As redes neurais convolucionais (CNNs) representam uma abordagem mais eficaz para realizar tarefas de reconhecimento de objetos e categorização de imagens.
O campo da tecnologia está em constante evolução, com avanços significativos. Inteligência artificial (IA) e aprendizado de máquina (ML) são termos frequentemente mencionados.
Essas tecnologias se tornaram onipresentes, encontrando aplicações em diversas áreas, como marketing, comércio eletrônico, desenvolvimento de software, bancos, finanças e medicina.
IA e ML abrangem áreas extensas, com esforços contínuos para expandir suas aplicações na resolução de problemas complexos do mundo real. Como resultado, surgem diversas ramificações nessas tecnologias; ML, por exemplo, é um subconjunto da própria IA.
As redes neurais convolucionais são um ramo da IA que ganhou destaque nos últimos tempos.
Neste artigo, exploraremos o conceito de CNNs, seu funcionamento e sua utilidade no cenário contemporâneo.
Vamos começar!
O que é uma Rede Neural Convolucional?
Uma rede neural convolucional (CNN ou ConvNet) é um tipo de rede neural artificial (RNA) que emprega algoritmos de aprendizado profundo para analisar imagens, classificar representações visuais e executar tarefas de visão computacional.
A CNN utiliza princípios da álgebra linear, como a multiplicação de matrizes, para identificar padrões em imagens. Esses cálculos complexos requerem o uso de unidades de processamento gráfico (GPUs) para treinar os modelos de forma eficaz.
Simplificando, a CNN utiliza algoritmos de aprendizado profundo para processar dados de entrada na forma de imagens e atribuir importância, por meio de pesos e vieses ajustáveis, a diferentes aspectos dessas imagens. Isso permite que a CNN diferencie e classifique imagens.
CNNs: Uma Breve História
Como uma rede neural convolucional é um tipo de rede neural artificial, é importante relembrar o conceito de redes neurais.
Em ciência da computação, uma rede neural é uma parte do aprendizado de máquina (ML) que utiliza algoritmos de aprendizado profundo. Ela se inspira na estrutura de conectividade dos neurônios no cérebro humano. As redes neurais artificiais também se baseiam na organização do córtex visual.
Portanto, diferentes tipos de redes neurais artificiais (RNAs) são usados para diferentes finalidades. Uma delas é a CNN, usada para detecção e classificação de imagens, entre outras aplicações. Sua introdução se deve ao pesquisador de pós-doutorado Yann LeCun, na década de 1980.
A versão inicial da CNN, chamada LeNet em homenagem a LeCun, era capaz de reconhecer dígitos manuscritos. Posteriormente, foi usada em serviços bancários e postais para leitura de dígitos em cheques e códigos postais em envelopes.
No entanto, essa versão inicial era limitada em termos de escalabilidade. Como resultado, as CNNs não tiveram uso generalizado em inteligência artificial e visão computacional naquela época. Além disso, exigiam recursos computacionais e conjuntos de dados substanciais para processar imagens maiores com eficiência.
Em 2012, a AlexNet reintroduziu o aprendizado profundo utilizando redes neurais com múltiplas camadas. Naquela época, a tecnologia havia melhorado, e grandes conjuntos de dados e recursos computacionais robustos estavam disponíveis, possibilitando a criação de CNNs complexas, capazes de realizar tarefas de visão computacional de maneira eficaz.
Camadas em uma CNN
Vamos explorar as diferentes camadas que compõem uma CNN. O aumento do número de camadas em uma CNN aumenta sua complexidade e permite a detecção de mais aspectos ou áreas de uma imagem. Iniciando com recursos simples, a CNN se torna capaz de identificar elementos complexos, como a forma do objeto e elementos maiores, até que possa finalmente reconhecer a imagem em sua totalidade.
Camada Convolucional
A primeira camada de uma CNN é a camada convolucional. Ela serve como o principal componente da CNN, onde ocorrem a maioria dos cálculos. Requer componentes essenciais como dados de entrada, um mapa de recursos e um filtro.
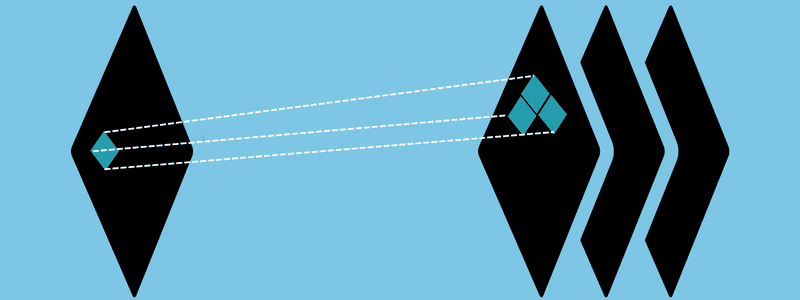
Uma CNN pode incluir camadas convolucionais adicionais. Isso confere uma estrutura hierárquica às CNNs, pois as camadas subsequentes podem visualizar pixels dentro dos campos receptivos das camadas anteriores. As camadas convolucionais transformam a imagem original em valores numéricos, permitindo que a rede entenda e extraia padrões relevantes.
