No verão de 2023, a Meta apresentou o Llama 2, uma versão aprimorada do modelo original Llama. Esta nova iteração foi treinada com um volume de dados 40% maior, dobrando seu alcance contextual e superando outros modelos de código aberto disponíveis no mercado. Embora o acesso ao Llama 2 possa ser feito rapidamente por meio de uma API online, para uma experiência otimizada, a instalação e execução local diretamente no seu computador é a melhor opção.
Pensando nisso, desenvolvemos um guia detalhado de como utilizar o Text-Generation-WebUI para carregar um modelo Llama 2 quantizado localmente em seu sistema.
Razões para Instalar o Llama 2 Localmente
Há diversas razões para optar pela execução local do Llama 2. Questões de privacidade, personalização e funcionalidades offline são alguns dos motivos. Se você está conduzindo pesquisas, ajustando ou integrando o Llama 2 em projetos, a utilização via API pode não ser a mais adequada. O objetivo de executar um LLM localmente é diminuir a dependência de ferramentas de IA de terceiros, permitindo o uso da IA em qualquer lugar e momento, sem a preocupação de vazamento de dados sensíveis para empresas ou outras organizações.
Com isso em mente, vamos ao guia passo a passo para instalar o Llama 2 localmente.
Para simplificar, usaremos um instalador de um clique para o Text-Generation-WebUI (o programa que permite carregar o Llama 2 com interface gráfica). No entanto, para que este instalador funcione, é necessário instalar o Visual Studio 2019 e os recursos necessários.
Download: Visual Studio 2019 (Grátis)
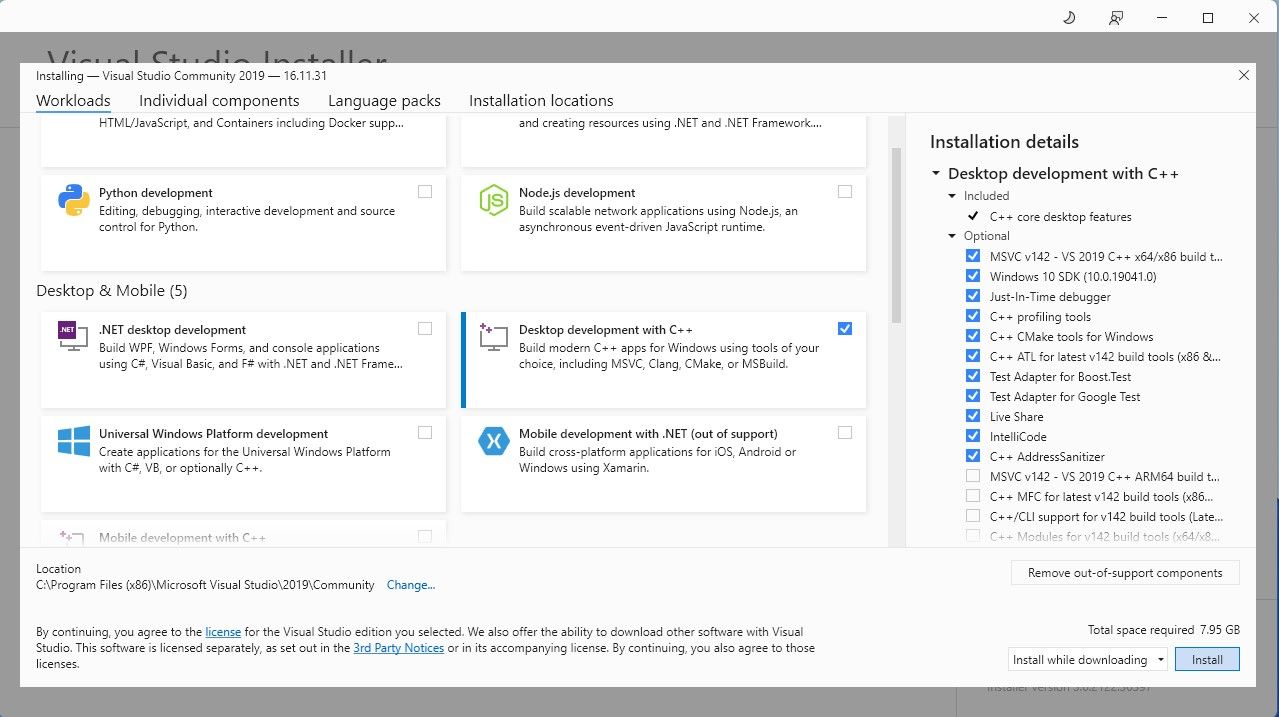
Com o desenvolvimento para desktop com C++ instalado, é hora de baixar o instalador de um clique do Text-Generation-WebUI.
