O Poder do Comando Patch no Linux
O comando patch no Linux é uma ferramenta eficiente para aplicar alterações de um conjunto de arquivos a outro de forma rápida e segura. Vamos desvendar como usar o patch de maneira simples e prática.
Entendendo os Comandos patch e diff
Imagine que você possui um arquivo de texto em seu computador e recebe uma versão modificada desse arquivo. Como transferir todas as alterações do arquivo modificado para o original de forma eficiente? É aqui que os comandos patch e diff entram em cena. Ambos estão disponíveis no Linux e em outros sistemas operacionais semelhantes ao Unix, como o macOS.
O comando diff analisa duas versões de um mesmo arquivo, identificando e listando as diferenças entre elas. Essas diferenças podem ser armazenadas em um arquivo, conhecido como arquivo de patch.
Por sua vez, o comando patch lê um arquivo de patch, interpretando seu conteúdo como um conjunto de instruções. Seguindo essas instruções, as alterações presentes no arquivo modificado são aplicadas no arquivo original.
Agora, imagine esse processo ocorrendo com um diretório inteiro de arquivos de texto, tudo de uma vez. Esse é o poder do patch.
Em algumas situações, você não recebe os arquivos modificados, mas apenas o arquivo de patch. Afinal, por que enviar dezenas de arquivos quando é possível enviar um único arquivo para download?
O que fazer com esse arquivo de patch para corrigir seus arquivos? Apesar de parecer um desafio, vamos guiá-lo através deste processo neste artigo.
O comando patch é bastante utilizado por profissionais que trabalham com código-fonte de software, mas sua funcionalidade se estende a qualquer conjunto de arquivos de texto, seja qual for sua finalidade.
Cenário Prático
Vamos trabalhar com um cenário onde temos um diretório chamado “work”, que contém dois outros diretórios: “working” e “latest”. O diretório “working” possui um conjunto de arquivos de código-fonte, enquanto “latest” contém a versão mais recente desses arquivos, alguns deles modificados.
O diretório “working” é uma cópia da versão atual dos arquivos de texto, servindo como uma espécie de backup.
Identificando as Diferenças
O comando diff é a ferramenta que revela as diferenças entre dois arquivos. Por padrão, ele exibe as linhas modificadas diretamente no terminal.
Vamos usar como exemplo um arquivo chamado “slang.c”. Compararemos a versão presente em “working” com a versão em “latest”.
A opção -u (unificado) instrui o diff a incluir algumas linhas de texto não modificadas antes e depois de cada seção alterada. Essas linhas são denominadas linhas de contexto e são cruciais para que o comando patch localize com precisão o ponto de cada alteração no arquivo original.
Ao fornecer os nomes dos arquivos, o diff sabe quais arquivos comparar. O arquivo original é listado primeiro, seguido pelo arquivo modificado. Veja o comando:
diff -u working/slang.c latest/slang.cO diff produz uma lista que detalha as diferenças entre os arquivos. Se fossem idênticos, nenhuma saída seria exibida. A existência de uma saída confirma que há diferenças entre as versões e que o arquivo original precisa ser corrigido com o patch.
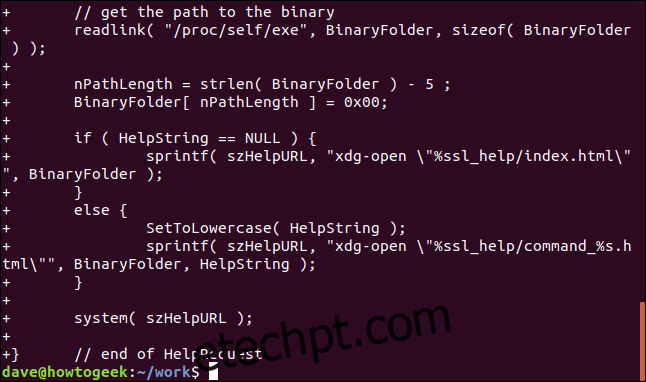
Criando um Arquivo de Patch
Para armazenar essas diferenças em um arquivo de patch, use o comando a seguir. É o mesmo comando anterior, mas com a saída do diff redirecionada para um arquivo chamado “slang.patch”:
diff -u working/slang.c latest/slang.c > slang.patch
O nome do arquivo de patch é arbitrário, você pode nomeá-lo como quiser. Atribuir a ele a extensão “.patch” é uma boa prática, pois torna o tipo de arquivo mais claro.
Para aplicar as alterações presentes no arquivo de patch ao arquivo “working/slang.c”, use o seguinte comando. A opção -u (unificado) informa ao patch que o arquivo de patch contém linhas de contexto unificadas. Ou seja, se usamos a opção -u com o diff, também devemos usá-la com o patch:
patch -u working/slang.c -i slang.patchSe tudo ocorrer corretamente, uma mensagem será exibida indicando que o patch está sendo aplicado ao arquivo.
