

Deepfakes de vídeo significam que você não pode confiar em tudo que vê. Agora, deepfakes de áudio podem significar que você não pode mais confiar em seus ouvidos. Era mesmo o presidente declarando guerra ao Canadá? É realmente o seu pai ao telefone pedindo a senha do e-mail dele?
Acrescente outra preocupação existencial à lista de como nossa própria arrogância pode inevitavelmente nos destruir. Durante a era Reagan, os únicos riscos tecnológicos reais eram a ameaça de guerra nuclear, química e biológica.
Nos anos seguintes, tivemos a oportunidade de ficar obcecados com a gosma cinzenta da nanotecnologia e as pandemias globais. Agora, temos deepfakes – pessoas perdendo o controle sobre sua aparência ou voz.
últimas postagens
O que é um Deepfake de áudio?
A maioria de nós já viu um vídeo deepfake, no qual algoritmos de aprendizado profundo são usados para substituir uma pessoa pela semelhança de outra. Os melhores são irritantemente realistas, e agora é a vez do áudio. Um deepfake de áudio é quando uma voz “clonada” potencialmente indistinguível da voz de uma pessoa real é usada para produzir áudio sintético.
“É como o Photoshop para voz”, disse Zohaib Ahmed, CEO da Assemelha-se a IA, sobre a tecnologia de clonagem de voz de sua empresa.
No entanto, trabalhos ruins do Photoshop são facilmente desmascarados. Uma empresa de segurança com quem conversamos disse que as pessoas geralmente apenas adivinham se um deepfake de áudio é real ou falso com cerca de 57% de precisão – não melhor do que um cara ou coroa.
Além disso, como muitas gravações de voz são de chamadas telefônicas de baixa qualidade (ou gravadas em locais barulhentos), as deepfakes de áudio podem se tornar ainda mais indistinguíveis. Quanto pior a qualidade do som, mais difícil é captar esses sinais reveladores de que uma voz não é real.
Mas por que alguém precisaria de um Photoshop para vozes, afinal?
O caso atraente para áudio sintético
Na verdade, há uma enorme demanda por áudio sintético. Segundo Ahmed, “o ROI é muito imediato”.
Isso é particularmente verdadeiro quando se trata de jogos. No passado, a fala era o único componente em um jogo que era impossível de criar sob demanda. Mesmo em títulos interativos com cenas com qualidade de cinema renderizadas em tempo real, as interações verbais com personagens que não jogam são sempre essencialmente estáticas.
Agora, porém, a tecnologia alcançou. Os estúdios têm o potencial de clonar a voz de um ator e usar mecanismos de conversão de texto em fala para que os personagens possam dizer qualquer coisa em tempo real.
Há também usos mais tradicionais em publicidade, tecnologia e suporte ao cliente. Aqui, uma voz que soa autenticamente humana e responde pessoal e contextualmente sem a participação humana é o que importa.
As empresas de clonagem de voz também estão entusiasmadas com as aplicações médicas. É claro que a substituição de voz não é novidade na medicina – Stephen Hawking usou uma voz sintetizada robótica depois de perder a sua própria em 1985. No entanto, a clonagem de voz moderna promete algo ainda melhor.
Em 2008, empresa de voz sintética, CereProc, deu ao falecido crítico de cinema, Roger Ebert, sua voz de volta depois que o câncer a tirou. A CereProc havia publicado uma página na web que permitia que as pessoas digitassem mensagens que seriam faladas na voz do ex-presidente George Bush.
“Ebert viu isso e pensou, ‘bem, se eles conseguiram copiar a voz de Bush, deveriam ser capazes de copiar a minha’”, disse Matthew Aylett, diretor científico da CereProc. Ebert então pediu à empresa que criasse uma voz substituta, o que eles fizeram processando uma grande biblioteca de gravações de voz.
“Foi uma das primeiras vezes que alguém fez isso e foi um verdadeiro sucesso”, disse Aylett.
Nos últimos anos, várias empresas (incluindo a CereProc) trabalharam com o Associação ELA sobre Renovação do Projeto para fornecer vozes sintéticas para aqueles que sofrem de ELA.

