejam lidos diretamente pelo usuário.
- Sem esquema: a ausência de esquema permite que você lide com todas as saídas de dados de suas funções. É simples integrar o banco de dados *serverless* com suas funções usando esta abordagem de “lidar com tudo”. Esta é uma característica exclusiva dos bancos de dados *serverless*.
Agora vamos explorar alguns dos melhores bancos de dados *serverless* para aplicações modernas.
Fauna
Fauna é um banco de dados distribuído e *serverless*. Fauna oferece uma flexibilidade excepcional. Você pode ajustar inúmeros parâmetros para atender às necessidades do seu projeto. O Fauna pode ser usado como um banco de dados de valor-chave, gráfico, baseado em documentos ou relacional tradicional. Você pode construir um esquema ou liberar os dados.
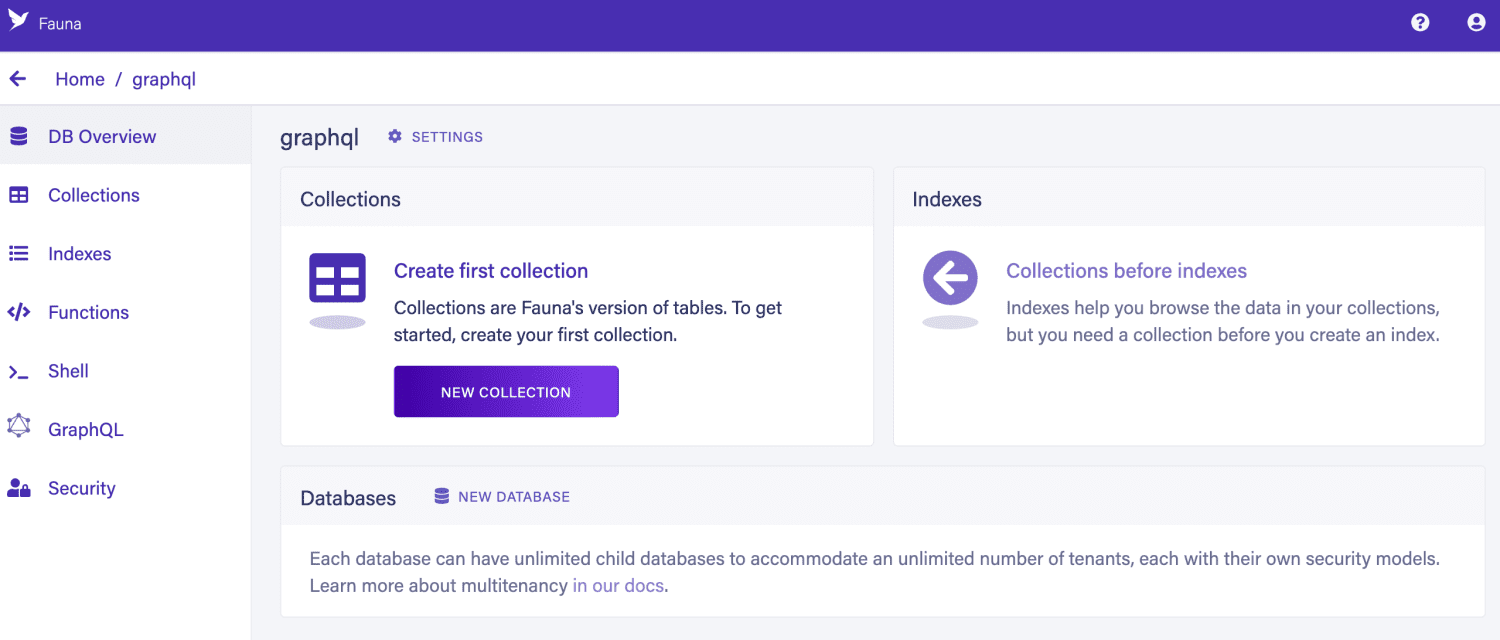
É extremamente versátil. O Fauna pode ser executado na nuvem, no local ou incorporado ao nosso aplicativo. Ele também oferece as opções de implantação mais usadas, como imagens de máquina ou imagens *docker*. Este aplicativo pode ser executado em velocidades muito altas e funciona bem com transações ACID.
