Usuários Linux de longa data certamente estão familiarizados com o grep, também conhecido como Global Regular Expression Print. Esta ferramenta de processamento textual é crucial para buscas em arquivos e diretórios, e se mostra extremamente valiosa para quem domina o sistema. Entretanto, o uso do grep sem expressões regulares (regex) pode limitar seu potencial.
Mas, afinal, o que são Regex?
Regex, ou expressões regulares, são padrões que expandem as capacidades de pesquisa do grep. Em essência, regex são mecanismos avançados de filtragem de resultados. Com a prática, você será capaz de utilizar regex eficientemente, inclusive em conjunto com outros comandos Linux.
Neste guia, exploraremos como usar o grep e o regex de maneira eficaz.
Pré-requisitos
Para dominar o uso do grep com regex, é necessário ter um bom conhecimento do sistema Linux. Se você é um iniciante, nossos guias introdutórios sobre Linux podem ser úteis.
Você também precisará de um computador com sistema operacional Linux. Qualquer distribuição Linux servirá, e se você utiliza Windows, o WSL2 permite executar o Linux. Temos um guia detalhado sobre o WSL2 que você pode conferir.
O acesso à linha de comando ou terminal é essencial para executar os comandos apresentados neste tutorial sobre grep/regex.
Além disso, é necessário ter pelo menos um arquivo de texto para executar os exemplos. Para este guia, utilizei o ChatGPT para gerar um texto sobre tecnologia, pedindo que repetisse os nomes das tecnologias. O prompt utilizado foi:
“Gere 400 palavras sobre tecnologia. Inclua a maior parte da tecnologia possível. Além disso, repita os nomes das tecnologias no texto.”
Com o texto gerado, copiei e salvei em um arquivo chamado tech.txt, que usaremos nos exemplos a seguir.
Por fim, é indispensável ter uma compreensão básica do comando grep. Para refrescar a memória, você pode consultar nossos 16 exemplos de comandos grep. Também apresentaremos um breve resumo do comando grep para iniciarmos.
Sintaxe e Exemplos do Comando grep
A estrutura do comando grep é simples:
$ grep -opções [regex/padrão] [arquivos]Como você pode observar, o comando espera um padrão e uma lista de arquivos onde a busca deve ocorrer.
Existem diversas opções para o comando grep que alteram sua funcionalidade, incluindo:
-i: Ignora a diferença entre maiúsculas e minúsculas.-r: Realiza uma busca recursiva em diretórios.-w: Busca apenas por palavras completas.-v: Exibe todas as linhas que NÃO correspondem ao padrão.-n: Exibe o número das linhas que correspondem ao padrão.-l: Imprime apenas o nome dos arquivos onde há correspondências.--color: Apresenta a saída com cores.-c: Mostra a contagem de correspondências para o padrão usado.
#1. Busca por Palavra Inteira
Para buscar uma palavra inteira, utilize o argumento -w com o grep. Isso fará com que o comando ignore qualquer sequência de caracteres que contenha o padrão como parte de outra palavra.
$ grep -w ‘tech\|5G’ tech.txtComo você pode observar, o comando procura por “5G” e “tech” no arquivo tech.txt, destacando os resultados em vermelho.
Note que o símbolo | (pipe) precisa ser “escapado” (com a barra invertida \) para que o grep não o interprete como um metacaractere.
#2. Busca Ignorando Maiúsculas e Minúsculas
Para realizar uma busca que não diferencia maiúsculas de minúsculas, use o argumento -i:
$ grep -i ‘tech’ tech.txtEste comando buscará qualquer ocorrência da sequência “tech”, seja como palavra completa ou como parte de uma palavra, sem se importar com a capitalização das letras.
#3. Busca por Linhas Não Correspondentes
Para exibir todas as linhas que não contêm um determinado padrão, use o argumento -v:
$ grep -v ‘tech’ tech.txt
O resultado mostrará todas as linhas que não incluem a palavra “tech”, incluindo também as linhas vazias, que geralmente são espaços entre parágrafos.
#4. Busca Recursiva
Para uma busca recursiva, use o argumento -r com o grep:
$ grep -R ‘error\|warning’ /var/log/*.log
#output
/var/log/bootstrap.log:2023-01-03 21:40:18 URL:http://ftpmaster.internal/ubuntu/pool/main/libg/libgpg-error/libgpg-erro 0_1.43-3_amd64.deb [69684/69684] -> "/build/chroot//var/cache/apt/archives/partial/libgpg-error0_1.43-3_amd64.deb" [1]
/var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 5 package 'dpkg':
/var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 5 package 'dpkg':
/var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 24 package 'dpkg':
/var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 24 package 'dpkg':
/var/log/bootstrap.log:dpkg: warning: ignoring pre-dependency problem!
