
A Meta lançou o Llama 2 no verão de 2023. A nova versão do Llama foi ajustada com 40% mais tokens do que o modelo Llama original, dobrando seu comprimento de contexto e superando significativamente outros modelos de código aberto disponíveis. A maneira mais rápida e fácil de acessar o Llama 2 é por meio de uma API em uma plataforma online. No entanto, se você deseja a melhor experiência, é melhor instalar e carregar o Llama 2 diretamente no seu computador.
Com isso em mente, criamos um guia passo a passo sobre como usar Text-Generation-WebUI para carregar um Llama 2 LLM quantizado localmente em seu computador.
últimas postagens
Por que instalar o Llama 2 localmente
Existem muitos motivos pelos quais as pessoas optam por executar o Llama 2 diretamente. Alguns fazem isso por questões de privacidade, alguns para personalização e outros para recursos offline. Se você estiver pesquisando, ajustando ou integrando o Llama 2 para seus projetos, acessar o Llama 2 via API pode não ser para você. O objetivo de executar um LLM localmente em seu PC é reduzir a dependência de ferramentas de IA de terceiros e usar IA a qualquer hora, em qualquer lugar, sem se preocupar com o vazamento de dados potencialmente confidenciais para empresas e outras organizações.
Dito isso, vamos começar com o guia passo a passo para instalar o Llama 2 localmente.
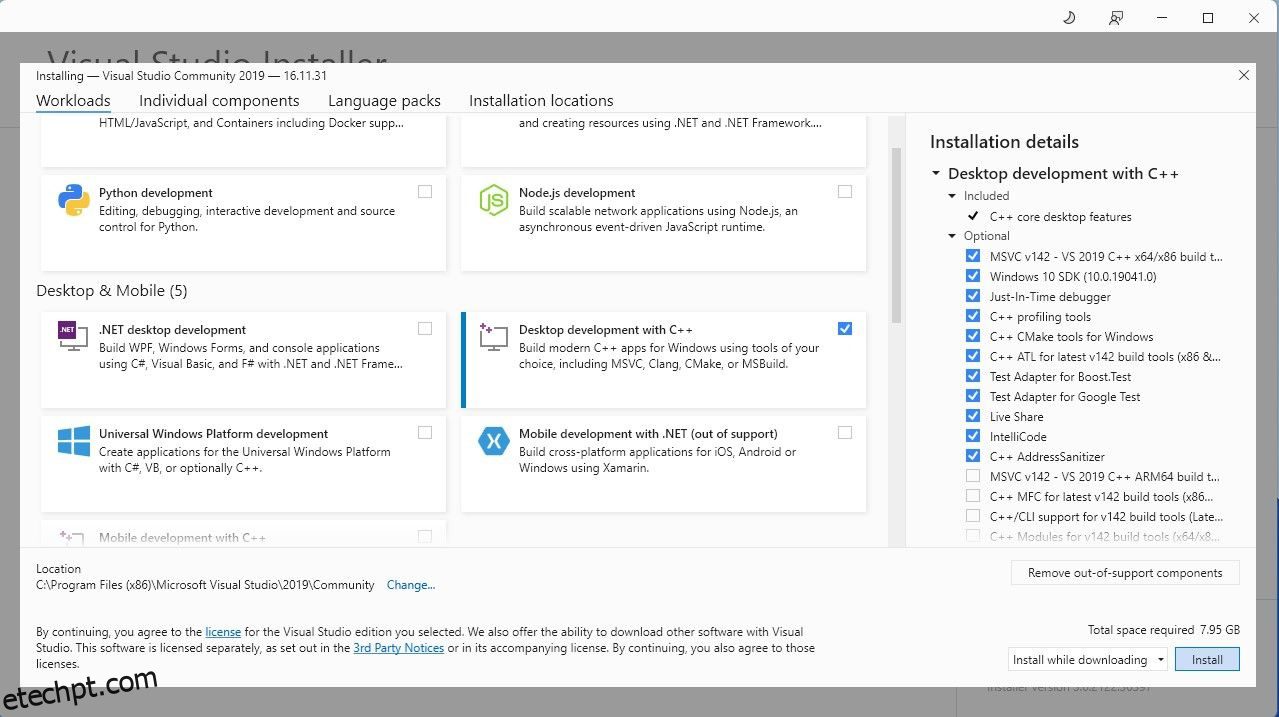
Para simplificar as coisas, usaremos um instalador de um clique para Text-Generation-WebUI (o programa usado para carregar o Llama 2 com GUI). Porém, para que este instalador funcione, você precisa baixar a ferramenta de compilação do Visual Studio 2019 e instalar os recursos necessários.