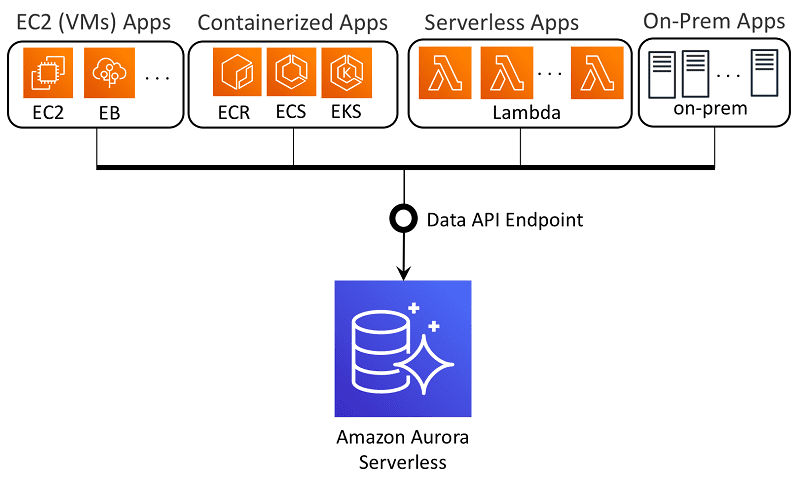
Amazon Aurora
O Amazon Aurora é um serviço de armazenamento de dados relacional acessível na nuvem da Amazon. Esse serviço é amplamente utilizado para armazenamento de dados. Ele possibilita armazenamento de dados de baixa latência e baseado em valor.
 Crédito da imagem: AWS
Crédito da imagem: AWS
O Amazon Aurora é um banco de dados relacional compatível com PostgreSQL e MySQL que une a acessibilidade e o desempenho de bancos de dados tradicionais com a confiabilidade e a simplicidade dos bancos de dados comerciais a um décimo do custo. Ele utiliza uma abordagem em cluster para replicação de dados na zona de acessibilidade da AWS para disponibilidade eficiente de dados.
O Amazon Aurora possui muitos subsistemas de alto desempenho. O armazenamento distribuído mais rápido é usado pelos mecanismos MySQL e PostgreSQL. O Aurora acelera a taxa de transferência e o desempenho do MySQL em 5x e 3x, respectivamente, quando comparado com o sistema atual.
O banco de dados pode ser escalado para até 64 Terabytes, oferecendo suporte para implementação empresarial. O Amazon Aurora é totalmente gerenciado pelo Amazon Relational Database Service (RDS), que automatiza tarefas administrativas como provisionamento de *hardware*, organização de dados, correção, reforços e muito mais.
Bit.io
bit.io permite que você configure um banco de dados PostgreSQL de forma rápida e fácil. Arraste e solte arquivos para carregar dados em um banco de dados PostgreSQL. Você também pode inserir um URL para um arquivo, enviar dados de R ou Python ou usar qualquer outro cliente Postgres/HTTP.
