O *pipeline* de agregação representa a metodologia mais indicada para a execução de consultas complexas no MongoDB. Se você ainda emprega o MapReduce neste sistema, a transição para o *pipeline* de agregação se mostra como a opção mais vantajosa, em termos de eficiência computacional.
O que é agregação no MongoDB e qual seu funcionamento?
O *pipeline* de agregação se constitui em um processo multifásico, concebido para a execução de consultas avançadas no MongoDB. Ele realiza o processamento de dados por meio de diversas etapas, conhecidas como *pipeline*. Os resultados gerados em cada fase servem como base para as operações nas fases subsequentes.
Por exemplo, é possível direcionar o resultado de uma operação de correspondência para uma etapa de ordenação, e assim sucessivamente, até a obtenção do resultado almejado.
Cada fase dentro do *pipeline* de agregação emprega um operador específico do MongoDB, gerando um ou mais documentos transformados. Dependendo da consulta, uma mesma fase pode ser repetida múltiplas vezes no *pipeline*. Como exemplo, pode ser necessário utilizar os operadores `$count` ou `$sort` diversas vezes.
As Fases do *Pipeline* de Agregação
O *pipeline* de agregação direciona os dados através de uma série de etapas dentro de uma única consulta. Existem diversas fases, cujos detalhes podem ser consultados na Documentação do MongoDB.
A seguir, detalharemos algumas das fases mais frequentemente utilizadas.
A Fase `$match`
Esta fase tem como objetivo definir critérios de filtragem específicos antes da execução das demais fases de agregação. Ela permite a seleção dos dados relevantes que serão incluídos no *pipeline* de agregação.
A Fase `$group`
A fase de agrupamento organiza os dados em diferentes conjuntos com base em critérios definidos, utilizando pares chave-valor. Cada conjunto representa uma chave no documento de saída.
Como ilustração, observe os seguintes dados de exemplo referentes a vendas:
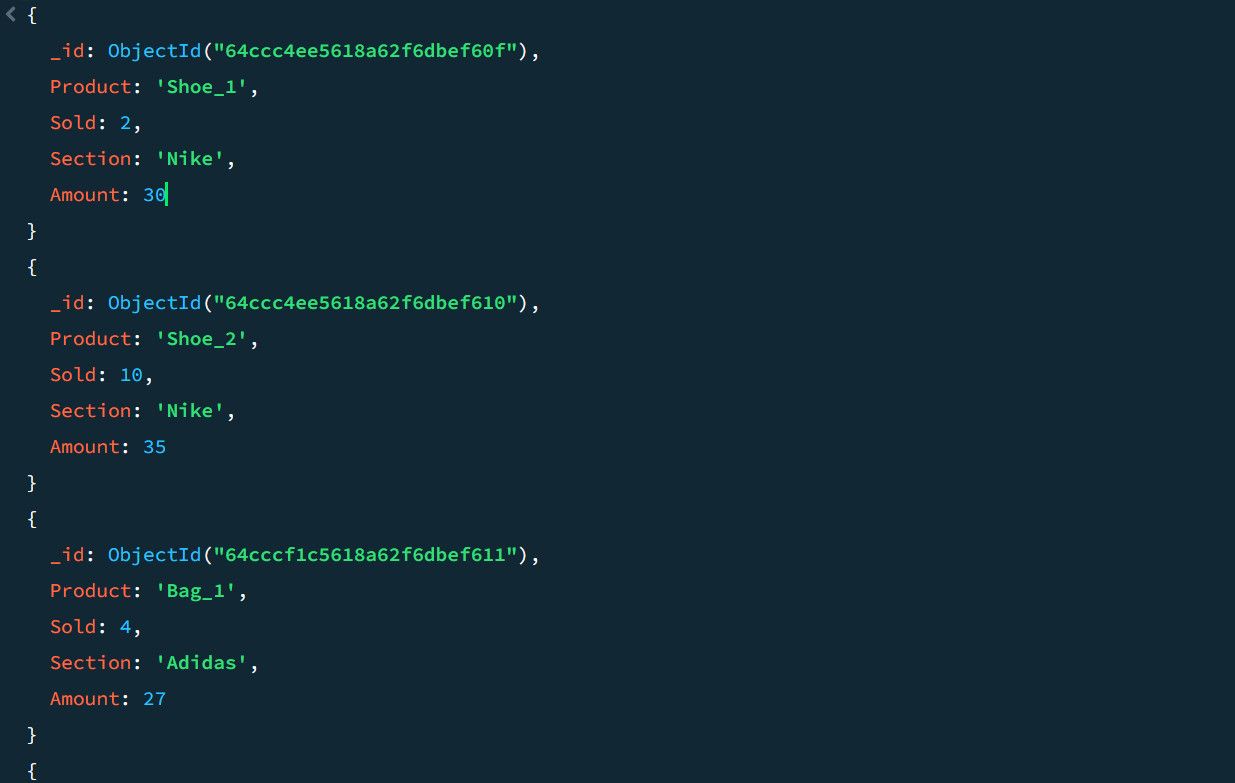
Através do *pipeline* de agregação, é possível calcular o número total de vendas e os valores mais altos de venda para cada seção de produto:
{
$group: {
_id: $Section,
total_sales_count: {$sum : $Sold},
top_sales: {$max: $Amount},
}
}
O par `_id: $Section` agrupa o documento de saída com base nas seções. Ao especificar os campos `top_sales_count` e `top_sales`, o MongoDB cria novas chaves com base na operação definida pelo agregador, podendo ser `$sum`, `$min`, `$max` ou `$avg`.
