A coleta de dados, também conhecida como extração de dados, refere-se ao processo de obter informações específicas de páginas da web. Usuários podem coletar diversos tipos de dados, como texto, imagens, vídeos, análises e informações de produtos. Essa prática é valiosa para pesquisas de mercado, análises de sentimento, estudos da concorrência e agregação de dados.
Para pequenos volumes de dados, a coleta manual, por meio de copiar e colar informações de sites para planilhas ou documentos, pode ser suficiente. Por exemplo, um cliente que busca avaliações online para auxiliar em uma decisão de compra pode coletar esses dados manualmente.
No entanto, quando se trata de grandes conjuntos de dados, a coleta manual se torna impraticável, exigindo técnicas automatizadas. Isso pode envolver o desenvolvimento de uma solução interna ou o uso de APIs de proxy ou scraping.
Essas abordagens podem enfrentar desafios, pois muitos sites implementam proteções como captchas. Além disso, o gerenciamento de bots e proxies pode consumir tempo e recursos, limitando a quantidade e a natureza dos dados que podem ser coletados.
O Navegador de Scraping: Uma Solução Eficaz
Para superar esses obstáculos, o Navegador de Scraping da Bright Data se apresenta como uma solução abrangente. Essa ferramenta facilita a coleta de dados de sites complexos. Trata-se de um navegador com interface gráfica (GUI), controlado pelas APIs Puppeteer ou Playwright, o que o torna indetectável por bots.
O Navegador de Scraping incorpora mecanismos de desbloqueio que lidam automaticamente com bloqueios. Ao ser executado em servidores da Bright Data, elimina a necessidade de infraestrutura interna dispendiosa para projetos de larga escala.
Funcionalidades do Navegador de Scraping da Bright Data
- Desbloqueio automático de sites: O navegador ajusta-se automaticamente para lidar com a resolução de CAPTCHA, bloqueios, impressões digitais e novas tentativas, simulando um usuário real.
- Ampla rede de proxies: Com mais de 72 milhões de IPs, é possível direcionar qualquer país, cidade ou operadora, utilizando tecnologia de ponta.
- Escalabilidade: A infraestrutura da Bright Data permite abrir milhares de sessões simultaneamente, lidando com todas as solicitações de forma eficiente.
- Compatibilidade com Puppeteer e Playwright: É possível realizar chamadas de API e gerenciar múltiplas sessões usando Puppeteer (Python) ou Playwright (Node.js).
- Economia de tempo e recursos: O navegador de scraping gerencia proxies e infraestrutura em segundo plano, eliminando a necessidade de configurações manuais.
Configuração do Navegador de Scraping
- Acesse o site da Bright Data e encontre o Scraping Browser na aba “Soluções de Scraping”.
- Crie sua conta. Escolha entre “Iniciar avaliação gratuita” ou “Iniciar gratuitamente com o Google”. Optaremos por “Iniciar avaliação gratuita” para este exemplo. A criação pode ser manual ou via conta Google.
- Após criar sua conta, o painel apresentará diversas opções. Selecione “Infraestrutura de Proxies e Scraping”.
- Na nova janela, escolha Scraping Browser e clique em “Começar”.
- Salve e ative suas configurações.
