
O mundo em que vivemos é movido por dados. Obter informações poderosas em tempo real sobre dados do mundo real permite que sua empresa tenha uma vantagem. O streaming de dados permite a captura e o processamento contínuos de dados provenientes de várias fontes de dados, e é por isso que boas plataformas de streaming de dados são importantes.
As plataformas de streaming de dados são sistemas escaláveis, distribuídos e altamente eficientes que garantem o processamento confiável de fluxos de dados. Eles suportam agregação e análise de dados e geralmente vêm com um painel unificado para visualizar seus dados.
Você pode escolher entre uma ampla variedade de plataformas e soluções de streaming de dados — desde sistemas totalmente gerenciados como Confluent Cloud e Amazon Kinesis até soluções de código aberto como Arroyo e Fluvio.
últimas postagens
Quais são alguns casos de uso para streaming de dados?
As plataformas de streaming de dados abrangem uma ampla variedade de casos de uso. Vamos passar rapidamente por alguns deles:
- A detecção de fraudes é feita analisando continuamente as transações, o comportamento do usuário e os padrões.
- Os dados de negociação do mercado de ações são capturados por vários sistemas que fazem negócios de alto volume com rapidez incrível com base na análise de mercado.
- Insights personalizados por meio de dados de mercado em tempo real fornecem aos mercados de comércio eletrônico o público certo para direcionar seus produtos.
- Existem milhões de sensores em vários sistemas que fornecem dados do mundo real e ajudam em informações preditivas, como previsões do tempo.
Aqui estão as melhores plataformas de dados para todas as suas necessidades de análise e processamento em tempo real.
nuvem confluente

Uma oferta totalmente nativa da nuvem do Apache Kafka, nuvem confluente fornece resiliência, escalabilidade e alto desempenho. Você obtém o poder do mecanismo Kora personalizado que fornece desempenho 10 vezes melhor do que executar seu próprio cluster Kafka. Ele traz para você os seguintes recursos:
- Clusters sem servidor oferecem escalabilidade e elasticidade. Você pode atender instantaneamente aos seus requisitos de streaming de dados com aumento e redução automáticos sob demanda.
- Seus requisitos de armazenamento de dados são atendidos com retenção de dados infinita e integridade de dados. Sem problemas de durabilidade, você pode fazer do Confluent Cloud sua fonte confiável.
- O Confluent Cloud oferece um SLA de tempo de atividade de 99,99%, um dos melhores do setor. Emparelhado com a replicação multizona, você fica protegido contra corrupção ou perda de dados.
O Stream Designer capacita você com uma IU de arrastar e soltar para criar visualmente seu pipeline de processamento. Além disso, os conectores Kafka pré-criados permitem que você se conecte a qualquer aplicativo ou provedor de dados.
O Confluent Cloud fornece a você o Stream Governance, o único conjunto de governança de dados do setor que é totalmente gerenciado. Ter segurança e conformidade em nuvem de nível empresarial permite que você proteja seus dados e controle o acesso.
O Confluent Cloud oferece diferentes opções de preços. Ele também oferece uma ampla gama de recursos para ajudá-lo a mergulhar de cabeça.
Aiven

Aiven ajuda você a executar suas necessidades de streaming de dados em um serviço de nuvem Apache Kafka totalmente gerenciado. Ele suporta todos os principais provedores de nuvem, incluindo AWS, Google Cloud, Microsoft Azure, Digital Ocean e UpCloud.
Configure seu próprio serviço Kafka em menos de 10 minutos usando o console da Web ou programaticamente por meio da API e da CLI. Além disso, você tem a opção de executá-lo em contêineres.
Ignore o incômodo de se preocupar com o gerenciamento do Kafka com um serviço de nuvem totalmente gerenciado. Você pode configurar seu pipeline de dados rapidamente junto com um painel de monitoramento. Vamos dar uma olhada nos benefícios que você terá:
- Receba atualizações automáticas para seu cluster e gerencie seus upgrades de versão e manutenção com apenas alguns cliques.
- O Aiven oferece 99,99% de tempo de atividade e quase zero interrupções.