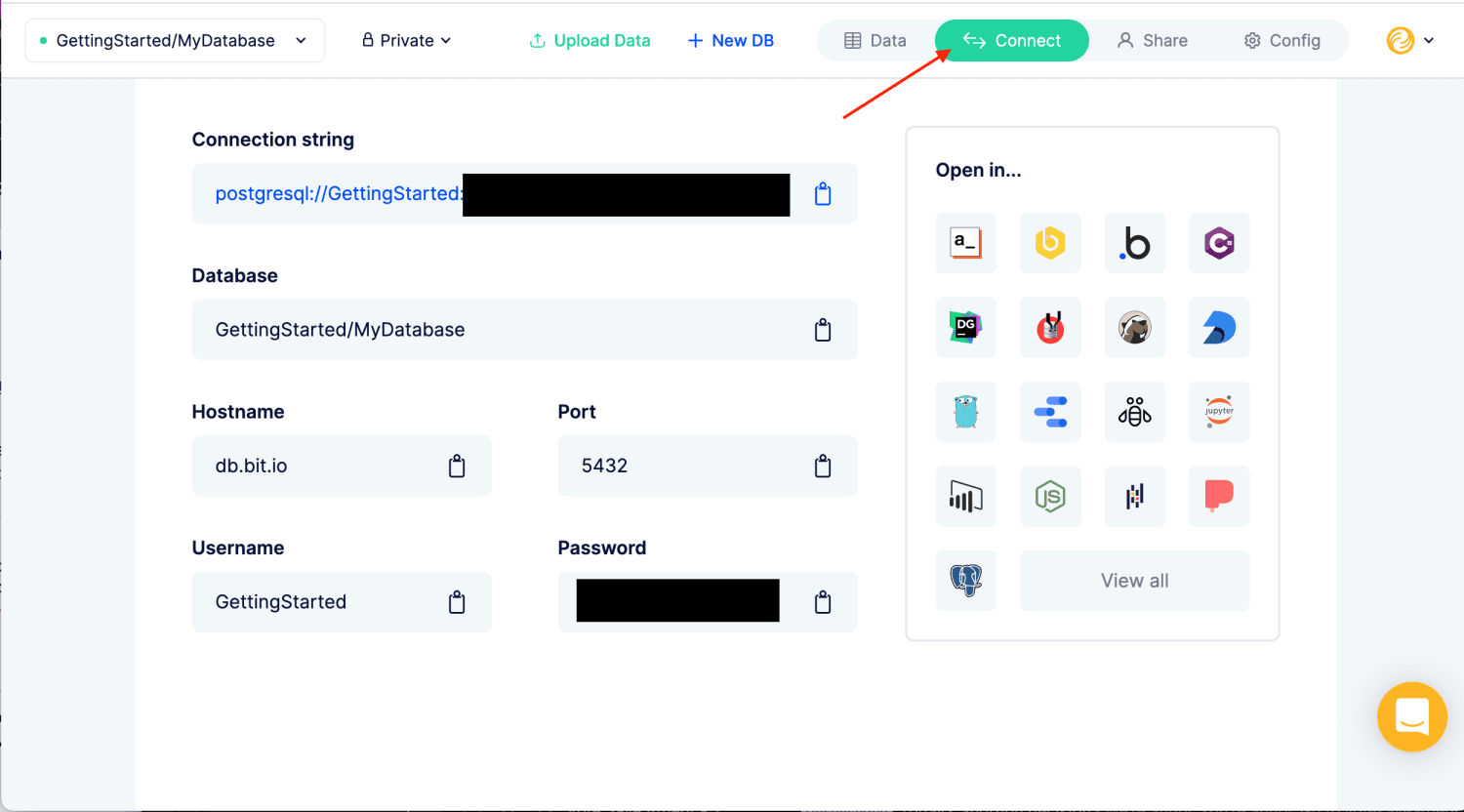
O editor SQL no navegador permite que você trabalhe com os dados usando qualquer uma de suas ferramentas de análise de dados favoritas, incluindo clientes SQL, *notebooks* R e Python, linha de comando e muito mais.
bit.io fornece um banco de dados PostgreSQL completo. Pode ser usado rapidamente e praticamente sem configuração. Ele também se integra a um número crescente de ferramentas de dados. bit.io funcionará com qualquer ferramenta que suporte PostgreSQL.
Upstash
Upstash é um banco de dados de nuvem em memória e *serverless* criado pela Upstash Inc (uma empresa com sede na Califórnia). Ele pode ser usado como uma camada de *cache* ou como um banco de dados. Não exige que você gerencie *clusters* ou servidores de banco de dados. É completamente *serverless*.