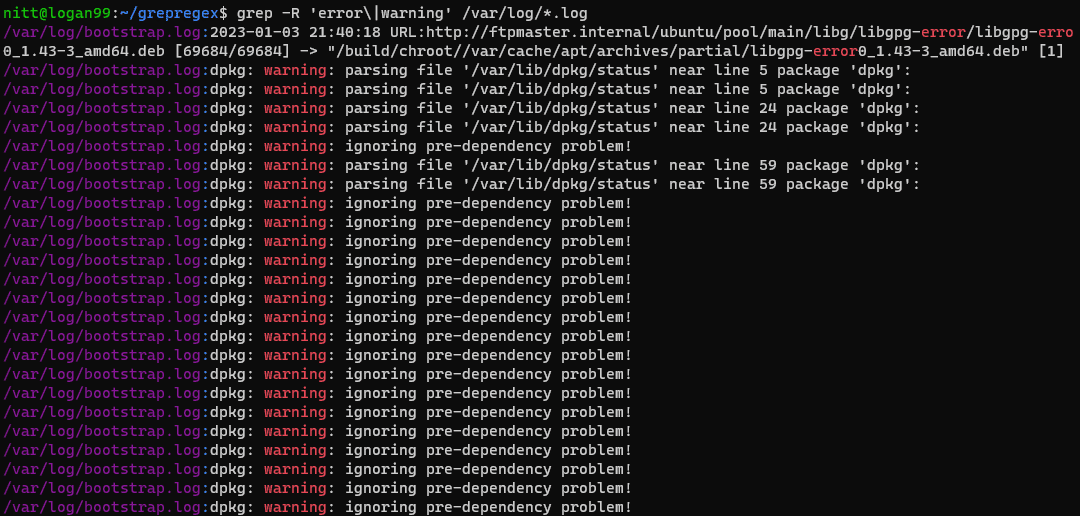
Neste caso, o comando procura recursivamente pelas palavras “error” e “warning” dentro do diretório /var/log. Este é um comando útil para identificar alertas e erros em arquivos de log.
grep e Regex: Definição e Exemplos
Ao trabalhar com regex, você precisa estar ciente de que existem três opções de sintaxe:
- Expressões Regulares Básicas (BRE)
- Expressões Regulares Estendidas (ERE)
- Expressões Regulares Compatíveis com Pearl (PCRE)
Por padrão, o comando grep utiliza o BRE. Portanto, se você precisar usar outros modos regex, deverá especificá-los. O grep também trata metacaracteres de maneira literal, então metacaracteres como ?, +, ) devem ser “escapados” com a barra invertida \.
A sintaxe do grep com regex é a seguinte:
$ grep [regex] [nomes_de_arquivos]A seguir, veremos exemplos práticos de grep e regex em ação.
#1. Correspondências Literais de Palavras
Para obter uma correspondência literal de uma palavra, basta fornecer a palavra como regex. Afinal, uma palavra é um regex em si.
$ grep "technologies" tech.txt
Da mesma forma, você pode usar correspondências literais para encontrar usuários que utilizam um determinado shell. Por exemplo:
$ grep bash /etc/passwd
#output
root:x:0:0:root:/root:/bin/bash
nitt:x:1000:1000:,,,:/home/nitt:/bin/bash
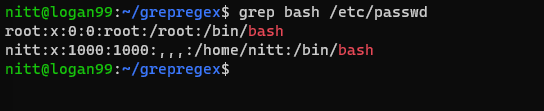
Este comando exibirá os usuários que têm acesso ao shell bash.
#2. Correspondência de Âncora
A correspondência de âncora é uma técnica útil para pesquisas avançadas que utilizam caracteres especiais. No regex, existem diferentes caracteres de âncora que você pode usar para representar posições específicas em um texto, incluindo:
- Símbolo de acento circunflexo
^: Corresponde ao início da string ou linha de entrada, buscando por uma string vazia. - Símbolo de cifrão
$: Corresponde ao final da string ou linha de entrada, buscando também por uma string vazia.
Outros dois caracteres de correspondência de âncora são o limite de palavra \b e o limite de não-palavra \B.