Camadas de Pooling
As camadas de pooling são usadas para reduzir a dimensionalidade e são chamadas de downsampling. Elas reduzem o número de parâmetros usados na entrada. A operação de pooling move um filtro sobre a entrada completa, como na camada convolucional, mas não utiliza pesos. O filtro aplica uma função agregada aos valores numéricos no campo receptivo para preencher a matriz de resultados.
Existem dois tipos principais de pooling:
- Agrupamento médio: O valor médio é calculado no campo receptivo enquanto o filtro percorre a entrada, e esse valor é transmitido para a matriz de saída.
- Agrupamento máximo: O pixel de maior valor é selecionado no campo receptivo e enviado para a matriz de saída enquanto o filtro se move sobre a entrada. O agrupamento máximo é mais utilizado que o agrupamento médio.
Embora informações significativas possam ser perdidas durante o pooling, ele ainda oferece vários benefícios para a CNN. Ele ajuda a diminuir os riscos e a complexidade de overfitting, ao mesmo tempo em que melhora a eficiência e a estabilidade da rede.
Camada Totalmente Conectada (FC)
Como o nome sugere, em uma camada totalmente conectada, cada nó da camada de saída está conectado diretamente a todos os nós da camada anterior. Essa camada classifica uma imagem com base nos recursos extraídos pelas camadas anteriores e seus filtros.
Além disso, as camadas FC geralmente empregam uma função de ativação softmax para classificar corretamente as entradas, em vez das funções ReLU usadas nas camadas de pooling e convolucionais. Isso ajuda a gerar uma probabilidade entre 0 e 1.
Como as CNNs Funcionam?
Uma rede neural convolucional é composta por várias camadas, às vezes centenas delas. Essas camadas aprendem a identificar diferentes recursos de uma imagem específica.
Embora as CNNs sejam redes neurais, sua arquitetura difere de uma RNA convencional.

Uma RNA tradicional processa a entrada por meio de várias camadas ocultas, onde cada camada é formada por um conjunto de neurônios artificiais e está totalmente conectada a todos os neurônios da camada seguinte. Finalmente, há uma camada totalmente conectada ou de saída para apresentar o resultado.
Por outro lado, a CNN organiza as camadas em três dimensões: largura, profundidade e altura. Aqui, um neurônio se conecta apenas a neurônios em uma pequena região, em vez de se conectar a todos os neurônios na próxima camada. O resultado final é representado por um único vetor com uma pontuação de probabilidade, tendo apenas a dimensão da profundidade.
Agora, você deve estar se perguntando o que é “convolução” em uma CNN.
Convolução é uma operação matemática que combina dois conjuntos de dados. Em CNNs, a convolução é aplicada aos dados de entrada para gerar um mapa de recursos, filtrando as informações.
Isso nos leva a alguns conceitos e terminologias importantes usadas em CNNs.
- Filtro: Também conhecido como detector de recursos ou kernel, um filtro tem uma dimensão específica, como 3×3. Ele passa pela imagem de entrada, realizando multiplicação de matrizes para cada elemento e aplicando a convolução. A aplicação de filtros a cada imagem de treinamento em diversas resoluções, juntamente com a saída da imagem convoluída, atuará como entrada para a próxima camada.
- Preenchimento: É usado para expandir uma matriz de entrada até as bordas da matriz, inserindo pixels adicionais. Isso é feito para compensar o fato de que a convolução reduz o tamanho da matriz. Por exemplo, uma matriz 9×9 pode se transformar em uma matriz 3×3 após a filtragem.
- Stride: Se o objetivo for obter uma saída menor que a entrada, você pode usar o stride, que permite pular certas áreas enquanto o filtro percorre a imagem. Ao ignorar dois ou três pixels, você pode produzir uma rede mais eficiente, reduzindo a resolução espacial.
- Pesos e vieses: As CNNs têm pesos e vieses em seus neurônios. O modelo aprende esses valores durante o treinamento, e eles permanecem os mesmos em uma determinada camada para todos os neurônios. Isso significa que cada neurônio oculto detecta os mesmos recursos em diferentes áreas de uma imagem. Como resultado, a rede se torna mais tolerante à tradução de objetos em uma imagem.