Etapa 2: Instalação do Text-Generation-WebUI
O instalador de um clique do Text-Generation-WebUI é um script que automatiza a criação das pastas necessárias e configura o ambiente Conda, além de todos os requisitos para executar um modelo de IA.
Para instalar o script, baixe o instalador clicando em “Código > Baixar ZIP”.
Download: Instalador Text-Generation-WebUI (Grátis)
- Se estiver no Windows, selecione o arquivo em lote “start_windows”.
- Para MacOS, selecione o script de shell “start_macos”.
- Para Linux, o script de shell “start_linux”.
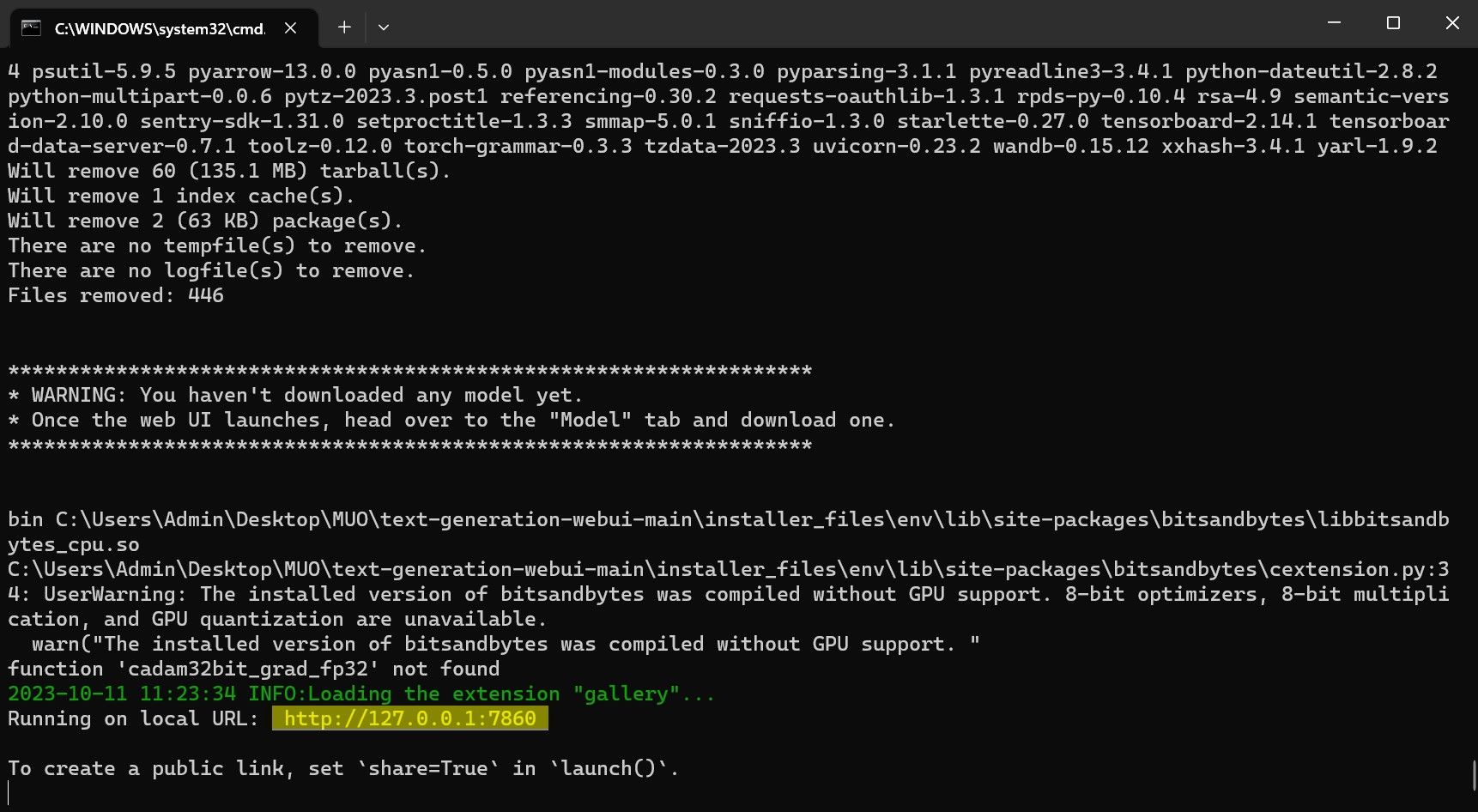
O programa, no entanto, é apenas um carregador de modelos. Vamos baixar o Llama 2 para inicializar o carregador de modelo.
Etapa 3: Download do Modelo Llama 2
Ao escolher a versão do Llama 2, é preciso considerar alguns fatores, como parâmetros, quantização, otimização de hardware, tamanho e uso. Essas informações estarão indicadas no nome do modelo.
- Parâmetros: o número de parâmetros usados no treinamento do modelo. Modelos com mais parâmetros tendem a ser mais avançados, porém, com um custo de desempenho.
- Uso: pode ser padrão ou de chat. Modelos de chat são otimizados para serem usados como chatbots, como o ChatGPT, enquanto o modelo padrão é a versão básica.