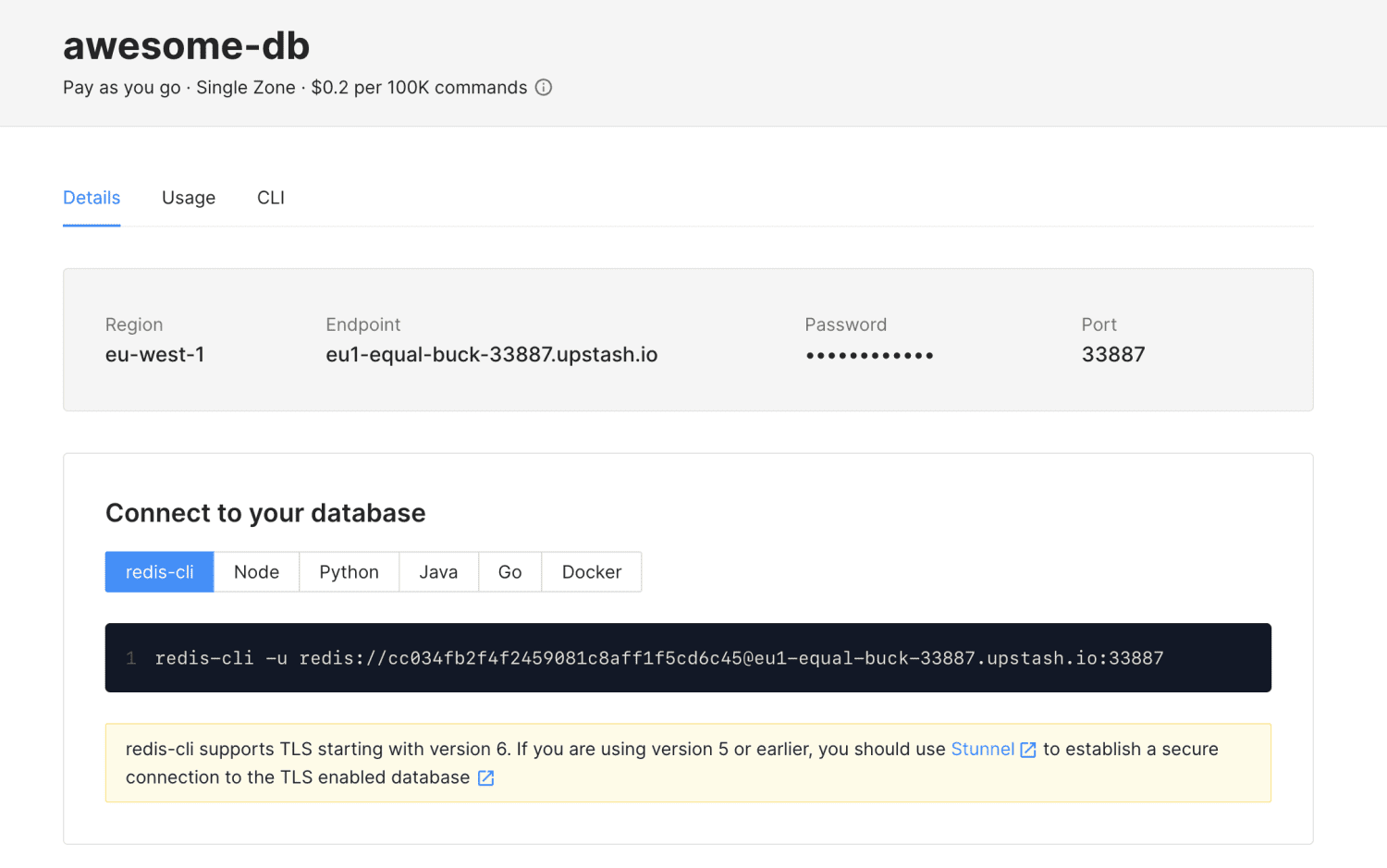
É por isso que tecnologias *serverless*, como o Upstash, são tão úteis. O Upstash não cobra nada se você não o usar. O Upstash pode ser usado para casos de uso populares do Redis, como:
- *Cache* geral
- *Cache* de sessão
- Tabelas de classificação
- Filas
- Medição de uso (contagem)
- Filtragem de conteúdo
Recursos:
- Projetado para *serverless*
- Pague conforme você usa
- Baixa latência
- Armazenamento rápido e durável
Xata
Xata, um banco de dados *serverless*, possui pesquisa e análise robustas embutidas. O Xata utiliza um modelo de banco de dados relacional com um esquema estrito (esquema) e oferece suporte a objetos similares a JSON. Os registros são organizados em tabelas que são agrupadas em bancos de dados.