- ReLU: Significa Unidade Linear Retificada e é usada para tornar o treinamento mais eficaz e rápido. Ela mapeia valores negativos para 0 e mantém valores positivos. Também é chamada de ativação, pois a rede transfere apenas os recursos de imagem ativados para a próxima camada.
- Campo receptivo: Em uma rede neural, cada neurônio recebe entrada de diferentes locais da camada anterior. Nas camadas convolucionais, cada neurônio recebe entrada de uma área restrita da camada anterior, chamada de campo receptivo do neurônio. No caso da camada FC, toda a camada anterior é o campo receptivo.
Em tarefas computacionais do mundo real, a convolução é frequentemente realizada em uma imagem 3D, o que exige um filtro 3D.
Retornando à CNN, ela compreende diferentes partes ou camadas de nós. Cada camada de nó tem um limite e um peso, e está conectada a outra camada. Ao exceder o limite, os dados são enviados para a próxima camada dessa rede.
Essas camadas podem realizar operações para modificar os dados e aprender recursos relevantes. Além disso, essas operações se repetem em centenas de camadas diferentes, que continuam aprendendo a detectar outros recursos de uma imagem.
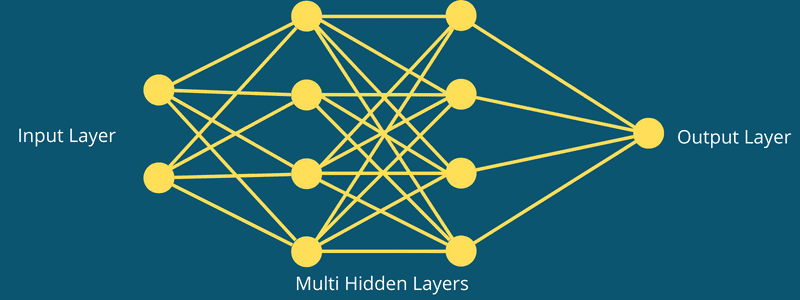
As partes de uma CNN são:
- Uma camada de entrada: Onde a entrada é obtida, como uma imagem. Será um objeto 3D com altura, largura e profundidade definidas.
- Uma ou várias camadas ocultas, ou fase de extração de recursos: Essas camadas podem ser uma camada convolucional, uma camada de pooling e uma camada totalmente conectada.
- Uma camada de saída: Onde o resultado é apresentado.
A passagem da imagem pela camada convolucional a transforma em um mapa de recursos ou mapa de ativação. Após a convolução da entrada, as camadas convoluem a imagem e passam o resultado para a camada seguinte.
A CNN realizará várias convoluções e técnicas de pooling para detectar os recursos durante a fase de extração de recursos. Por exemplo, se você inserir uma imagem de um gato, a CNN reconhecerá suas quatro patas, cor, dois olhos, etc.
Em seguida, as camadas totalmente conectadas em uma CNN agirão como um classificador sobre os recursos extraídos. Com base na previsão do algoritmo de aprendizado profundo sobre a imagem, as camadas gerarão o resultado.
Vantagens das CNNs

Maior Precisão
As CNNs oferecem maior precisão em comparação com redes neurais regulares que não usam convolução. As CNNs são úteis, especialmente em tarefas que envolvem grandes conjuntos de dados, reconhecimento de vídeo e imagem, etc. Elas produzem resultados e previsões altamente precisos. Portanto, seu uso está aumentando em diversos setores.
Eficiência Computacional

As CNNs oferecem um nível superior de eficiência computacional em comparação com outras redes neurais comuns. Isso se deve ao uso do processo de convolução. Elas também utilizam redução de dimensionalidade e compartilhamento de parâmetros para tornar os modelos mais rápidos e fáceis de implantar. Essas técnicas também podem ser otimizadas para funcionar em diferentes dispositivos, sejam smartphones ou laptops.
Extração de Recursos
A CNN consegue aprender facilmente os recursos de uma imagem sem a necessidade de engenharia manual. É possível usar CNNs pré-treinadas e ajustar os pesos ao alimentá-las com dados ao trabalhar em uma nova tarefa. A CNN se adaptará perfeitamente a essa nova tarefa.