- Otimização de Hardware: indica em qual hardware o modelo tem melhor desempenho. GPTQ significa otimização para GPU dedicada, enquanto GGML para CPUs.
- Quantização: indica a precisão dos pesos e ativações em um modelo. Para inferência, uma precisão de q4 é ideal.
- Tamanho: refere-se ao tamanho do modelo específico.
Note que alguns modelos podem estar organizados de maneira diferente e podem não mostrar os mesmos tipos de informações. No entanto, essa convenção de nomenclatura é comum na biblioteca de modelos HuggingFace, sendo útil compreendê-la.

Neste exemplo, o modelo é um Llama 2 de tamanho médio treinado em 13 bilhões de parâmetros, otimizado para inferência de chat usando uma CPU dedicada.
Para usuários de GPU dedicada, escolha um modelo GPTQ, e para CPU, um modelo GGML. Para conversar com o modelo como no ChatGPT, escolha chat, ou use o modelo padrão para experimentar todos os recursos. Modelos maiores tendem a oferecer melhores resultados, mas com maior custo de desempenho. Recomenda-se começar com um modelo 7B, e para quantização, utilize q4, pois é ideal para inferência.
Download: GML (Grátis)
Download: GPTQ (Grátis)
Com sua versão do Llama 2 escolhida, prossiga com o download.
Para este exemplo, em um ultrabook, usaremos um modelo GGML ajustado para chat, “llama-2-7b-chat-ggmlv3.q4_K_S.bin”.
