O Apache Kafka representa uma plataforma de streaming de mensagens, facilitando a comunicação e o compartilhamento de dados entre diversas aplicações dentro de um sistema distribuído. Essa troca ocorre através de mensagens, garantindo a fluidez das informações.
Seu funcionamento segue um modelo de publicação/assinatura, onde aplicações produtoras emitem mensagens e sistemas consumidores se inscrevem para recebê-las. Este mecanismo assegura uma distribuição eficiente e organizada dos dados.
A adoção do Apache Kafka promove uma arquitetura de baixo acoplamento entre os componentes de um sistema que geram e utilizam dados. Tal abordagem simplifica o design e a gestão do sistema como um todo. O Kafka utiliza o Zookeeper para administrar metadados e coordenar os diversos elementos do cluster.
Atributos Notáveis do Apache Kafka
O Apache Kafka consolidou sua popularidade devido, entre outros fatores, a:
- Sua escalabilidade, suportada por clusters e partições eficientes
- Sua alta velocidade, com capacidade para processar até 2 milhões de gravações por segundo
- A manutenção da ordem cronológica das mensagens enviadas
- Sua confiabilidade, garantida pelo sistema de réplicas
- A capacidade de ser atualizado sem interrupções no serviço
A seguir, exploraremos algumas das aplicações mais comuns do Kafka.
Aplicações Práticas do Apache Kafka
O Kafka é frequentemente empregado no processamento de grandes volumes de dados, no registro e agregação de eventos (como cliques em botões para análise) e na centralização de logs de diferentes partes de um sistema. Sua versatilidade o torna uma ferramenta valiosa em diversos cenários.
Além disso, ele possibilita a comunicação entre diferentes aplicações dentro de um sistema e viabiliza o processamento em tempo real de dados provenientes de dispositivos IoT, o que aumenta sua relevância em aplicações modernas.
