Nos últimos anos, a aplicação de Python na ciência de dados experimentou um crescimento notável, e essa tendência continua a se fortalecer dia após dia.
A ciência de dados é um campo vasto, abrangendo diversas áreas especializadas. A análise de dados, sem dúvida, se destaca como uma das mais cruciais. Independentemente do nível de proficiência em ciência de dados, compreender ou pelo menos ter um conhecimento básico dessa área tornou-se cada vez mais essencial.
O Que É Análise de Dados?
A análise de dados envolve o processo de limpar e transformar grandes conjuntos de dados não estruturados ou desorganizados, com o objetivo principal de extrair *insights* e informações valiosas que possam subsidiar decisões bem fundamentadas.
Existem diversas ferramentas para realizar análises de dados, como Python, Microsoft Excel, Tableau e SAS. No entanto, neste artigo, nosso foco será a realização de análise de dados utilizando Python, mais especificamente, como isso é feito com o auxílio da biblioteca pandas.
O Que É Pandas?
Pandas é uma biblioteca Python de código aberto, amplamente utilizada para manipulação e tratamento de dados. Caracteriza-se pela sua velocidade e alta eficiência, além de oferecer recursos para carregar diversos tipos de dados na memória. Com pandas, é possível remodelar, rotular, fatiar, indexar e até mesmo agrupar dados de diferentes formas.
Estruturas de Dados em Pandas
Pandas oferece três estruturas de dados principais:
A melhor forma de entender a relação entre essas estruturas é visualizar uma como uma pilha de outras. Assim, um DataFrame pode ser visto como uma pilha de Series, enquanto um Panel seria uma pilha de DataFrames.
Uma Series é um *array* unidimensional.
Uma pilha de várias Series forma um DataFrame bidimensional.
E uma pilha de diversos DataFrames compõe um Panel tridimensional.
Neste contexto, a estrutura de dados mais comum com a qual iremos trabalhar é o DataFrame bidimensional, que também pode ser considerado o formato padrão de representação para muitos conjuntos de dados que encontramos.
Análise de Dados com Pandas
Para este tutorial, nenhuma instalação é necessária. Utilizaremos o ambiente Colaboratory, uma ferramenta criada pelo Google. Trata-se de um ambiente Python online projetado para análise de dados, aprendizado de máquina e IA. Essencialmente, é um Jupyter Notebook baseado na nuvem que já vem com praticamente todos os pacotes Python necessários para um cientista de dados.
Acesse https://colab.research.google.com/notebooks/intro.ipynb. Você deverá ver algo semelhante a isso:
No canto superior esquerdo, clique na opção “Arquivo” e depois em “Novo notebook”. Uma nova página do Jupyter Notebook será carregada no seu navegador. O primeiro passo é importar a biblioteca pandas para o nosso ambiente de trabalho. Isso pode ser feito executando o seguinte código:
import pandas as pd
Neste artigo, utilizaremos um conjunto de dados contendo informações sobre preços de imóveis para realizar nossa análise. O conjunto de dados está disponível aqui. Inicialmente, precisamos carregar esse conjunto de dados em nosso ambiente.
Podemos realizar essa tarefa com o seguinte código em uma nova célula:
df = pd.read_csv('https://firebasestorage.googleapis.com/v0/b/ai6-portfolio-abeokuta.appspot.com/o/kc_house_data.csv?alt=media &token=6a5ab32c-3cac-42b3-b534-4dbd0e4bdbc0 ', sep=',')
A função `.read_csv` é utilizada para ler arquivos CSV, e passamos a propriedade `sep` para indicar que o arquivo é delimitado por vírgulas.
É importante notar que o nosso arquivo CSV carregado é armazenado na variável `df`.
Não é necessário usar a função `print()` no Jupyter Notebook. Basta digitar o nome da variável em uma célula, e o Jupyter Notebook a exibirá para você.
Podemos testar isso digitando `df` em uma nova célula e executando-a. Isso imprimirá todos os dados do nosso conjunto como um DataFrame.