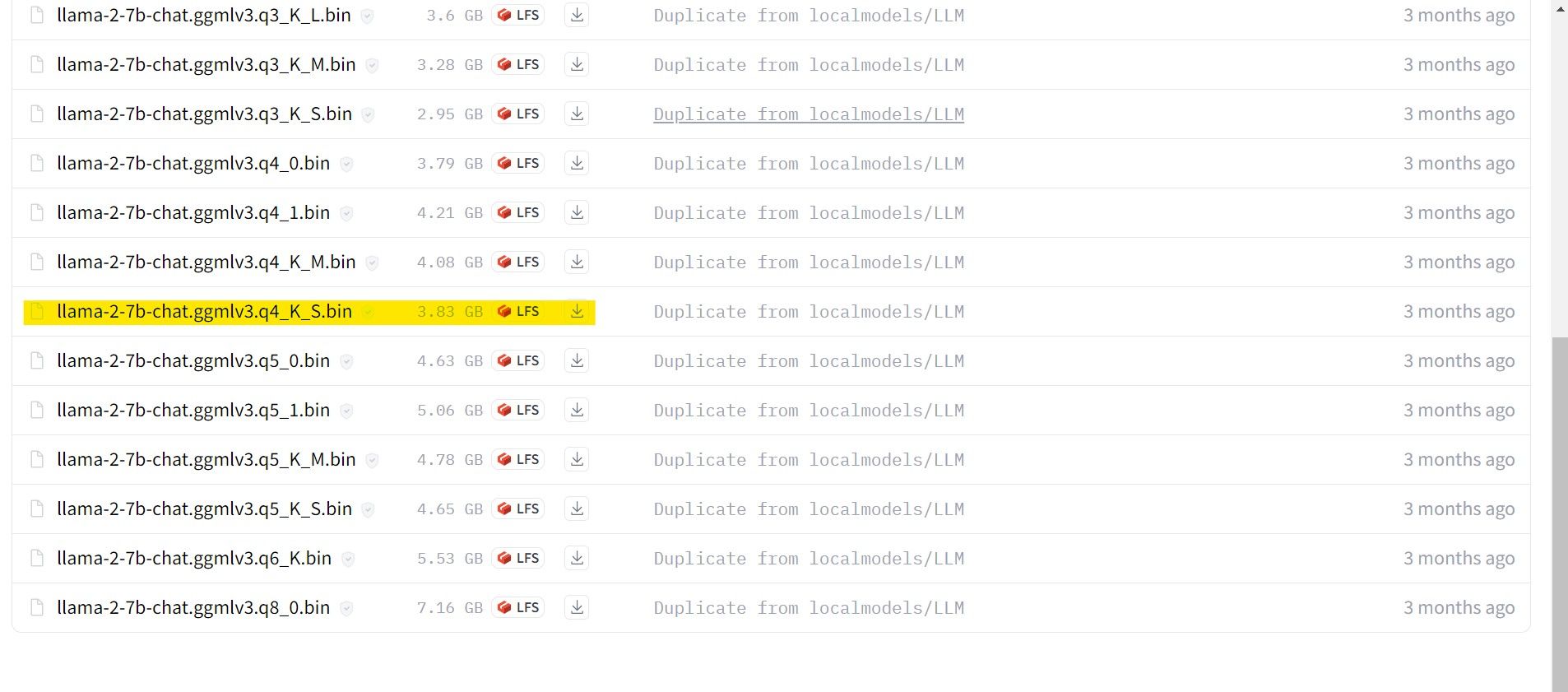
Com o download concluído, coloque o modelo em “text-generation-webui-main > models”.
