

A extração de dados é o processo de coleta de dados específicos de páginas da web. Os usuários podem extrair texto, imagens, vídeos, análises, produtos etc. Você pode extrair dados para realizar pesquisas de mercado, análises de sentimentos, análises competitivas e dados agregados.
Se você estiver lidando com uma pequena quantidade de dados, poderá extraí-los manualmente copiando e colando as informações específicas de páginas da Web em uma planilha ou formato de documento de sua preferência. Por exemplo, se, como cliente, você estiver procurando avaliações on-line para ajudá-lo a tomar uma decisão de compra, poderá descartar os dados manualmente.
Por outro lado, se você estiver lidando com grandes conjuntos de dados, precisará de uma técnica automatizada de extração de dados. Você pode criar uma solução interna de extração de dados ou usar a API Proxy ou a API Scraping para essas tarefas.
No entanto, essas técnicas podem ser menos eficazes, pois alguns dos sites que você segmenta podem estar protegidos por captchas. Você também pode ter que gerenciar bots e proxies. Essas tarefas podem tomar muito do seu tempo e limitar a natureza do conteúdo que você pode extrair.
últimas postagens
Navegador de raspagem: a solução
Você pode superar todos esses desafios através do Scraping Browser da Bright Data. Este navegador tudo-em-um ajuda a coletar dados de sites que são difíceis de rastrear. É um navegador que usa uma interface gráfica do usuário (GUI) e é controlado por Puppeteer ou Playwright API, tornando-o indetectável por bots.
O Scraping Browser possui recursos de desbloqueio integrados que lidam automaticamente com todos os bloqueios em seu nome. O navegador é aberto nos servidores da Bright Data, o que significa que você não precisa de uma infraestrutura interna cara para descartar dados para seus projetos de grande escala.
Recursos do navegador Bright Data Scraping
- Desbloqueios automáticos de sites: você não precisa ficar atualizando seu navegador, pois esse navegador se ajusta automaticamente para lidar com a resolução de CAPTCHA, novos bloqueios, impressões digitais e novas tentativas. Scraping Browser imita um usuário real.
- Uma grande rede de proxies: você pode segmentar qualquer país que desejar, pois o Scraping Browser tem mais de 72 milhões de IPs. Você pode segmentar cidades ou até operadoras e se beneficiar da melhor tecnologia da categoria.
- Escalável: você pode abrir milhares de sessões simultaneamente, pois este navegador usa a infraestrutura Bright Data para lidar com todas as solicitações.
- Compatível com Puppeteer e Playwright: este navegador permite que você faça chamadas de API e obtenha qualquer número de sessões de navegador usando Puppeteer (Python) ou Playwright (Node.js).
- Economiza tempo e recursos: em vez de configurar proxies, o Scraping Browser cuida de tudo em segundo plano. Você também não precisa configurar uma infraestrutura interna, pois essa ferramenta cuida de tudo em segundo plano.
Como configurar o navegador de raspagem
- Vá até o site da Bright Data e clique no Scraping Browser na guia “Scraping Solutions”.
- Crie a sua conta aqui. Você verá duas opções; “Iniciar avaliação gratuita” e “Iniciar gratuitamente com o Google”. Vamos escolher “Iniciar avaliação gratuita” por enquanto e passar para a próxima etapa. Você pode criar a conta manualmente ou usar sua conta do Google.
- Quando sua conta for criada, o painel apresentará várias opções. Selecione “Infraestrutura de proxies e raspagem”.
- Na nova janela que se abre, selecione Scraping Browser e clique em “Começar”.
