Uma matriz de confusão serve como instrumento para avaliar a performance de modelos de classificação em aprendizado de máquina supervisionado.
O que Define uma Matriz de Confusão?
A percepção humana é subjetiva, moldando como interpretamos até mesmo fatos. Uma linha que parece ter 10 cm para mim, pode parecer ter 9 cm para você. O valor real, entretanto, pode ser 9, 10 ou qualquer outro valor. O que percebemos é o valor que foi previsto!
O Mecanismo do Pensamento Humano
Assim como nosso cérebro aplica nossa lógica para fazer previsões, as máquinas utilizam diversos algoritmos (conhecidos como algoritmos de aprendizado de máquina) para chegar a um valor previsto para uma determinada questão. Esses valores podem ou não corresponder ao valor real.
Em um ambiente competitivo, é crucial saber se nossa previsão é precisa para avaliarmos nosso desempenho. Analogamente, podemos avaliar a eficácia de um algoritmo de aprendizado de máquina pela quantidade de previsões corretas que ele produz.
O que Exatamente é um Algoritmo de Aprendizado de Máquina?
As máquinas buscam soluções para problemas aplicando uma lógica específica ou um conjunto de instruções, chamados algoritmos de aprendizado de máquina. Existem três tipos principais: supervisionado, não supervisionado e por reforço.
Categorias de Algoritmos de Aprendizado de Máquina
Os algoritmos supervisionados são os mais básicos, onde já conhecemos as respostas e treinamos as máquinas para alcançá-las através de dados – como uma criança aprendendo a distinguir pessoas de diferentes idades observando suas características repetidamente.
Os algoritmos de aprendizado de máquina supervisionados se dividem em classificação e regressão.
Algoritmos de classificação categorizam dados com base em critérios. Por exemplo, se você deseja que seu algoritmo separe clientes por preferências alimentares (os que gostam de pizza e os que não gostam), usaria um algoritmo de classificação como árvore de decisão, floresta aleatória, Bayes ingênuo ou SVM (Máquina de Vetor de Suporte).
Qual desses algoritmos seria mais eficaz? Por que escolher um em detrimento de outro?
É aqui que entra a matriz de confusão…
A matriz de confusão é uma tabela que detalha a precisão de um algoritmo de classificação ao categorizar um conjunto de dados. Contrário ao nome, ela não visa confundir, mas sim indicar que um excesso de previsões incorretas sugere que o algoritmo está “confuso”😉!
Assim, a matriz de confusão é uma ferramenta para avaliar o desempenho de um algoritmo de classificação.
Como Funciona?
Suponha que você tenha aplicado diferentes algoritmos para o problema binário de classificar pessoas com base em seu gosto por pizza. Para avaliar qual algoritmo se aproxima mais da resposta correta, você usaria uma matriz de confusão. Para problemas de classificação binária (gosta/não gosta, verdadeiro/falso, 1/0), a matriz de confusão gera quatro valores:
- Verdadeiro Positivo (VP)
- Verdadeiro Negativo (VN)
- Falso Positivo (FP)
- Falso Negativo (FN)
Quais São os Quatro Componentes de uma Matriz de Confusão?
Os quatro valores definidos na matriz de confusão compõem sua estrutura.
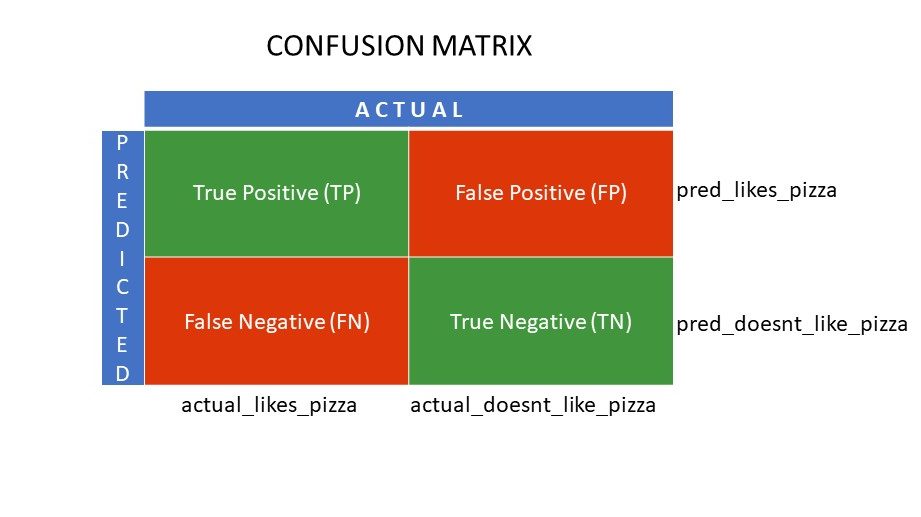 Matrizes de confusão
Matrizes de confusão
Verdadeiro Positivo (VP) e Verdadeiro Negativo (VN) são os valores corretamente previstos pelo algoritmo de classificação.
