O Llama 2 representa um avanço notável como um modelo de linguagem amplo (LLM) de código aberto, desenvolvido pela Meta. Ele se destaca como uma opção de código aberto robusta, superando até mesmo algumas alternativas proprietárias, como o GPT-3.5 e o PaLM 2. A família Llama 2 abrange três modelos de texto generativo, pré-treinados e ajustados, variando em tamanho de 7 bilhões, 13 bilhões a 70 bilhões de parâmetros.
Neste artigo, exploraremos as capacidades de diálogo do Llama 2 através da criação de um chatbot, utilizando o Streamlit e o próprio Llama 2.
Explorando o Llama 2: Características e Vantagens
Quais são os diferenciais do Llama 2 em comparação com seu predecessor, o Llama 1?
- Aumento na Capacidade do Modelo: Com uma arquitetura que alcança 70 bilhões de parâmetros, o Llama 2 aprende correlações mais complexas entre palavras e sentenças.
- Diálogo Aprimorado: O uso de Aprendizado por Reforço com Feedback Humano (RLHF) eleva as habilidades de conversação, possibilitando que o modelo gere conteúdo natural em interações complexas.
- Inferência Acelerada: A introdução da atenção de consulta agrupada agiliza o processo de inferência, abrindo portas para aplicações mais eficazes, como chatbots e assistentes virtuais.
- Eficiência Aprimorada: O modelo apresenta uma gestão de memória e recursos computacionais mais eficiente que seu antecessor.
- Licença Open Source Não Comercial: O Llama 2 é de código aberto, permitindo que pesquisadores e desenvolvedores o utilizem e modifiquem livremente.