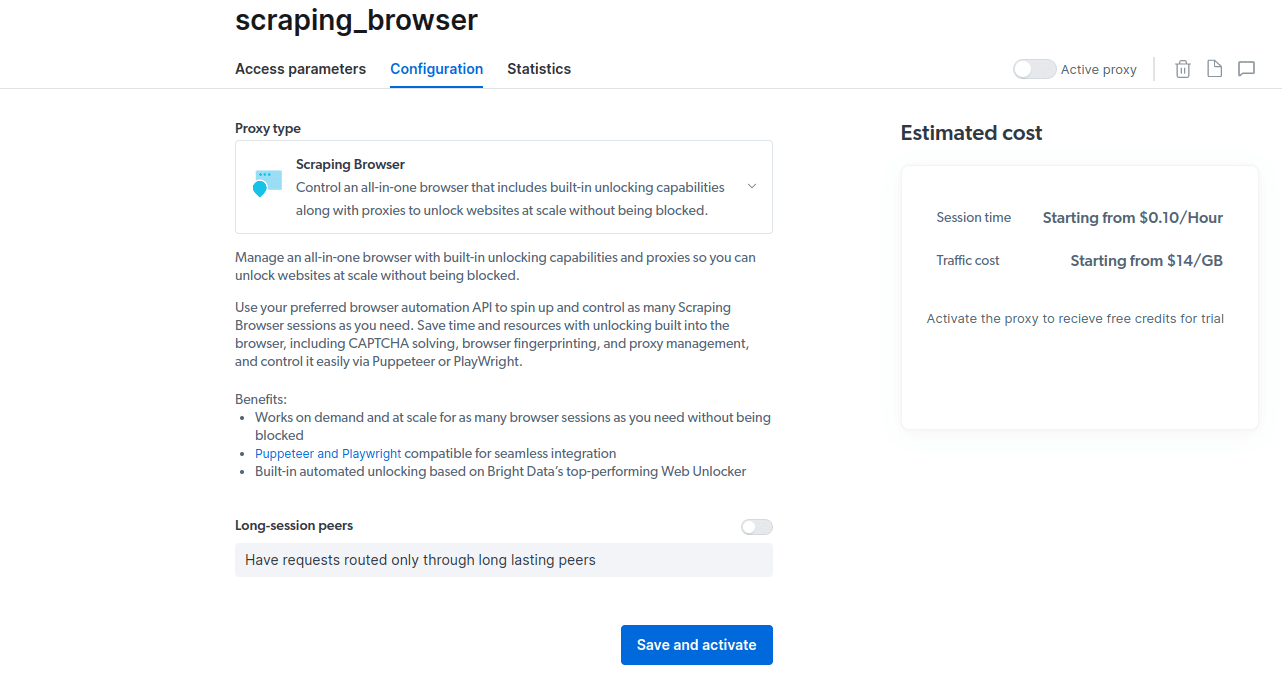
- Salve e ative suas configurações.
- Ative seu teste gratuito. A primeira opção oferece um crédito de $ 5 que você pode usar para o uso do proxy. Clique na primeira opção para experimentar este produto. No entanto, se você for um usuário pesado, pode clicar na segunda opção que oferece $ 50 de graça se você carregar sua conta com $ 50 ou mais.
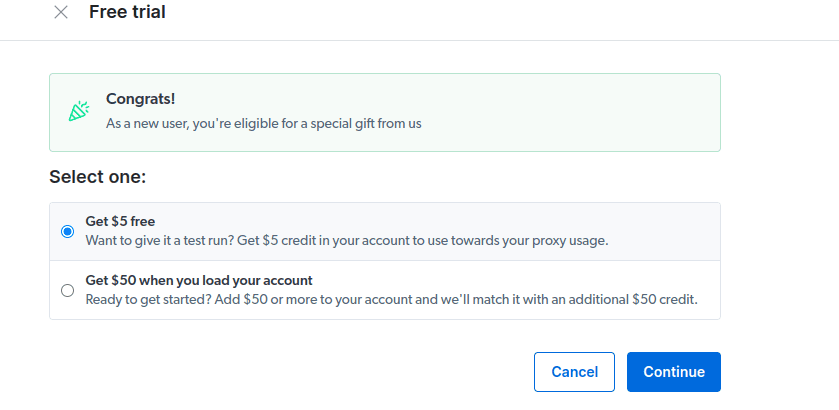
- Insira suas informações de faturamento. Não se preocupe, pois a plataforma não cobrará nada. As informações de cobrança apenas verificam se você é um novo usuário e não está procurando brindes criando várias contas.
