Interessa-se por analisar dados usando linguagem natural? Descubra como fazê-lo com a biblioteca Python PandasAI.
Em um cenário onde os dados são cruciais, a capacidade de compreendê-los e analisá-los torna-se vital. No entanto, a análise de dados tradicional pode ser complexa. É aqui que o PandasAI se destaca. Ele simplifica a análise de dados, possibilitando a interação com os seus dados através de linguagem natural.
O PandasAI opera convertendo as suas questões em código para análise de dados. Ele é construído sobre a popular biblioteca Python pandas. PandasAI é uma biblioteca Python que expande as capacidades do pandas, a conhecida ferramenta de análise e manipulação de dados, com funcionalidades de IA generativa. O objetivo é complementar o pandas, não substituí-lo.
O PandasAI adiciona um elemento conversacional ao pandas (assim como a outras bibliotecas de análise de dados), permitindo interagir com os seus dados através de perguntas em linguagem natural.
Este tutorial irá guiá-lo através dos passos para configurar o PandasAI, utilizando-o com um conjunto de dados real, criando gráficos, explorando atalhos e analisando os pontos fortes e limitações desta ferramenta poderosa.
Após a conclusão, será capaz de conduzir análises de dados de forma mais fácil e intuitiva, utilizando linguagem natural.
Então, vamos explorar o fascinante mundo da análise de dados em linguagem natural com o PandasAI!
Configurando o seu ambiente
Para iniciar a utilização do PandasAI, primeiro terá que instalar a biblioteca PandasAI.
Para este projeto, estou a usar um Jupyter Notebook. No entanto, pode usar o Google Colab ou o VS Code, de acordo com as suas necessidades.
Se planeia usar modelos de linguagem grandes (LLMs) da OpenAI, é crucial também instalar o SDK Python da OpenAI para uma experiência mais suave.
# Installing Pandas AI !pip install pandas-ai # Pandas AI uses OpenAI's language models, so you need to install the OpenAI Python SDK !pip install openai
Agora, vamos importar todas as bibliotecas necessárias:
# Importing necessary libraries import pandas as pd import numpy as np # Importing PandasAI and its components from pandasai import PandasAI, SmartDataframe from pandasai.llm.openai import OpenAI
Um aspeto chave da análise de dados com o PandasAI é a chave API. Esta ferramenta oferece suporte para vários modelos de linguagem grande (LLMs) e modelos LangChains, que são usados para gerar código a partir de consultas em linguagem natural. Isto torna a análise de dados mais acessível e simples de usar.
O PandasAI é versátil e funciona com vários tipos de modelos, incluindo modelos Hugging Face, Azure OpenAI, Google PALM e Google VertexAI. Cada um destes modelos traz os seus próprios pontos fortes, melhorando as capacidades do PandasAI.
Lembre-se, para utilizar estes modelos, necessita das chaves API apropriadas. Estas chaves autenticam os seus pedidos e permitem que aproveite o poder destes modelos de linguagem avançada nas suas tarefas de análise de dados. Por isso, certifique-se de que tem as suas chaves API prontas ao configurar o PandasAI para os seus projetos.
Pode obter a chave API e exportá-la como uma variável de ambiente.
Na próxima etapa, aprenderá como usar o PandasAI com diferentes modelos de linguagem grande (LLMs) da OpenAI e do Hugging Face Hub.
Utilizando modelos de linguagem grandes
Pode selecionar um LLM instanciando um e passando-o para o construtor SmartDataFrame ou SmartDatalake, ou especificando um no arquivo pandasai.json.
Se o modelo necessitar de um ou mais parâmetros, pode passá-los para o construtor ou especificá-los no arquivo pandasai.json no parâmetro llm_options, como abaixo:
{
"llm": "OpenAI",
"llm_options": {
"api_token": "API_TOKEN_GOES_HERE"
}
}
Como usar modelos OpenAI?
