

As empresas dependem de dados para prosperar neste mundo digital em rápido avanço. As empresas coletam diferentes tipos de dados regularmente, incluindo interações com clientes, vendas, receita, dados de concorrentes, dados de sites, etc.
Gerenciar esses dados pode ser uma tarefa assustadora. E se não for bem feito, pode causar um grande erro.
É aqui que entra a orquestração de dados.
A orquestração de dados ajuda você a gerenciar e organizar todos os seus dados cruciais de forma eficaz.
Ele ajuda as empresas a aproveitar o poder dos dados e obter uma vantagem competitiva no mercado.
Neste artigo, falarei sobre orquestração de dados e como ela pode ajudar sua organização.
Vamos começar!
últimas postagens
O que é orquestração de dados?
O processo de coleta, transformação, integração e gerenciamento eficiente de dados de várias fontes é conhecido como orquestração de dados.
O principal objetivo da orquestração de dados é simplificar os dados de diferentes fontes de forma eficaz e eficiente para que as empresas possam tirar o máximo proveito desses dados. É um processo crucial que é fundamental no mundo moderno orientado por dados.
A orquestração de dados ajuda você a obter insights claros sobre seus negócios, clientes, mercado e concorrentes, o que ajuda você a tomar decisões informadas e alcançar os resultados desejados.
Em termos mais simples, a orquestração de dados atua como um condutor que lê e coleta dados de várias fontes de dados. Isso garante que todos os dados representem a visão geral do desempenho da sua empresa.
Benefícios da orquestração de dados

A orquestração de dados oferece vários benefícios para as organizações, conforme listado abaixo.
Impulsiona a Tomada de Decisão
Você pode ter um conjunto de dados unificado e bem apresentado por meio da orquestração de dados. Isso ajuda você a fazer escolhas melhores, pois pode interpretar facilmente até mesmo os dados mais aleatórios e não decifrados com essa técnica.
Melhor experiência do cliente
Com uma melhor compreensão do comportamento, preferências e comentários de seus clientes, você pode atendê-los de uma maneira melhor. A orquestração de dados permitirá que você coloque esforços direcionados, levando a uma experiência aprimorada do cliente.
Eficiência operacional aprimorada
A orquestração de dados ajuda a reduzir as horas de trabalho, que você costumava dedicar à coleta e unificação de dados manualmente. Isso reduz os esforços manuais, minimiza os silos de dados e simplifica os dados de forma automática e sem esforço.
Econômico
A orquestração de dados baseada em nuvem oferece opções flexíveis de armazenamento e processamento. Assim, você evita cobranças extras e paga apenas pelo que precisa e usa.
Vantagem competitiva
Aproveitando os insights obtidos com a orquestração de dados, fica mais fácil para você tomar decisões melhores e mais rápidas do que seus concorrentes. Você pode ficar à frente de seus concorrentes, revelando oportunidades ocultas e respondendo proativamente às tendências do mercado.
Escalabilidade
A orquestração de dados pode lidar com as cargas crescentes à medida que o volume de dados cresce. Portanto, quando sua empresa se expandir, a orquestração de dados se adaptará às mudanças habituais.
Como funciona a orquestração de dados?

O processo de orquestração de dados envolve o gerenciamento e a coordenação de dados em toda a organização. Assim, inclui a coleta de dados de diferentes fontes, transformando-os em um único dado simplificado e automatizando o fluxo de trabalho.
A orquestração de dados permite que você tome decisões de negócios informadas usando os dados como seu guia. Assim, melhorando a eficiência de sua operação e facilitando a colaboração entre diferentes equipes e departamentos de sua organização.
Isso permite movimentação, análise e entrega de dados perfeitas e ajuda você a tomar decisões informadas.
Fases da Orquestração de Dados
A orquestração de dados é um processo complexo que envolve uma série de fases interconectadas. Cada fase é crítica para coletar, processar e analisar dados de forma eficaz.
Vamos nos aprofundar em cada uma dessas fases:
#1. Coleção de dados
A jornada de orquestração de dados começa com a fase de coleta de dados. Esta é a base de todo o processo, onde os dados são coletados de várias fontes. Essas fontes podem ser tão diversas quanto bancos de dados, APIs, aplicativos e arquivos externos.