- Limite de palavra
\b: Permite identificar a posição entre uma palavra e um caractere não-palavra. Em outras palavras, ele permite encontrar palavras completas, evitando correspondências parciais. Você também pode usá-lo para substituir palavras ou contar ocorrências em uma string. - Limite de não-palavra
\B: É o oposto do\b, identificando uma posição que não está entre caracteres de duas palavras ou não-palavras.
Vamos analisar alguns exemplos para entender melhor:
$ grep ‘^From’ tech.txt
É importante inserir a palavra ou padrão corretamente, pois o acento circunflexo diferencia maiúsculas e minúsculas. O comando abaixo não retornará nenhum resultado:
$ grep ‘^from’ tech.txtDe maneira semelhante, o símbolo $ pode ser usado para encontrar frases que terminam com determinado padrão, string ou palavra:
$ grep ‘technology.$' tech.txt
Você também pode combinar os símbolos ^ e $, como no exemplo a seguir:
$ grep “^From \| technology.$” tech.txt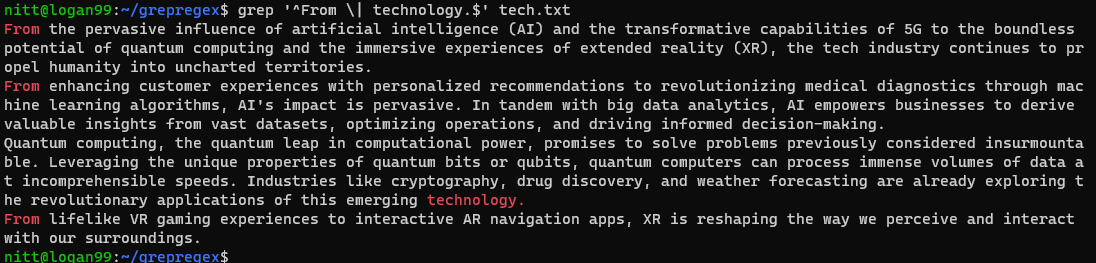
O resultado exibirá as frases que começam com “From” ou terminam com “technology”.
#3. Agrupamento
Para procurar múltiplos padrões de uma vez, use o agrupamento. Ele permite criar pequenos grupos de caracteres ou padrões que são tratados como uma única unidade. Por exemplo, você pode criar um grupo (tech) que inclua as letras 't', 'e', 'c' e 'h'.
Para exemplificar, observe o comando a seguir:
$ grep 'technol\(ogy\)\?' tech.txt
Com o agrupamento, você pode encontrar padrões repetidos, capturar grupos e procurar alternativas.
Busca Alternativa com Agrupamento
Vejamos um exemplo de busca alternativa:
$ grep "\(tech\|technology\)" tech.txt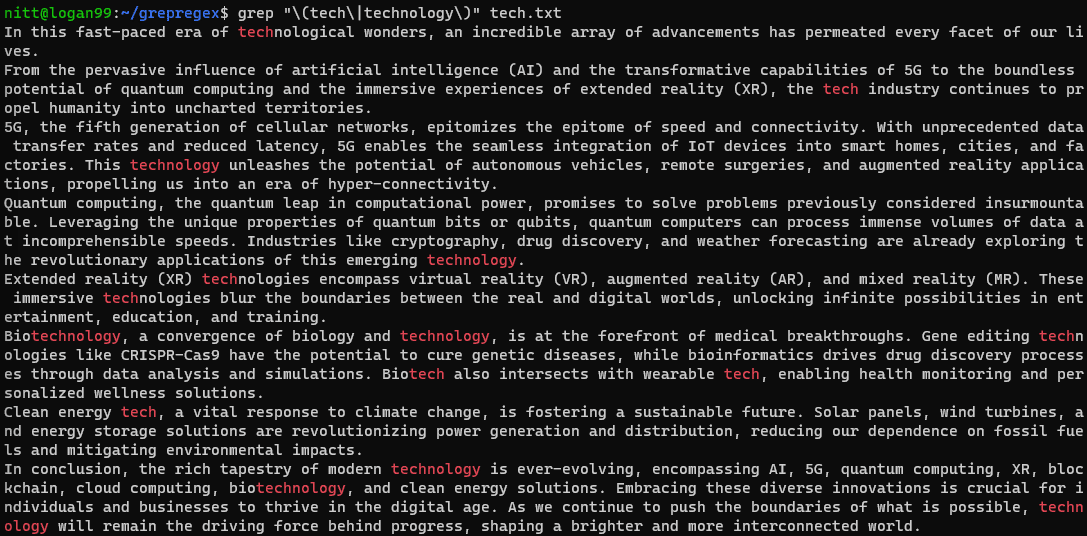
Para buscar várias opções em uma string, você pode usar o símbolo de pipe |, conforme demonstrado abaixo:
$ echo “tech technological technologies technical” | grep "\(tech\|technology\)"
#output
“tech technological technologies technical”

Grupos de Captura, Grupos de Não Captura e Padrões Repetidos
E quanto aos grupos de captura e não captura?
