

Big O Analysis é uma técnica para analisar e classificar a eficiência de algoritmos.
Isso permite que você escolha os algoritmos mais eficientes e escalonáveis. Este artigo é uma folha de dicas do Big O que explica tudo o que você precisa saber sobre a notação Big O.
últimas postagens
O que é análise Big O?
Big O Analysis é uma técnica para analisar quão bem os algoritmos são dimensionados. Especificamente, perguntamos quão eficiente é um algoritmo à medida que o tamanho da entrada aumenta.
Eficiência é quão bem os recursos do sistema são usados durante a produção de uma saída. Os recursos com os quais estamos principalmente preocupados são o tempo e a memória.
Portanto, ao realizar o Big O Analysis, as perguntas que fazemos são:
A resposta à primeira pergunta é a complexidade espacial do algoritmo, enquanto a resposta à segunda é a complexidade temporal. Usamos uma notação especial chamada Big O Notation para expressar respostas a ambas as perguntas. Isso será abordado a seguir na folha de dicas do Big O.
Pré-requisitos
Antes de prosseguir, devo dizer que para aproveitar ao máximo esta folha de dicas do Big O, você precisa entender um pouco de álgebra. Além disso, como darei exemplos de Python, também é útil entender um pouco de Python. Um entendimento profundo é desnecessário, pois você não escreverá nenhum código.
Como realizar a análise Big O
Nesta seção, abordaremos como realizar a análise Big O.
Ao realizar a Análise de Complexidade Big O, é importante lembrar que o desempenho do algoritmo depende de como os dados de entrada são estruturados.
Por exemplo, os algoritmos de classificação são executados mais rapidamente quando os dados da lista já estão classificados na ordem correta. Esse é o melhor cenário para o desempenho do algoritmo. Por outro lado, os mesmos algoritmos de classificação são mais lentos quando os dados são estruturados na ordem inversa. Esse é o pior cenário possível.
Ao realizar a Big O Analysis, consideramos apenas o pior cenário.
Análise de Complexidade Espacial

Vamos começar esta folha de dicas do Big O abordando como realizar análises de complexidade de espaço. Queremos considerar como a memória adicional que um algoritmo usa é dimensionada à medida que a entrada se torna cada vez maior.
Por exemplo, a função abaixo usa recursão para fazer um loop de n a zero. Possui uma complexidade espacial que é diretamente proporcional a n. Isso ocorre porque à medida que n cresce, também aumenta o número de chamadas de função na pilha de chamadas. Portanto, tem uma complexidade espacial de O(n).
def loop_recursively(n):
if n == -1:
return
else:
print(n)
loop_recursively(n - 1)
No entanto, uma implementação melhor seria assim:
def loop_normally(n):
count = n
while count >= 0:
print(count)
count =- 1
No algoritmo acima, criamos apenas uma variável adicional e a usamos para fazer um loop. Se n crescesse cada vez mais, ainda usaríamos apenas uma variável adicional. Portanto, o algoritmo possui complexidade de espaço constante, denotada pelo símbolo “O(1)”.
Ao comparar a complexidade espacial dos dois algoritmos acima, concluímos que o loop while era mais eficiente que a recursão. Esse é o objetivo principal do Big O Analysis: analisar como os algoritmos mudam à medida que os executamos com entradas maiores.
Análise de Complexidade de Tempo

Ao realizar a análise de complexidade de tempo, não nos preocupamos com o crescimento do tempo total gasto pelo algoritmo. Em vez disso, estamos preocupados com o crescimento das etapas computacionais realizadas. Isso ocorre porque o tempo real depende de muitos fatores sistêmicos e aleatórios que são difíceis de contabilizar. Portanto, rastreamos apenas o crescimento das etapas computacionais e assumimos que cada etapa é igual.
Para ajudar a demonstrar a análise de complexidade de tempo, considere o seguinte exemplo:
Suponha que temos uma lista de usuários onde cada usuário possui um ID e um nome. Nossa tarefa é implementar uma função que retorne o nome do usuário quando receber um ID. Veja como podemos fazer isso:
users = [
{'id': 0, 'name': 'Alice'},
{'id': 1, 'name': 'Bob'},
{'id': 2, 'name': 'Charlie'},
]
def get_username(id, users):
for user in users:
if user['id'] == id:
return user['name']
return 'User not found'
get_username(1, users)
Dada uma lista de usuários, nosso algoritmo percorre todo o array do usuário para encontrar o usuário com o ID correto. Quando temos 3 usuários, o algoritmo realiza 3 iterações. Quando temos 10, ele executa 10.