- Aumente seu armazenamento sob demanda, adicione mais nós Kafka ou implante em diferentes regiões.
Mensalidade de Aiven preços começa em $ 200 e varia de acordo com sua localização e o provedor de nuvem que você escolher.
arroio
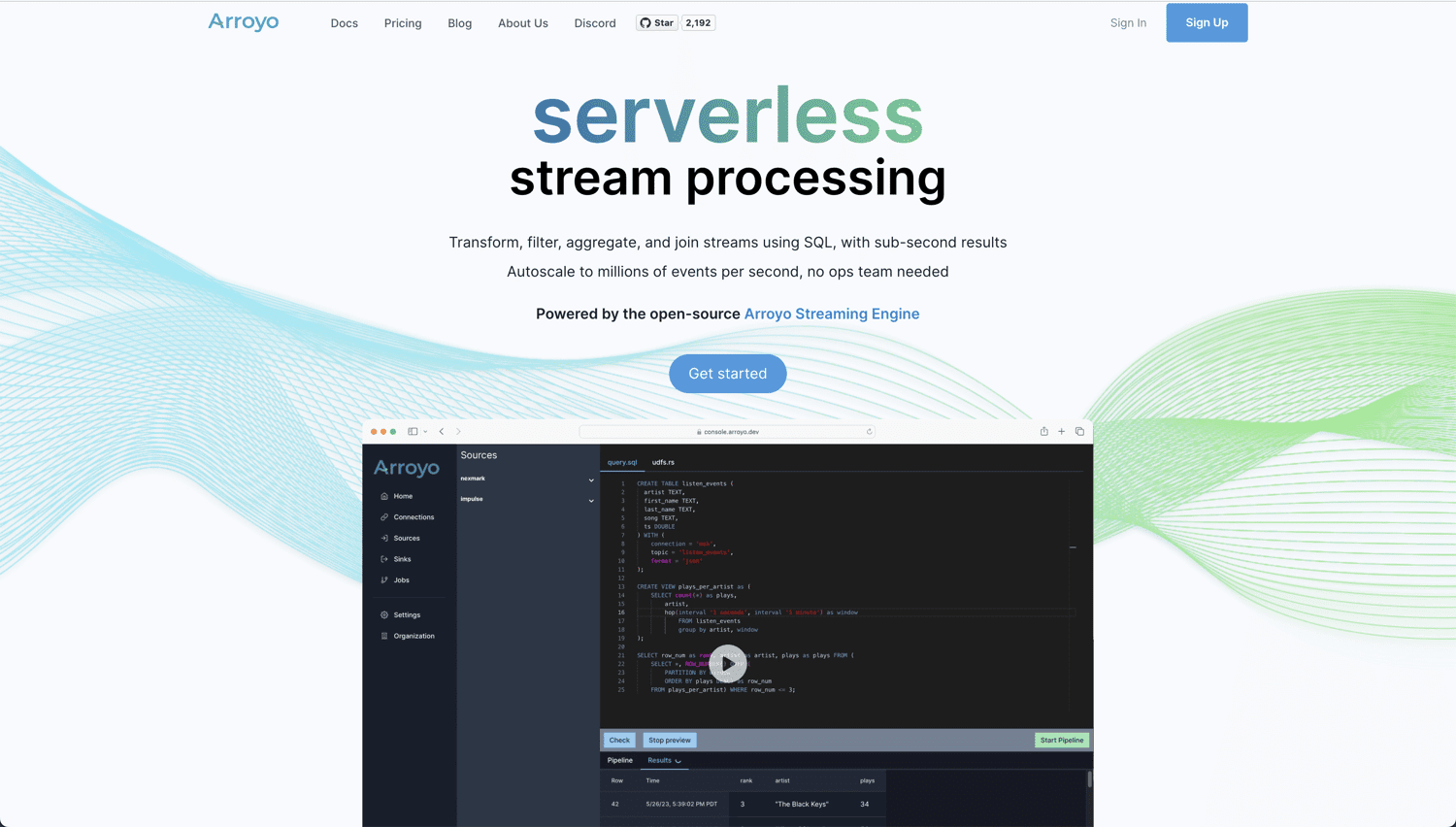
Se você está procurando uma solução verdadeiramente nativa da nuvem e de código aberto para sua análise e processamento em tempo real, arroio é uma ótima ferramenta. Ele é alimentado pelo Arroyo Streaming Engine — uma solução de processamento de fluxo distribuído que brilha quando se trata de pesquisa de dados em tempo real com resultados abaixo de um segundo.