Download: Estúdio Visual 2019 (Livre)
Agora que você instalou o desenvolvimento de desktop com C++, é hora de baixar o instalador de um clique Text-Generation-WebUI.
Etapa 2: instalar Text-Generation-WebUI
O instalador de um clique Text-Generation-WebUI é um script que cria automaticamente as pastas necessárias e configura o ambiente Conda e todos os requisitos necessários para executar um modelo de IA.
Para instalar o script, baixe o instalador com um clique clicando em Código > Baixar ZIP.
Download: Instalador de geração de texto-WebUI (Livre)
- Se você estiver no Windows, selecione o arquivo em lote start_windows
- para MacOS, selecione script de shell start_macos
- para Linux, script de shell start_linux.
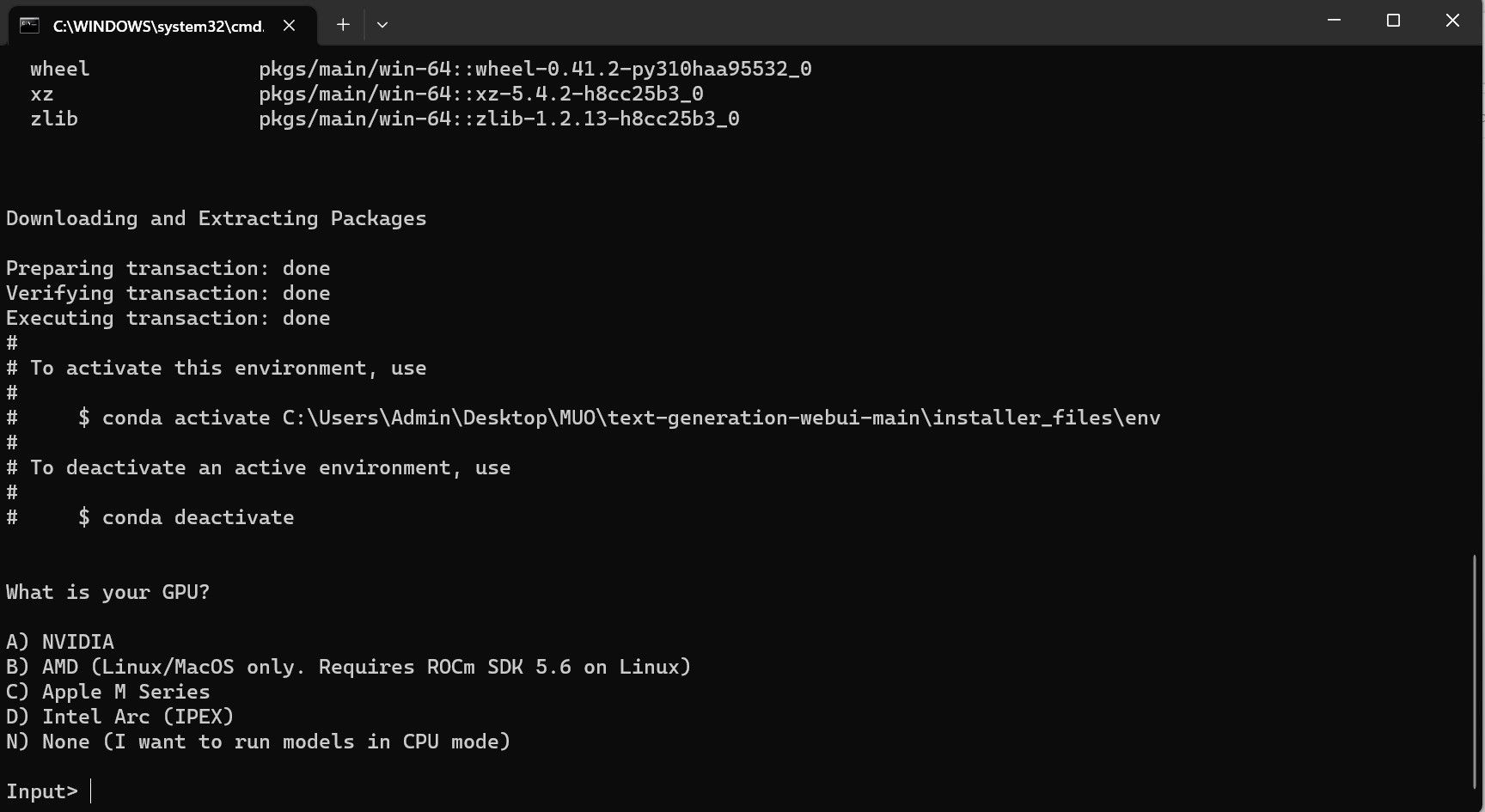
No entanto, o programa é apenas um carregador de modelo. Vamos baixar o Llama 2 para iniciar o carregador de modelo.
Etapa 3: Baixe o modelo Llama 2
Há algumas coisas a serem consideradas ao decidir qual iteração do Llama 2 você precisa. Isso inclui parâmetros, quantização, otimização de hardware, tamanho e uso. Todas essas informações serão encontradas indicadas no nome do modelo.
- Parâmetros: o número de parâmetros usados para treinar o modelo. Parâmetros maiores tornam os modelos mais capazes, mas à custa do desempenho.
- Uso: Pode ser padrão ou chat. Um modelo de chat é otimizado para ser usado como um chatbot como o ChatGPT, enquanto o modelo padrão é o modelo padrão.
