

Python é uma linguagem muito versátil, e os desenvolvedores de Python geralmente precisam trabalhar com uma variedade de arquivos e obter informações armazenadas neles para processamento. Um formato de arquivo popular que você certamente encontrará como desenvolvedor Python é o Portable Document Format, popularmente conhecido como PDF.
Os arquivos PDF podem conter texto, imagens e links. Ao processar dados em um programa Python, você pode precisar extrair os dados armazenados em um documento PDF. Ao contrário de estruturas de dados como tuplas, listas e dicionários, obter informações armazenadas em um documento PDF pode parecer algo difícil de fazer.
Felizmente, existem várias bibliotecas que facilitam o trabalho com PDFs e a extração dos dados armazenados em arquivos PDF. Para aprender sobre essas diferentes bibliotecas, vejamos como você pode extrair textos, links e imagens de arquivos PDF. Para acompanhar, baixe o arquivo PDF a seguir e salve-o no mesmo diretório do arquivo do programa Python.
Para extrair texto de arquivos PDF usando Python, usaremos o PyPDF2 biblioteca. PyPDF2 é uma biblioteca Python gratuita e de código aberto que pode ser usada para mesclar, cortar e transformar páginas de arquivos PDF. Ele pode adicionar dados personalizados, opções de visualização e senhas a arquivos PDF. É importante ressaltar que o PyPDF2 pode recuperar texto de arquivos PDF.
Para usar o PyPDF2 para extrair texto de arquivos PDF, instale-o usando pip, que é um instalador de pacote para Python. pip permite que você instale diferentes pacotes Python em sua máquina:
1. Verifique se você já possui o pip instalado executando:
pip --version
Se você não receber um número de versão, significa que o pip não está instalado.
2. Para instalar o pip, clique em pegue pip para baixar seu script de instalação.
O link abre uma página com o script para instalar o pip conforme mostrado abaixo:
Clique com o botão direito na página e clique em Salvar como para salvar o arquivo. Por padrão, o nome do arquivo é get-pip.py
Abra o terminal e navegue até o diretório com o arquivo get-pip.py que você acabou de baixar e execute o comando:
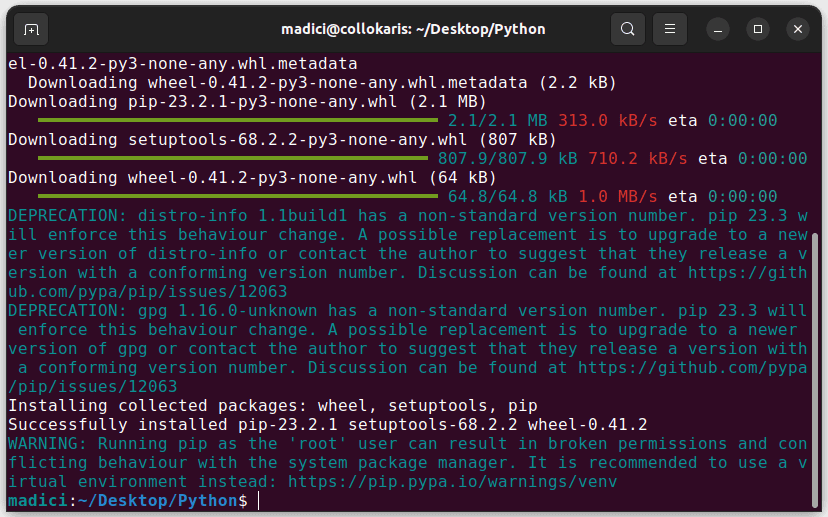
sudo python3 get-pip.py
Isso deve instalar o pip conforme mostrado abaixo:
3. Verifique se o pip foi instalado com sucesso executando:
pip --version
Se for bem-sucedido, você deverá obter um número de versão:

Com o pip instalado, agora podemos começar a trabalhar com PyPDF2.
