É notável que as estatísticas da Forbes indicam que impressionantes 90% das empresas globais empregam análises de Big Data para a elaboração de seus relatórios de investimento.
O aumento da popularidade do Big Data resulta em um crescimento nas oportunidades de emprego relacionadas ao Hadoop, superando os níveis anteriores.
Para auxiliar você a conquistar uma posição como especialista em Hadoop, este artigo apresenta uma compilação de perguntas e respostas de entrevistas que podem ser cruciais para o seu sucesso no processo seletivo.
Talvez a compreensão do potencial de ganhos, que torna as funções em Hadoop e Big Data tão atrativas, possa impulsioná-lo em sua preparação para a entrevista. 🤔
- Segundo o Indeed.com, um desenvolvedor de Big Data Hadoop nos EUA tem um salário médio de US$ 144.000.
- Conforme o itjobswatch.co.uk, o salário médio de um desenvolvedor de Big Data Hadoop no Reino Unido é de £ 66.750.
- Na Índia, o Indeed.com informa que a remuneração média é de ₹ 16.00.000.
São valores atraentes, concorda? Vamos, então, explorar o universo do Hadoop.
O Que É Hadoop?
Hadoop é uma estrutura robusta, desenvolvida em Java, que utiliza modelos de programação para processar, armazenar e analisar extensos conjuntos de dados.
Sua arquitetura padrão permite a expansão de servidores únicos para múltiplas máquinas, oferecendo recursos de computação e armazenamento locais. Adicionalmente, a capacidade de detecção e tratamento de falhas na camada de aplicação resulta em serviços de alta disponibilidade, conferindo ao Hadoop um alto nível de confiabilidade.
Vamos agora abordar diretamente as perguntas mais frequentes em entrevistas sobre Hadoop, juntamente com suas respostas apropriadas.
Perguntas e Respostas em Entrevistas Sobre Hadoop
Qual a Unidade de Armazenamento no Hadoop?
Resposta: A unidade de armazenamento no Hadoop é conhecida como Hadoop Distributed File System (HDFS).
Como o Armazenamento Conectado à Rede se Diferencia do Sistema de Arquivos Distribuído do Hadoop?
Resposta: O HDFS, sendo o principal sistema de armazenamento do Hadoop, opera como um sistema de arquivos distribuído, armazenando arquivos de grandes dimensões utilizando hardware padrão. O NAS, por outro lado, funciona como um servidor de armazenamento de dados em nível de arquivo, permitindo o acesso aos dados por diferentes grupos de clientes.
Enquanto no NAS o armazenamento é realizado em hardware dedicado, o HDFS distribui blocos de dados entre as máquinas dentro do cluster Hadoop.
O NAS emprega dispositivos de armazenamento de ponta, o que acarreta custos elevados, enquanto o hardware comum utilizado no HDFS é mais econômico.
No NAS, os dados são armazenados separadamente dos cálculos, o que o torna inadequado para o MapReduce. Por outro lado, a arquitetura do HDFS é projetada para operar em conjunto com o framework MapReduce. Os cálculos são direcionados aos dados dentro da estrutura MapReduce, em vez de o contrário.
Explique o MapReduce no Hadoop e o Embaralhamento
Resposta: MapReduce refere-se a duas operações distintas que programas Hadoop executam, permitindo uma alta escalabilidade em centenas a milhares de servidores em um cluster Hadoop. O embaralhamento, por sua vez, transfere a saída do mapa dos mappers para os redutores necessários no MapReduce.