Para usar modelos OpenAI, necessita de uma chave API OpenAI. Pode obter uma aqui.
Após obter a chave API, pode usá-la para instanciar um objeto OpenAI:
#We have imported all necessary libraries in privious step
llm = OpenAI(api_token="my-api-key")
pandas_ai = SmartDataframe("data.csv", config={"llm": llm})
Certifique-se de substituir “my-api-key” pela sua chave API original.
Em alternativa, pode definir a variável de ambiente OPENAI_API_KEY e instanciar o objeto OpenAI sem passar a chave API:
# Set the OPENAI_API_KEY environment variable
llm = OpenAI() # no need to pass the API key, it will be read from the environment variable
pandas_ai = SmartDataframe("data.csv", config={"llm": llm})
Se estiver por trás de um proxy explícito, pode especificar openai_proxy ao instanciar o objeto OpenAI ou definir a variável de ambiente OPENAI_PROXY para a passagem.
Nota importante: ao usar a biblioteca PandasAI para análise de dados com a sua chave API, é essencial monitorizar a utilização de tokens para gerir os custos.
Quer saber como? Basta executar o seguinte código de contador de tokens para ter uma imagem clara da utilização de tokens e das respetivas cobranças. Desta forma, pode gerir os seus recursos de forma eficaz e evitar surpresas na faturação.
Pode contar o número de tokens utilizados por um prompt da seguinte forma:
"""Example of using PandasAI with a pandas dataframe"""
from pandasai import SmartDataframe
from pandasai.llm import OpenAI
from pandasai.helpers.openai_info import get_openai_callback
import pandas as pd
llm = OpenAI()
# conversational=False is supposed to display lower usage and cost
df = SmartDataframe("data.csv", {"llm": llm, "conversational": False})
with get_openai_callback() as cb:
response = df.chat("Calculate the sum of the gdp of north american countries")
print(response)
print(cb)
Obterá resultados semelhantes a estes:
# The sum of the GDP of North American countries is 19,294,482,071,552. # Tokens Used: 375 # Prompt Tokens: 210 # Completion Tokens: 165 # Total Cost (USD): $ 0.000750
Lembre-se de manter um registo do custo total se tiver crédito limitado!
Como usar modelos Hugging Face?
Para usar modelos HuggingFace, necessita de uma chave API HuggingFace. Pode criar uma conta HuggingFace aqui e obter uma chave API aqui.
Após obter uma chave API, pode utilizá-la para instanciar um dos modelos HuggingFace.
Atualmente, o PandasAI oferece suporte para os seguintes modelos HuggingFace:
- Starcoder: bigcode/starcoder
- Falcon: tiiuae/falcon-7b-instruct
from pandasai.llm import Starcoder, Falcon
llm = Starcoder(api_token="my-huggingface-api-key")
# or
llm = Falcon(api_token="my-huggingface-api-key")
df = SmartDataframe("data.csv", config={"llm": llm})
Em alternativa, pode definir a variável de ambiente HUGGINGFACE_API_KEY e instanciar o objeto HuggingFace sem passar a chave API:
from pandasai.llm import Starcoder, Falcon
llm = Starcoder() # no need to pass the API key, it will be read from the environment variable
# or
llm = Falcon() # no need to pass the API key, it will be read from the environment variable
df = SmartDataframe("data.csv", config={"llm": llm})
Starcoder e Falcon são modelos LLM disponíveis no Hugging Face.
Configurámos o nosso ambiente com sucesso e explorámos como usar modelos OpenAI e Hugging Face LLMs. Vamos agora avançar na nossa jornada de análise de dados.
Usaremos o conjunto de dados Big Mart Sales, que contém informações sobre as vendas de vários produtos em diferentes pontos de venda do Big Mart. O conjunto de dados tem 12 colunas e 8.524 linhas. Receberá o link no final do artigo.