O Arroyo foi desenvolvido para tornar o processamento em tempo real tão fácil quanto o processamento em lote. Sendo altamente amigável por design, você não precisa ser um especialista para construir seu pipeline. Aqui está o que você ganha com Arroyo:
- Há suporte nativo para diferentes conectores, incluindo Kafka, Pulsar, Redpanda, WebSockets e Server Sent Events.
- Após a ingestão e processamento de dados, os resultados de saída podem ser gravados em vários sistemas – como Kafka, Amazon S3 e Postgres.
- Você obtém um compilador de última geração, eficiente e de alto desempenho que transforma suas consultas SQL para serem executadas com a máxima eficiência.
- O fluxo de dados para suas plataformas de dados pode escalar horizontalmente para suportar milhões de eventos por segundo.
Você pode executar sua instância auto-hospedada do Arroyo, que é gratuita, ou usar a ajuda do Arroyo Cloud, a partir de US$ 200 por mês. No entanto, Arroyo está atualmente em Alpha e pode ter recursos ausentes.
Amazon Kinesis

Amazon Kinesis Data Streams permite coletar e processar grandes fluxos de dados para ingestão rápida e contínua. Tem enorme escalabilidade, durabilidade e baixo custo. Vejamos os principais recursos que você obtém:
- O Amazon Kinesis é executado na nuvem AWS em um modo sem servidor sob demanda. Com alguns cliques no Console de gerenciamento da AWS, você pode ter seus streams do Kinesis Data em execução.
- Você pode ter o Kinesis em execução em até 3 zonas de disponibilidade (AZs). Ele também oferece 365 dias de retenção de dados.
- Os streams do Kinesis Data permitem que você conecte até 20 consumidores. Além disso, cada consumidor tem sua própria taxa de transferência de leitura dedicada e pode publicar em até 70 milissegundos após a ingestão.
- Atenda aos seus requisitos de segurança criptografando seus dados usando criptografia do lado do servidor.
- Fazer parte da AWS permite que o Kinesis se integre perfeitamente a outros serviços da AWS, como Cloudwatch, DynamoDB e AWS Lambda.
Com o Amazon Kinesis, você paga pelo que usa. Considerando 1.000 registros/segundo de 3 KB cada, seu custo diário para um modo sob demanda para iniciantes será de aproximadamente US$ 30,61. Você pode usar o calculadora AWS para descobrir seu custo baseado no uso.
Databricks

Se você estiver procurando por uma única plataforma de dados para processamento em lote e fluxo, o Plataforma Databricks Lakehouse é uma ótima escolha. Além disso, você obtém análises em tempo real, aprendizado de máquina e aplicativos em uma plataforma.
A Databricks Lakehouse Platform possui sua própria exibição de dados chamada Delta Live Tables (DLT) com os seguintes benefícios:
- O DLT permite que você defina facilmente seu pipeline de dados de ponta a ponta.
- Você obtém testes automáticos de qualidade de dados. Simultaneamente, você pode monitorar tendências de qualidade de dados ao longo do tempo.
- Se sua carga de trabalho for imprevisível, o escalonamento automático aprimorado da DLT lidará com isso.
Você obtém o melhor lugar para executar suas cargas de trabalho do Apache Spark, com o Spark Structured Streaming como tecnologia principal. Juntamente com isso está o Delta Lake, a única plataforma de armazenamento de código aberto que suporta streaming e dados em lote.
Com a Plataforma Databricks Lakehouse, você pode desfrutar de um teste gratuito de 14 dias, após o qual você será automaticamente inscrito no plano em que esteve.