- Otimização de Hardware: Refere-se a qual hardware executa melhor o modelo. GPTQ significa que o modelo é otimizado para rodar em uma GPU dedicada, enquanto GGML é otimizado para rodar em uma CPU.
- Quantização: Denota a precisão dos pesos e ativações em um modelo. Para inferência, uma precisão de q4 é ideal.
- Tamanho: Refere-se ao tamanho do modelo específico.
Observe que alguns modelos podem estar organizados de forma diferente e podem até não exibir os mesmos tipos de informações. No entanto, esse tipo de convenção de nomenclatura é bastante comum na biblioteca do modelo HuggingFace, portanto, ainda vale a pena entendê-la.

Neste exemplo, o modelo pode ser identificado como um modelo Llama 2 de tamanho médio treinado em 13 bilhões de parâmetros otimizados para inferência de chat usando uma CPU dedicada.
Para quem roda em GPU dedicada, escolha um modelo GPTQ, enquanto para quem usa CPU, escolha GGML. Se você quiser conversar com o modelo como faria com o ChatGPT, escolha chat, mas se quiser experimentar o modelo com todos os seus recursos, use o modelo padrão. Quanto aos parâmetros, saiba que utilizar modelos maiores proporcionará melhores resultados em detrimento do desempenho. Eu pessoalmente recomendo que você comece com um modelo 7B. Quanto à quantização, use q4, pois serve apenas para inferência.