O Llama 2 supera seu antecessor em vários aspectos, tornando-se uma ferramenta poderosa para diversas finalidades, como chatbots, assistentes virtuais e compreensão da linguagem natural.
Preparando um Ambiente Streamlit para o Desenvolvimento do Chatbot
Para iniciar a construção do seu aplicativo, é crucial estabelecer um ambiente de desenvolvimento. Isso assegura que seu projeto permaneça isolado de outras atividades em sua máquina.
Primeiramente, crie um ambiente virtual com o Pipenv:
pipenv shell
Em seguida, instale as bibliotecas necessárias para construir o chatbot.
pipenv install streamlit replicate
Streamlit: Um framework web open source para a criação rápida de aplicações de aprendizado de máquina e ciência de dados.
Replicate: Uma plataforma em nuvem que oferece acesso a modelos de aprendizado de máquina de código aberto para implementação.
Obtendo seu Token da API Llama 2 do Replicate
Para obter sua chave de token do Replicate, inscreva-se no Replicate utilizando sua conta GitHub.
Após acessar o painel, clique em Explorar e procure por Llama 2 chat para visualizar o modelo llama-2–70b-chat.
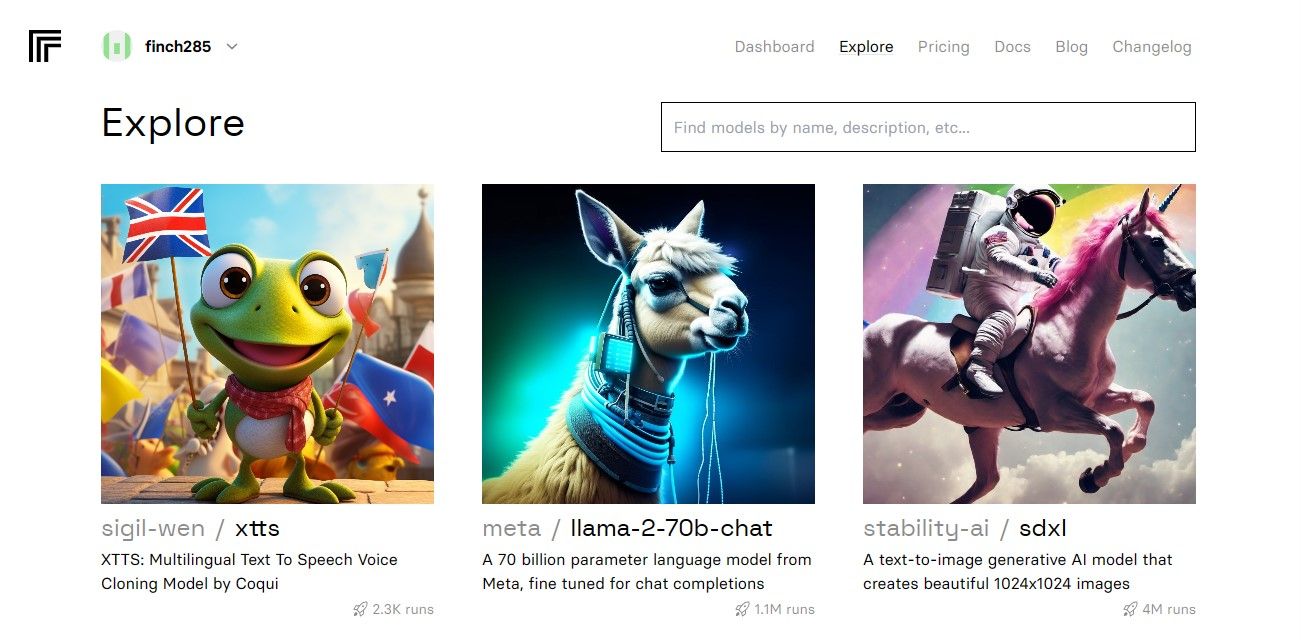
Selecione o modelo llama-2–70b-chat para acessar os endpoints da API. Clique em API na barra de navegação. Na seção à direita, escolha Python. Isso fornecerá acesso ao token da API para uso em aplicações Python.
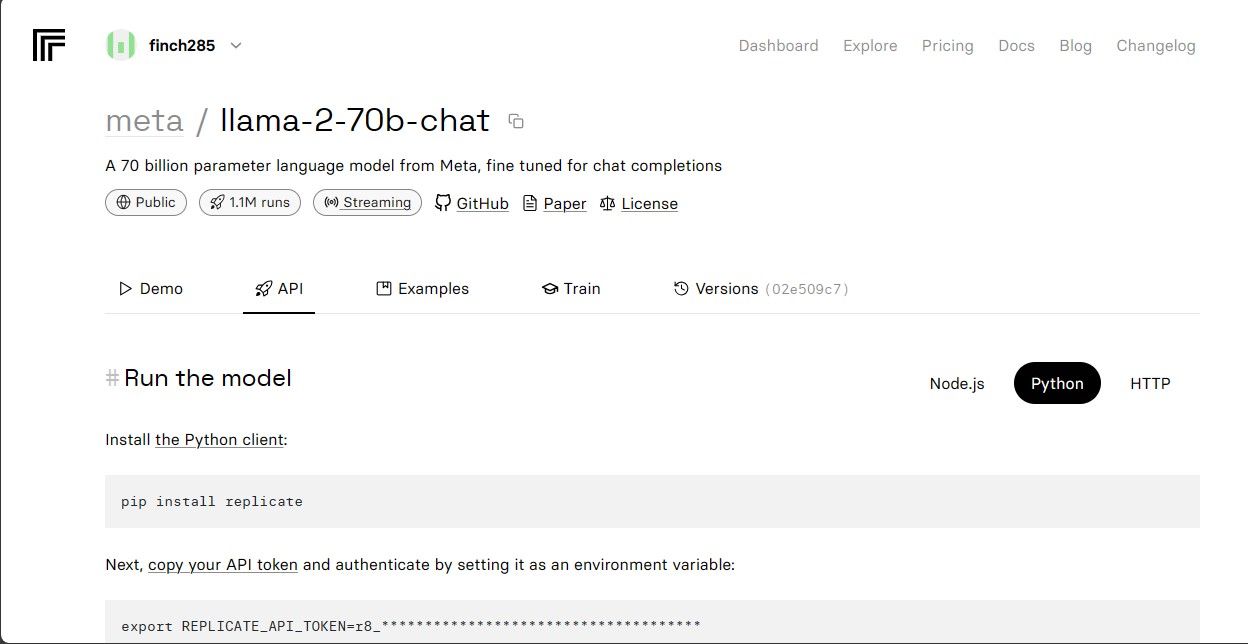
Copie o REPLICATE_API_TOKEN e armazene-o em um local seguro.
Construindo o Chatbot
Crie um arquivo Python (llama_chatbot.py) e um arquivo de ambiente (.env). Você codificará em llama_chatbot.py e guardará suas chaves secretas e tokens da API em .env.