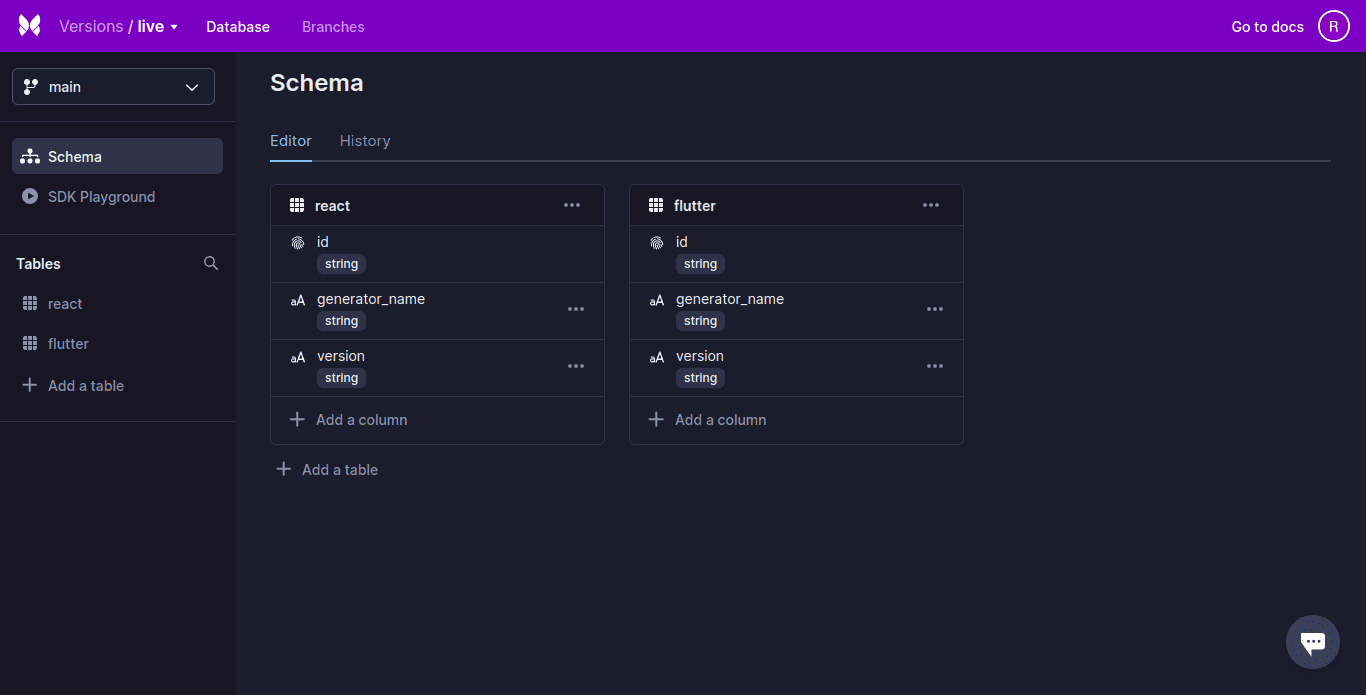
O Xata oferece suporte a colunas ricas, e os relacionamentos entre as tabelas podem ser representados usando colunas de link. Estas são similares à chave estrangeira.
O Xata, um novo tipo de serviço em nuvem, oferece uma camada de abstração sobre vários armazenamentos de dados para simplificar o desenvolvimento e a operação de aplicações. Esse tipo de serviço é chamado de plataforma de dados *serverless*. Este documento pode ser usado para auxiliá-lo a replicar a arquitetura, o que lhe dará algumas das vantagens de usar o Xata.