- VP representa aqueles que gostam de pizza e foram corretamente classificados.
- VN representa aqueles que não gostam de pizza e foram corretamente classificados.
Falso Positivo (FP) e Falso Negativo (FN) são os valores que o classificador previu incorretamente.
- FP representa aqueles que não gostam de pizza (negativo), mas o classificador previu que gostam (erroneamente positivo). FP é também chamado de erro tipo I.
- FN representa aqueles que gostam de pizza (positivo), mas o classificador previu que não (erroneamente negativo). FN é também chamado de erro tipo II.
Para melhor compreensão, vamos usar um exemplo real.
Suponha que você tenha dados de 400 pessoas que fizeram teste para Covid. Você obteve os resultados de vários algoritmos que determinam o número de pessoas com e sem Covid.
A seguir, duas matrizes de confusão para comparação:
Ao observar ambas, você pode ser levado a pensar que o primeiro algoritmo é mais preciso. No entanto, para uma avaliação mais precisa, precisamos de métricas que comprovem qual algoritmo é superior.
Métricas Derivadas da Matriz de Confusão e sua Importância
As principais métricas que nos ajudam a avaliar a eficácia de um classificador são:
#1. Revocação/Sensibilidade
Revocação, sensibilidade ou taxa de verdadeiros positivos (TVP) é a proporção entre previsões positivas corretas (VP) e o total de positivos (VP+FN).
R = VP / (VP + FN)
Revocação mede a proporção de resultados positivos corretos retornados entre todos os resultados positivos que poderiam ter sido produzidos. Um valor de revocação alto indica menos falsos negativos, o que é desejável. Use a revocação quando a detecção de falsos negativos é essencial. Por exemplo, se um paciente tem bloqueios cardíacos múltiplos e o modelo diz que está saudável, pode ser fatal.
#2. Precisão
Precisão é a medida de resultados positivos corretos entre todas as previsões positivas, incluindo verdadeiros e falsos positivos.
Pr = VP / (VP + FP)
A precisão é crucial quando falsos positivos são relevantes. Por exemplo, se um modelo indica que alguém tem diabetes quando não tem, o médico pode prescrever medicamentos desnecessários, levando a efeitos colaterais graves.
#3. Especificidade
Especificidade, ou taxa de verdadeiros negativos (TVN), é a proporção de resultados negativos corretos entre todos os resultados que poderiam ter sido negativos.
S = VN / (VN + FP)
Essa métrica avalia quão bem o classificador está identificando os valores negativos.
#4. Acurácia
Acurácia é a proporção de previsões corretas sobre o total de previsões. Por exemplo, se você previu corretamente 20 positivos e 10 negativos em uma amostra de 50, a acurácia do seu modelo seria 30/50.
Acurácia A = (VP + VN) / (VP + VN + FP + FN)
#5. Prevalência
Prevalência é a proporção de resultados positivos em relação ao total de resultados.
P = (VP + FN) / (VP + VN + FP + FN)
#6. Pontuação F
Às vezes, comparar classificadores usando apenas precisão e revocação é difícil, pois são apenas médias aritméticas de uma combinação dos quatro componentes da matriz. Nesses casos, usamos a Pontuação F ou Pontuação F1, que é a média harmônica, mais precisa por ser menos afetada por valores extremos. Uma Pontuação F mais alta (máximo 1) indica um modelo superior.
Pontuação F = 2 * Precisão * Revocação / (Revocação + Precisão)
A pontuação F1 é útil quando é crucial controlar tanto falsos positivos quanto falsos negativos. Por exemplo, pessoas sem Covid não devem ser isoladas desnecessariamente, e quem tem Covid precisa ser isolado.
#7. Curvas ROC
Acurácia e Precisão são métricas úteis para dados balanceados. Contudo, para conjuntos de dados desequilibrados, alta precisão não garante a eficiência do classificador. Por exemplo, se 90 de 100 alunos falam espanhol, mesmo que seu algoritmo diga que todos falam, a precisão será de 90%, uma representação enganosa do modelo. Nesses casos, métricas como ROC são mais eficazes.
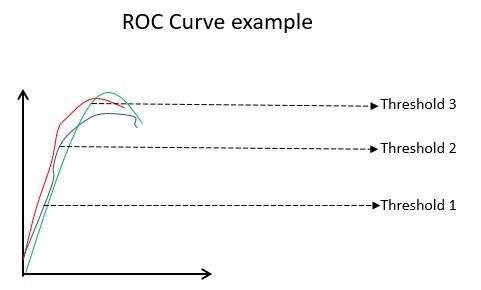 Exemplo de curva ROC
Exemplo de curva ROC
A curva ROC (Característica de Operação do Receptor) mostra visualmente o desempenho de um modelo de classificação binária em diferentes limiares de classificação. Ela é um gráfico de TVP contra a Taxa de Falso Positivo (TFP), calculada como (1-Especificidade) em diferentes valores de limiar. O valor mais próximo de 45 graus (canto superior esquerdo) no gráfico é o limiar mais preciso. Se o limiar é muito alto, teremos poucos falsos positivos, mas muitos falsos negativos, e vice-versa.