Como funciona o áudio sintético
A clonagem de voz está tendo um momento agora, e uma série de empresas estão desenvolvendo ferramentas. Assemelha-se a IA e Descrição tem demos online que qualquer um pode experimentar gratuitamente. Basta gravar as frases que aparecem na tela e, em poucos minutos, é criado um modelo da sua voz.
Você pode agradecer à IA – especificamente, algoritmos de aprendizado profundo – por ser capaz de combinar a fala gravada com o texto para entender os fonemas componentes que compõem sua voz. Em seguida, ele usa os blocos de construção linguísticos resultantes para aproximar palavras que não ouviu você falar.
A tecnologia básica já existe há algum tempo, mas, como Aylett apontou, exigia alguma ajuda.
“Copiar voz era um pouco como fazer pastelaria”, disse ele. “Era meio difícil de fazer e havia várias maneiras de ajustá-lo manualmente para fazê-lo funcionar.”
Os desenvolvedores precisavam de enormes quantidades de dados de voz gravados para obter resultados aceitáveis. Então, alguns anos atrás, as comportas se abriram. A pesquisa no campo da visão computacional provou ser crítica. Os cientistas desenvolveram redes adversariais generativas (GANs), que podem, pela primeira vez, extrapolar e fazer previsões com base em dados existentes.
“Em vez de um computador ver uma foto de um cavalo e dizer ‘isto é um cavalo’, meu modelo agora pode transformar um cavalo em uma zebra”, disse Aylett. “Então, a explosão na síntese de fala agora é graças ao trabalho acadêmico de visão computacional.”
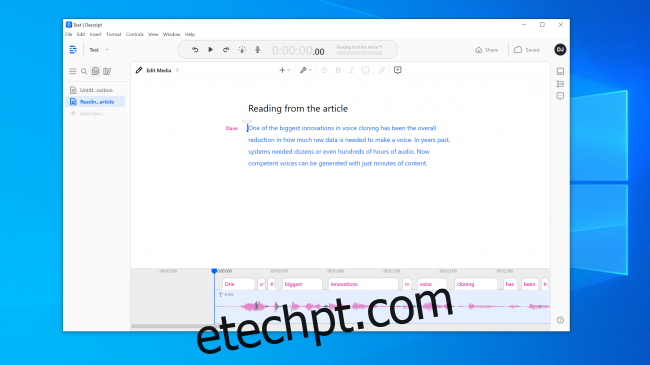
Uma das maiores inovações na clonagem de voz foi a redução geral da quantidade de dados brutos necessários para criar uma voz. No passado, os sistemas precisavam de dezenas ou mesmo centenas de horas de áudio. Agora, no entanto, vozes competentes podem ser geradas a partir de apenas alguns minutos de conteúdo.
O medo existencial de não confiar em nada
Essa tecnologia, juntamente com energia nuclear, nanotecnologia, impressão 3D e CRISPR, é simultaneamente emocionante e aterrorizante. Afinal, já houve casos nas notícias de pessoas sendo enganadas por clones de voz. Em 2019, uma empresa no Reino Unido alegou que era enganado por um deepfake de áudio telefonema para transferir dinheiro para criminosos.
Você também não precisa ir muito longe para encontrar falsificações de áudio surpreendentemente convincentes. Canal do Youtube Síntese Vocal apresenta pessoas conhecidas dizendo coisas que nunca disseram, como George W. Bush lendo “In Da Club” de 50 Cent. Está no local.
Em outros lugares do YouTube, você pode ouvir um bando de ex-presidentes, incluindo Obama, Clinton e Reagan, fazendo rap NWA. A música e os sons de fundo ajudam a disfarçar algumas das óbvias falhas robóticas, mas mesmo nesse estado imperfeito, o potencial é óbvio.
Experimentamos as ferramentas em Assemelha-se a IA e Descrição e clone de voz criado. O Descript usa um mecanismo de clonagem de voz que foi originalmente chamado Lyrebird e foi particularmente impressionante. Ficamos chocados com a qualidade. Ouvir sua própria voz dizer coisas que você sabe que nunca disse é enervante.
Definitivamente, há uma qualidade robótica no discurso, mas em uma audição casual, a maioria das pessoas não teria motivos para pensar que era falso.
Tínhamos esperanças ainda maiores para o Reemble AI. Ele oferece as ferramentas para criar uma conversa com várias vozes e variar a expressividade, emoção e ritmo do diálogo. No entanto, não achamos que o modelo de voz capturasse as qualidades essenciais da voz que usamos. Na verdade, era improvável que enganasse alguém.