Entretanto, nem sempre queremos visualizar todos os dados. Em algumas situações, queremos apenas as primeiras linhas e os nomes das colunas. Para isso, podemos usar a função `df.head()` para exibir as cinco primeiras linhas e `df.tail()` para exibir as cinco últimas. A saída de ambos seria algo parecido com:
Para entendermos melhor as relações entre as diversas linhas e colunas de dados, podemos usar a função `.describe()`, que oferece uma visão geral das estatísticas dos dados.
A execução de `df.describe()` produzirá a seguinte saída:
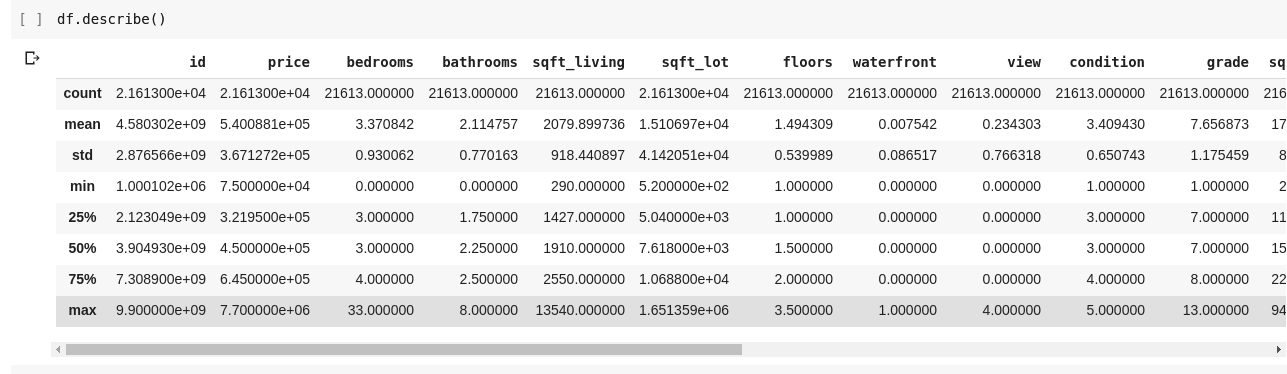
Podemos notar que `.describe()` nos fornece a média, o desvio padrão, os valores mínimos e máximos, e os percentis de cada coluna do DataFrame. Essas informações são muito úteis.
Também podemos verificar a forma do nosso DataFrame 2D para descobrir o número de linhas e colunas que ele possui. Isso pode ser feito usando `df.shape`, que retorna uma tupla no formato `(linhas, colunas)`.
Adicionalmente, podemos verificar os nomes de todas as colunas do nosso DataFrame usando `df.columns`.
E se quisermos selecionar apenas uma coluna e obter todos os seus dados? Isso é feito de forma semelhante a fatiar um dicionário. Digite o seguinte código em uma nova célula e execute-o:
df['price ']
O código acima retorna a coluna de preços. Podemos ir além e salvá-la em uma nova variável:
price = df['price']
Agora podemos executar diversas operações que são possíveis em um DataFrame na nossa variável `price`, já que ela é um subconjunto do DataFrame original. Podemos usar métodos como `df.head()`, `df.shape`, etc.