Uma Visão Geral da Arquitetura do Apache Pig
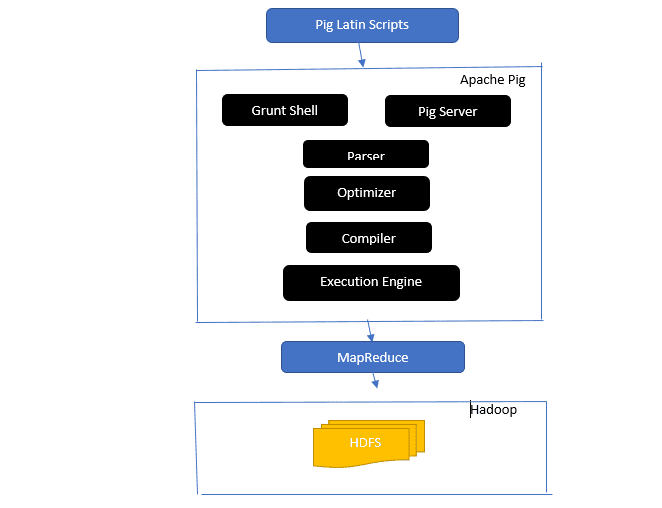 Arquitetura do Apache Pig
Arquitetura do Apache Pig
Resposta: A arquitetura do Apache Pig inclui um interpretador Pig Latin que processa e analisa grandes conjuntos de dados usando scripts em Pig Latin.
O Apache Pig também organiza conjuntos de dados nos quais operações de dados como junção, carregamento, filtro, classificação e agrupamento são executadas.
A linguagem Pig Latin utiliza mecanismos de execução, como shells de concessão, UDFs e incorporados, para criar scripts Pig que executam as tarefas necessárias.
O Pig simplifica o trabalho dos programadores, convertendo esses scripts em séries de tarefas MapReduce.
Os componentes da arquitetura do Apache Pig incluem:
- Analisador: Analisa os scripts Pig, verifica a sintaxe e realiza a verificação de tipo. A saída do analisador é um DAG (gráfico acíclico direcionado) que representa as declarações e operadores lógicos do Pig Latin.
- Otimizador: Implementa otimizações lógicas no DAG, como projeção e pushdown.
- Compilador: Compila o plano lógico otimizado em uma sequência de trabalhos MapReduce.
- Mecanismo de Execução: É onde ocorre a execução final dos trabalhos MapReduce para gerar a saída desejada.
- Modo de Execução: Os modos de execução do Apache Pig incluem principalmente o modo local e o MapReduce.
Resposta: O serviço Metastore no Metastore Local é executado na mesma JVM que o Hive, mas se conecta a um banco de dados executado em um processo separado na mesma máquina ou em uma máquina remota. Por outro lado, o Metastore no Metastore Remoto opera em sua própria JVM, separada da JVM do serviço Hive.
Quais São os Cinco V’s do Big Data?
Resposta: Os cinco V’s representam as características principais do Big Data. Eles incluem:
- Valor: O Big Data visa proporcionar benefícios significativos com alto retorno sobre o investimento (ROI) para as organizações que utilizam o Big Data em suas operações de dados. O valor reside na descoberta de insights e reconhecimento de padrões, resultando em relações mais sólidas com os clientes e operações mais eficientes, entre outros benefícios.
- Variedade: Representa a heterogeneidade nos tipos de dados coletados. Os formatos variam, incluindo CSV, vídeos, áudios, entre outros.
- Volume: Define a quantidade e o tamanho consideráveis dos dados gerenciados e analisados pelas organizações. Esses dados experimentam um crescimento exponencial.
- Velocidade: Representa a taxa exponencial de crescimento dos dados.
- Veracidade: Refere-se à incerteza ou imprecisão dos dados disponíveis devido a dados incompletos ou inconsistentes.
Explique os Diferentes Tipos de Dados do Pig Latin
Resposta: Os tipos de dados no Pig Latin incluem tipos atômicos e complexos.