Um representante da Reemble AI nos disse que “a maioria das pessoas fica impressionada com os resultados se fizerem isso corretamente”. Construímos um modelo de voz duas vezes com resultados semelhantes. Então, evidentemente, nem sempre é fácil fazer um clone de voz que você pode usar para realizar um assalto digital.
Mesmo assim, o fundador da Lyrebird (que agora faz parte da Descript), Kundan Kumar, sente que já ultrapassamos esse limite.
“Para uma pequena porcentagem de casos, já existe”, disse Kumar. “Se eu usar áudio sintético para mudar algumas palavras em um discurso, já é tão bom que você terá dificuldade em saber o que mudou.”
Também podemos supor que essa tecnologia só melhorará com o tempo. Os sistemas precisarão de menos áudio para criar um modelo, e processadores mais rápidos poderão construir o modelo em tempo real. A IA mais inteligente aprenderá a adicionar cadência humana mais convincente e ênfase na fala sem ter um exemplo para trabalhar.
O que significa que podemos estar nos aproximando da ampla disponibilidade de clonagem de voz sem esforço.
A Ética da Caixa de Pandora
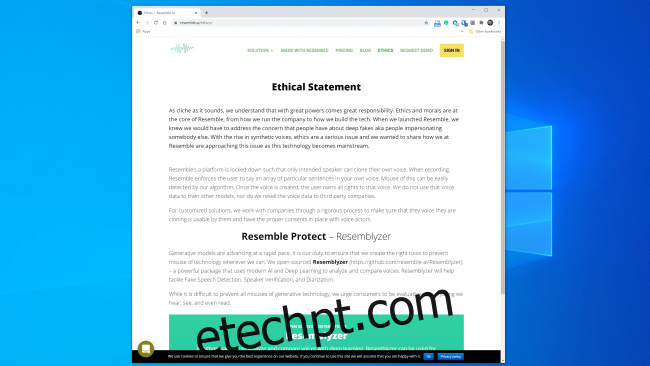
A maioria das empresas que trabalham nessa área parece preparada para lidar com a tecnologia de maneira segura e responsável. A IA semelhante, por exemplo, tem uma seção inteira de “Ética” em seu site, e o trecho a seguir é encorajador:
“Trabalhamos com as empresas por meio de um processo rigoroso para garantir que a voz que estão clonando seja utilizável por elas e tenhamos os consentimentos adequados com os dubladores.”
Da mesma forma, Kumar disse que a Lyrebird estava preocupada com o uso indevido desde o início. É por isso que agora, como parte do Descript, só permite que as pessoas clonem sua própria voz. Na verdade, tanto o Resemble quanto o Descript exigem que as pessoas gravem suas amostras ao vivo para evitar a clonagem de voz não consensual.
É animador que os principais players comerciais tenham imposto algumas diretrizes éticas. No entanto, é importante lembrar que essas empresas não são guardiãs dessa tecnologia. Existem várias ferramentas de código aberto já disponíveis, para as quais não há regras. De acordo com Henry Ajder, chefe de inteligência de ameaças da Deeptrace, você também não precisa de conhecimento avançado de codificação para usá-lo de forma inadequada.
“Muito do progresso no espaço veio por meio de trabalho colaborativo em lugares como o GitHub, usando implementações de código aberto de trabalhos acadêmicos publicados anteriormente”, disse Ajder. “Ele pode ser usado por qualquer pessoa que tenha proficiência moderada em codificação.”
Profissionais de segurança já viram tudo isso antes
Os criminosos tentaram roubar dinheiro por telefone muito antes da clonagem de voz ser possível, e os especialistas em segurança sempre estiveram de plantão para detectar e evitar isso. Compania de segurança Pindrop tenta impedir a fraude bancária verificando se um chamador é quem ele afirma ser a partir do áudio. Somente em 2019, a Pindrop afirma ter analisado 1,2 bilhão de interações de voz e evitado cerca de US$ 470 milhões em tentativas de fraude.
Antes da clonagem de voz, os fraudadores tentaram várias outras técnicas. O mais simples era apenas ligar de outro lugar com informações pessoais sobre a marca.