Também é possível selecionar múltiplas colunas, passando uma lista com os nomes das colunas para `df`:
data = df[['price ', 'bedrooms']]
O código acima seleciona as colunas com os nomes ‘preço’ e ‘quartos’. Se digitarmos `data.head()` em uma nova célula, teremos o seguinte resultado:
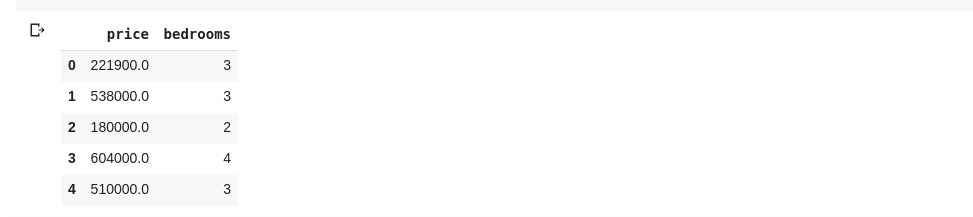
A forma de fatiar colunas mostrada acima retorna todos os elementos das linhas daquela coluna. Mas e se quisermos obter um subconjunto de linhas e colunas do nosso conjunto de dados? Isso pode ser feito utilizando `.iloc`, que funciona de forma semelhante à indexação de listas em Python. Assim, podemos fazer algo como:
df.iloc[50: , 3]
O código acima retorna a terceira coluna da linha 50 até o final. É bem similar à forma como fatiamos listas em Python.
Agora, vamos fazer algumas coisas realmente interessantes. Nosso conjunto de dados sobre preços de imóveis possui uma coluna com o preço e outra com o número de quartos. O preço é um valor contínuo, então é possível que não haja duas casas com o mesmo valor. O número de quartos, por outro lado, é um dado discreto, e podemos ter várias casas com dois, três, quatro quartos, etc.
E se quisermos obter todas as casas com o mesmo número de quartos e calcular o preço médio por número de quartos? Isso é relativamente fácil de fazer com pandas. Podemos usar o seguinte código:
df.groupby('bedrooms ')['price '].mean()
O primeiro passo agrupa o DataFrame pelos conjuntos de dados com o mesmo número de quartos, utilizando a função `df.groupby()`. Em seguida, selecionamos apenas a coluna de preços e utilizamos a função `.mean()` para calcular a média do preço de cada casa no conjunto de dados.
E se quisermos visualizar o resultado obtido? Queremos observar como varia o preço médio em função do número de quartos. Para isso, podemos adicionar a função `.plot()` ao código anterior:
df.groupby('bedrooms ')['price '].mean().plot()
Obteremos uma saída parecida com esta:
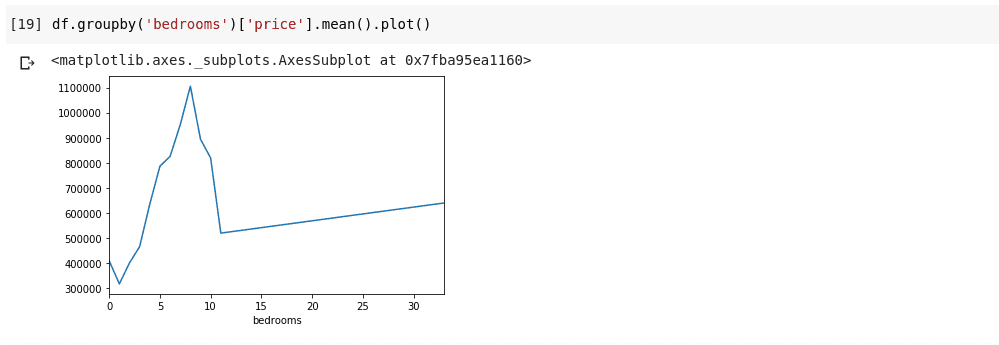
Essa visualização nos mostra algumas tendências nos dados. No eixo horizontal, temos o número distinto de quartos (note que várias casas podem ter o mesmo número de quartos). No eixo vertical, temos a média de preços correspondente ao número de quartos no eixo horizontal. Podemos observar que as casas com 5 a 10 quartos custam muito mais do que as com 3 quartos. Também fica evidente que casas com cerca de 7 ou 8 quartos custam muito mais do que aquelas com 15, 20 ou até 30 quartos.
Informações como essa são o que torna a análise de dados tão importante. Somos capazes de extrair informações úteis dos dados que não seriam perceptíveis sem uma análise.
Dados Ausentes
Vamos supor que estou conduzindo uma pesquisa com várias perguntas. Compartilho um *link* com milhares de pessoas para que possam fornecer suas respostas. Meu objetivo é realizar uma análise de dados sobre essas respostas para extrair *insights* importantes.