SurrealDB
O SurrealDB, um banco de dados na nuvem NewSQL inovador, pode ser usado para aplicações *serverless*, *jamstack*, de página única, tradicionais e não *serverless*. Ele oferece flexibilidade e valor financeiro incomparáveis. Ele pode ser implantado em ambientes locais, incorporados ou de computação de borda, além de poder ser implantado na nuvem.
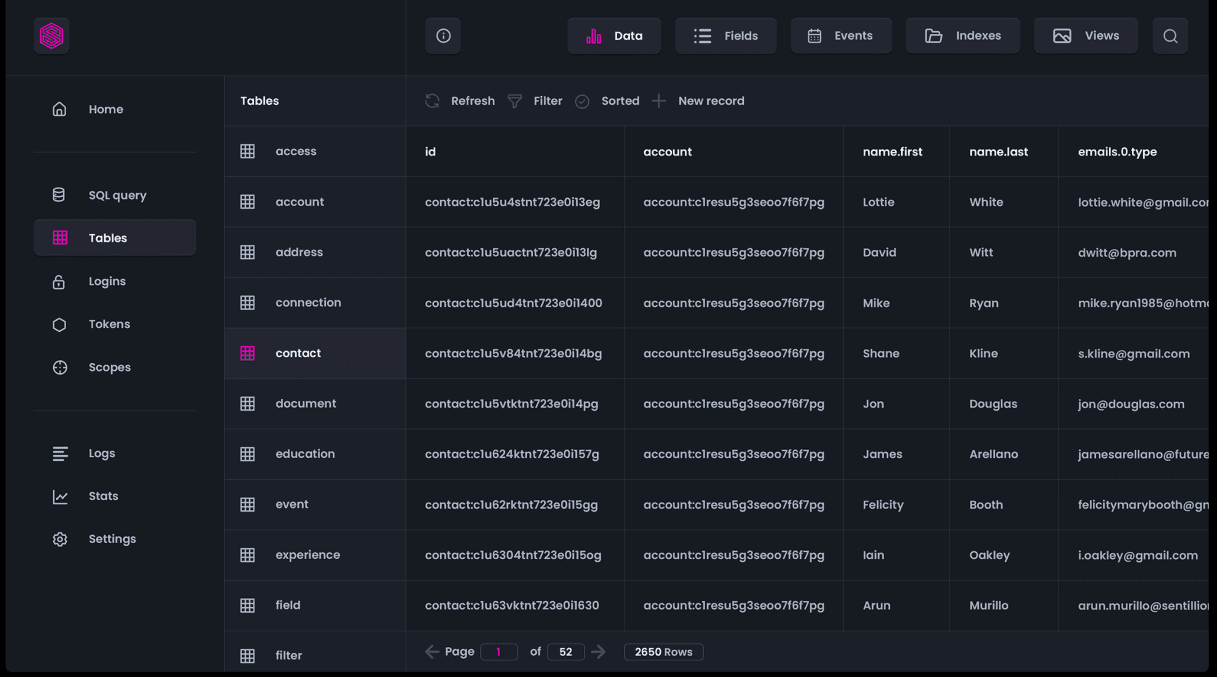
Sua equipe não precisa ser especialista em linguagens complexas de banco de dados. A funcionalidade avançada também é simples e direta, mas ainda rápida e eficiente. Você pode esquecer de dimensionar servidores, bancos de dados, balanceadores de carga e *endpoints* de API.
O SurrealDB elimina a complexidade de sua pilha e permite que você expanda com uma plataforma distribuída e de alta disponibilidade. O SurrealDB Cloud permite que você implante em qualquer lugar.
Cosmos DB
O Azure Cosmos DB, um banco de dados global distribuído baseado em JSON, está disponível como uma ‘plataforma como serviço’ (PaaS) no Microsoft Azure. Ele permite que os usuários construam e distribuam aplicativos automaticamente nos *datacenters* do Azure sem configuração.