Em llama_chatbot.py, importe as bibliotecas:
import streamlit as st
import os
import replicate
Defina as variáveis globais do modelo llama-2–70b-chat:
REPLICATE_API_TOKEN = os.environ.get('REPLICATE_API_TOKEN', default="")
LLaMA2_7B_ENDPOINT = os.environ.get('MODEL_ENDPOINT7B', default="")
LLaMA2_13B_ENDPOINT = os.environ.get('MODEL_ENDPOINT13B', default="")
LLaMA2_70B_ENDPOINT = os.environ.get('MODEL_ENDPOINT70B', default="")
Em .env, adicione o token do Replicate e os endpoints do modelo no seguinte formato:
REPLICATE_API_TOKEN='Cole_Seu_Token_Replicate'
MODEL_ENDPOINT7B='a16z-infra/llama7b-v2-chat:4f0a4744c7295c024a1de15e1a63c880d3da035fa1f49bfd344fe076074c8eea'
MODEL_ENDPOINT13B='a16z-infra/llama13b-v2-chat:df7690f1994d94e96ad9d568eac121aecf50684a0b0963b25a41cc40061269e5'
MODEL_ENDPOINT70B='replicate/llama70b-v2-chat:e951f18578850b652510200860fc4ea62b3b16fac280f83ff32282f87bbd2e48'
Cole seu token do Replicate e salve o arquivo .env.
Planejando o Fluxo de Conversa do Chatbot
Defina um pré-prompt para guiar o Llama 2 dependendo da tarefa desejada. Neste caso, o modelo deve atuar como um assistente.
PRE_PROMPT = "Você é um assistente útil. Não responda como 'Usuário' ou finja ser 'Usuário'. Responda apenas uma vez como Assistente."
Configure as definições da página do seu chatbot:
st.set_page_config(
page_title="LLaMA2Chat",
page_icon=":volleyball:",
layout="wide"
)
Crie uma função para inicializar as variáveis de estado da sessão:
LLaMA2_MODELS = {
'LLaMA2-7B': LLaMA2_7B_ENDPOINT,
'LLaMA2-13B': LLaMA2_13B_ENDPOINT,
'LLaMA2-70B': LLaMA2_70B_ENDPOINT,
}
DEFAULT_TEMPERATURE = 0.1
DEFAULT_TOP_P = 0.9
DEFAULT_MAX_SEQ_LEN = 512
DEFAULT_PRE_PROMPT = PRE_PROMPTdef setup_session_state():
st.session_state.setdefault('chat_dialogue', [])
selected_model = st.sidebar.selectbox(
'Escolha um modelo LLaMA2:', list(LLaMA2_MODELS.keys()), key='model')
st.session_state.setdefault(
'llm', LLaMA2_MODELS.get(selected_model, LLaMA2_70B_ENDPOINT))
st.session_state.setdefault('temperature', DEFAULT_TEMPERATURE)
st.session_state.setdefault('top_p', DEFAULT_TOP_P)
st.session_state.setdefault('max_seq_len', DEFAULT_MAX_SEQ_LEN)
st.session_state.setdefault('pre_prompt', DEFAULT_PRE_PROMPT)
Essa função configura variáveis como chat_dialogue, pre_prompt, llm, top_p, max_seq_len e temperatura no estado da sessão. Ela também gerencia a seleção do modelo Llama 2 com base na preferência do usuário.
Crie uma função para renderizar a barra lateral do aplicativo Streamlit:
def render_sidebar():
st.sidebar.header("Chatbot LLaMA2")
st.session_state['temperature'] = st.sidebar.slider('Temperatura:',
min_value=0.01, max_value=5.0, value=DEFAULT_TEMPERATURE, step=0.01)
st.session_state['top_p'] = st.sidebar.slider('Top P:', min_value=0.01,
max_value=1.0, value=DEFAULT_TOP_P, step=0.01)
st.session_state['max_seq_len'] = st.sidebar.slider('Comprimento Máximo da Sequência:',
min_value=64, max_value=4096, value=DEFAULT_MAX_SEQ_LEN, step=8)
new_prompt = st.sidebar.text_area(
'Prompt antes do início da conversa. Edite se desejar:',
DEFAULT_PRE_PROMPT,height=60)
if new_prompt != DEFAULT_PRE_PROMPT and new_prompt != "" and
new_prompt is not None:
st.session_state['pre_prompt'] = new_prompt + "\n"
else:
st.session_state['pre_prompt'] = DEFAULT_PRE_PROMPT
Essa função exibe o cabeçalho e as opções de configuração para o ajuste do chatbot Llama 2.