Análise de dados com PandasAI
Agora que instalámos e importámos com sucesso todas as bibliotecas necessárias, vamos carregar o nosso conjunto de dados.
Carregar o conjunto de dados
Pode selecionar um LLM instanciando um e passando-o para o SmartDataFrame. Receberá o link para o conjunto de dados no final do artigo.
#Load the dataset from device path = r"D:\Pandas AI\Train.csv" df = SmartDataframe(path)
Utilizar o modelo LLM da OpenAI
Após carregar os nossos dados, irei usar o modelo LLM da OpenAI para utilizar o PandasAI.
llm = OpenAI(api_token="API_Key") pandas_ai = PandasAI(llm, conversational=False)
Está tudo pronto! Agora, vamos experimentar usar prompts.
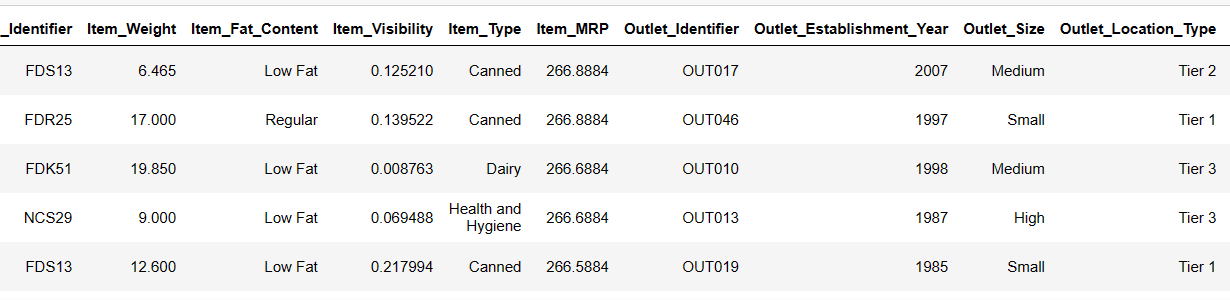
Imprimir as primeiras 6 linhas do nosso conjunto de dados
Vamos tentar carregar as primeiras 6 linhas, fornecendo instruções:
Result = pandas_ai(df, "Show the first 6 rows of data in tabular form") Result
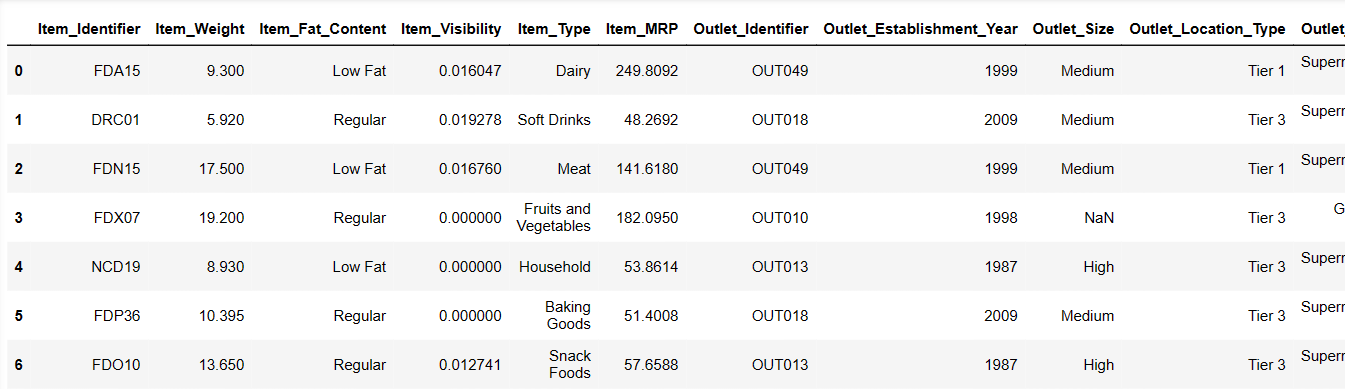 As primeiras 6 linhas do conjunto de dados
As primeiras 6 linhas do conjunto de dados
Isto foi muito rápido! Vamos compreender o nosso conjunto de dados.