Diversas coisas podem dar errado. Alguns participantes podem não se sentir confortáveis em responder a algumas perguntas e deixá-las em branco. Muitas pessoas podem fazer o mesmo em várias partes da pesquisa. Isso pode não parecer um problema, mas imagine que eu esteja coletando dados numéricos e parte da análise envolva somar, calcular a média ou alguma outra operação aritmética. Vários valores ausentes causariam diversas imprecisões na minha análise. Preciso encontrar uma forma de detectar e substituir esses valores ausentes por valores adequados.
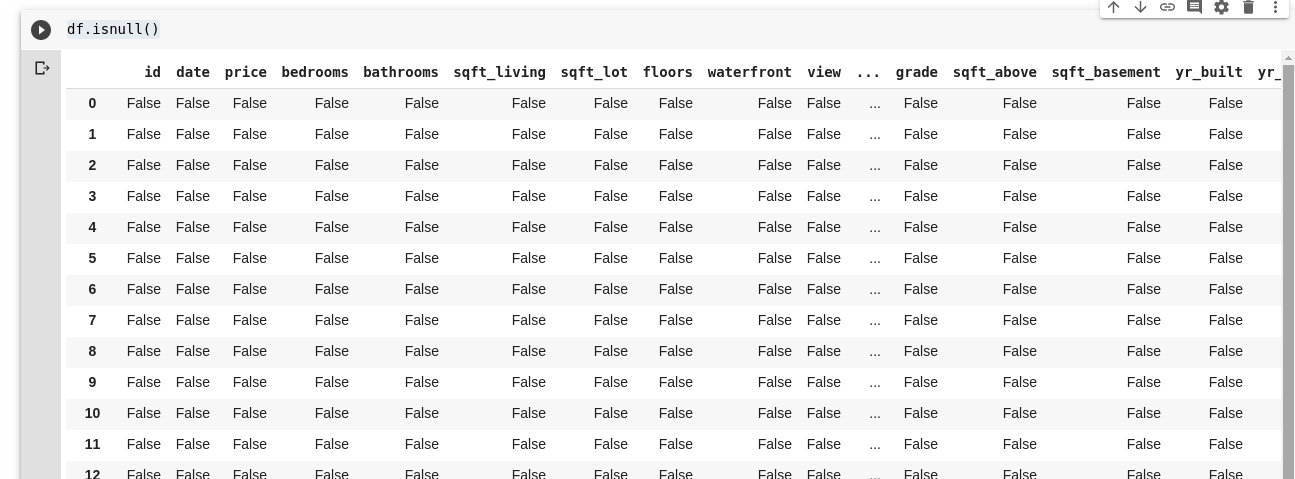
Pandas nos oferece uma função para identificar valores ausentes em um DataFrame, chamada `isnull()`.
A função `isnull()` pode ser usada da seguinte forma:
df.isnull()
Isso retorna um DataFrame de valores booleanos que indicam se os dados originalmente presentes estão ausentes (True) ou não (False). A saída seria algo como:
Precisamos de uma forma de substituir todos esses valores ausentes. Na maioria dos casos, podemos escolher o valor zero para isso. Em outras situações, podemos usar a média de todos os outros dados, ou a média dos dados ao redor. A escolha depende do cientista de dados e do caso de uso específico.
Para preencher todos os valores ausentes em um DataFrame, usamos a função `.fillna()`, da seguinte forma:
df.fillna(0)
O código acima preenche todos os valores vazios com o valor zero. Poderia ser qualquer outro número que especificarmos.
A importância dos dados não pode ser negligenciada. Eles nos ajudam a obter respostas diretamente de nossas próprias informações. A análise de dados, como se diz, é o novo petróleo para as economias digitais.
Todos os exemplos apresentados neste artigo podem ser encontrados aqui.
Se você deseja se aprofundar no assunto, confira este curso online de Análise de Dados com Python e Pandas.