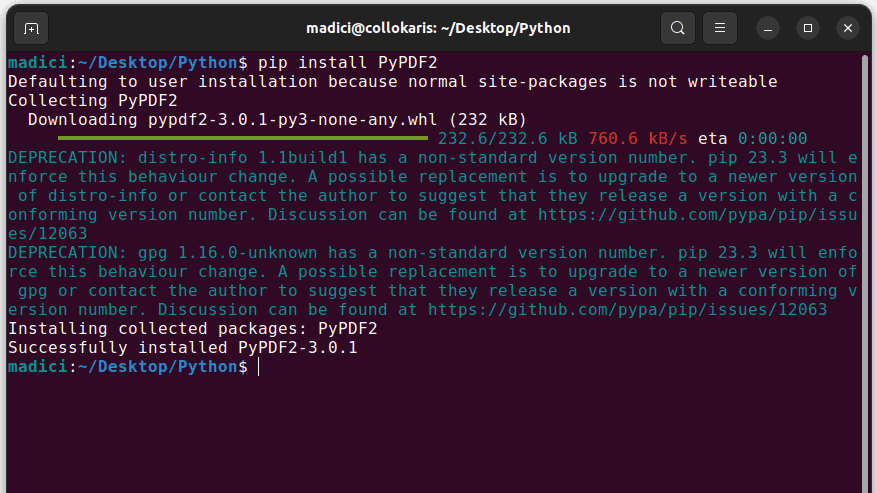
1. Instale o PyPDF2 executando o seguinte comando no terminal:
pip install PyPDF2
2. Crie um arquivo Python e importe o PdfReader do PyPDF2 usando a seguinte linha:
from PyPDF2 import PdfReader
A biblioteca PyPDF2 oferece uma variedade de classes para trabalhar com arquivos PDF. Uma dessas classes é o PdfReader, que pode ser usado para abrir arquivos PDF, ler o conteúdo e extrair texto de arquivos PDF, entre outras coisas.
3. Para começar a trabalhar com um arquivo PDF, primeiro você precisa abrir o arquivo. Para fazer isso, crie uma instância da classe PdfReader e passe o arquivo PDF com o qual deseja trabalhar:
reader = PdfReader('games.pdf')
A linha acima instancia o PdfReader e o prepara para acessar o conteúdo do arquivo PDF especificado. A instância é armazenada em uma variável chamada leitor, que deverá acessar diversos métodos e propriedades disponíveis na classe PdfReader.
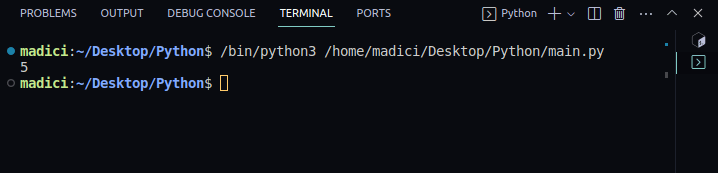
4. Para verificar se está tudo funcionando bem, imprima a quantidade de páginas do PDF que você passou usando o seguinte código:
print(len(reader.pages))
Saída:
5
5. Como nosso arquivo PDF possui 5 páginas, podemos acessar cada página disponível no PDF. No entanto, a contagem começa em 0, assim como a convenção de indexação do Python. Portanto, a primeira página do arquivo PDF será a página número 0. Para recuperar a primeira página do PDF, adicione a seguinte linha ao seu código:
page1 = reader.pages[0]
A linha acima recupera a primeira página do arquivo PDF e a armazena em uma variável chamada página1.
6. Para extrair o texto da primeira página do arquivo PDF, adicione a seguinte linha:
textPage1 = page1.extract_text()
Isso extrai o texto da primeira página do PDF e armazena o conteúdo em uma variável chamada textPage1. Assim, você tem acesso ao texto da primeira página do arquivo PDF através da variável textPage1.