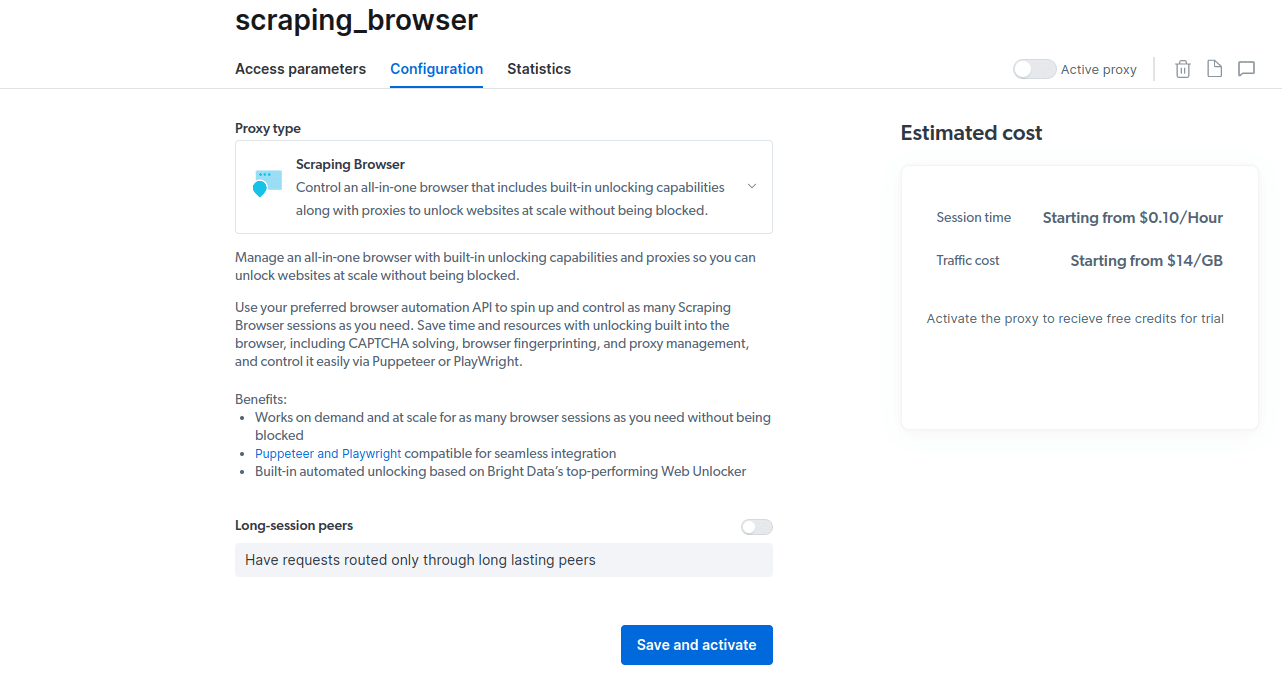
- Ative seu período de testes. A primeira opção oferece US$ 5 de crédito para uso de proxy. Caso pretenda um uso mais intenso, a segunda opção oferece US$ 50 de crédito ao carregar sua conta com US$ 50 ou mais.
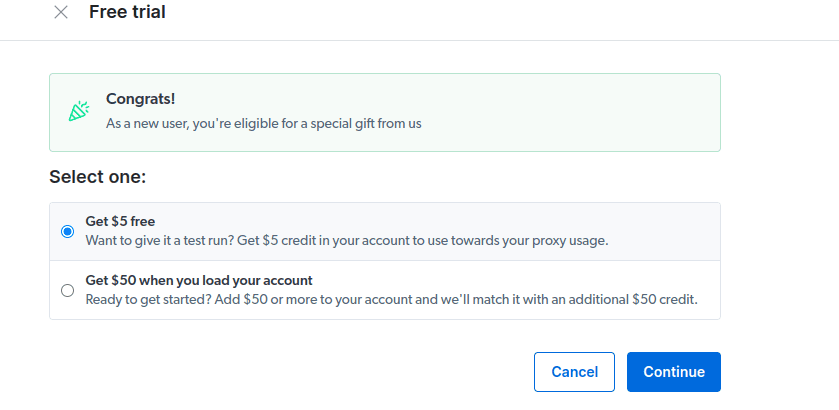
- Insira seus dados de faturamento. Não se preocupe, pois não haverá cobrança. Os dados são para confirmar que você é um novo usuário e não está tentando criar múltiplas contas para aproveitar o período de teste gratuito.