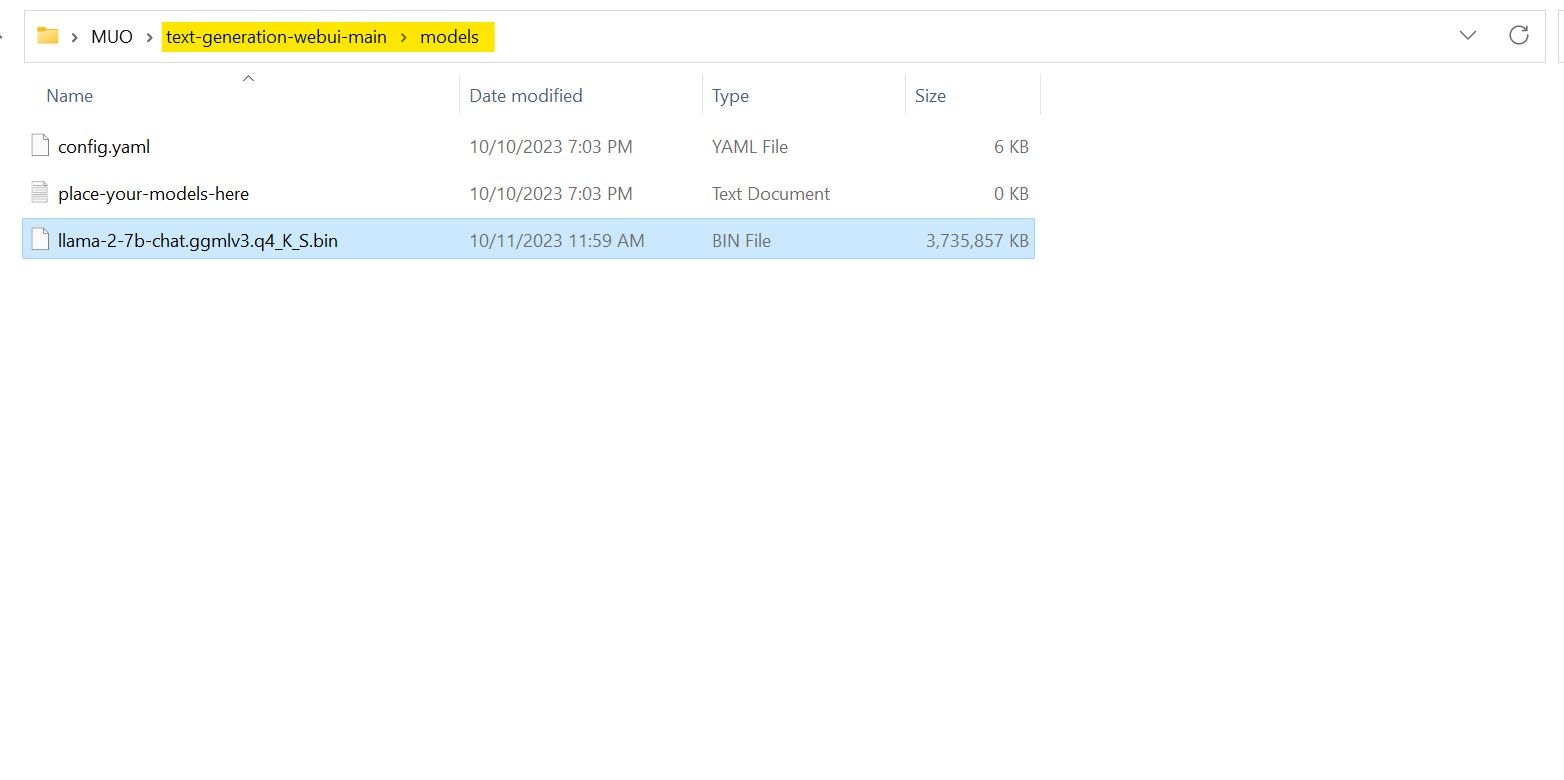
Com o modelo na pasta correta, é hora de configurar o carregador de modelos.
Etapa 4: Configuração do Text-Generation-WebUI
Iniciemos a fase de configuração.