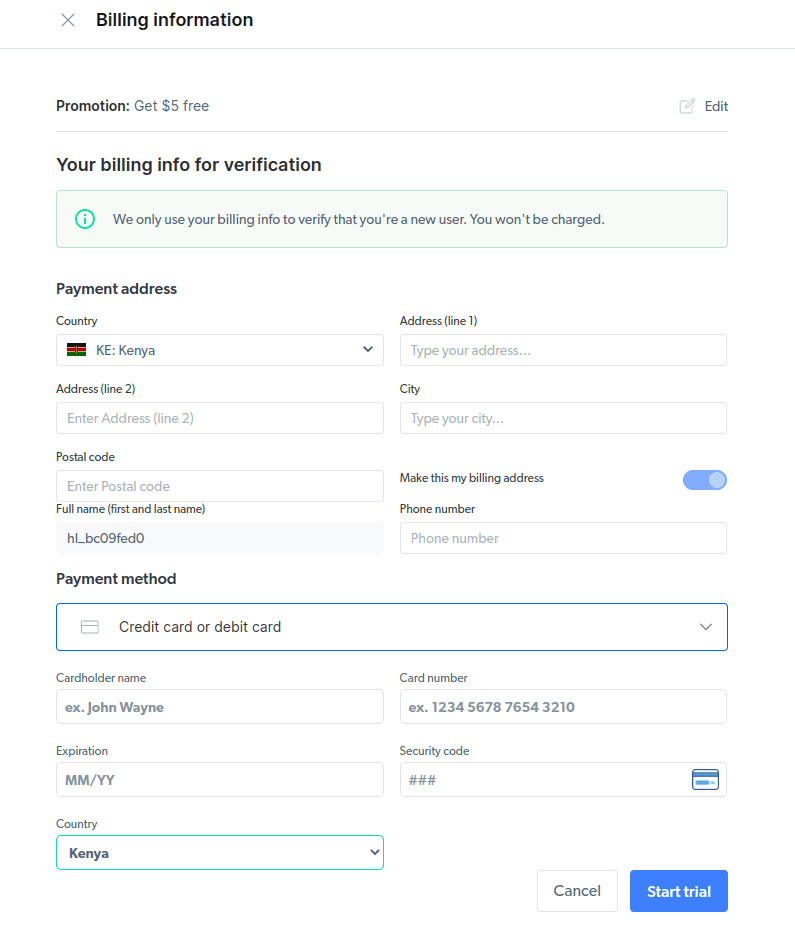
- Crie um novo proxy. Depois de salvar seus detalhes de cobrança, você pode criar um novo proxy. Clique no ícone “adicionar” e selecione Scraping Browser como seu “tipo de proxy”. Clique em “Adicionar proxy” e vá para a próxima etapa.
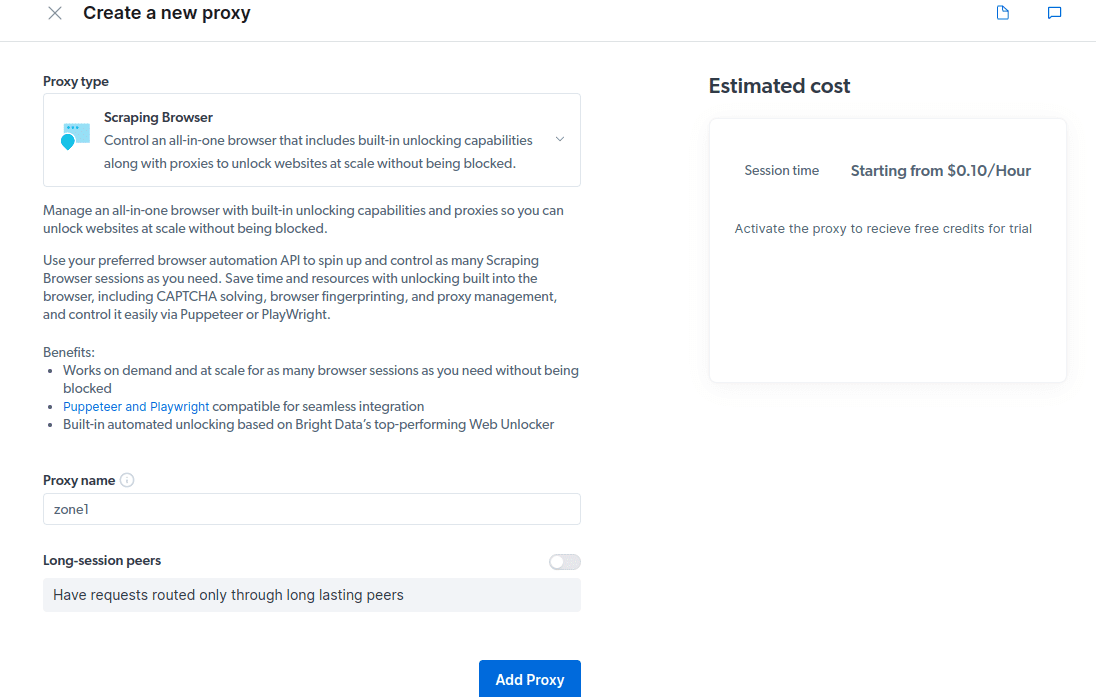
- Crie uma nova “zona”. Aparecerá um pop perguntando se você deseja criar uma nova Zona; clique em “Sim” e continue.