Gerar estatísticas descritivas do DataFrame
# To get descriptive statistics Result = pandas_ai(df, "Show the description of data in tabular form") Result
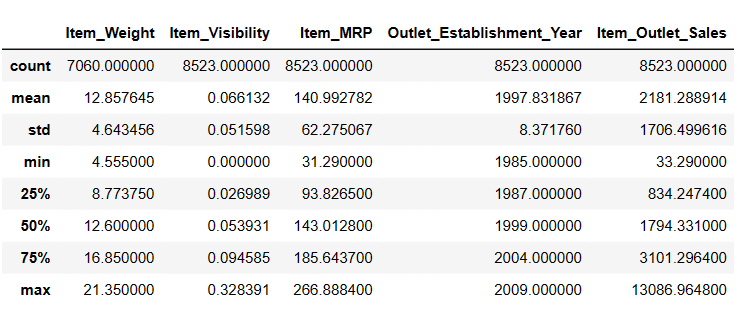 Descrição
Descrição
Existem 7.060 valores em Item_Weigth; talvez haja alguns valores em falta.
Encontrar valores em falta
Existem duas formas de encontrar valores em falta usando o pandas ai.
#Find missing values Result = pandas_ai(df, "Show the missing values of data in tabular form") Result
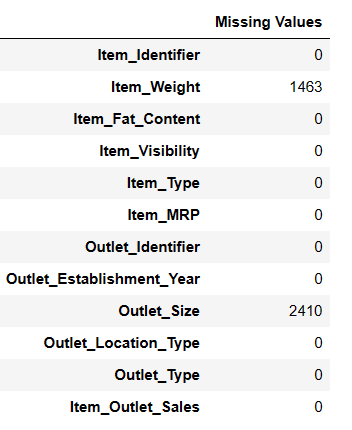 Encontrar valores em falta
Encontrar valores em falta
# Atalho para limpeza de dados
df = SmartDataframe('data.csv')
df.clean_data()
Este atalho irá limpar os dados no quadro de dados.
Agora, vamos preencher os valores nulos em falta.
Preencher os valores em falta
#Fill Missing values result = pandas_ai(df, "Fill Item Weight with median and Item outlet size null values with mode and Show the missing values of data in tabular form") result
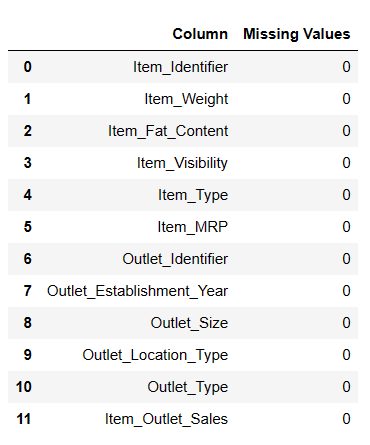 Valores nulos preenchidos
Valores nulos preenchidos
É um método útil para preencher valores nulos, mas enfrentei alguns problemas ao preencher valores nulos.
# Atalho para preencher valores nulos
df = SmartDataframe('data.csv')
df.impute_missing_values()
Este atalho imputará valores em falta no quadro de dados.
Remover valores nulos
Se pretende remover todos os valores nulos do seu df, pode tentar este método.
result = pandas_ai(df, "Drop the row with missing values with inplace=True") result
A análise de dados é essencial para identificar tendências, tanto de curto como de longo prazo, que podem ser inestimáveis para empresas, governos, investigadores e indivíduos.
Vamos tentar encontrar uma tendência geral de vendas ao longo dos anos desde a sua criação.