Os tipos de dados atômicos são os básicos, utilizados em todas as linguagens de programação. Eles incluem:
- Int: Define um inteiro de 32 bits com sinal. Exemplo: 13
- Long: Define um inteiro de 64 bits. Exemplo: 10L
- Float: Define um ponto flutuante de 32 bits com sinal. Exemplo: 2.5F
- Double: Define um ponto flutuante de 64 bits com sinal. Exemplo: 23.4
- Boolean: Define um valor booleano. Inclui: Verdadeiro/Falso
- Datetime: Define um valor de data e hora. Exemplo: 1980-01-01T00:00.00.000+00:00
Os tipos de dados complexos incluem:
- Map: Refere-se a um conjunto de pares chave-valor. Exemplo: [‘color’#’yellow’, ‘number’#3]
- Bag: É uma coleção de tuplas, utilizando o símbolo ‘{}’. Exemplo: {(Henrique, 32), (Kiti, 47)}
- Tupla: Define um conjunto ordenado de campos. Exemplo: (Idade, 33)
O Que São Apache Oozie e Apache ZooKeeper?
Resposta: Apache Oozie é um agendador para Hadoop, responsável por agendar e coordenar trabalhos Hadoop como um único trabalho lógico.
O Apache ZooKeeper, por outro lado, coordena vários serviços em um ambiente distribuído. Ele simplifica o trabalho dos desenvolvedores, expondo serviços simples como sincronização, agrupamento, manutenção de configurações e nomenclatura. O Apache ZooKeeper também oferece suporte integrado para enfileiramento e eleição de líder.
Qual o Papel do Combiner, RecordReader e Partitioner em uma Operação MapReduce?
Resposta: O Combiner atua como um mini redutor. Ele recebe e processa dados das tarefas map e, em seguida, direciona a saída para a fase de redução.
O RecordReader interage com o InputSplit e converte os dados em pares chave-valor para que o mapper possa lê-los corretamente.
O Partitioner decide o número de tarefas de redução necessárias para agregar os dados e como as saídas do combiner são enviadas para o redutor. O Partitioner também controla o particionamento das chaves das saídas intermediárias do mapa.
Mencione Diferentes Distribuições Específicas de Fornecedores do Hadoop
Resposta: Vários fornecedores estendem as capacidades do Hadoop, incluindo:
- IBM Open Platform.
- Cloudera CDH Hadoop Distribution
- MapR Hadoop Distribution
- Amazon Elastic MapReduce
- Hortonworks Data Platform (HDP)
- Big Data Essential Suite
- Datastax Enterprise Analytics
- Microsoft Azure HDInsight – Distribuição Hadoop baseada em nuvem.
Por Que o HDFS é Tolerante a Falhas?
Resposta: O HDFS replica dados em diferentes DataNodes, tornando-o tolerante a falhas. O armazenamento de dados em nós diferentes permite a recuperação a partir de outros nós caso um falhe.
Diferencie Federação e Alta Disponibilidade
Resposta: A HDFS Federation oferece tolerância a falhas, permitindo um fluxo contínuo de dados mesmo quando um nó falha. A alta disponibilidade, por outro lado, requer duas máquinas separadas configurando o NameNode ativo e o NameNode secundário em máquinas diferentes.
A federação pode ter um número ilimitado de NameNodes não relacionados, enquanto na alta disponibilidade, apenas dois NameNodes relacionados, ativos e de espera, operam continuamente.
Os NameNodes na federação compartilham um pool de metadados, com cada NameNode tendo seu próprio pool dedicado. Na alta disponibilidade, os NameNodes ativos são executados um de cada vez, enquanto os NameNodes de espera permanecem inativos, atualizando seus metadados periodicamente.
Como Verificar o Status dos Blocos e a Saúde do Sistema de Arquivos?
Resposta: Utilize o comando hdfs fsck / tanto no nível do usuário raiz quanto em um diretório individual para examinar o status de integridade do sistema de arquivos HDFS.
Comando HDFS fsck em uso:
hdfs fsck / -files --blocks –locations> dfs-fsck.log
Descrição do comando:
- -files: Exibe os arquivos que estão sendo verificados.
- –locations: Exibe a localização de todos os blocos durante a verificação.
Comando para verificar o estado dos blocos:
hdfs fsck <caminho> -files -blocks
- <caminho>: Inicia a verificação a partir do caminho especificado aqui.