Agora, vamos detalhar os passos necessários para instalar o Kafka tanto no Windows quanto no Linux.
Instalando o Kafka no Windows
Antes de iniciar a instalação do Apache Kafka no Windows, é fundamental verificar se o Java está corretamente instalado. Para isso, abra o Prompt de Comando como Administrador e execute o seguinte comando:
java --version
Se o Java estiver instalado, você verá a versão do JDK atualmente em uso.
Caso apareça uma mensagem de erro indicando que o comando não foi reconhecido, isso significa que o Java não está instalado e precisa ser configurado. Para instalar o Java, acesse o site Adoptium.net e clique no botão de download.
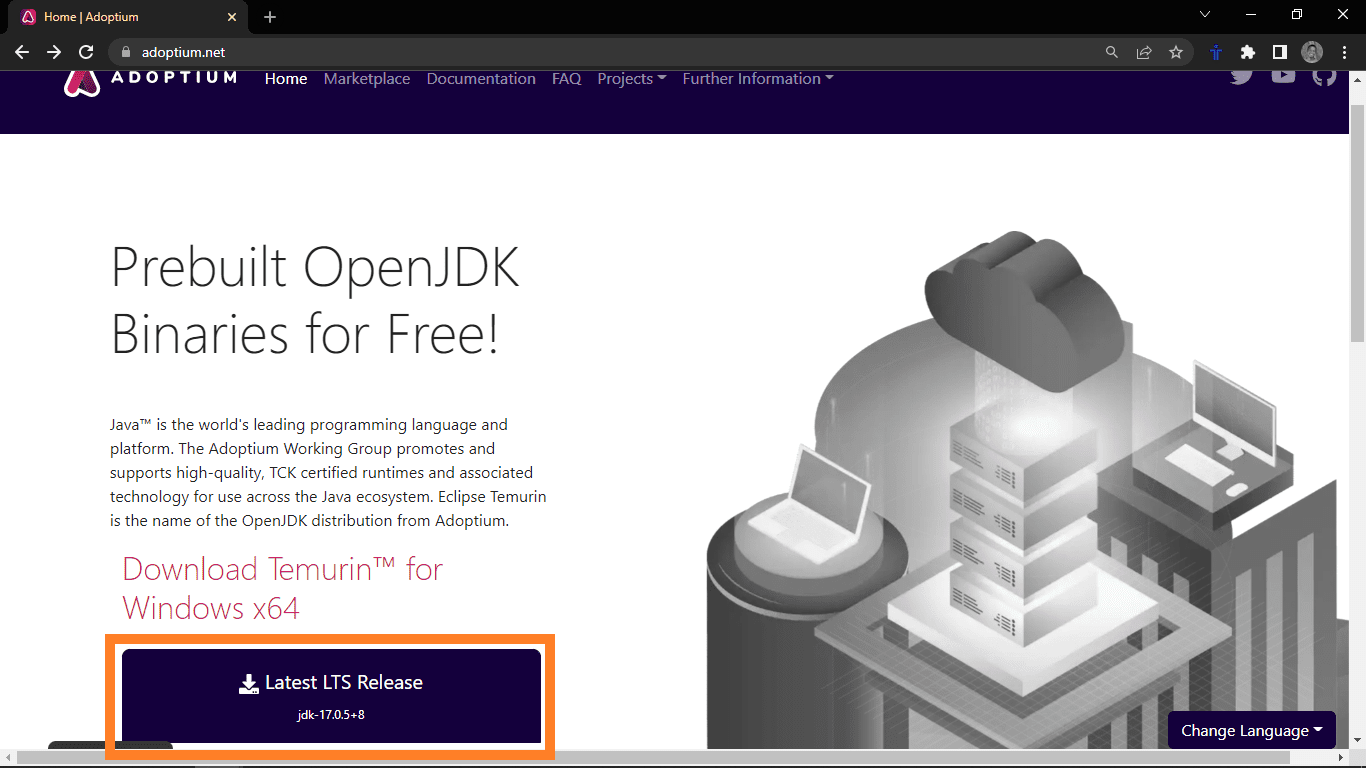
Isso iniciará o download do instalador do Java. Após a conclusão do download, execute o instalador, que abrirá o processo de instalação.
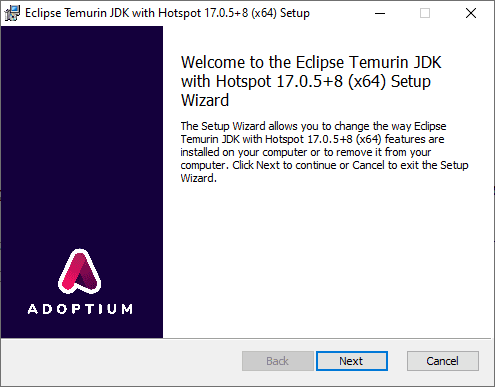
Pressione “Avançar” para aceitar as configurações padrão. A instalação começará logo em seguida. Para verificar se a instalação foi bem-sucedida, feche o Prompt de Comando, abra-o novamente como Administrador e digite o comando:
java --version
Agora, você deverá ver a versão do JDK que acabou de instalar. Com a instalação do Java confirmada, podemos prosseguir para a instalação do Kafka.
Para instalar o Kafka, acesse o site oficial do Kafka.

Clique no link que leva à página de downloads e escolha a versão binária mais recente.
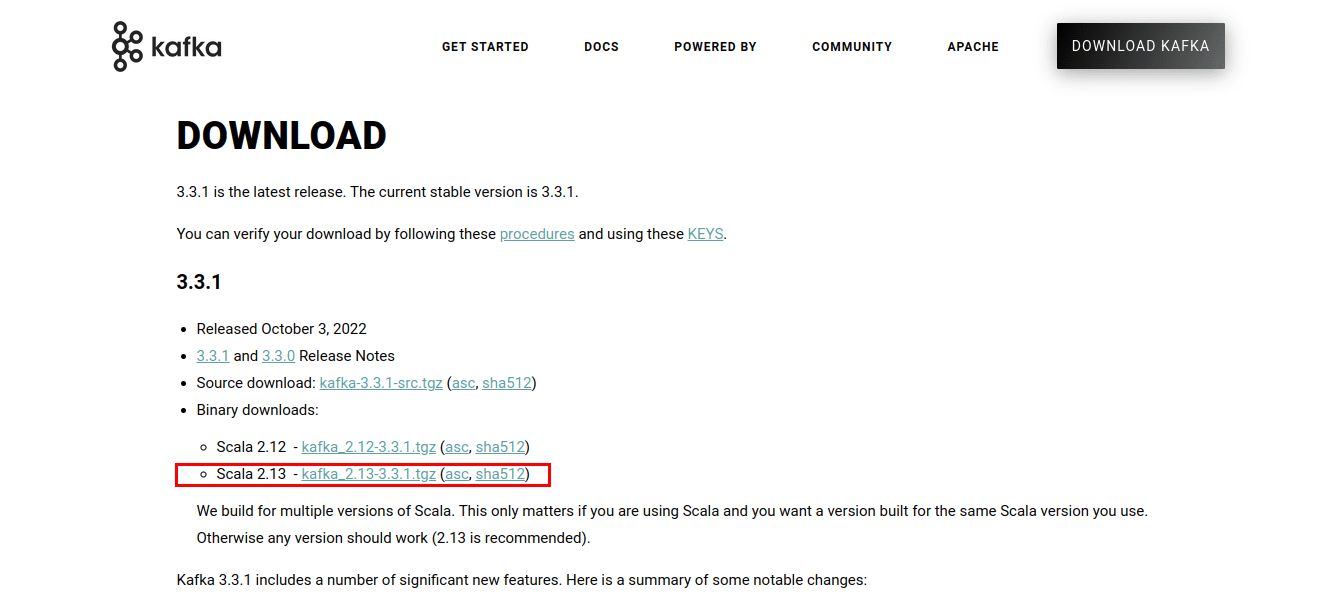
O download resultará em um arquivo .tgz contendo os scripts e binários do Kafka. Após o download, você precisará extrair os arquivos. Para isso, você pode usar o WinZip, disponível para download em seu site oficial.