Crie uma função que exibe o histórico da conversa na área principal do aplicativo:
def render_chat_history():
response_container = st.container()
for message in st.session_state.chat_dialogue:
with st.chat_message(message["role"]):
st.markdown(message["content"])
Essa função percorre o chat_dialogue salvo, exibindo cada mensagem com seu respectivo papel (usuário ou assistente).
Gerencie a entrada do usuário com a função abaixo:
def handle_user_input():
user_input = st.chat_input(
"Digite sua pergunta aqui para conversar com o LLaMA2"
)
if user_input:
st.session_state.chat_dialogue.append(
{"role": "user", "content": user_input}
)
with st.chat_message("user"):
st.markdown(user_input)
Essa função fornece um campo de entrada para os usuários inserirem suas mensagens e dúvidas. A mensagem é adicionada ao chat_dialogue no estado da sessão, identificada com o papel de usuário, assim que é enviada.
Crie uma função que gere as respostas do modelo Llama 2 e as exiba na interface do chat:
def generate_assistant_response():
message_placeholder = st.empty()
full_response = ""
string_dialogue = st.session_state['pre_prompt']
for dict_message in st.session_state.chat_dialogue:
speaker = "Usuário" if dict_message["role"] == "user" else "Assistente"
string_dialogue += f"{speaker}: {dict_message['content']}\n"
output = debounce_replicate_run(
st.session_state['llm'],
string_dialogue + "Assistente: ",
st.session_state['max_seq_len'],
st.session_state['temperature'],
st.session_state['top_p'],
REPLICATE_API_TOKEN
)
for item in output:
full_response += item
message_placeholder.markdown(full_response + "▌")
message_placeholder.markdown(full_response)
st.session_state.chat_dialogue.append({"role": "assistant",
"content": full_response})
Essa função cria um histórico de conversas, incluindo as mensagens do usuário e do assistente, antes de chamar debounce_replicate_run para obter a resposta do assistente. A resposta é mostrada de forma progressiva na interface, simulando uma conversa em tempo real.
Crie a função principal para renderizar todo o aplicativo Streamlit:
def render_app():
setup_session_state()
render_sidebar()
render_chat_history()
handle_user_input()
generate_assistant_response()
Essa função chama as outras funções em sequência lógica para configurar o estado da sessão, renderizar a barra lateral e o histórico de conversa, gerenciar a entrada do usuário e obter as respostas do assistente.
Implemente uma função para executar o aplicativo ao iniciar o script:
def main():
render_app()if __name__ == "__main__":
main()
Nesse momento, o aplicativo deve estar pronto para rodar.
Tratando Requisições da API
Crie um arquivo utils.py e adicione a função abaixo:
import replicate
import time
last_call_time = 0
debounce_interval = 2def debounce_replicate_run(llm, prompt, max_len, temperature, top_p,
API_TOKEN):
global last_call_time
print("última chamada: ", last_call_time)current_time = time.time()
elapsed_time = current_time - last_call_timeif elapsed_time < debounce_interval:
print("Debouncing")
return "Olá! Suas solicitações estão muito rápidas. Por favor, aguarde alguns" \
" segundos antes de enviar outra solicitação."last_call_time = time.time()
output = replicate.run(llm, input={"prompt": prompt + "Assistente: ",
"max_length": max_len, "temperature":
temperature, "top_p": top_p,
"repetition_penalty": 1}, api_token=API_TOKEN)
return output
Essa função implementa um mecanismo para evitar consultas frequentes à API.