Qlik Data Streaming (CDC)

CDC ou Change Data Capture é a técnica pela qual qualquer alteração nos dados é notificada a outros sistemas. Uma solução simples e universal, Qlik Data Streaming (CDC) permite que você mova facilmente seus dados da origem ao destino em tempo real. Você consegue gerenciar tudo através de uma interface gráfica simples.
O Qlik Data Streaming (CDC) fornece uma configuração simplificada e automática. Assim, você pode facilmente configurar, controlar e monitorar seu pipeline de dados em tempo real.
Você obtém o suporte de uma ampla variedade de fontes, destinos e plataformas. Isso permite não apenas ingerir uma ampla variedade de dados, mas também sincronizar dados locais, na nuvem e híbridos.
O Qlik Enterprise Manager é seu centro de comando central que permite dimensionar facilmente e monitorar o fluxo de dados por meio de alertas.
Há uma opção de implantação flexível quando se trata de escolher como você deseja executar seu pipeline de CDC. Com base em sua necessidade, você pode escolher entre os seguintes:
Você pode começar com um teste grátis sem baixar ou instalar nada.
Flúvio

Procurando uma solução de streaming nativa em nuvem de código aberto com baixa latência e alto desempenho? Flúvio se encaixa nessa descrição. Você ganha a capacidade de realizar cálculos em linha usando SmartModules que aprimoram a funcionalidade da plataforma Fluvio.
O Fluvio distribuiu processamento de fluxo com verificações para evitar perda de dados e tempo de inatividade. Além disso, há suporte de API nativo para linguagens de programação populares como Rust, Node.js, Python, Java e Go. Vamos dar uma olhada no que a plataforma tem reservado para você:
- O poder de combinar computação com streaming em um cluster unificado oferece atrasos minimizados.
- O Fluvio carrega dinamicamente módulos personalizados que ampliam os recursos computacionais.
- Você obtém alta escalabilidade que varia de pequenos dispositivos IoT a sistemas multinúcleo.
- Possui recursos de recuperação automática usando gerenciamento declarativo, reconciliação e replicação.
- Como foi desenvolvido pensando na comunidade de desenvolvedores, você obtém uma CLI poderosa para eficiência.
Seja seu laptop, data center corporativo ou nuvem pública de sua escolha, você pode instalar o Fluvio em qualquer plataforma.
Por ser de código aberto, a execução do Fluvio não é cobrada.
Cloudera Stream Processing (CSP)

Desenvolvido por Apache Flink e Apache Kafka, Cloudera Stream Processing (CSP) fornece recursos de análise para obter informações sobre seus dados de streaming. Possui suporte nativo para tecnologias padrão como SQL e REST. Além disso, você obtém uma solução completa de gerenciamento de fluxo combinada com processamento dinâmico criado para empresas.
Cloudera Stream Processing lê e analisa grandes volumes de dados em tempo real para produzir resultados em latências de subsegundos. Obtenha suporte para multinuvem e nuvem híbrida, juntamente com as ferramentas necessárias para criar análises orientadas por dados altamente sofisticadas. Aproveite as seguintes ferramentas e recursos:
- Suportando milhões de mensagens por segundo, você pode acompanhar suas necessidades em constante mudança com streaming altamente escalável.
- O Streams Messaging Manager oferece uma visão de ponta a ponta de como seus dados se movem em seu pipeline de processamento de dados.
- O Streams Replication Manager oferece replicação, disponibilidade e recuperação de desastres.
- Reduza incompatibilidades e interrupções de esquema com o Schema Registry, que permite gerenciar tudo em um repositório compartilhado.
- Uma segurança centralizada aplicada automaticamente, o Cloudera SDX oferece controle e governança unificados em todos os seus componentes.
Com Cloudera Stream Processing em menos de 10 minutos, você pode ativar seu pipeline de processamento de stream na plataforma de nuvem de sua escolha – seja AWS, Azure ou Google Cloud Platform.