Encontrar tendências de vendas
# finding trend in sales result = pandas_ai(df, "What is the overall trend in sales over the years since outlet establishment?") result
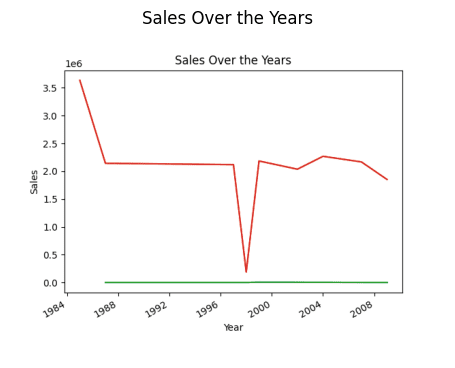 Vendas ao longo do ano (gráfico de linhas)
Vendas ao longo do ano (gráfico de linhas)
O processo inicial de criação do gráfico foi um pouco lento, mas depois de reiniciar o kernel e executar tudo novamente, ficou mais rápido.
# Atalho para traçar gráficos de linhas
df.plot_line_chart(x = ['a', 'b', 'c'], y = [1, 2, 3])
Este atalho irá traçar um gráfico de linhas do quadro de dados.
Pode estar a questionar-se por que existe um declínio na tendência. É porque não temos dados de 1989 a 1994.
Encontrar o ano de maiores vendas
Agora, vamos descobrir qual o ano com as maiores vendas.
# finding year of highest sales result = pandas_ai(df, "Explain which years have highest sales") result

Por isso, o ano com maiores vendas é 1985.
No entanto, quero descobrir qual o tipo de item que gera a maior média de vendas e qual o tipo que gera a menor média de vendas.
Vendas médias mais altas e mais baixas
# finding highest and lowest average sale result = pandas_ai(df, "Which item type generates the highest average sales, and which one generates the lowest?") result

Os alimentos ricos em amido (Starchy Foods) têm as vendas médias mais altas e Outros têm as vendas médias mais baixas. Se não quiser que Outros tenham as vendas mais baixas, pode refinar o prompt de acordo com as suas necessidades.
Excelente! Agora, quero descobrir a distribuição de vendas nos diferentes pontos de venda.
Distribuição de vendas em diferentes pontos de venda
Existem quatro tipos de pontos de venda: Supermercado Tipo 1/2/3 e Mercearias.
# distribution of sales across different outlet types since establishment response = pandas_ai(df, "Visualize the distribution of sales across different outlet types since establishment using bar plot, plot size=(13,10)") response
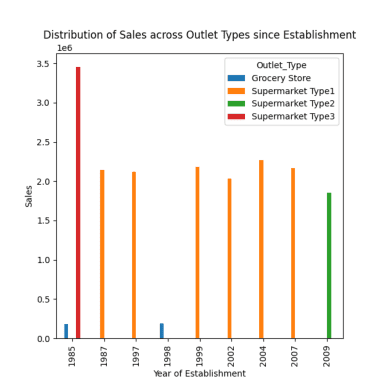 Distribuição das vendas em diferentes pontos de venda
Distribuição das vendas em diferentes pontos de venda
Conforme observado nas instruções anteriores, o pico de vendas ocorreu em 1985, e este gráfico destaca as vendas mais altas em 1985 nos supermercados tipo 3.
# Atalho para traçar gráficos de barras
df = SmartDataframe('data.csv')
df.plot_bar_chart(x = ['a', 'b', 'c'], y = [1, 2, 3])
Este atalho irá traçar um gráfico de barras do quadro de dados.
# Atalho para traçar histograma
df = SmartDataframe('data.csv')
df.plot_histogram(column = 'a')
Este atalho irá traçar um histograma do quadro de dados.
Agora, vamos descobrir quais são as vendas médias dos itens com teor de gordura ‘Low Fat’ e ‘Regular’.