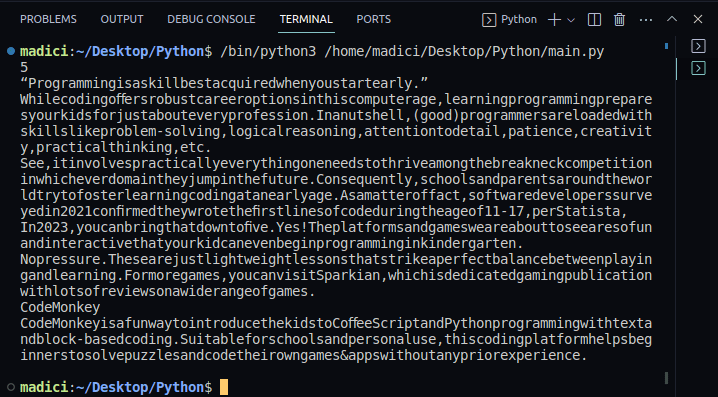
7. Para confirmar se o texto foi extraído com sucesso, você pode imprimir o conteúdo da variável textPage1. Todo o nosso código, que também imprime o texto na primeira página do arquivo PDF, é mostrado abaixo:
# import the PdfReader class from PyPDF2
from PyPDF2 import PdfReader
# create an instance of the PdfReader class
reader = PdfReader('games.pdf')
# get the number of pages available in the pdf file
print(len(reader.pages))
# access the first page in the pdf
page1 = reader.pages[0]
# extract the text in page 1 of the pdf file
textPage1 = page1.extract_text()
# print out the extracted text
print(textPage1)
Saída:
Para extrair links de arquivos PDF, vamos ao PyMuPDF que é uma biblioteca Python para extrair, analisar, converter e manipular os dados armazenados em documentos como PDFs. Para usar PyMuPDF, você deve ter Python 3.8 ou posterior. Para começar:
1. Instale o PyMuPDF executando a seguinte linha no terminal:
pip install PyMuPDF
2. Importe PyMuPDF para seu arquivo Python usando a seguinte instrução:
import fitz
3. Para acessar o PDF do qual deseja extrair links, primeiro você precisa abri-lo. Para abri-lo, digite a seguinte linha:
doc = fitz.open("games.pdf")
4. Após abrir o arquivo PDF, imprima o número de páginas do PDF usando a seguinte linha:
print(doc.page_count)
Saída:
5
4. Para extrair links de uma página do arquivo PDF, precisamos carregar a página da qual queremos extrair os links. Para carregar uma página, insira a seguinte linha, onde você passa o número da página que deseja carregar para uma função chamada load_page()
page = doc.load_page(0)
Para extrair links da primeira página, passamos 0(zero). A contagem de páginas começa do zero, assim como em estruturas de dados como arrays e dicionários.
5. Extraia os links da página usando a seguinte linha:
links = page.get_links()
Todos os links da página que você especificou, no nosso caso, página 1, serão extraídos e armazenados na variável chamada links
6. Para ver o conteúdo da variável links, imprima-a assim:
print(links)
Saída:
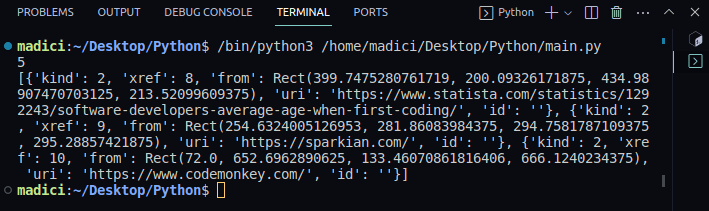
Na saída impressa, observe que os links das variáveis contêm uma lista de dicionários com pares de valores-chave. Cada link na página é representado por um dicionário, com o link real armazenado na chave “uri“
7. Para obter os links da lista de objetos armazenados sob os links de nome de variável, itere pela lista usando uma instrução for in e imprima os links específicos armazenados sob a chave uri. Todo o código que faz isso é mostrado abaixo:
import fitz
# Open the PDF file
doc = fitz.open("games.pdf")
# Print out the number of pages
print(doc.page_count)
# load the first page from the PDF
page = doc.load_page(0)
# extract all links from the page and store it under - links
links = page.get_links()
# print the links object
#print(links)
# print the actual links stored under the key "uri"
for obj in links:
print(obj["uri"])
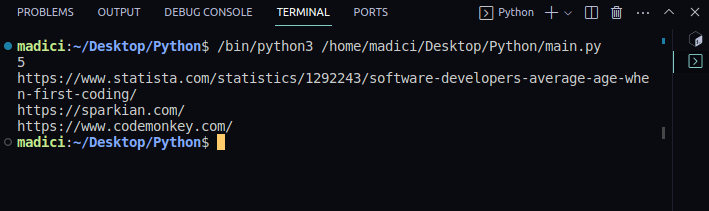
Saída:
5 https://www.statista.com/statistics/1292243/software-developers-average-age-when-first-coding/ https://sparkian.com/ https://www.codemonkey.com/
8. Para tornar nosso código mais reutilizável, podemos refatorá-lo definindo uma função para extrair todos os links de um PDF e uma função para imprimir todos os links encontrados em um PDF. Dessa forma, você pode chamar as funções com qualquer PDF e receberá de volta todos os links do PDF. O código que faz isso é mostrado abaixo:
import fitz
# Extract all the links in a PDF document
def extract_link(path_to_pdf):
links = []
doc = fitz.open(path_to_pdf)
for page_num in range(doc.page_count):
page = doc.load_page(page_num)
page_links = page.get_links()
links.extend(page_links)
return links
# print out all the links returned from the PDF document
def print_all_links(links):
for link in links:
print(link["uri"])
# Call the function to extract all the links in a pdf
# all the return links are stored under all_links
all_links = extract_link("games.pdf")
# call the function to print all links in the PDF
print_all_links(all_links)
Saída:
https://www.statista.com/statistics/1292243/software-developers-average-age-when-first-coding/ https://sparkian.com/ https://www.codemonkey.com/ https://scratch.mit.edu/ https://www.tynker.com/ https://codecombat.com/ https://lightbot.com/ https://sparkian.com
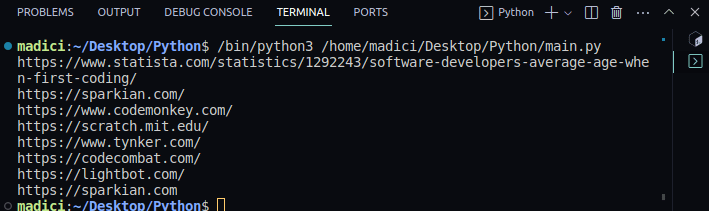
A partir do código acima, a função extract_link() recebe um arquivo PDF, percorre todas as páginas do PDF, extrai todos os links e os retorna. O resultado desta função é armazenado em uma variável chamada all_links
A função print_all_links() recebe o resultado de extract_link(), percorre a lista e imprime todos os links reais encontrados no PDF que você passou para a função extract_link().