Faz parte do Azure e está disponível em todas as regiões. Ele também replica dados em vários *datacenters* na rede.
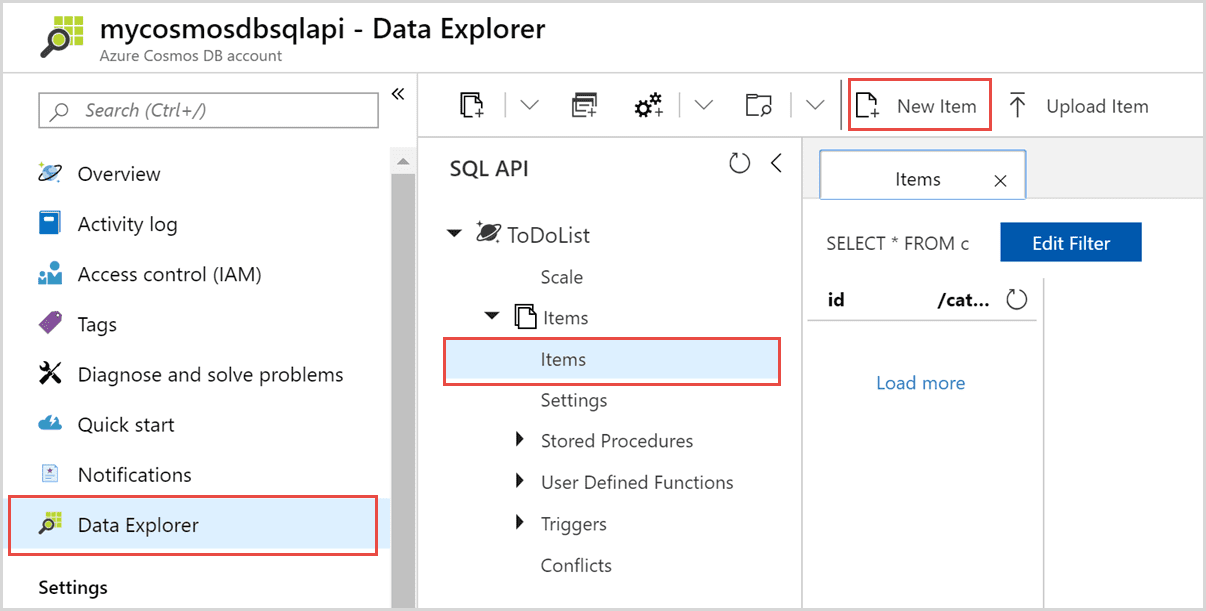
Há muitas interfaces disponíveis, sendo a mais interessante baseada em SQL. O CosmosDB é o serviço ideal para organizações que processam, consultam e gerenciam muitas informações importantes e de curta duração.
CockroachDB
CockroachDB é um banco de dados SQL distribuído construído sobre um valor-chave consistente e armazenamento transacional.
É escrito em Go e é totalmente de código aberto. Seus principais objetivos incluem o suporte a transações ACID, escalabilidade horizontal e capacidade de sobrevivência. Ele visa tolerar qualquer coisa, desde uma única falha de disco até uma operação completa de recuperação de desastres, sem qualquer intervenção manual e com interrupção mínima de latência.