Encontrar as vendas médias para itens com teor de gordura
# finding index of a row using value of a column result = pandas_ai(df, "What is the average sales for the items with 'Low Fat' and 'Regular' item fat content?") result
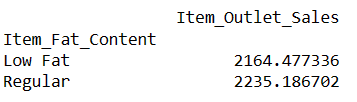
Escrever prompts como este permite comparar dois ou mais produtos.
Vendas médias para cada tipo de item
Quero comparar todos os produtos com as respetivas vendas médias.
#Average Sales for Each Item Type result = pandas_ai(df, "What are the average sales for each item type over the past 5 years?, use pie plot, size=(6,6)") result
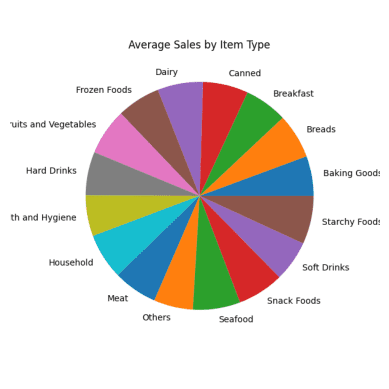 Gráfico circular da média de vendas
Gráfico circular da média de vendas
Todas as secções do gráfico circular parecem semelhantes porque têm praticamente os mesmos números de vendas.
# Atalho para traçar gráficos circulares
df.plot_pie_chart(labels = ['a', 'b', 'c'], values = [1, 2, 3])
Este atalho irá traçar um gráfico circular do quadro de dados.
Os 5 tipos de itens mais vendidos
Embora já tenhamos comparado todos os produtos com base nas vendas médias, agora gostaria de identificar os 5 itens com maiores vendas.
#Finding top 5 highest selling items result = pandas_ai(df, "What are the top 5 highest selling item type based on average sells? Write in tablular form") result
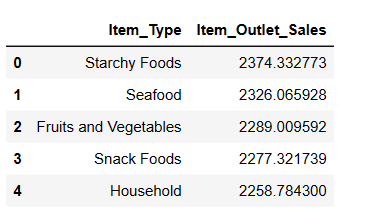
Como esperado, os alimentos ricos em amido são o item mais vendido com base nas vendas médias.
Os 5 tipos de itens menos vendidos
result = pandas_ai(df, "What are the top 5 lowest selling item type based on average sells?") result
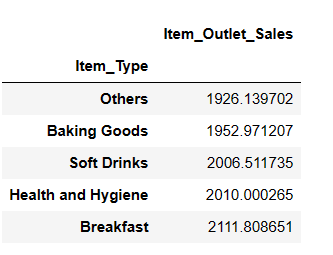
Pode ser surpreendente ver os refrigerantes na categoria de menor venda. No entanto, é fundamental notar que estes dados só vão até 2008 e que a tendência dos refrigerantes disparou alguns anos depois.
Vendas de categorias de produtos
Aqui, usei a palavra “categoria de produto” em vez de “tipo de item”, e o PandasAI ainda gerou os gráficos, mostrando a sua compreensão de palavras semelhantes.
result = pandas_ai(df, "Give a stacked large size bar chart of the sales of the various product categories for the last FY") result
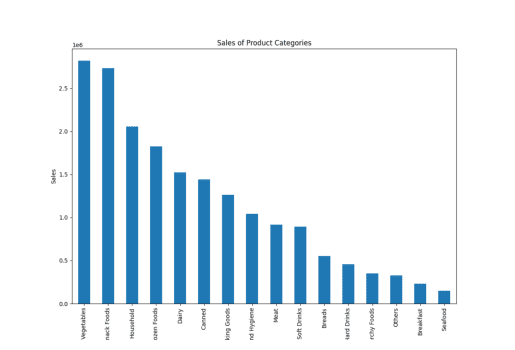 Vendas do tipo de item
Vendas do tipo de item
Pode encontrar os restantes atalhos aqui.