Para capturar grupos, é preciso criar um grupo no regex e direcioná-lo para uma string ou um arquivo:
$ echo 'tech655 tech655nical technologies655 tech655-oriented 655' | grep "\(tech\)\(655\)"
#output
tech655 tech655nical technologies655 tech655-oriented 655

Para grupos sem captura, use ?: dentro dos parênteses.
Por fim, vamos analisar padrões repetidos. Para isso, você precisa ajustar o regex:
$ echo ‘teach tech ttrial tttechno attest’ | grep '\(t\+\)'
#output
‘teach tech ttrial tttechno attest’
Este comando procura por uma ou mais ocorrências do caractere 't'.
#4. Classes de Caracteres
Classes de caracteres facilitam a escrita de expressões regex. Estas classes utilizam colchetes. Algumas classes comuns incluem:
[:digit:]– Dígitos de 0 a 9.[:alpha:]– Caracteres alfabéticos.[:alnum:]– Caracteres alfanuméricos.[:lower:]– Letras minúsculas.[:upper:]– Letras maiúsculas.[:xdigit:]– Dígitos hexadecimais, incluindo 0-9, A-F e a-f.[:blank:]– Caracteres em branco, como tabulação ou espaço.
E várias outras!
Vejamos alguns exemplos práticos:
$ grep [[:digit]] tech.txt
$ grep [[:alpha:]] tech.txt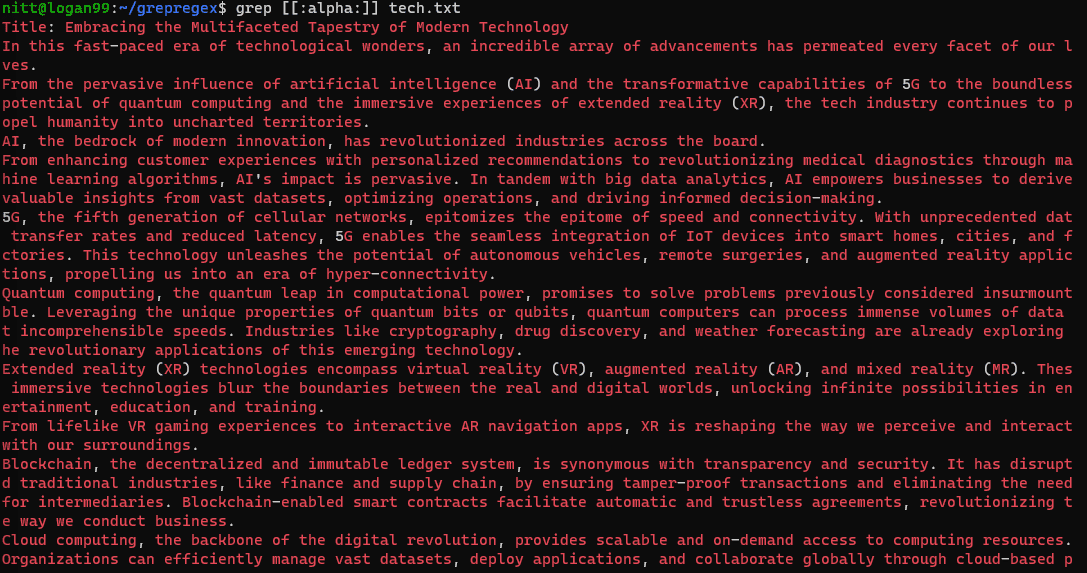
$ grep [[:xdigit:]] tech.txt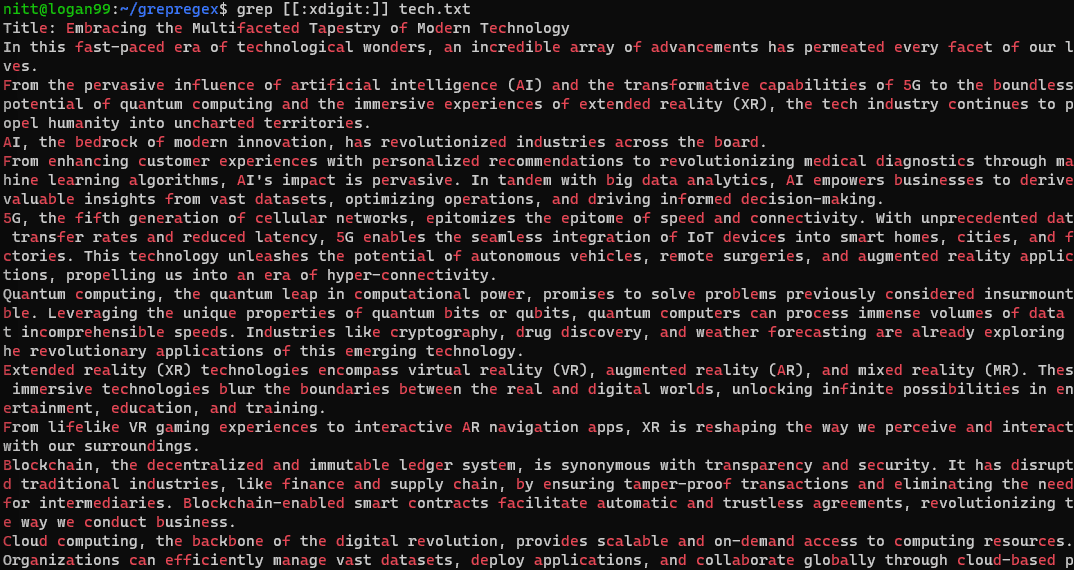
#5. Quantificadores
Quantificadores são metacaracteres cruciais em regex. Eles permitem especificar a quantidade exata de ocorrências de um padrão. Veja alguns exemplos:
*→ Zero ou mais correspondências.+→ Uma ou mais correspondências.?→ Zero ou uma correspondência.{x}→ Exatamente x correspondências.{x,}→ x ou mais correspondências.{x,z}→ De x a z correspondências.{,z}→ Até z correspondências.
$ echo ‘teach tech ttrial tttechno attest’ | grep -E 't+'
#output
‘teach tech ttrial tttechno attest’
Neste exemplo, o comando procura por uma ou mais ocorrências do caractere 't'. O argumento -E indica o uso de regex estendido, que será discutido mais adiante.