Aplicações da CNN
As CNNs são utilizadas em diferentes indústrias para diversas aplicações. Algumas aplicações práticas das CNNs incluem:
Classificação de Imagem
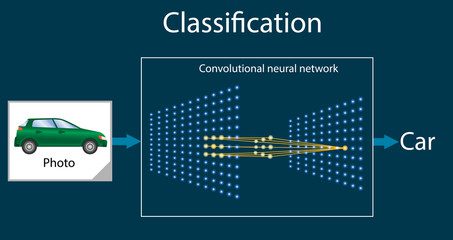
As CNNs são amplamente empregadas na classificação de imagens. Elas podem identificar recursos importantes e reconhecer objetos em uma imagem. Por essa razão, são utilizadas em setores como a saúde, especialmente em ressonâncias magnéticas. Além disso, essa tecnologia é usada no reconhecimento de dígitos manuscritos, uma das primeiras aplicações das CNNs em visão computacional.
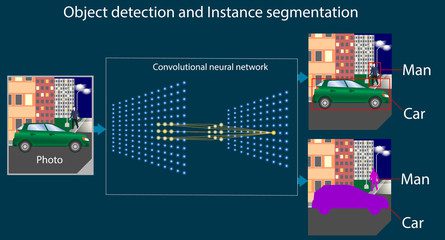
Detecção de Objetos
A CNN pode detectar objetos em imagens em tempo real, além de rotulá-los e classificá-los. Por isso, essa técnica é amplamente utilizada em veículos automatizados. Também permite que casas inteligentes e pedestres reconheçam o rosto do proprietário do veículo. Além disso, ela é usada em sistemas de vigilância com inteligência artificial para identificar e marcar objetos.
Correspondência Audiovisual
O uso de CNNs na correspondência audiovisual ajuda a aprimorar plataformas de streaming de vídeo, como Netflix e YouTube. Também auxilia a atender a solicitações de usuários, como “músicas de amor de Elton John”.
Reconhecimento de Fala

Além de imagens, as CNNs são úteis no processamento de linguagem natural (PLN) e no reconhecimento de fala. Um exemplo prático é o Google utilizando CNNs em seu sistema de reconhecimento de fala.
Reconstrução de Objetos
As CNNs podem ser utilizadas na modelagem 3D de objetos reais em ambientes digitais. Também é possível que modelos CNN criem modelos faciais 3D a partir de uma imagem. Além disso, a CNN é útil na criação de gêmeos digitais em biotecnologia, manufatura, biotecnologia e arquitetura.
O uso de CNNs em diferentes setores inclui:
- Saúde: A visão computacional pode ser usada em radiologia para auxiliar os médicos na detecção mais eficaz de tumores cancerígenos.
- Agricultura: As redes podem utilizar imagens de satélites artificiais, como LSAT, para classificar terras férteis. Isso também auxilia na previsão dos níveis de fertilidade do solo e no desenvolvimento de estratégias eficazes para maximizar o rendimento.
- Marketing: Aplicativos de mídia social podem sugerir uma pessoa em uma foto postada no perfil de alguém. Isso facilita a marcação de pessoas em álbuns de fotos.
- Varejo: Plataformas de comércio eletrônico podem usar a pesquisa visual para ajudar as marcas a recomendar itens relevantes que os clientes-alvo desejam comprar.
- Automotivo: As CNNs são empregadas em automóveis para aprimorar a segurança de passageiros e motoristas, por meio de recursos como detecção de faixa de rodagem, detecção de objetos, classificação de imagens, etc. Isso também contribui para a evolução do mundo dos carros autônomos.
Recursos para Aprender sobre CNNs
Curso:
O Coursera oferece um curso sobre CNNs que você pode considerar. Este curso aborda a evolução da visão computacional e algumas aplicações de CNNs no mundo moderno.
Recursos da Amazon:
Você pode consultar estes livros e palestras para aprender mais sobre CNNs:
- Redes Neurais e Aprendizado Profundo: Aborda modelos, algoritmos e a teoria do aprendizado profundo e redes neurais.
- Um Guia para Redes Neurais Convolucionais para Visão Computacional: Este livro aborda aplicações de CNNs e seus conceitos.
- Redes Neurais Convolucionais Práticas com TensorFlow: Você pode usar este livro para resolver problemas de visão computacional usando Python e TensorFlow.
- Aprendizado Profundo Aplicado Avançado: Este livro ajuda a entender CNNs, aprendizado profundo e suas aplicações avançadas, incluindo detecção de objetos.
- Redes Neurais Convolucionais e Redes Neurais Recorrentes: Este livro ensina sobre CNNs e RNNs, bem como a construção dessas redes.
Conclusão
As redes neurais convolucionais são um dos campos emergentes da inteligência artificial, aprendizado de máquina e aprendizado profundo. Elas encontram diversas aplicações no mundo atual, em quase todos os setores. Dado o seu uso crescente, espera-se que sua expansão continue e que se tornem cada vez mais úteis na resolução de problemas do mundo real.