Os dados coletados podem abranger dados estruturados, que seguem um formato específico, e dados não estruturados, que não possuem um modelo ou formulário predefinido. A qualidade, precisão e relevância dos dados coletados neste estágio influenciam significativamente os estágios subsequentes da orquestração de dados.
Portanto, é crucial ter estratégias e ferramentas robustas de coleta de dados para garantir a coleta de dados relevantes e de alta qualidade.
#2. Ingestão de dados
A fase de ingestão de dados envolve importar e carregar os dados coletados em um local de armazenamento centralizado, geralmente um data warehouse.
Essa localização central atua como um ponto focal onde os dados de diferentes fontes se reúnem. Essa consolidação agiliza o gerenciamento e o processamento de dados, permitindo que você os manuseie e utilize com eficiência.
Para garantir a transferência precisa de todos os dados relevantes para o local de armazenamento central, é imperativo que o processo de ingestão de dados ocorra sem problemas e sem erros.
#3. Integração e transformação de dados
A terceira fase da orquestração de dados envolve integrar e transformar os dados coletados para torná-los utilizáveis para análise. A integração de dados pega dados de várias fontes e os mescla para apresentar uma informação coesa e significativa.

Esse processo é crucial para eliminar silos de dados e garantir que todos os dados sejam acessíveis e utilizáveis.
Quando se trata de transformação de dados, você precisa lidar com valores ausentes, resolver inconsistências de dados e converter os dados em um formato padronizado para facilitar a análise. Esse processo crucial facilita a melhoria da qualidade dos dados e aumenta sua adequação para análise.
#4. Armazenamento e gerenciamento de dados
Depois que os dados foram integrados e transformados, a próxima fase envolve o armazenamento desses dados em um sistema de armazenamento apropriado.
Grandes volumes de dados podem exigir sistemas de armazenamento distribuídos, enquanto dados de alta velocidade podem exigir recursos de processamento em tempo real. O processo de gerenciamento de dados inclui a configuração de controles para acesso a dados, definição de políticas de governança de dados e organização de dados para permitir uma análise eficiente.
Garantir que os dados sejam armazenados com segurança, adequadamente organizados e facilmente acessíveis para análise é fundamental durante esta fase.
#5. Processamento e análise de dados
O processamento e a análise de dados envolvem a execução de fluxos de trabalho de dados para realizar várias tarefas de processamento de dados. Essas tarefas podem incluir filtragem, classificação, agregação e junção de conjuntos de dados.

Com base em seus requisitos de negócios, você tem duas opções de processamento – fluxo em tempo real ou métodos de processamento em lote. Depois que os dados são processados, eles ficam prontos para análise usando várias plataformas, como inteligência de negócios, ferramentas de visualização de dados ou aprendizado de máquina.
Essa etapa tem grande importância na extração de informações valiosas dos dados e na capacitação da tomada de decisões com base nos dados.
#6. Movimentação e distribuição de dados
Dependendo de suas necessidades de negócios, pode ser necessário mover os dados para diferentes sistemas para fins específicos.
A movimentação de dados envolve a transmissão ou replicação segura de dados para parceiros externos ou outros sistemas dentro da organização. Essa fase garante que os dados estejam disponíveis onde você precisar, seja para processamento, análise ou relatório posterior.
#7. Gestão de fluxo de trabalho
Automatizar os fluxos de trabalho reduz a intervenção manual e os erros, aumentando assim a eficiência dos dados.
A maioria das ferramentas de orquestração de dados oferece recursos para monitorar fluxos de trabalho de dados e facilitar operações suaves e eficientes. Essa fase desempenha um papel crucial para garantir que todo o processo de orquestração de dados seja executado sem problemas.
#8. Segurança de dados