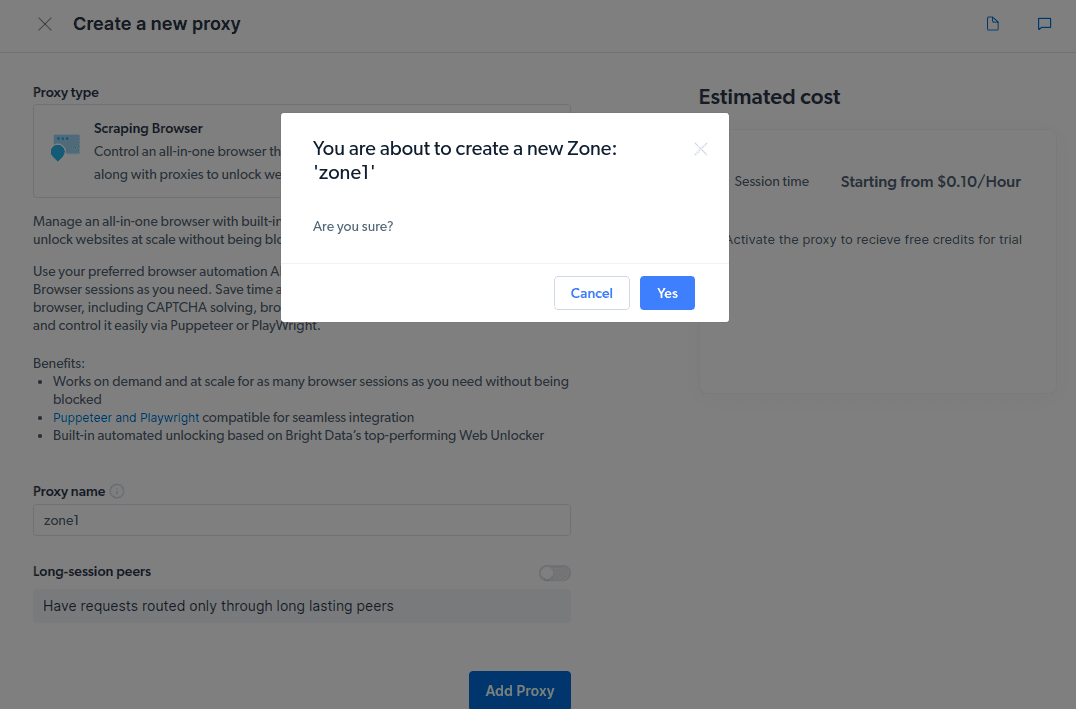
- Clique em “Confira exemplos de código e integração”. Agora você obterá exemplos de integração de proxy que pode usar para descartar dados do site de destino. Você pode usar Node.js ou Python para extrair dados do site de destino.
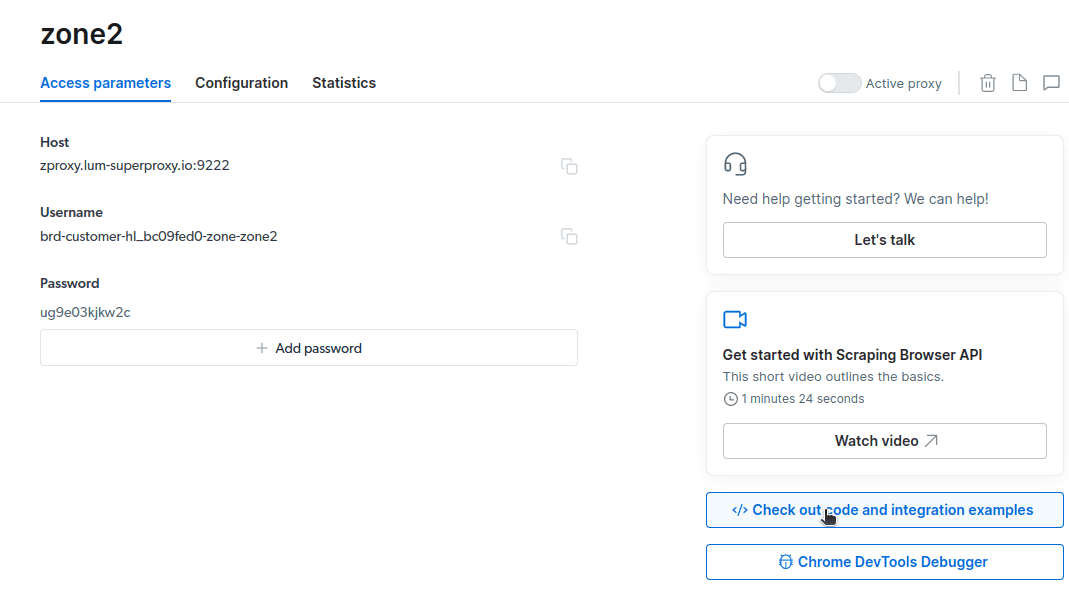
Agora você tem tudo o que precisa para extrair dados de um site. Usaremos nosso site, etechpt.com.com, para demonstrar como o Scraping Browser funciona. Para esta demonstração, usaremos node.js. Você pode acompanhar se tiver o node.js instalado.