Para extrair imagens de um PDF, ainda usaremos PyMuPDF. Para extrair imagens de um arquivo PDF:
1. Importe PyMuPDF, io e PIL. Python Imaging Library (PIL) fornece ferramentas que facilitam a criação e salvamento de imagens, entre outras funções. io fornece classes para manipulação fácil e eficiente de dados binários.
import fitz from io import BytesIO from PIL import Image
2. Abra o arquivo PDF do qual deseja extrair as imagens:
doc = fitz.open("games.pdf")
3. Carregue a página da qual deseja extrair as imagens:
page = doc.load_page(0)
4. PyMuPdf identifica imagens em um arquivo PDF usando um número de referência cruzada (xref), que geralmente é um número inteiro. Cada imagem em um arquivo PDF possui uma refex exclusiva. Portanto, para extrair uma imagem de um PDF, primeiro precisamos obter o número da refex que a identifica. Para obter o número xref das imagens em uma página, usamos a função get_images() assim:
image_xref = page.get_images() print(image_xref)
Saída:
[(7, 0, 699, 407, 8, 'DeviceRGB', '', 'X7', 'FlateDecode')]
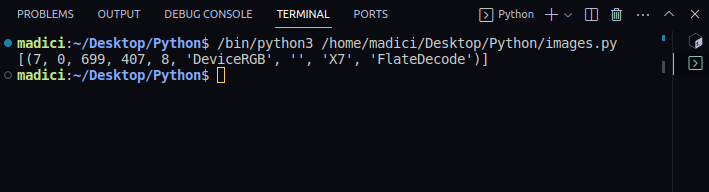
get_images() retorna uma lista de tuplas com informações sobre a imagem. Como temos apenas uma imagem na primeira página, existe apenas uma tupla. O primeiro elemento da tupla representa a refex da imagem na página. Portanto, a refex da imagem na primeira página é 7.
5. Para extrair o valor xref da imagem da lista de tuplas, usamos o código abaixo:
# get xref value of the image xref_value = image_xref[0][0] print(xref_value)
Saída:
[(7, 0, 699, 407, 8, 'DeviceRGB', '', 'X7', 'FlateDecode')] 7
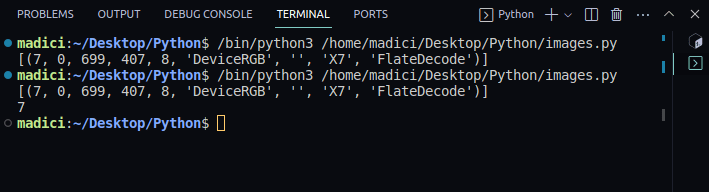
6. Como agora você tem a refex que identifica uma imagem no PDF, você pode extrair a imagem usando a função extract_image() da seguinte forma:
img_dictionary = doc.extract_image(xref_value)
Esta função, entretanto, não retorna a imagem real. Em vez disso, ele retorna um dicionário contendo os dados binários da imagem e metadados sobre a imagem, entre outras coisas.