Para habilitar a segurança dos dados, você deve estabelecer controles de acesso e mecanismos de autenticação. Essas medidas protegem informações valiosas contra acesso não autorizado e ajudam a manter a conformidade com os regulamentos de dados e políticas internas.
Ao proteger a integridade e a privacidade dos dados durante todo o seu ciclo de vida, você pode manter um ambiente seguro para informações confidenciais. Esta fase é crítica para manter a confiança do cliente e prevenir intenções maliciosas.
#9. Monitoramento e otimização de desempenho
Depois que o processo de orquestração de dados estiver em vigor, é essencial monitorar os fluxos de trabalho de dados e o desempenho do processamento. Ele ajuda a identificar gargalos, problemas de utilização de recursos e possíveis falhas.
Esta fase envolve a análise de métricas de desempenho e otimização de processos para aumentar a eficiência. Esse monitoramento e otimização contínuos ajudam a tornar o processo de orquestração de dados eficiente e eficaz.
#10. Feedback e Melhoria Contínua
A orquestração de dados é um processo repetitivo. Envolve obter feedback contínuo de analistas de dados, partes interessadas e usuários de negócios para identificar áreas de melhoria e novos requisitos e refinar os fluxos de trabalho de dados existentes.
Esse ciclo de feedback garante que o processo de orquestração de dados esteja em constante evolução e aprimoramento, atendendo assim às necessidades de mudança de seus negócios.
Casos de uso de orquestração de dados
A orquestração de dados encontra aplicação em vários setores para uma variedade de casos de uso.
E-commerce e Varejo

A orquestração de dados ajuda o setor de comércio eletrônico e varejo a gerenciar grandes volumes de dados de produtos, informações de inventário e interação com o cliente. Também os ajuda a integrar dados de lojas online, sistemas de ponto de venda e plataformas de gerenciamento da cadeia de suprimentos.
Saúde e Ciências da Vida
A orquestração de dados desempenha um papel vital no setor de saúde e ciências biológicas. Ele os ajuda a gerenciar, integrar e analisar registros eletrônicos de saúde, dados de dispositivos médicos e estudos de recursos com segurança. Também ajuda na interoperabilidade de dados, compartilhamento de dados de pacientes e avanços em pesquisas médicas.
Setor financeiro
Os serviços financeiros incluem diversos dados financeiros, como registros de transações, dados de mercado, informações de clientes, etc. Assim, usando a orquestração de dados, as organizações do setor financeiro podem melhorar seu gerenciamento de riscos, detecção de fraudes e conformidade regulatória.
Recursos Humanos
Os departamentos de RH podem usar a orquestração de dados para consolidar e analisar dados de funcionários, métricas de desempenho e informações de recrutamento. Também ajuda na gestão de talentos, no engajamento dos funcionários e no planejamento da força de trabalho.
Mídia e Entretenimento

O setor de mídia e entretenimento engloba a distribuição de conteúdo em várias plataformas. A indústria de mídia pode facilmente fazer anúncios direcionados, mecanismos de recomendação de conteúdo e análise de audiência por meio da orquestração de dados.
Gestão da cadeia de abastecimento
O gerenciamento da cadeia de suprimentos compreende dados de fornecedores, provedores de logística e sistemas de estoque. Aqui, a orquestração de dados ajuda a integrar todos esses dados e permite o rastreamento de produtos em tempo real.
Melhores plataformas de orquestração de dados
Agora que você tem uma ideia de orquestração de dados, vamos falar sobre as melhores plataformas de orquestração de dados.
#1. Flyte

Flyte é uma plataforma abrangente de orquestração de fluxo de trabalho projetada para unificar dados, aprendizado de máquina (ML) e dados analíticos. Este sistema baseado em nuvem para aprendizado de máquina e processamento de dados pode ajudá-lo a gerenciar dados com confiabilidade e eficácia.
A Flyte incorpora uma solução distribuída e de programação estruturada de código aberto. Ele permite que você use fluxos de trabalho simultâneos, escaláveis e fáceis de manter para tarefas de aprendizado de máquina e processamento de dados.
Um dos aspectos exclusivos do Flyte é o uso de buffers de protocolo como linguagem de especificação para definir esses fluxos de trabalho e tarefas, tornando-o uma solução flexível e adaptável para várias necessidades de dados.
Características principais
- Facilita a experimentação rápida usando software de nível de produção
- Projetado com escalabilidade em mente para lidar com cargas de trabalho em constante mudança e necessidades de recursos
- Capacita profissionais e cientistas de dados a criar fluxos de trabalho de forma independente usando o Python SDK
- Fornece dados extremamente flexíveis e fluxos de trabalho de ML com linhagem de dados de ponta a ponta e componentes reutilizáveis
- Oferece uma plataforma centralizada para gerenciar o ciclo de vida dos fluxos de trabalho
- Requer sobrecarga mínima de manutenção
- Apoiado por uma comunidade vibrante para suporte
- Oferece uma variedade de integrações para um processo de desenvolvimento de fluxo de trabalho simplificado
#2. Prefeito
Encontrar Prefeito, a solução de gerenciamento de fluxo de trabalho de última geração impulsionada pelo mecanismo de fluxo de trabalho Prefect Core de código aberto. Ele representa a vanguarda no gerenciamento de fluxos de trabalho com seus recursos avançados.