Download: GML (Livre)
Download: GPTQ (Livre)
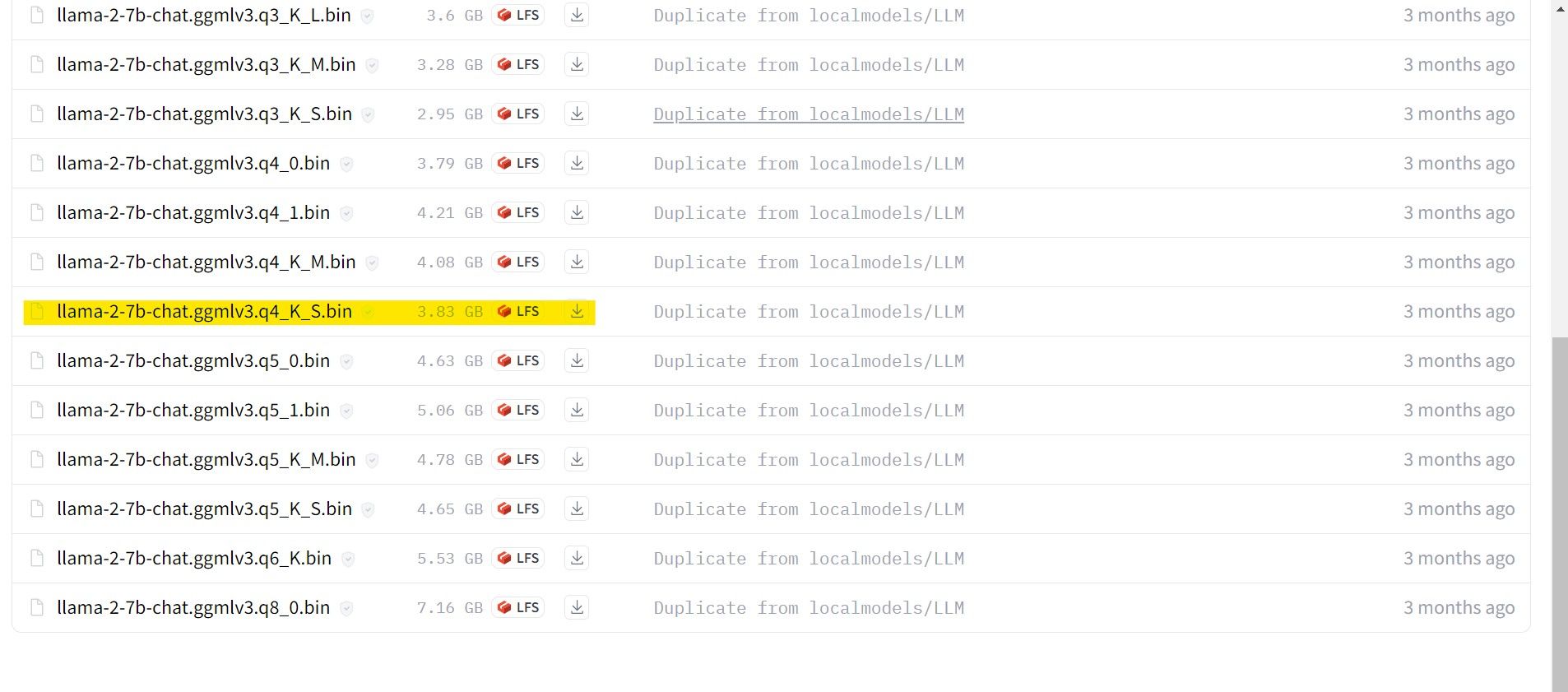
Agora que você sabe qual iteração do Llama 2 precisa, vá em frente e baixe o modelo desejado.
No meu caso, como estou executando isso em um ultrabook, usarei um modelo GGML ajustado para chat, llama-2-7b-chat-ggmlv3.q4_K_S.bin.
Após a conclusão do download, coloque o modelo em text-generation-webui-main > models.