A Fase `$skip`
A fase `$skip` permite a omissão de um número específico de documentos na saída. Geralmente, ela é utilizada após a fase de agrupamento. Por exemplo, caso a expectativa seja obter dois documentos de saída, mas um deles seja ignorado, a agregação retornará apenas o segundo documento.
Para incluir a fase de salto, insira a operação `$skip` no *pipeline* de agregação:
...,
{
$skip: 1
},
A Fase `$sort`
A fase de ordenação possibilita a organização dos dados em ordem crescente ou decrescente. Como exemplo, é possível ordenar os dados do exemplo anterior em ordem decrescente, para identificar a seção com o maior volume de vendas.
Adicione o operador `$sort` à consulta anterior:
...,
{
$sort: {top_sales: -1}
},
A Fase `$limit`
A operação `$limit` auxilia na redução do número de documentos de saída exibidos pelo *pipeline* de agregação. Por exemplo, o operador `$limit` pode ser utilizado para obter a seção com o maior volume de vendas, resultado da etapa anterior:
...,
{
$sort: {top_sales: -1}
},
{"$limit": 1}
O código acima retorna somente o primeiro documento, que representa a seção com maior volume de vendas, por se encontrar no topo da saída ordenada.
A Fase `$project`
A fase `$project` permite a formatação do documento de saída de acordo com a necessidade. Com o uso do operador `$project`, é possível definir quais campos serão incluídos na saída e personalizar seus nomes.
Como exemplo, uma saída sem a fase `$project` apresenta a seguinte estrutura:
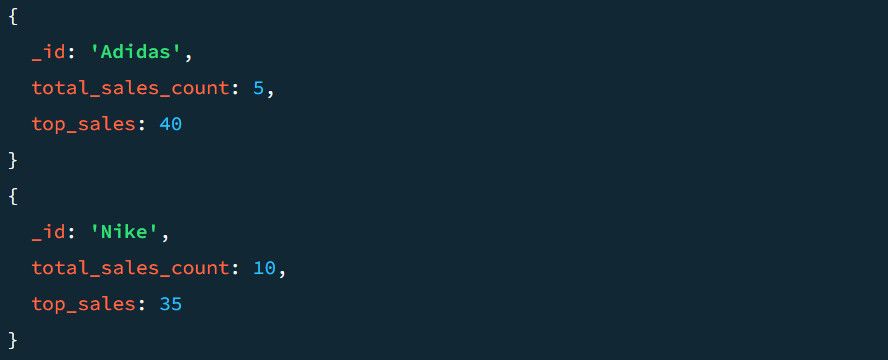
Vejamos como a fase `$project` modifica essa estrutura. Para adicionar `$project` ao *pipeline*:
...,
{
"$project": {
"_id": 0,
"Section": "$_id",
"TotalSold": "$total_sales_count",
"TopSale": "$top_sales",
}
}
Considerando que os dados foram agrupados anteriormente com base nas seções de produto, o código acima inclui cada seção de produto no documento de saída. Ele também assegura que a contagem de vendas agregadas e os valores mais altos de venda apareçam na saída como `TotalSold` e `TopSale`, respectivamente.