O Prefect foi projetado especificamente para ajudá-lo a lidar perfeitamente com tarefas complexas envolvendo dados, com simplicidade e eficiência como princípios básicos. Com o Prefect à sua disposição, organize facilmente suas funções Python em unidades de trabalho gerenciáveis enquanto desfruta de recursos abrangentes de monitoramento e coordenação.
Uma das características notáveis do Prefect é sua capacidade de criar fluxos de trabalho robustos e dinâmicos, permitindo que você se adapte suavemente às mudanças em seu ambiente. Caso ocorra algum evento inesperado, o Prefect recupera normalmente, garantindo o gerenciamento de dados contínuo.
Essa adaptabilidade torna o Prefect a escolha ideal para situações em que a flexibilidade é crucial. Com novas tentativas automáticas, execução distribuída, agendamento, armazenamento em cache e muito mais, o Prefect se torna uma ferramenta inestimável capaz de lidar com qualquer desafio relacionado a dados que você possa encontrar.
Características principais
- Automação para observabilidade e controle em tempo real
- Uma comunidade vibrante para suporte e compartilhamento de conhecimento
- Documentação abrangente para criar aplicativos de dados poderosos
- Fórum de discurso para respostas a perguntas relacionadas ao prefeito
#3. Control-M
Control-M é uma solução robusta que conecta, automatiza e orquestra fluxos de trabalho de aplicativos e dados em ambientes locais, privados e de nuvem pública.
Essa ferramenta garante sempre a conclusão pontual e consistente do trabalho, tornando-a uma solução confiável se você precisar de um gerenciamento de dados consistente e eficiente. Com uma interface consistente e uma ampla variedade de plug-ins, os usuários podem gerenciar facilmente todas as suas operações, incluindo transferências de arquivos, aplicativos, fontes de dados e infraestrutura.