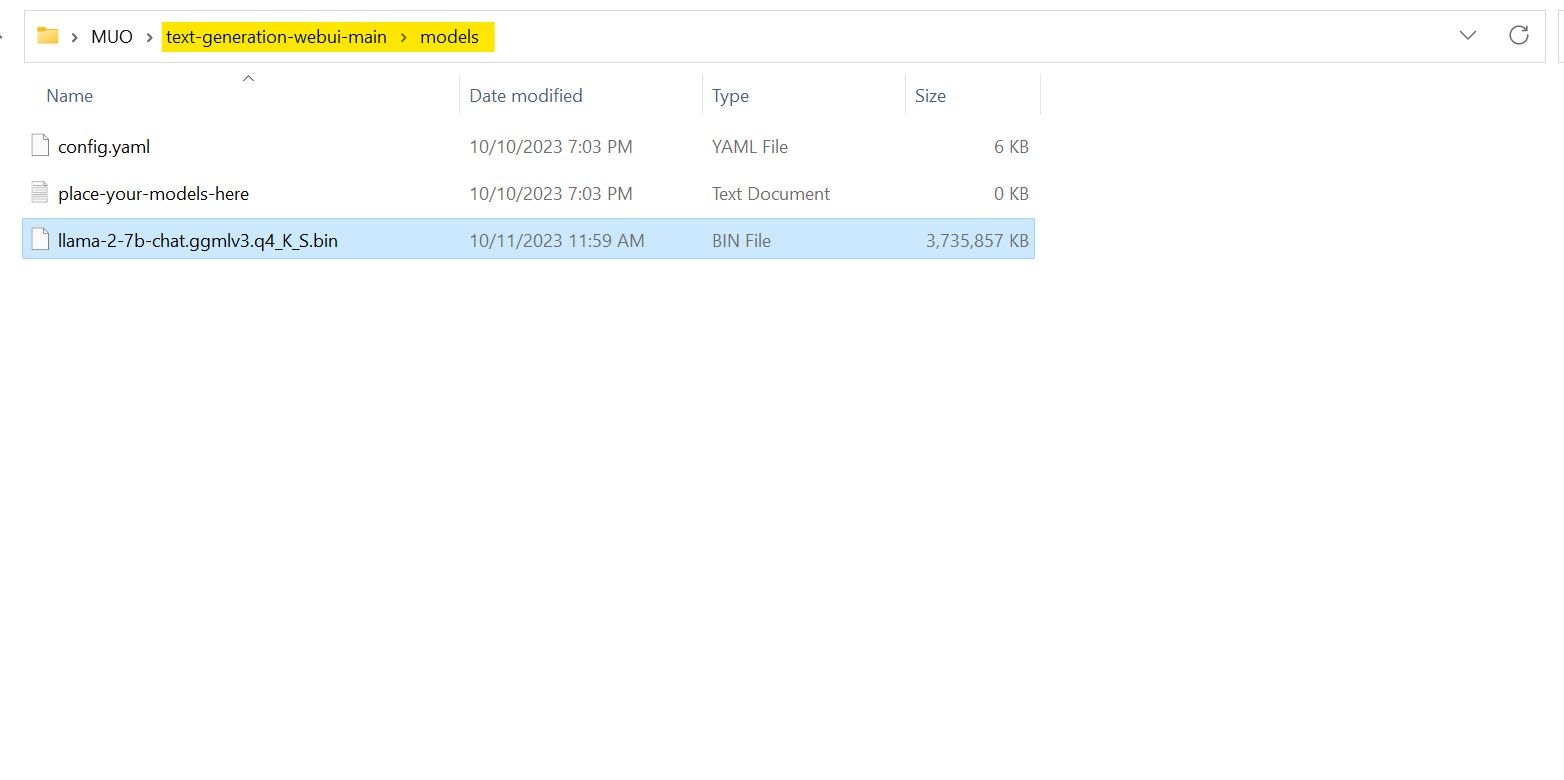
Agora que você baixou seu modelo e o colocou na pasta de modelos, é hora de configurar o carregador de modelo.
Etapa 4: configurar a geração de texto-WebUI
Agora, vamos começar a fase de configuração.