- –blocks: Exibe os blocos do arquivo durante a verificação.
Quando Utilizar os Comandos rmadmin-refreshNodes e dfsadmin-refreshNodes?
Resposta: Esses dois comandos são úteis para atualizar as informações do nó durante o comissionamento ou quando o comissionamento do nó está concluído.
O comando dfsadmin-refreshNodes é executado pelo cliente HDFS e atualiza a configuração do nó do NameNode. O comando rmadmin-refreshNodes, por outro lado, executa tarefas administrativas do ResourceManager.
O Que é um Checkpoint?
Resposta: Checkpoint é uma operação que combina as alterações mais recentes do sistema de arquivos com a FSImage mais recente, garantindo que os arquivos de log de edição permaneçam pequenos o suficiente para acelerar o processo de inicialização de um NameNode. O checkpoint ocorre no NameNode secundário.
Por Que Utilizar HDFS em Aplicações com Grandes Conjuntos de Dados?
Resposta: O HDFS fornece uma arquitetura DataNode e NameNode que implementa um sistema de arquivos distribuído.
Essas duas arquiteturas proporcionam acesso de alto desempenho aos dados em clusters Hadoop altamente escaláveis. Seu NameNode armazena os metadados do sistema de arquivos na RAM, o que significa que a quantidade de memória limita o número de arquivos no sistema de arquivos HDFS.
O Que o Comando ‘jps’ Faz?
Resposta: O comando Java Virtual Machine Process Status (JPS) verifica se daemons Hadoop específicos, como NodeManager, DataNode, NameNode e ResourceManager, estão em execução. Esse comando precisa ser executado a partir do diretório raiz para verificar os nós operacionais no Host.
O Que é ‘Execução Especulativa’ no Hadoop?
Resposta: É um processo onde o nó mestre no Hadoop, em vez de corrigir tarefas lentas detectadas, inicia uma nova instância da mesma tarefa como uma tarefa de backup (tarefa especulativa) em outro nó. A execução especulativa economiza muito tempo, especialmente em ambientes com alta carga de trabalho.
Cite os Três Modos em Que o Hadoop Pode Ser Executado
Resposta: Os três modos principais de execução do Hadoop incluem:
- Nó autônomo: Modo padrão que executa os serviços Hadoop usando o FileSystem local e um único processo Java.
- Nó pseudodistribuído: Executa todos os serviços Hadoop utilizando uma única implementação do Hadoop.
- Nó totalmente distribuído: Executa os serviços mestre e escravo do Hadoop em nós separados.
O Que É um UDF?
Resposta: UDF (User-Defined Functions), ou funções definidas pelo usuário, permitem que você codifique suas funções personalizadas para processar valores de coluna durante uma consulta Impala.
O Que É DistCP?
Resposta: DistCp, ou Distributed Copy, é uma ferramenta útil para cópias de dados em larga escala entre clusters ou dentro do mesmo cluster. Utilizando o MapReduce, o DistCp implementa uma cópia distribuída eficiente de grandes volumes de dados, além de lidar com erros, recuperação e geração de relatórios.
Resposta: O metastore do Hive é um serviço que armazena metadados do Apache Hive para as tabelas do Hive em um banco de dados relacional, como o MySQL. Ele fornece uma API de serviço metastore que permite acesso central aos metadados.
Defina RDD
Resposta: RDD, ou Resilient Distributed Datasets (Conjuntos de Dados Distribuídos Resilientes), é a estrutura de dados do Spark, sendo uma coleção distribuída imutável de elementos de dados, que é processada nos diferentes nós do cluster.
Como Incluir Bibliotecas Nativas em Trabalhos YARN?
Resposta: Isso pode ser feito utilizando -Djava.library.path no comando ou definindo LD+LIBRARY_PATH no arquivo .bashrc, seguindo o seguinte formato:
<property> <name>mapreduce.map.env</name> <value>LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/caminho/para/minhas/libs</value> </property>
Explique ‘WAL’ no HBase
Resposta: O Write Ahead Log (WAL) é um protocolo de recuperação que registra as alterações de dados do MemStore no HBase para o armazenamento baseado em arquivo. O WAL recupera esses dados se o RegionalServer falhar ou antes de liberar o MemStore.