Striim Cloud
Sua plataforma de dados e análise em tempo real precisam de uma ampla variedade de produtores e consumidores de dados? Striim Cloud, com suporte embutido para mais de 100 conectores, pode ser a escolha perfeita. Integre-se facilmente com seus armazenamentos de dados existentes e transmita dados em tempo real com a ajuda de uma plataforma SaaS totalmente gerenciada projetada para a nuvem.
O Striim Cloud oferece uma interface simples de arrastar e soltar, que não apenas ajuda a construir seu pipeline, mas também fornece informações sobre seus dados. Ele oferece suporte às ferramentas de análise mais populares, incluindo Google BigQuery, Snowflake, Azure Synapse e Databricks. Além disso, você obtém o seguinte:
- Suas preocupações sobre mudanças na estrutura de dados são tratadas pelos recursos de evolução do esquema do Striim. Você pode configurá-lo para resolução automática ou intervenção manual.
- Construído na plataforma SQL de streaming distribuído, o Striim permite executar consultas contínuas.
- O Striim oferece alta escalabilidade e rendimento. Posteriormente, você pode dimensionar seu pipeline sem nenhum planejamento ou custo adicional.
- O método ‘ReadOnlyWriteMany’ permite adicionar e remover novos alvos sem qualquer impacto em seus armazenamentos de dados.
Pague apenas pelo que usar. O ambiente do desenvolvedor Striim é gratuito e permite que você experimente a plataforma com 10 milhões de eventos/mês. Para uma solução de nuvem em escala empresarial, ela começa em US$ 2.500/mês.
Plataforma de dados de streaming VK
Com o mais alto padrão de produtos de dados e insights, o Vertical Knowledge (VK) ajuda indivíduos e empresas a tomar decisões poderosas em escala. Plataforma de dados de streaming VK permite que você processe grandes quantidades de dados por meio de um ambiente de streaming de dados baseado na web.
Obtenha insights acionáveis com a descoberta automatizada de dados. Aqui estão os principais benefícios da plataforma de dados de streaming da VK:
- Você obtém segurança cibernética robusta devido à infraestrutura estável do VK que protege você contra conteúdo malicioso. Além disso, você pode baixar dados por meio de um ambiente virtual.
- Os fluxos de dados automatizados permitem que você opere em várias fontes de dados com facilidade.