Siga esses passos;
const puppeteer = require('puppeteer-core');
// should look like 'brd-customer-<ACCOUNT ID>-zone-<ZONE NAME>:<PASSWORD>'
const auth="USERNAME:PASSWORD";
async function run(){
let browser;
try {
browser = await puppeteer.connect({browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222`});
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2*60*1000);
await page.goto('https://example.com');
const html = await page.evaluate(() => document.documentElement.outerHTML);
console.log(html);
}
catch(e) {
console.error('run failed', e);
}
finally {
await browser?.close();
}
}
if (require.main==module)
run();
Vou alterar meu código na linha 10 para o seguinte;
await page.goto(‘https://etechpt.com.com/authors/‘);
Meu código final agora será;
const puppeteer = require('puppeteer-core');
// should look like 'brd-customer-<ACCOUNT ID>-zone-<ZONE NAME>:<PASSWORD>'
const auth="brd-customer-hl_bc09fed0-zone-zone2:ug9e03kjkw2c";
async function run(){
let browser;
try {
browser = await puppeteer.connect({browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222`});
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2*60*1000);
await page.goto('https://etechpt.com.com/authors/');
const html = await page.evaluate(() => document.documentElement.outerHTML);
console.log(html);
}
catch(e) {
console.error('run failed', e);
}
finally {
await browser?.close();
}
}
if (require.main==module)
run();
node script.js
Você terá algo assim em seu terminal
Como exportar os dados
Você pode usar várias abordagens para exportar os dados, dependendo de como pretende usá-los. Hoje, podemos exportar os dados para um arquivo html alterando o script para criar um novo arquivo chamado data.html em vez de imprimi-lo no console.
Você pode alterar o conteúdo do seu código da seguinte maneira;
const puppeteer = require('puppeteer-core');
const fs = require('fs');
// should look like 'brd-customer-<ACCOUNT ID>-zone-<ZONE NAME>:<PASSWORD>'
const auth="brd-customer-hl_bc09fed0-zone-zone2:ug9e03kjkw2c";
async function run() {
let browser;
try {
browser = await puppeteer.connect({ browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222` });
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2 * 60 * 1000);
await page.goto('https://etechpt.com.com/authors/');
const html = await page.evaluate(() => document.documentElement.outerHTML);
// Write HTML content to a file
fs.writeFileSync('data.html', html);
console.log('Data export complete.');
} catch (e) {
console.error('run failed', e);
} finally {
await browser?.close();
}
}
if (require.main == module) {
run();
}
Agora você pode executar o código usando este comando;