Pode notar que quando escreve um prompt e fornece instruções a um PandasAI, este fornece resultados com base unicamente nesse prompt específico. Ele não analisa os seus pedidos anteriores para oferecer respostas mais precisas.
No entanto, com a ajuda de um agente de chat, pode também obter essa funcionalidade.
Agente de chat
Com o agente de chat, pode participar em conversas dinâmicas, nas quais o agente retém o contexto ao longo da discussão. Isto permite ter trocas mais interativas e significativas.
Os principais recursos que potenciam esta interação incluem a retenção de contexto, onde o agente se lembra do histórico da conversa, permitindo interações contínuas e conscientes do contexto. Pode utilizar o método de perguntas de esclarecimento para solicitar explicações sobre qualquer aspeto da conversa, garantindo a compreensão total das informações fornecidas.
Além disso, o método explicar está disponível para obter explicações detalhadas sobre como o agente chegou a uma determinada solução ou resposta, oferecendo transparência e insights sobre o processo de tomada de decisão do agente.
Sinta-se à vontade para iniciar conversas, procurar esclarecimentos e explorar explicações para aprimorar as suas interações com o agente de chat!
from pandasai import Agent
agent = Agent(df, config={"llm": llm}, memory_size=10)
result = agent.chat("Which are top 5 items with highest MRP")
result
Ao contrário de um SmartDataframe ou SmartDatalake, um agente irá monitorizar o estado da conversa e será capaz de responder a várias conversas.
Vamos avançar em direção às vantagens e limitações do PandasAI
Vantagens do PandasAI
A utilização do Pandas AI oferece várias vantagens que o tornam uma ferramenta valiosa para a análise de dados, tais como:
- Acessibilidade: o PandasAI simplifica a análise de dados, tornando-os acessíveis a uma vasta gama de utilizadores. Qualquer pessoa, independentemente da sua formação técnica, pode usá-lo para extrair insights de dados e responder a questões de negócios.
- Consultas em linguagem natural: a capacidade de fazer perguntas diretamente e receber respostas de dados usando consultas em linguagem natural torna a exploração e análise de dados mais fácil de usar. Este recurso permite que até mesmo utilizadores não técnicos interajam com os dados de forma eficaz.
- Funcionalidade de chat do agente: a função de chat permite que os utilizadores interajam com os dados de forma interativa, enquanto o recurso de chat do agente aproveita o histórico de chat anterior para fornecer respostas com base no contexto. Isto promove uma abordagem dinâmica e conversacional para a análise de dados.
- Visualização de dados: o PandasAI oferece uma variedade de opções de visualização de dados, incluindo mapas de calor, gráficos de dispersão, gráficos de barras, gráficos circulares, gráficos de linhas e muito mais. Estas visualizações ajudam a compreender e apresentar padrões e tendências dos dados.
- Atalhos que economizam tempo: A disponibilidade de atalhos e recursos que economizam tempo agiliza o processo de análise de dados, ajudando os utilizadores a trabalhar com mais eficiência e eficácia.
- Compatibilidade de arquivos: o PandasAI oferece suporte a vários formatos de arquivo, incluindo CSV, Excel, folhas de cálculo Google e muito mais. Esta flexibilidade permite que os utilizadores trabalhem com dados de diversas fontes e formatos.
- Prompts personalizados: os utilizadores podem criar prompts personalizados usando instruções simples e código Python. Este recurso permite que os utilizadores adaptem as suas interações com os dados para satisfazer necessidades e consultas específicas.
- Salvar alterações: a capacidade de salvar as alterações feitas em quadros de dados garante que o seu trabalho é preservado e que pode revisitar e partilhar a sua análise a qualquer momento.
- Respostas personalizadas: a opção de criar respostas personalizadas permite que os utilizadores definam comportamentos ou interações específicas, tornando a ferramenta ainda mais versátil.