Importe a função debounce para llama_chatbot.py:
from utils import debounce_replicate_run
Execute o aplicativo:
streamlit run llama_chatbot.py
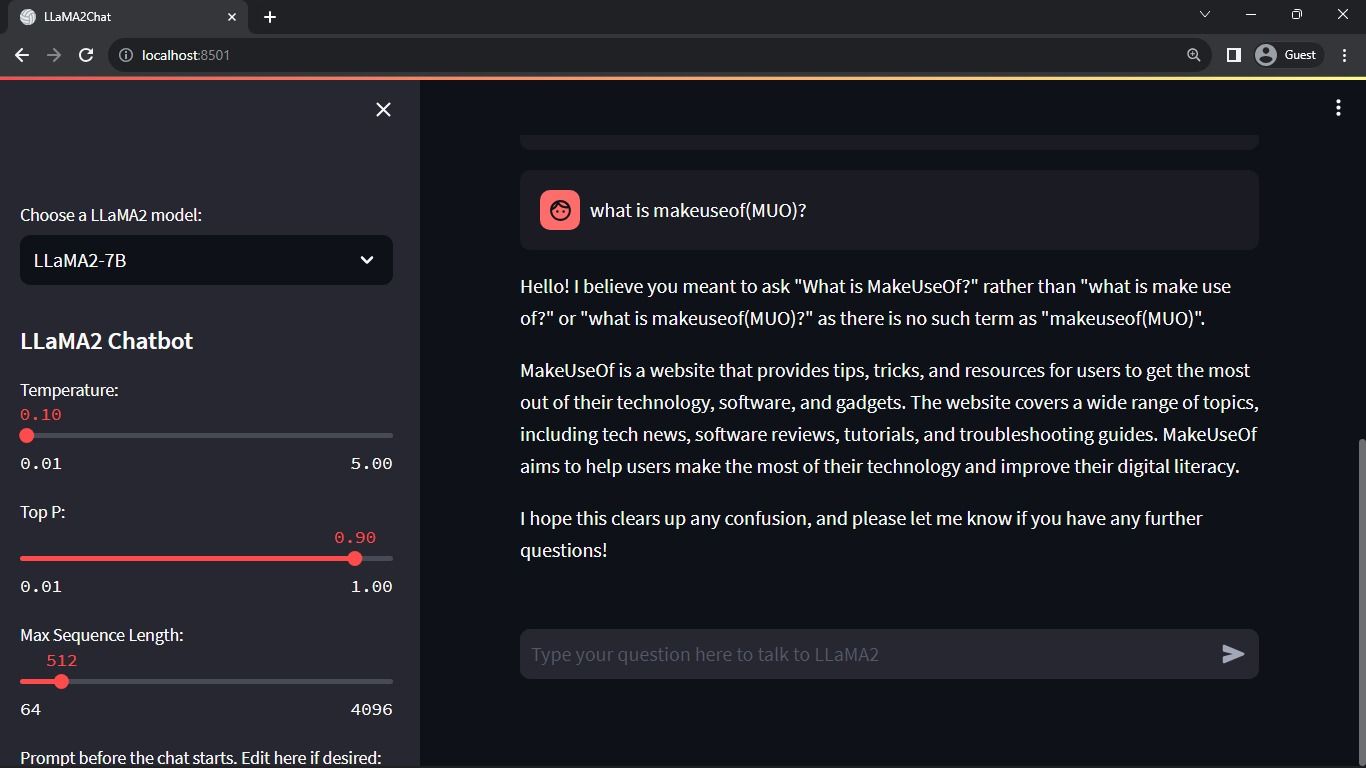
Resultado Esperado:
A interface mostrará uma conversa entre o modelo e o usuário.
Aplicações Reais de Chatbots Streamlit e Llama 2
Alguns exemplos de aplicação do Llama 2 são:
- Chatbots: Criação de chatbots com respostas humanas para conversas em tempo real sobre diversos temas.
- Assistentes Virtuais: Desenvolvimento de assistentes virtuais que interpretam e respondem a perguntas em linguagem natural.
- Tradução de Idiomas: Aplicação em tarefas de tradução de diferentes idiomas.
- Resumo de Textos: Capacidade de condensar textos extensos em versões concisas.
- Pesquisa: Utilização do Llama 2 para responder a questões sobre variados temas.
O Futuro da IA
Com modelos proprietários como o GPT-3.5 e GPT-4, construir algo significativo utilizando LLMs torna-se um desafio para pequenos desenvolvedores, devido ao alto custo de acesso à API.
A disponibilização de modelos de linguagem avançados, como o Llama 2, representa o início de uma nova era para a IA, fomentando aplicações criativas e inovadoras que impulsionam o progresso em direção à superinteligência artificial (ASI).