#6. Regex Estendido
Para evitar o uso excessivo de caracteres de escape, você pode usar regex estendido. Ele elimina a necessidade de “escapar” certos metacaracteres. Para isso, use o argumento -E.
$ grep -E 'in+ovation' tech.txt
#7. Usando PCRE para Pesquisas Complexas
PCRE (Perl Compatible Regular Expression) permite fazer muito mais do que escrever expressões básicas. Por exemplo, \d corresponde a [0-9].
Um exemplo de uso do PCRE é a pesquisa por endereços de email:
echo "Contact me at [email protected]" | grep -P "\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,}\b"
#output
Contact me at [email protected]

O PCRE garante que o padrão corresponda a um endereço de email válido. Da mesma forma, você pode usar o PCRE para verificar padrões de data:
$ echo "The Sparkain site launched on 2023-07-29" | grep -P "\b\d{4}-\d{2}-\d{2}\b"
#output
The Sparkain site launched on 2023-07-29

Este comando encontra datas no formato AAAA-MM-DD. Você pode modificar o padrão para corresponder a outros formatos.
#8. Alternância
Para encontrar correspondências alternativas, use o símbolo de pipe “escapado” \|.
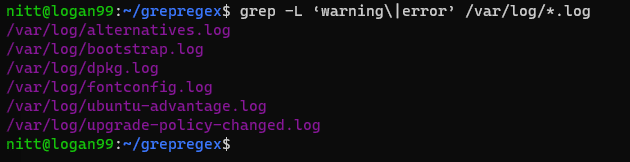
$ grep -L ‘warning\|error’ /var/log/*.log
#output
/var/log/alternatives.log
/var/log/bootstrap.log
/var/log/dpkg.log
/var/log/fontconfig.log
/var/log/ubuntu-advantage.log
/var/log/upgrade-policy-changed.log
O resultado lista os nomes dos arquivos que contêm as palavras “warning” ou “error”.
Considerações Finais
Chegamos ao final deste guia sobre grep e regex. O grep com regex é extremamente útil para refinar suas buscas. Com o uso correto, você economiza tempo e automatiza tarefas, especialmente ao criar scripts ou realizar buscas em texto.
Para expandir seus conhecimentos, veja nossa lista de perguntas e respostas frequentes sobre entrevistas para cargos Linux.