YARN é um Substituo para o Hadoop MapReduce?
Resposta: Não, YARN não substitui o Hadoop MapReduce. Em vez disso, o MapReduce é suportado por uma tecnologia poderosa chamada Hadoop 2.0 ou MapReduce 2.
Qual a Diferença entre ORDER BY e SORT BY no Hive?
Resposta: Embora ambos os comandos organizem dados de forma classificada no Hive, os resultados do uso de SORT BY podem ser apenas parcialmente ordenados.
Além disso, SORT BY requer um redutor para ordenar as linhas. Esses redutores podem ser múltiplos, o que significa que a saída final pode ser apenas parcialmente ordenada.
Por outro lado, ORDER BY requer apenas um redutor para uma ordenação total na saída. Você também pode usar a palavra-chave LIMIT, que reduz o tempo total de classificação.
Qual a Diferença entre Spark e Hadoop?
Resposta: Apesar de Hadoop e Spark serem frameworks de processamento distribuído, a principal diferença reside na forma de processamento. Enquanto Hadoop é eficiente para processamento em lote, Spark é eficiente para processamento de dados em tempo real.
Além disso, Hadoop lê e escreve arquivos principalmente no HDFS, enquanto o Spark usa o conceito de Resilient Distributed Dataset para processar dados na RAM.
Em termos de latência, Hadoop é uma estrutura de computação de alta latência, sem modo interativo para processar dados, enquanto Spark é uma estrutura de computação de baixa latência, que processa dados de forma interativa.
Compare Sqoop e Flume
Resposta: Sqoop e Flume são ferramentas do Hadoop que coletam dados de diversas fontes e carregam esses dados no HDFS.
- Sqoop (SQL-to-Hadoop) extrai dados estruturados de bancos de dados, como Teradata, MySQL, Oracle, etc., enquanto Flume é útil para extrair dados não estruturados de fontes de banco de dados e carregá-los no HDFS.
- Em termos de eventos direcionados, Flume é orientado a eventos, enquanto Sqoop não é.
- Sqoop usa uma arquitetura baseada em conectores, onde os conectores sabem como se conectar a diferentes fontes de dados. Flume usa uma arquitetura baseada em agente, onde o código escrito no agente é responsável por coletar os dados.
- Devido à natureza distribuída do Flume, ele pode facilmente coletar e agregar dados. O Sqoop é útil para transferência paralela de dados, resultando em uma saída com vários arquivos.
Explique o BloomMapFile
Resposta: BloomMapFile é uma classe que estende a classe MapFile e utiliza filtros bloom dinâmicos, que fornecem um teste de associação rápido para chaves.
Liste as Diferenças entre HiveQL e PigLatin
Resposta: Enquanto HiveQL é uma linguagem declarativa semelhante a SQL, PigLatin é uma linguagem de fluxo de dados processual de alto nível.
O Que É Limpeza de Dados?
Resposta: A limpeza de dados é um processo essencial para eliminar ou corrigir erros identificados nos dados, que incluem dados incorretos, incompletos, corrompidos, duplicados e formatados de forma inadequada.
O objetivo desse processo é melhorar a qualidade dos dados e fornecer informações mais precisas, consistentes e confiáveis, essenciais para uma tomada de decisão eficiente dentro de uma organização.
Conclusão💃
Dado o aumento atual nas oportunidades de emprego em Big Data e Hadoop, pode ser vantajoso aprimorar suas chances de ingressar nesse mercado. As perguntas e respostas de entrevista sobre Hadoop apresentadas neste artigo podem ser um diferencial em sua próxima entrevista.
Você pode explorar recursos adicionais para aprender mais sobre Big Data e Hadoop.
Boa sorte! 👍