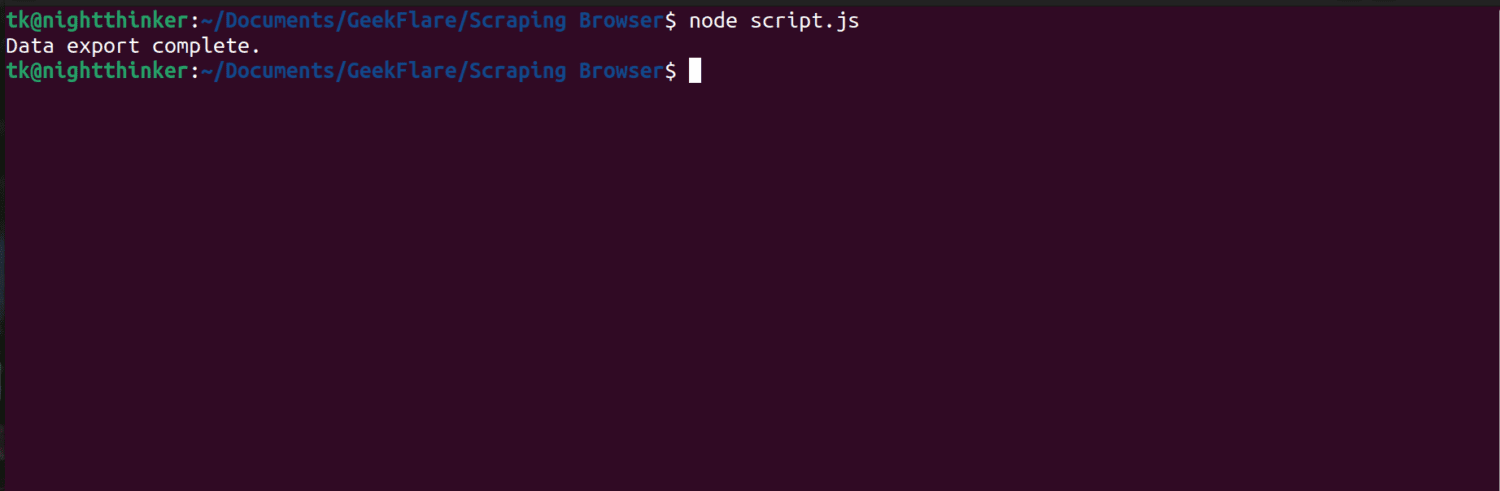
node script.js
Como você pode ver na captura de tela a seguir, o terminal exibe uma mensagem dizendo “exportação de dados concluída”.
Se verificarmos a pasta do nosso projeto, agora podemos ver um arquivo chamado data.html com milhares de linhas de código.
Acabei de arranhar a superfície de como extrair dados usando o navegador Scraping. Posso até restringir e descartar apenas os nomes dos autores e suas descrições usando esta ferramenta.
Se você quiser usar o Scraping Browser, identifique os conjuntos de dados que deseja extrair e modifique o código de acordo. Você pode extrair texto, imagens, vídeos, metadados e links, dependendo do site que você está segmentando e da estrutura do arquivo HTML.
perguntas frequentes
A extração de dados e a raspagem da web são legais?
A raspagem da Web é um tópico controverso, com um grupo dizendo que é imoral, enquanto outros acham que está tudo bem. A legalidade da raspagem da web dependerá da natureza do conteúdo que está sendo copiado e da política da página da web de destino.
Geralmente, a coleta de dados com informações pessoais, como endereços e detalhes financeiros, é considerada ilegal. Antes de descartar os dados, verifique se o site que você está segmentando possui alguma diretriz. Sempre certifique-se de não descartar os dados que não estão disponíveis publicamente.
O Scraping Browser é uma ferramenta gratuita?
Não. O Scraping Browser é um serviço pago. Se você se inscrever para uma avaliação gratuita, a ferramenta oferece um crédito de $ 5. Os pacotes pagos começam em US$ 15/GB + US$ 0,1/h. Você também pode optar pela opção Pay As You Go que começa em $ 20/GB + $ 0,1/h.
Qual é a diferença entre os navegadores Scraping e os navegadores sem cabeça?
O Scraping Browser é um navegador headful, o que significa que possui uma interface gráfica do usuário (GUI). Por outro lado, os navegadores sem cabeça não possuem uma interface gráfica. Navegadores sem cabeça, como o Selenium, são usados para automatizar a raspagem da Web, mas às vezes são limitados, pois precisam lidar com CAPTCHAs e detecção de bots.
Empacotando
Como você pode ver, o Scraping Browser simplifica a extração de dados de páginas da web. O Scraping Browser é simples de usar em comparação com ferramentas como o Selenium. Mesmo não desenvolvedores podem usar este navegador com uma interface de usuário incrível e boa documentação. A ferramenta possui recursos de desbloqueio indisponíveis em outras ferramentas de sucateamento, tornando-a eficaz para todos que desejam automatizar esses processos.
Você também pode explorar como impedir que os plug-ins do ChatGPT raspem o conteúdo do seu site.