Após a extração, mova a pasta extraída para C: para que o caminho se torne C:kafka.
Em seguida, abra o Prompt de Comando como Administrador e inicie o Zookeeper navegando até o diretório do Kafka e executando o arquivo zookeeper-server-start.bat com o arquivo de configuração zookeeper.properties.
cd C:kafka binwindowszookeeper-server-start.bat configzookeeper.properties
Com o Zookeeper em execução, adicione o executável wmic, utilizado pelo Kafka, ao PATH do sistema.
set PATH=C:WindowsSystem32wbem;%PATH%;
Feito isso, inicie o servidor Apache Kafka abrindo outra sessão do Prompt de Comando como Administrador e navegando até a pasta C:kafka.
cd C:kafka
Em seguida, inicie o Kafka com o comando:
binwindowskafka-server-start.bat configserver.properties
Neste ponto, o Kafka deve estar em funcionamento. Você pode personalizar as propriedades do servidor, como o local de armazenamento dos logs, no arquivo server.properties.
Instalando o Kafka no Linux
Inicialmente, garanta que seu sistema esteja atualizado, atualizando todos os pacotes.
sudo apt update && sudo apt upgrade
Verifique se o Java está instalado executando o comando:
java --version
Se o Java estiver instalado, você verá a versão. Caso contrário, você pode instalá-lo usando o apt.
sudo apt install default-jdk
Com o Java configurado, podemos prosseguir para a instalação do Apache Kafka, baixando os binários do site.
Abra o terminal e navegue até o diretório onde o download foi salvo. No exemplo, o download está na pasta Downloads.
cd Downloads
Na pasta de downloads, extraia os arquivos baixados com o comando tar:
tar -xvzf kafka_2.13-3.3.1.tgz
Acesse a pasta extraída:
cd kafka_2.13-3.3.1.tgz
Liste os diretórios e arquivos para confirmar a extração.
Dentro da pasta, inicie o servidor Zookeeper executando o script zookeeper-server-start.sh, localizado no diretório bin da pasta extraída.
Este script requer um arquivo de configuração do Zookeeper, geralmente o zookeeper.properties, localizado no subdiretório config.
Para iniciar o servidor, utilize o comando:
bin/zookeeper-server-start.sh config/zookeeper.properties
Com o Zookeeper em execução, podemos iniciar o servidor Apache Kafka. O script kafka-server-start.sh também está no diretório bin e também necessita de um arquivo de configuração, que por padrão é o server.properties, armazenado na pasta config.
bin/kafka-server-start.sh config/server.properties
Com isso, o Apache Kafka estará operacional. Dentro do diretório bin, você encontrará vários scripts para diversas operações, como criação de tópicos, gerenciamento de produtores e consumidores. Você também pode customizar as propriedades do servidor no arquivo server.properties.
Considerações Finais
Neste guia, abordamos o processo de instalação do Java e do Apache Kafka. Embora seja possível configurar e gerenciar clusters Kafka manualmente, também existem opções gerenciadas, como os serviços da Amazon Web Services e da Confluent.
Como próximo passo, você pode aprender sobre o processamento de dados utilizando Kafka e Spark.