- Com a descoberta rápida, você pode reduzir os processos manuais, que geralmente são demorados.
- Gere coleções de dados profundas executando pipelines simultâneos de várias fontes. Assim, você pode gerar resultados globais para palavras-chave selecionadas.
- Você pode exportar suas coleções de dados em formato bruto JSON ou CSV ou usar APIs para integração com sistemas de terceiros.
Plataforma HStream
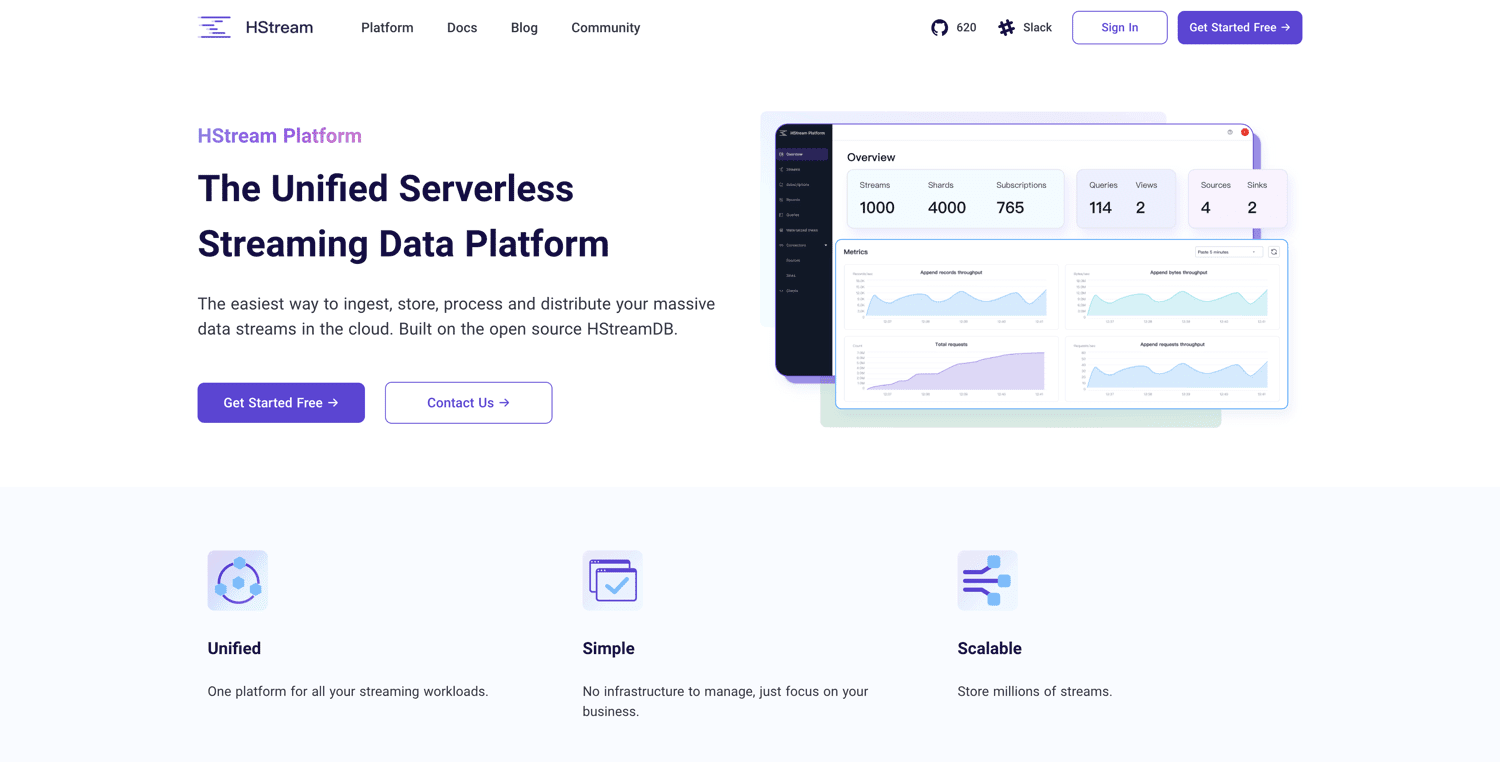
Construído no HStreamDB de código aberto, o Plataforma HStream oferece uma plataforma de dados de streaming sem servidor. Você pode ingerir grandes quantidades de dados e armazenar milhões de fluxos de dados de maneira confiável. O HStreamDB é tão rápido quanto o Kafka. Além disso, você pode reproduzir dados históricos
Você pode usar o SQL para filtrar, transformar, agregar e até mesmo unir várias exibições de dados. Assim, você obtém informações em tempo real sobre seus dados. A plataforma HStream permite que você comece pequeno e é enxuto. Aqui estão os principais recursos:
- Por ser sem servidor, está pronto para uso desde o início.
- Não há necessidade de Kafka para suas necessidades de streaming.
- Você obtém processamento de fluxo no local usando SQL padrão.
- Consuma e produza para diferentes sistemas, sejam bancos de dados, data warehouses ou data lakes. Portanto, não há necessidade de ferramentas ETL adicionais.
- Você pode gerenciar com eficiência toda a sua carga de trabalho em uma plataforma de streaming unificada.
- A arquitetura nativa da nuvem permite dimensionar suas necessidades de computação e armazenamento de forma independente.
A plataforma HStream está atualmente em versão beta pública. O uso é gratuito — tudo o que você precisa fazer é inscrever-se para isso.
Conclusão
A escolha de uma boa plataforma de streaming de dados depende de sua escala, necessidade de diferentes conectores, tempo de atividade e confiabilidade.
Enquanto algumas plataformas são serviços totalmente gerenciados, outras são de código aberto e fornecem várias personalizações. Analise suas necessidades e orçamento e escolha o que melhor se adapta a você.
Em seguida, você ainda está se perguntando como pode fazer o melhor uso de todos esses dados? Experimente as ferramentas de previsão e previsão de dados com IA para empresas.