O resultado final se apresenta de forma mais organizada em comparação com a estrutura anterior:

A Fase `$unwind`
A fase `$unwind` realiza a divisão de um array presente em um documento em documentos individuais. Considere os seguintes dados de pedidos, como exemplo:
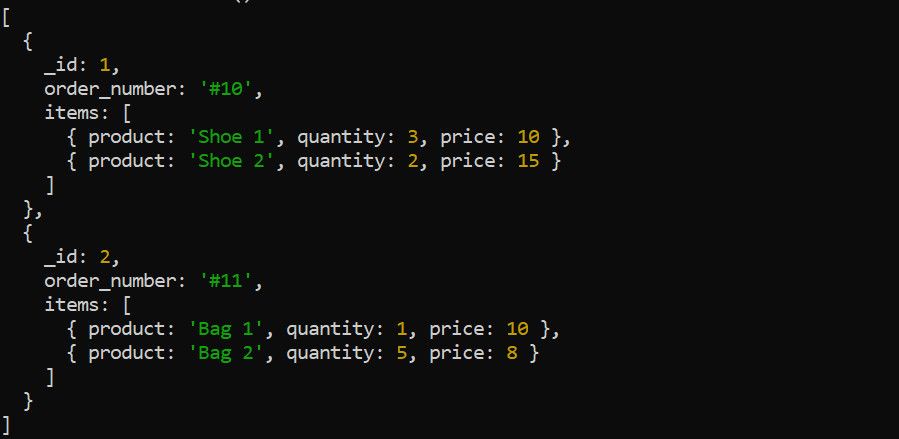
Utilize a fase `$unwind` para desconstruir o *array* de itens antes da aplicação das demais fases de agregação. Por exemplo, a expansão do *array* de itens se justifica caso o objetivo seja calcular a receita total por produto:
db.Orders.aggregate([
{
"$unwind": "$items"
},
{
"$group": {
"_id": "$items.product",
"total_revenue": { "$sum": { "$multiply": ["$items.quantity", "$items.price"] } }
}
},
{
"$sort": { "total_revenue": -1 }
},
{
"$project": {
"_id": 0,
"Product": "$_id",
"TotalRevenue": "$total_revenue",
}
}
])
A seguir, apresenta-se o resultado da consulta de agregação acima:

Como Criar um *Pipeline* de Agregação no MongoDB
Apesar da variedade de operações disponíveis no *pipeline* de agregação, as fases apresentadas anteriormente fornecem uma compreensão sobre como aplicá-las no *pipeline*, incluindo a consulta básica de cada uma.
Com base nos dados de vendas apresentados anteriormente, vamos reunir algumas das fases discutidas para uma visão mais ampla do *pipeline* de agregação:
db.sales.aggregate([
{
"$match": {
"Sold": { "$gte": 5 }
}
},
{
"$group": {
"_id": "$Section",
"total_sales_count": { "$sum": "$Sold" },
"top_sales": { "$max": "$Amount" },
}
},
{
"$sort": { "top_sales": -1 }
},
{"$skip": 0},
{
"$project": {
"_id": 0,
"Section": "$_id",
"TotalSold": "$total_sales_count",
"TopSale": "$top_sales",
}
}
])
O resultado final apresenta uma estrutura similar a resultados previamente apresentados:
*Pipeline* de Agregação vs. MapReduce
Até a sua descontinuação no MongoDB 5.0, o MapReduce era a forma padrão de agregação de dados no MongoDB. Apesar do MapReduce possuir aplicações mais amplas além do MongoDB, ele se demonstra menos eficiente do que o *pipeline* de agregação, exigindo *scripts* de terceiros para a escrita de funções de *map* e *reduce* separadamente.
O *pipeline* de agregação, por outro lado, é uma funcionalidade específica do MongoDB, proporcionando uma forma mais organizada e eficiente para a execução de consultas complexas. Além da simplicidade e escalabilidade, as fases do *pipeline* tornam a saída mais personalizável.
Existem diversas outras diferenças entre o *pipeline* de agregação e o MapReduce, que serão observadas durante a transição do MapReduce para o *pipeline* de agregação.
Otimizando Consultas de *Big Data* no MongoDB
Para a execução de cálculos detalhados em dados complexos no MongoDB, as consultas devem ser tão eficientes quanto possível. O *pipeline* de agregação se mostra como a solução ideal para consultas avançadas. Em vez de manipular os dados em operações separadas, o que frequentemente leva à redução do desempenho, a agregação permite o agrupamento de todas as operações em um único *pipeline*, com sua execução em uma única vez.
Embora o *pipeline* de agregação seja mais eficiente do que o MapReduce, é possível otimizar a agregação, através da indexação dos dados. Essa ação limita a quantidade de dados que o MongoDB precisa analisar em cada fase de agregação.