“Nossa assinatura acústica nos permite determinar que uma chamada está realmente vindo de um telefone Skype na Nigéria por causa das características do som”, disse o CEO da Pindrop, Vijay Balasubramaniyan. “Então, podemos comparar isso sabendo que o cliente usa um telefone da AT&T em Atlanta.”
Alguns criminosos também fizeram carreira usando sons de fundo para enganar os representantes bancários.
“Há um fraudador que chamamos de Chicken Man que sempre tinha galos em segundo plano”, disse Balasubramaniyan. “E há uma senhora que usou um bebê chorando no fundo para essencialmente convencer os agentes do call center de que ‘ei, estou passando por um momento difícil’ para obter simpatia.”
E depois há os criminosos do sexo masculino que perseguem as contas bancárias das mulheres.
“Eles usam a tecnologia para aumentar a frequência de sua voz, para soar mais feminino”, explicou Balasubramaniyan. Eles podem ser bem-sucedidos, mas “ocasionalmente, o software falha e eles soam como Alvin e os Esquilos”.
Claro, a clonagem de voz é apenas o mais recente desenvolvimento nesta guerra cada vez maior. As empresas de segurança já pegaram fraudadores usando áudio sintético em pelo menos um ataque de caça submarina.
“Com o alvo certo, o pagamento pode ser enorme”, disse Balasubramaniyan. “Então, faz sentido dedicar tempo para criar uma voz sintetizada do indivíduo certo.”
Alguém pode dizer se uma voz é falsa?

Quando se trata de reconhecer se uma voz foi falsificada, há boas e más notícias. O ruim é que os clones de voz estão melhorando a cada dia. Os sistemas de aprendizado profundo estão ficando mais inteligentes e produzindo vozes mais autênticas que exigem menos áudio para serem criadas.
Como você pode ver neste clipe de Presidente Obama dizendo a MC Ren para depor, também já chegamos ao ponto em que um modelo de voz de alta fidelidade e cuidadosamente construído pode soar bastante convincente ao ouvido humano.
Quanto mais longo for um clipe de som, maior a probabilidade de você perceber que há algo errado. Para clipes mais curtos, no entanto, você pode não perceber que é sintético, especialmente se você não tiver motivos para questionar sua legitimidade.
Quanto mais clara a qualidade do som, mais fácil é notar sinais de deepfake de áudio. Se alguém estiver falando diretamente em um microfone com qualidade de estúdio, você poderá ouvir atentamente. Mas uma gravação de telefonema de baixa qualidade ou uma conversa capturada em um dispositivo portátil em uma garagem barulhenta será muito mais difícil de avaliar.
A boa notícia é que, mesmo que os humanos tenham problemas para separar o real do falso, os computadores não têm as mesmas limitações. Felizmente, as ferramentas de verificação de voz já existem. Pindrop tem um que coloca sistemas de aprendizado profundo uns contra os outros. Ele usa ambos para descobrir se uma amostra de áudio é a pessoa que deveria ser. No entanto, também examina se um ser humano pode fazer todos os sons da amostra.
Dependendo da qualidade do áudio, cada segundo de fala contém entre 8.000 e 50.000 amostras de dados que podem ser analisadas.
“As coisas que normalmente procuramos são restrições à fala devido à evolução humana”, explicou Balasubramaniyan.
Por exemplo, dois sons vocais têm uma separação mínima possível um do outro. Isso ocorre porque não é fisicamente possível dizê-las mais rápido devido à velocidade com que os músculos da boca e das cordas vocais podem se reconfigurar.
“Quando olhamos para áudio sintetizado”, disse Balasubramaniyan, “às vezes vemos coisas e dizemos: ‘isso nunca poderia ter sido gerado por um humano porque a única pessoa que poderia ter gerado isso precisa ter um pescoço de dois metros e meio de comprimento. ”
Há também uma classe de som chamada “fricativas”. Eles são formados quando o ar passa por uma estreita constrição em sua garganta quando você pronuncia letras como f, s, v e z. As fricativas são especialmente difíceis para os sistemas de aprendizado profundo dominarem porque o software tem dificuldade em diferenciá-las do ruído.
Então, pelo menos por enquanto, o software de clonagem de voz tropeça no fato de que os humanos são sacos de carne que fluem ar através de orifícios em seus