Portanto, o número de etapas é linear e diretamente proporcional ao número de usuários. Portanto, nosso algoritmo tem complexidade de tempo linear. No entanto, podemos melhorar nosso algoritmo.
Suponha que em vez de armazenar usuários em uma lista, nós os armazenamos em um dicionário. Então, nosso algoritmo para procurar um usuário ficaria assim:
users = {
'0': 'Alice',
'1': 'Bob',
'2': 'Charlie'
}
def get_username(id, users):
if id in users:
return users[id]
else:
return 'User not found'
get_username(1, users)
Com este novo algoritmo, suponha que tivéssemos 3 usuários em nosso dicionário; realizaríamos várias etapas para obter o nome de usuário. E suponha que tivéssemos mais usuários, digamos dez. Realizaríamos o mesmo número de etapas de antes para obter o usuário. À medida que o número de usuários aumenta, o número de etapas para obter um nome de usuário permanece constante.
Portanto, este novo algoritmo possui complexidade constante. Não importa quantos usuários temos; o número de etapas computacionais realizadas é o mesmo.
O que é notação Big O?
Na seção anterior, discutimos como calcular a complexidade de espaço e tempo Big O para diferentes algoritmos. Usamos palavras como linear e constante para descrever complexidades. Outra maneira de descrever complexidades é usar a notação Big O.
Big O Notation é uma forma de representar as complexidades de espaço ou tempo de um algoritmo. A notação é relativamente simples; é um O seguido de parênteses. Dentro dos parênteses, escrevemos uma função de n para representar a complexidade particular.
A complexidade linear é representada por n, então a escreveríamos como O(n) (leia-se como “O de n”). A complexidade constante é representada por 1, então a escreveríamos como O(1).
Existem mais complexidades, que discutiremos na próxima seção. Mas geralmente, para escrever a complexidade de um algoritmo, siga os seguintes passos:
O resultado disso se torna o termo que usamos entre parênteses.
Exemplo:
Considere a seguinte função Python:
users = [
'Alice',
'Bob',
'Charlie'
]
def print_users(users):
number_of_users = len(users)
print("Total number of users:", number_of_users)
for i in number_of_users:
print(i, end=': ')
print(user)
Agora, calcularemos a complexidade Big O Time do algoritmo.
Primeiro escrevemos uma função matemática de nf(n) para representar o número de etapas computacionais que o algoritmo executa. Lembre-se de que n representa o tamanho da entrada.
A partir do nosso código, a função realiza duas etapas: uma para calcular o número de usuários e outra para imprimir o número de usuários. Então, para cada usuário, realiza duas etapas: uma para imprimir o índice e outra para imprimir o usuário.
Portanto, a função que melhor representa o número de passos computacionais realizados pode ser escrita como f(n) = 2 + 2n. Onde n é o número de usuários.
Passando para a etapa dois, escolhemos o termo mais dominante. 2n é um termo linear e 2 é um termo constante. Linear é mais dominante que constante, então escolhemos 2n, o termo linear.
Então, nossa função agora é f(n) = 2n.
A última etapa é eliminar coeficientes. Em nossa função, temos 2 como coeficiente. Então nós eliminamos isso. E a função se torna f(n) = n. Esse é o termo que usamos entre parênteses.
Portanto, a complexidade de tempo do nosso algoritmo é O(n) ou complexidade linear.
Diferentes complexidades do Big O
A última seção de nossa folha de dicas do Big O mostrará diferentes complexidades e os gráficos associados.
#1. Constante

Complexidade constante significa que o algoritmo usa uma quantidade constante de espaço (ao realizar análise de complexidade de espaço) ou um número constante de etapas (ao realizar análise de complexidade de tempo). Esta é a complexidade ideal, pois o algoritmo não precisa de espaço ou tempo adicional à medida que a entrada aumenta. É, portanto, muito escalonável.
A complexidade constante é representada como O(1). No entanto, nem sempre é possível escrever algoritmos que rodem em complexidade constante.