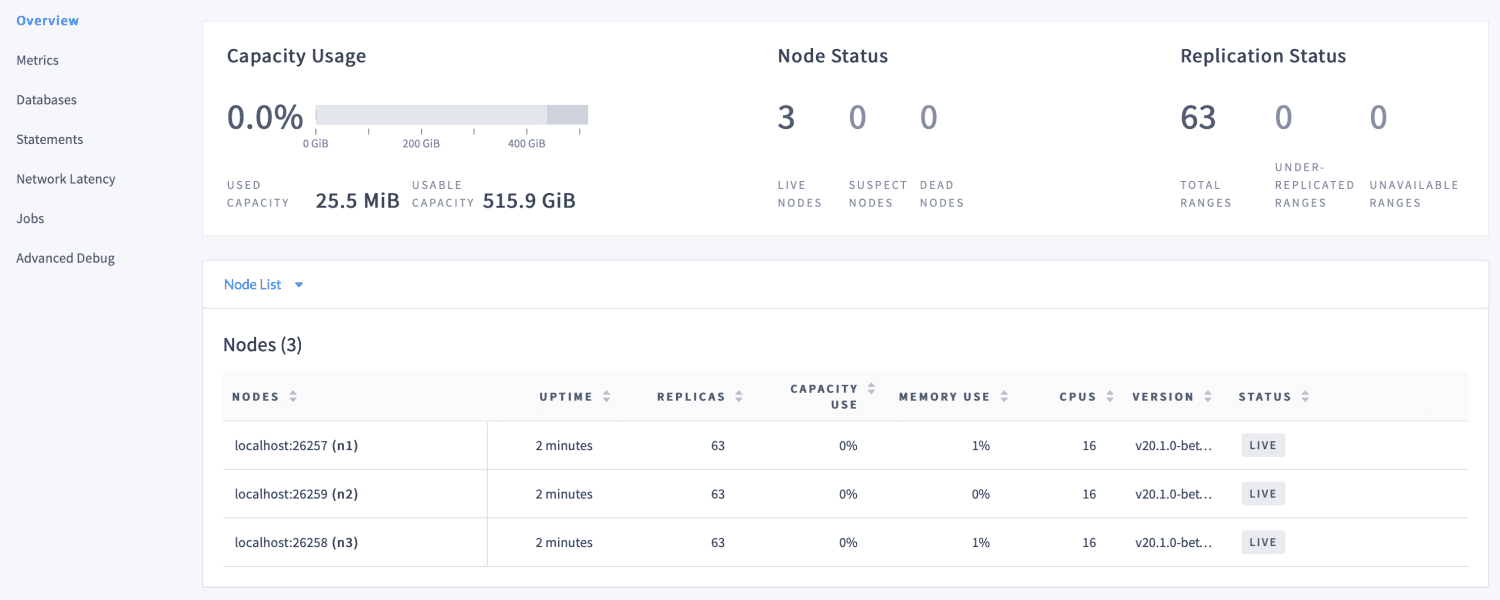
O CockroachDB é uma boa opção para aplicativos que precisam de dados confiáveis, precisos e disponíveis em todas as escalas. Você pode acessar a interface do usuário do administrador, que vem em um pacote com o CockroachDB em http://localhost:8080 assim que o *cluster* estiver funcionando.
Ele fornece informações sobre a configuração do *cluster* e do banco de dados e nos ajuda a otimizar o desempenho do *cluster* monitorando métricas como integridade, métricas de tempo de execução, replicação e detalhes do nó.
PlanetScale
PlanetScale é uma nova plataforma DBaaS que permite criar rapidamente um banco de dados sem qualquer gerenciamento de conexão. Os bancos de dados PlanetScale foram projetados para desenvolvedores e seus fluxos de trabalho. Você pode implantar um banco de dados totalmente gerenciado com a confiabilidade e a flexibilidade do MySQL. Seus bancos de dados são construídos no MySQL 8.0.
O PlanetScale oferece dois tipos de ramificações de banco de dados: produção e desenvolvimento. Seu recurso de ramificação permite tratar seus bancos de dados como código. Você pode criar uma ramificação de seu esquema de banco de dados de produção que será usada para ambientes de desenvolvimento isolados.
Conclusão
Isso foi tudo sobre os melhores bancos de dados *serverless* para aplicações modernas. Os bancos de dados *serverless*, especialmente o Amazon Aurora *Serverless*, são um futuro promissor. Graças a essa nova tecnologia, agora podemos nos concentrar no acesso em tempo real aos dados, escalabilidade e segurança.
Você também pode se interessar por 7 maneiras pelas quais a computação *serverless* é uma tecnologia em ascensão.