Você pode provisionar rapidamente o Control-M na nuvem, usando os recursos transitórios dos serviços baseados em nuvem. Isso o torna uma solução versátil e adaptável para várias necessidades de dados.
Características principais
- Recursos operacionais avançados para desenvolvimento e operações
- Gerenciamento proativo de SLA com análise preditiva inteligente
- Suporte robusto para auditorias, conformidade e governança
- Estabilidade comprovada para escalar de dezenas a milhões de trabalhos com tempo de inatividade zero
- Abordagem Jobs-as-Code para escalar a colaboração Dev e Ops
- Fluxos de trabalho simplificados em ambientes híbridos e multinuvem
- Movimento e visibilidade de arquivos seguros, integrados e inteligentes
#4. datacoral
datacoral é um fornecedor líder de uma pilha de infraestrutura de dados abrangente para big data. Ele pode coletar dados de várias fontes em tempo real sem esforço manual. Depois de coletar os dados, ele os organiza automaticamente em um mecanismo de consulta de sua escolha.
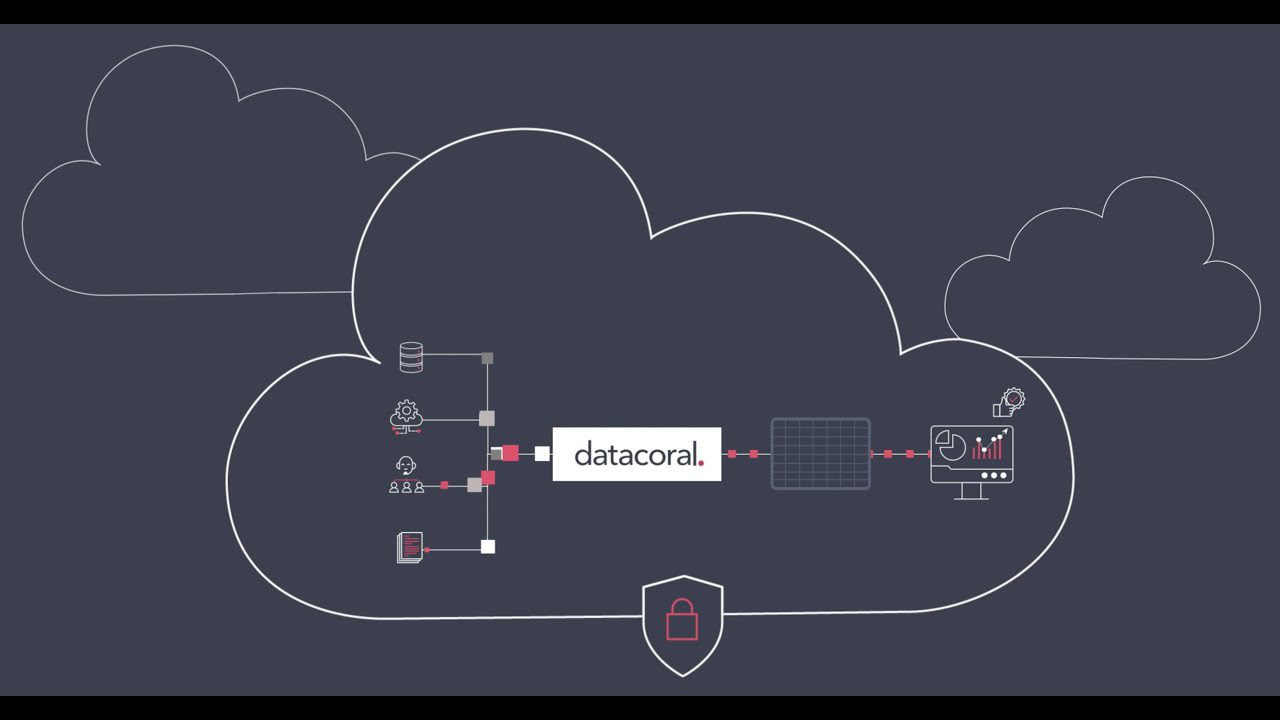
Depois de obter informações valiosas, você pode utilizar os dados para vários fins e publicá-los. A linguagem é focada em dados, permitindo acesso em tempo real a fontes de dados para qualquer mecanismo de consulta. Ele também serve como uma ferramenta para monitorar a atualização dos dados e garantir a integridade dos dados, tornando-se uma solução ideal se você precisar de um gerenciamento de dados confiável e eficiente.
Características principais
- Conectores de dados sem código para acesso seguro e confiável aos dados
- Arquitetura de metadados para uma imagem de dados completa
- Extração de dados personalizável com visibilidade total da atualização e qualidade dos dados
- Instalação segura em sua VPC
- Verificações de qualidade de dados prontas para uso
- Conectores CDC para bancos de dados como PostgreSQL e MySQL
- Construído para escalar com uma estrutura simplificada para integrações e pipelines de dados baseados em nuvem
#5. punhal
punhal é uma plataforma de orquestração de código aberto de última geração para desenvolvimento, produção e monitoramento de ativos de dados.

A ferramenta aborda a engenharia de dados desde o início, abrangendo todo o ciclo de vida do desenvolvimento, desde o desenvolvimento inicial e a implantação até o monitoramento e a observabilidade contínuos. O Dagster é uma solução completa e abrangente se você precisar de um gerenciamento de dados eficaz e confiável.
Características principais
- Fornece linhagem e observabilidade integradas
- Usa um modelo de programação declarativa para facilitar o gerenciamento do fluxo de trabalho
- Oferece a melhor testabilidade da categoria para fluxos de trabalho confiáveis e precisos
- Dagster Cloud para implantações sem servidor ou híbridas, ramificação nativa e CI/CD pronto para uso
- Integra-se com as ferramentas que você já usa e pode ser implantado em sua infraestrutura
Conclusão
A orquestração de dados é uma ótima maneira de agilizar e otimizar todo o processo de gerenciamento de dados. Simplifica como as empresas lidam com seus dados, desde a coleta e preparação até a análise e utilização efetiva.
A orquestração de dados permite que as empresas colaborem facilmente com diferentes fontes de dados, aplicativos e equipes. Como resultado, você experimentará tomadas de decisão mais rápidas e precisas, produtividade aprimorada e desempenho geral aprimorado.
Portanto, escolha qualquer uma das ferramentas de orquestração de dados acima com base em suas preferências e requisitos e colha seus benefícios.
Você também pode explorar algumas ferramentas de orquestração de contêineres para DevOps