#2. Logarítmico
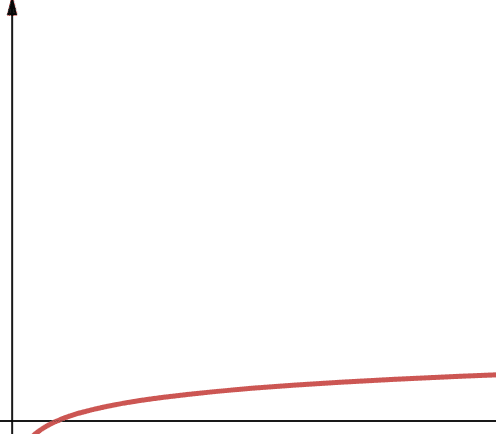
A complexidade logarítmica é representada pelo termo O(log n). É importante notar que se a base do logaritmo não for especificada em Ciência da Computação, assumimos que é 2.
Portanto, log n é log2n. Sabe-se que as funções logarítmicas crescem rapidamente no início e depois diminuem. Isso significa que eles escalam e trabalham de forma eficiente com números cada vez maiores de n.
#3. Linear
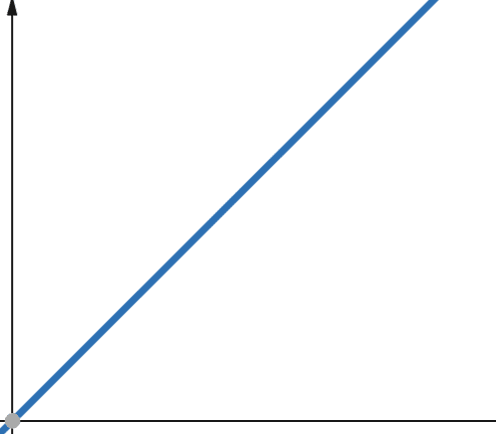
Para funções lineares, se a variável independente for dimensionada por um fator de p. A variável dependente é dimensionada pelo mesmo fator de p.
Portanto, uma função com complexidade linear cresce no mesmo fator que o tamanho da entrada. Se o tamanho da entrada dobrar, o mesmo acontecerá com o número de etapas computacionais ou o uso de memória. A complexidade linear é representada pelo símbolo O(n).
#4. Linearítmico
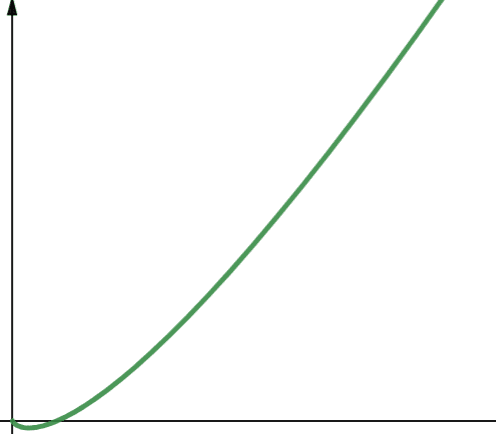
O (n * log n) representa funções linearítmicas. Funções lineares são uma função linear multiplicada pela função logarítmica. Portanto, uma função linearítmica produz resultados ligeiramente maiores do que funções lineares quando log n é maior que 1. Isso ocorre porque n aumenta quando multiplicado por um número maior que 1.
Log n é maior que 1 para todos os valores de n maiores que 2 (lembre-se, o log n é log2n). Portanto, para qualquer valor de n maior que 2, as funções lineares são menos escalonáveis que as funções lineares. Dos quais n é maior que 2 na maioria dos casos. Portanto, as funções linearítmicas são geralmente menos escalonáveis que as funções logarítmicas.
#5. Quadrático
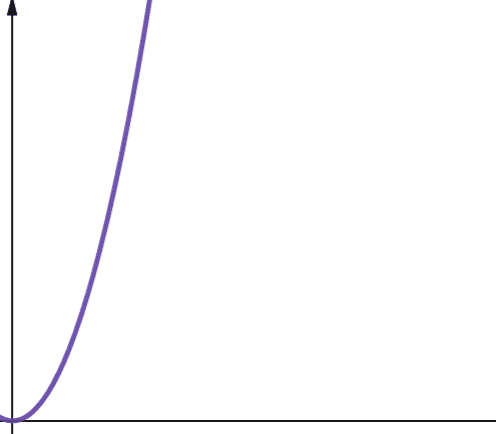
A complexidade quadrática é representada por O(n2). Isso significa que se o tamanho da sua entrada aumentar 10 vezes, o número de etapas executadas ou o espaço usado aumentará 102 vezes ou 100! Isso não é muito escalável e, como você pode ver no gráfico, a complexidade aumenta muito rapidamente.