- Integração de modelos: o PandasAI suporta vários modelos de linguagem, incluindo os modelos Hugging Face, Azure, Google Palm, Google VertexAI e LangChain. Esta integração melhora as capacidades da ferramenta e permite o processamento e compreensão avançados da linguagem natural.
- Suporte LangChain integrado: o suporte integrado para modelos LangChain expande ainda mais a gama de modelos e funcionalidades disponíveis, aumentando a profundidade da análise e dos insights que podem ser derivados dos dados.
- Compreender nomes: o PandasAI demonstra a capacidade de compreender a correlação entre nomes de colunas e terminologia da vida real. Por exemplo, mesmo que use termos como “categoria de produto” em vez de “tipo de item” nas suas solicitações, a ferramenta ainda será capaz de fornecer resultados relevantes e precisos. Esta flexibilidade no reconhecimento de sinónimos e no seu mapeamento para as colunas de dados apropriadas melhora a conveniência do utilizador e a adaptabilidade da ferramenta a consultas em linguagem natural.
Embora o PandasAI ofereça várias vantagens, também apresenta algumas limitações e desafios dos quais os utilizadores devem estar conscientes:
Limitações do PandasAI
Aqui estão algumas limitações que observei:
- Requisito de chave API: para usar o PandasAI, é essencial ter uma chave API. Se não tiver créditos suficientes na sua conta OpenAI, poderá não conseguir utilizar o serviço. No entanto, é importante notar que a OpenAI oferece um crédito de 5 dólares para novos utilizadores, o que o torna acessível para aqueles que são novos na plataforma.
- Tempo de processamento: por vezes, o serviço pode sofrer atrasos no fornecimento de resultados, o que pode ser atribuído à elevada utilização ou carga do servidor. Os utilizadores devem estar preparados para possíveis tempos de espera ao consultar o serviço.
- Interpretação de instruções: embora possa fazer perguntas através de instruções, a capacidade do sistema de explicar as respostas pode não estar totalmente desenvolvida e a qualidade das explicações pode variar. Este aspeto do PandasAI poderá melhorar no futuro com mais desenvolvimento.
- Sensibilidade de prompts: os utilizadores precisam de ter cuidado ao criar os prompts, pois mesmo pequenas alterações podem levar a resultados diferentes. Esta sensibilidade ao fraseado e à estrutura de prompts pode afetar a consistência dos resultados, especialmente ao trabalhar com gráficos de dados ou consultas mais complexas.
- Limitações em prompts complexos: O PandasAI pode não lidar com prompts ou consultas altamente complexas com a mesma eficácia que os mais simples. Os utilizadores devem estar atentos à complexidade das suas questões e certificar-se de que a ferramenta é adequada às suas necessidades específicas.
- Alterações inconsistentes no DataFrame: os utilizadores relataram problemas ao fazer alterações em DataFrames, como preencher valores nulos ou eliminar linhas de valores nulos, mesmo ao especificar ‘Inplace = True’. Esta inconsistência pode ser frustrante para os utilizadores que tentam modificar os seus dados.
- Resultados variáveis: ao reiniciar um kernel ou executar novamente prompts, é possível receber resultados ou interpretações de dados diferentes de execuções anteriores. Esta variabilidade pode ser um desafio para os utilizadores que necessitam de resultados consistentes e reproduzíveis. Não é aplicável a todos os prompts.
Pode descarregar o conjunto de dados aqui.
O código está disponível em GitHub.
Conclusão
O PandasAI oferece uma abordagem amigável para a análise de dados, acessível até mesmo para aqueles que não têm grandes habilidades de programação.
Neste artigo, abordei como configurar e usar o PandasAI para análise de dados, incluindo a criação de gráficos, o tratamento de valores nulos e o aproveitamento da funcionalidade de chat do agente.
Assine a nossa newsletter para artigos mais informativos. Pode estar interessado em aprender sobre modelos de IA para criar IA generativa.
Este artigo foi útil?
Obrigado pelo seu feedback!