7. No dicionário retornado pela função extract_image(), verifique a extensão do arquivo da imagem extraída. A extensão do arquivo é armazenada na chave “ext“:
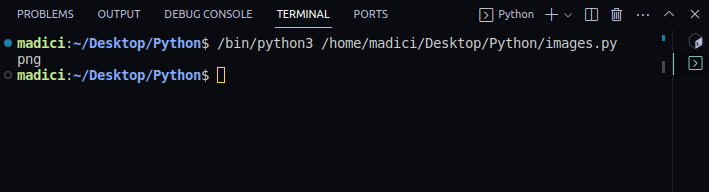
# get file extenstion img_extension = img_dictionary["ext"] print(img_extension)
Saída:
png
8. Extraia os binários da imagem do dicionário armazenado em img_dictionary. Os binários da imagem são armazenados na chave “imagem”
# get the actual image binary data img_binary = img_dictionary["image"]
9. Crie um objeto BytesIO e inicialize-o com os dados binários da imagem que representa a imagem. Isso cria um objeto semelhante a um arquivo que pode ser processado por bibliotecas Python, como PIL, para que você possa salvar a imagem.
# create a BytesIO object to work with the image bytes image_io = BytesIO(img_binary)
10. Abra e analise os dados de imagem armazenados no objeto BytesIO denominado image_io usando a biblioteca PIL. Isso é importante porque permite que a biblioteca PIL determine o formato da imagem com a qual você está tentando trabalhar, neste caso, um PNG. Após detectar o formato da imagem, o PIL cria um objeto de imagem que pode ser manipulado com funções e métodos PIL, como o método save(), para salvar a imagem no armazenamento local.
# open the image using Pillow image = Image.open(image_io)
11. Especifique o caminho onde deseja salvar a imagem.
output_path = "image_1.png"
Como o caminho acima contém apenas o nome do arquivo com sua extensão, a imagem extraída será salva no mesmo diretório do arquivo Python que contém este programa. A imagem será salva como image_1.png. A extensão PNG é importante para corresponder à extensão original da imagem.
12. Salve a imagem e feche o objeto ByteIO.
# save the image image.save(output_path) # Close the BytesIO object image_io.close()
O código completo para extrair uma imagem de um arquivo PDF é mostrado abaixo:
import fitz
from io import BytesIO
from PIL import Image
doc = fitz.open("games.pdf")
page = doc.load_page(0)
# get a cross reference(xref) to the image
image_xref = page.get_images()
# get the actual xref value of the image
xref_value = image_xref[0][0]
# extract the image
img_dictionary = doc.extract_image(xref_value)
# get file extenstion
img_extension = img_dictionary["ext"]
# get the actual image binary data
img_binary = img_dictionary["image"]
# create a BytesIO object to work with the image bytes
image_io = BytesIO(img_binary)
# open the image using PIL library
image = Image.open(image_io)
#specify the path where you want to save the image
output_path = "image_1.png"
# save the image
image.save(output_path)
# Close the BytesIO object
image_io.close()
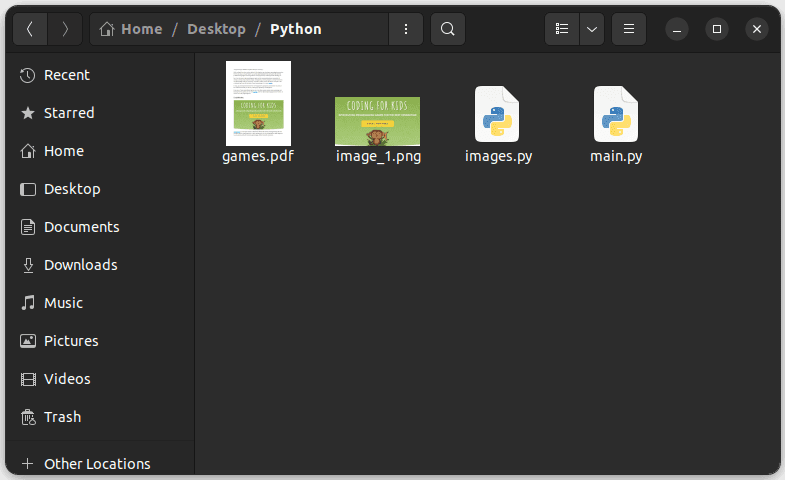
Execute o código e vá para a pasta que contém seu arquivo Python; você deverá ver a imagem extraída chamada image_1.png, conforme mostrado abaixo:
Conclusão
Para praticar mais a extração de links, imagens e textos de PDFs, tente refatorar o código nos exemplos para torná-los mais reutilizáveis, conforme mostrado no exemplo de links. Dessa forma, você só precisará passar um arquivo PDF e seu programa Python extrairá todos os links, imagens ou texto do PDF inteiro. Boa codificação!
Você também pode explorar algumas das melhores APIs de PDF para cada necessidade comercial.