A complexidade quadrática surge em algoritmos onde você faz um loop n vezes e, para cada iteração, você faz um loop n vezes novamente, por exemplo, no Bubble Sort. Embora geralmente não seja o ideal, às vezes você não tem outra opção a não ser implementar algoritmos com complexidade quadrática.
#6. Polinomial
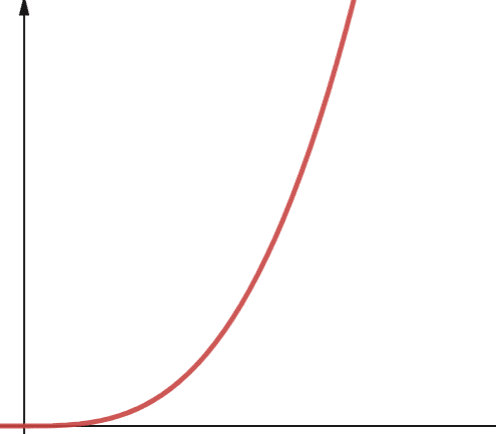
Um algoritmo com complexidade polinomial é representado por O(np), onde p é algum número inteiro constante. P representa a ordem em que n é aumentado.
Essa complexidade surge quando você tem um número específico de loops aninhados. A diferença entre complexidade polinomial e complexidade quadrática é que quadrática é da ordem de 2, enquanto polinômio tem qualquer número maior que 2.
#7. Exponencial
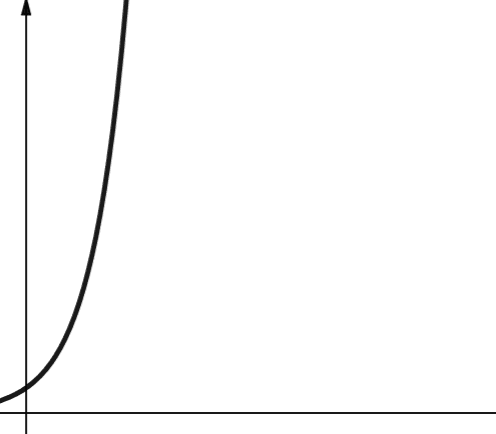
A complexidade exponencial cresce ainda mais rápido que a complexidade polinomial. Em matemática, o valor padrão para a função exponencial é a constante e (número de Euler). Na Ciência da Computação, entretanto, o valor padrão para a função exponencial é 2.
A complexidade exponencial é representada pelo símbolo O(2n). Quando n é 0, 2n é 1. Mas quando n é aumentado para 5, 2n aumenta para 32. Um aumento em n em um dobrará o número anterior. Portanto, funções exponenciais não são muito escaláveis.
#8. Fatorial
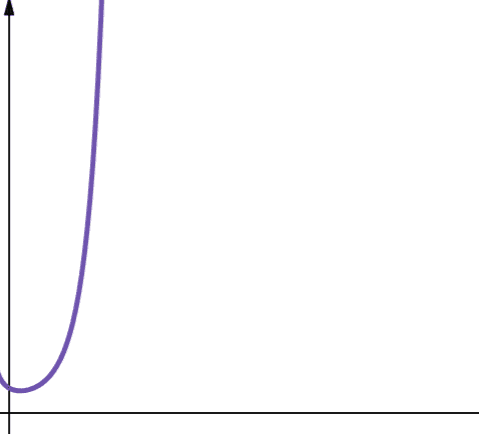
A complexidade fatorial é representada pelo símbolo O(n!). Esta função também cresce muito rapidamente e, portanto, não é escalável.
Conclusão
Este artigo abordou a Análise Big O e como calculá-la. Também discutimos as diferentes complexidades e discutimos sua escalabilidade.
A seguir, você pode querer praticar a análise Big O no algoritmo de classificação Python.