Fazendo Backup do Arquivo Original
Podemos instruir o patch a criar um backup dos arquivos corrigidos antes de serem modificados, utilizando a opção -b (backup). A opção -i (entrada) especifica o nome do arquivo de patch a ser usado:
patch -u -b working/slang.c -i slang.patch
O arquivo é corrigido como antes, sem diferença visível na saída. No entanto, ao analisar o diretório de trabalho, você verá que um arquivo chamado “slang.c.orig” foi criado. Os registros de data e hora mostram que “slang.c.orig” é o arquivo original, enquanto “slang.c” é o novo arquivo criado pelo patch.

Utilizando diff com Diretórios
Podemos usar o diff para gerar um arquivo de patch que contenha todas as diferenças entre os arquivos em dois diretórios. Em seguida, usar esse arquivo de patch com o comando patch para aplicar essas diferenças aos arquivos no diretório de trabalho com um único comando.
As opções que usaremos com o diff são: -u (contexto unificado), que já utilizamos; -r (recursivo), para que o diff procure em todos os subdiretórios; e -N (novo arquivo).
A opção -N informa ao diff como lidar com arquivos presentes no diretório “latest” que não existem no diretório “working”. Ela força o diff a incluir instruções no arquivo de patch para que o patch crie os arquivos que estão presentes em “latest”, mas que estão ausentes em “working”.
É possível agrupar as opções usando um único hífen (-).
Note que fornecemos apenas os nomes dos diretórios, sem especificar arquivos:
diff -ruN working/ latest/ > slang.patch
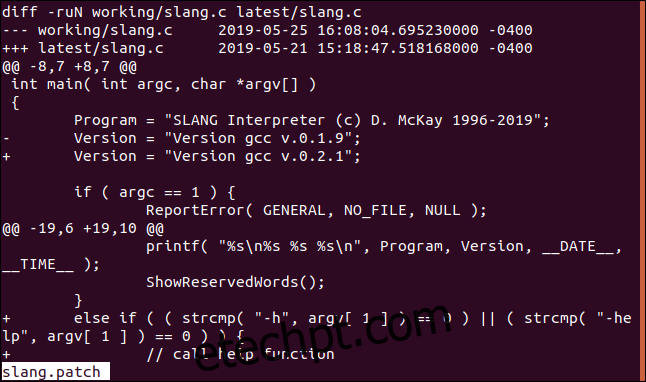
Analisando o Arquivo de Patch
Vamos analisar o arquivo de patch. Usaremos o comando less para examinar seu conteúdo.

A parte superior do arquivo mostra as diferenças entre as duas versões do arquivo “slang.c”.
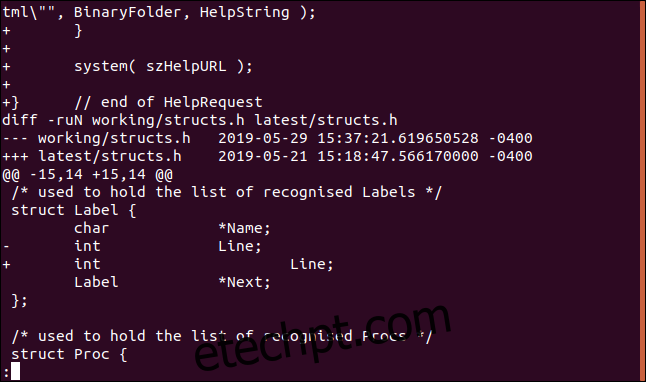
Ao navegar pelo arquivo de patch, vemos que ele descreve as alterações em outro arquivo, “structs.h”. Isso confirma que o arquivo de patch inclui as diferenças entre as versões de vários arquivos.
Verificação Antes da Aplicação
Aplicar um patch em um grande conjunto de arquivos pode ser um pouco preocupante. Por isso, vamos utilizar a opção --dry-run para verificar se está tudo certo antes de confirmar as alterações.
A opção --dry-run faz com que o patch simule todo o processo, exceto a modificação dos arquivos. O patch realizará todas as verificações prévias e, caso encontre problemas, os relatará. Os arquivos não serão modificados neste processo.
Se nenhum problema for reportado, podemos repetir o comando sem a opção --dry-run e aplicar os patches com segurança.
A opção -d (diretório) especifica o diretório de trabalho para o patch.
Observe que não estamos usando a opção -i (entrada) para especificar o arquivo de patch. Em vez disso, estamos redirecionando o arquivo de patch para o patch com <.
patch --dry-run -ruN -d working < slang.patch
Neste exemplo, o diff identificou dois arquivos para aplicar o patch. As instruções para essas modificações foram verificadas e nenhum problema foi detectado.
Com as verificações prévias realizadas, podemos aplicar o patch.
Aplicando o Patch a um Diretório
Para aplicar os patches aos arquivos, usamos o comando anterior sem a opção --dry-run:
patch -ruN -d working < slang.patch
Desta vez, cada linha de saída começa com “patching”, ao invés de “checking”.
E nenhum problema é reportado. Agora, podemos compilar nosso código fonte e teremos a versão mais recente do software.
Solucionando as Diferenças
Essa é, de longe, a maneira mais fácil e segura de usar o patch. Copie seus arquivos para uma pasta e aplique o patch nessa pasta. Em seguida, copie os arquivos de volta quando estiver certo de que o processo ocorreu sem erros.