No universo do Linux, o awk se destaca como uma ferramenta de linha de comando formidável para manipulação de texto, funcionando também como uma linguagem de script robusta. Este artigo oferece uma introdução a algumas de suas funcionalidades mais notáveis.
A Origem do Nome awk
O nome do comando awk é uma homenagem aos seus criadores originais, cujas iniciais foram usadas para batizá-lo: Alfred Aho, Peter Weinberger e Brian Kernighan. Esses três renomados profissionais pertenciam ao panteão Unix do AT&T Bell Laboratories. Ao longo dos anos, com a contribuição de muitos outros, o awk continuou sua evolução.
Ele se apresenta como uma linguagem de script completa e uma caixa de ferramentas versátil para manipulação de texto diretamente pela linha de comando. Se este artigo despertar seu interesse, você pode explorar todos os detalhes sobre o awk e suas capacidades.
Estrutura: Regras, Padrões e Ações
O awk opera através de programas que consistem em regras formadas por padrões e ações. Uma ação é executada quando um padrão correspondente é encontrado no texto. Os padrões são delimitados por chaves ({}), e a combinação de um padrão e uma ação cria uma regra. Todo o programa awk é encapsulado por aspas simples (‘).
Vamos analisar o programa awk mais elementar. Sem nenhum padrão especificado, ele se aplica a todas as linhas de texto que recebe, executando a ação em cada uma delas. Para exemplificar, vamos empregá-lo na saída do comando who.
Aqui está a saída padrão do comando who:
who
Suponha que desejemos extrair apenas os nomes de usuário, omitindo as demais informações. Podemos direcionar a saída do comando who para o awk e instruir o awk a exibir apenas o primeiro campo.
No awk, um campo é definido como uma sequência de caracteres delimitada por espaços em branco, o início ou o fim de uma linha. Cada campo é identificado por um cifrão ($) seguido de um número. Assim, $1 representa o primeiro campo, que usaremos com a ação ‘print’ para exibir esse campo.
O comando é:
who | awk '{print $1}'
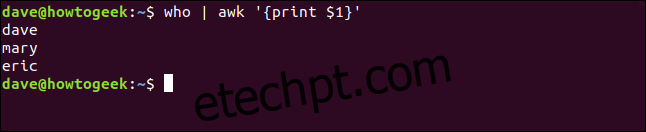
O awk então imprime o primeiro campo, descartando o restante da linha.
Podemos escolher quais campos exibir. Ao inserir uma vírgula como separador, o awk adiciona um espaço entre cada campo exibido.
Para exibir também a hora de login (quarto campo), o comando seria:
who | awk '{print $1,$4}'
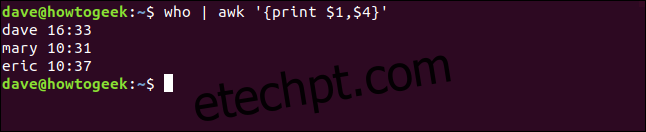
Existem também identificadores de campo especiais, que representam a linha inteira e o último campo:
$0: A linha de texto completa.
$1: O primeiro campo.
$2: O segundo campo.
$7: O sétimo campo.
$45: O quadragésimo quinto campo.
$NF: Significa “número de campos” e representa o último campo.
Vamos analisar um pequeno arquivo de texto que contém uma citação atribuída a Dennis Ritchie:
cat dennis_ritchie.txt

Nosso objetivo é que o awk exiba o primeiro, o segundo e o último campo dessa citação. Apesar de aparecer dividida na janela do terminal, a citação consiste em uma única linha de texto.
O comando para isso seria:
awk '{print $1,$2,$NF}' dennis_ritchie.txt

A palavra “simplicidade”, que aparece na imagem, é o 18º campo da linha, mas não precisamos dessa informação. O importante é que ele é o último campo, e podemos usar $NF para obter seu valor. A pontuação é tratada como parte do último campo.