Geralmente, ao comparar curvas ROC de vários modelos, aquele com a maior Área Sob a Curva (AUC) é considerado o melhor.
Vamos calcular as métricas para as matrizes de confusão do Classificador I e Classificador II:
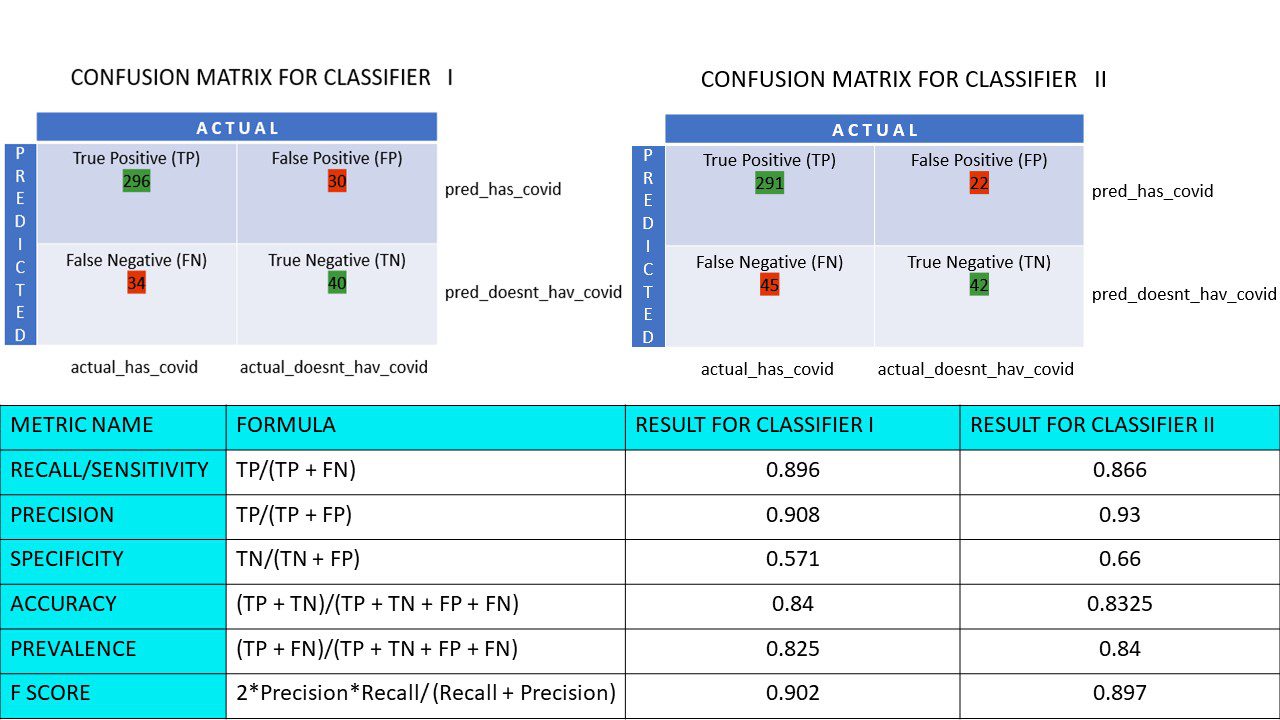 Comparação de métricas para os classificadores 1 e 2 da pesquisa de pizza
Comparação de métricas para os classificadores 1 e 2 da pesquisa de pizza
Observamos que a precisão é maior no classificador II, enquanto a revocação é ligeiramente maior no classificador I. A escolha entre os classificadores I ou II dependerá das necessidades específicas do problema.
Matriz de Confusão N x N
Até agora, vimos matrizes de confusão para classificadores binários. Mas, se houvesse mais categorias que apenas sim/não ou gosta/não gosta? Por exemplo, um algoritmo que classifique imagens nas cores vermelho, verde e azul. Isso é chamado de classificação multiclasse. O número de variáveis de saída determina o tamanho da matriz. Nesse caso, a matriz seria 3×3.
 Matriz de confusão para um classificador multiclasse
Matriz de confusão para um classificador multiclasse
Conclusão
A matriz de confusão é uma ferramenta de avaliação valiosa que oferece informações detalhadas sobre o desempenho de um algoritmo de classificação. Ela é eficaz para classificadores binários e multiclasse, onde há mais de dois parâmetros a serem considerados. A matriz de confusão é fácil de visualizar e permite calcular métricas de desempenho como Pontuação F, precisão, ROC e acurácia.
Você também pode aprender sobre como selecionar algoritmos de ML para problemas de regressão.