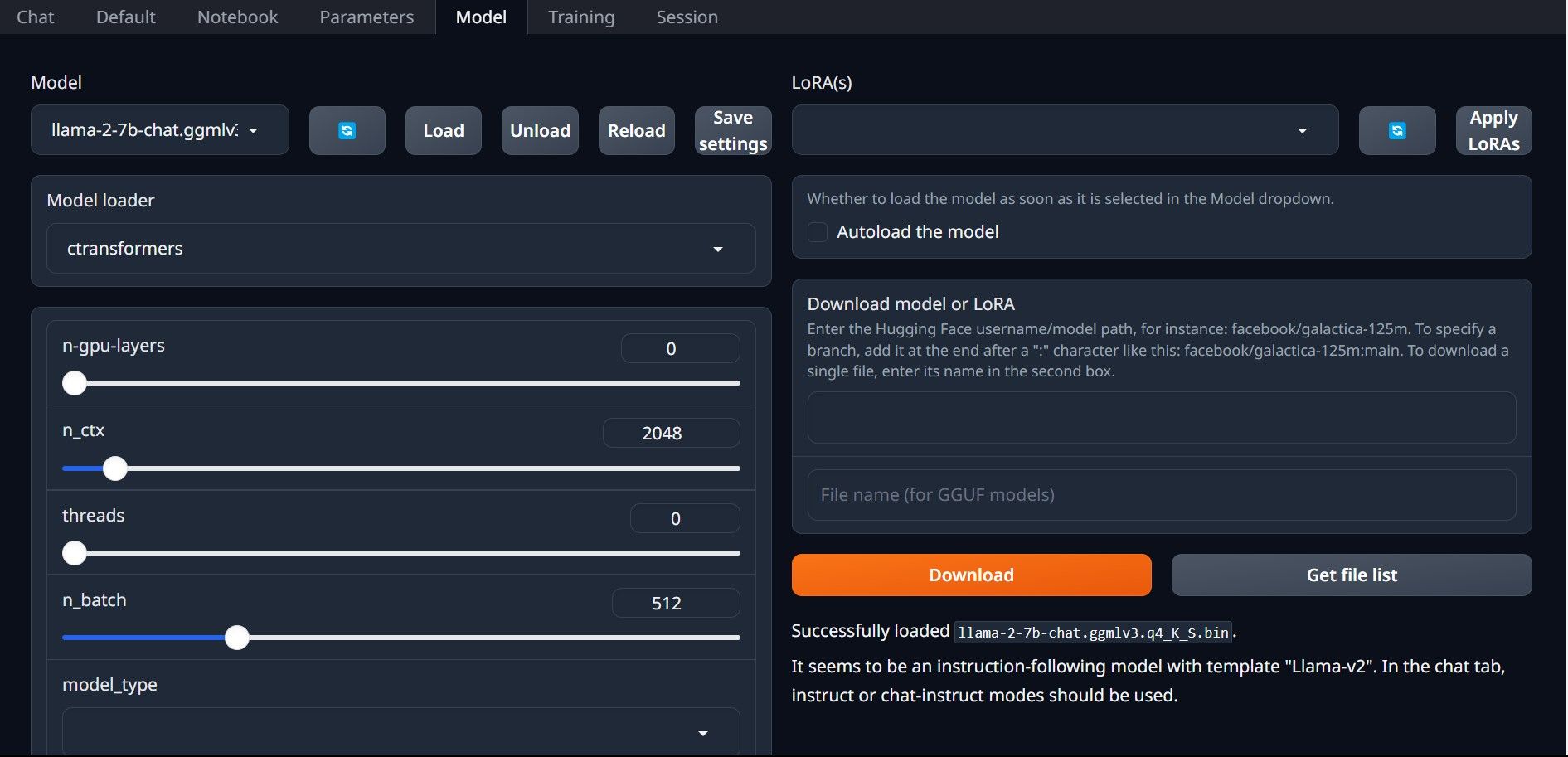
Parabéns, você carregou o Llama2 com sucesso em seu computador local!
Experimente outros LLMs
Agora que você sabe como executar o Llama 2 diretamente em seu computador usando Text-Generation-WebUI, também poderá executar outros LLMs além do Llama. Basta lembrar as convenções de nomenclatura dos modelos e que apenas versões quantizadas de modelos (geralmente com precisão q4) podem ser carregadas em PCs normais. Muitos LLMs quantizados estão disponíveis no HuggingFace. Se você quiser explorar outros modelos, pesquise TheBloke na biblioteca de modelos do HuggingFace e você encontrará muitos modelos disponíveis.