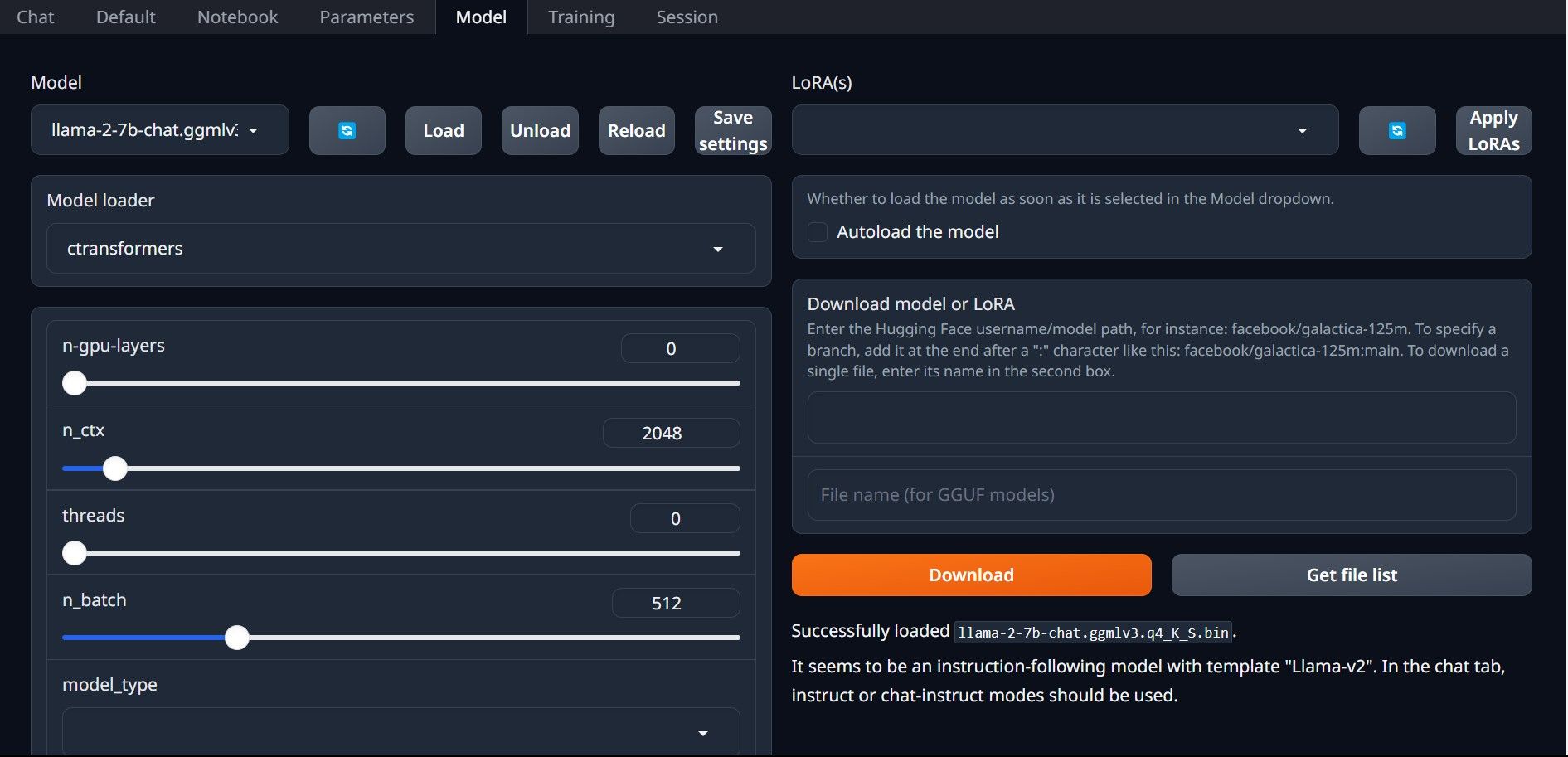
Parabéns! Você carregou o Llama 2 com sucesso em seu computador local!
Explorando Outros LLMs
Com o conhecimento de como executar o Llama 2 diretamente em seu computador através do Text-Generation-WebUI, você também pode explorar outros LLMs. Lembre-se das convenções de nomenclatura e que apenas versões quantizadas (geralmente com precisão q4) podem ser carregadas em PCs comuns. Há muitos LLMs quantizados disponíveis no HuggingFace. Para explorar outros modelos, procure por “TheBloke” na biblioteca de modelos do HuggingFace, onde encontrará uma vasta seleção.