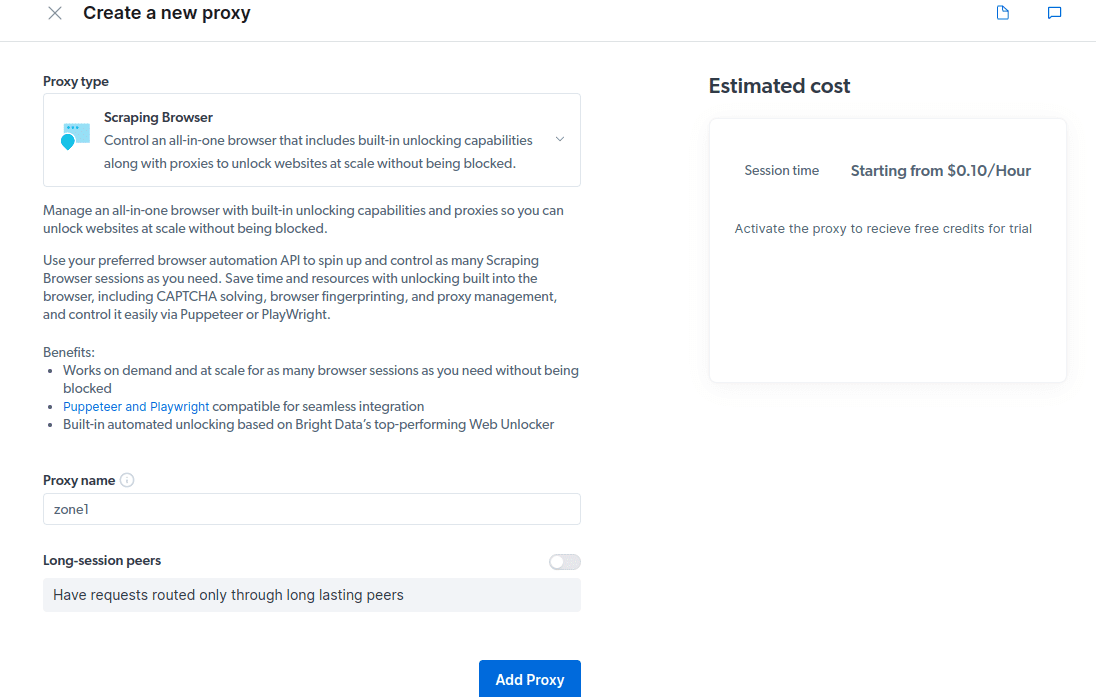
- Crie um novo proxy. Após salvar os dados de faturamento, clique no ícone “adicionar” e selecione Scraping Browser como “tipo de proxy”. Clique em “Adicionar proxy” para continuar.
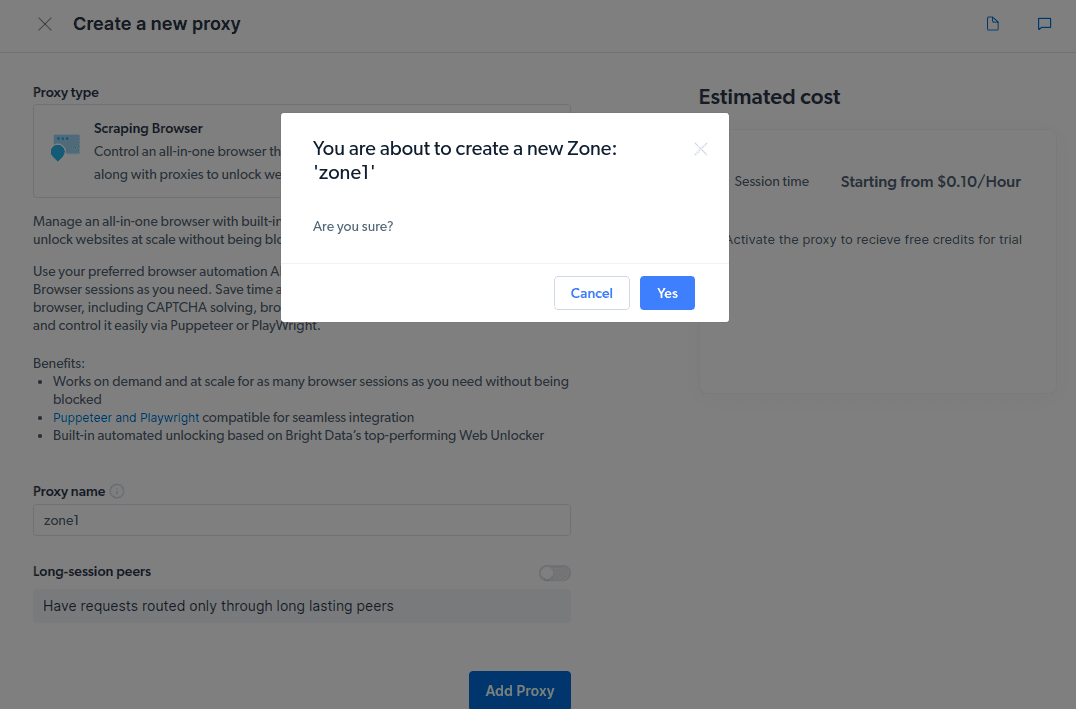
- Crie uma nova “zona”. Um pop-up perguntará se deseja criar uma nova zona, clique em “Sim”.
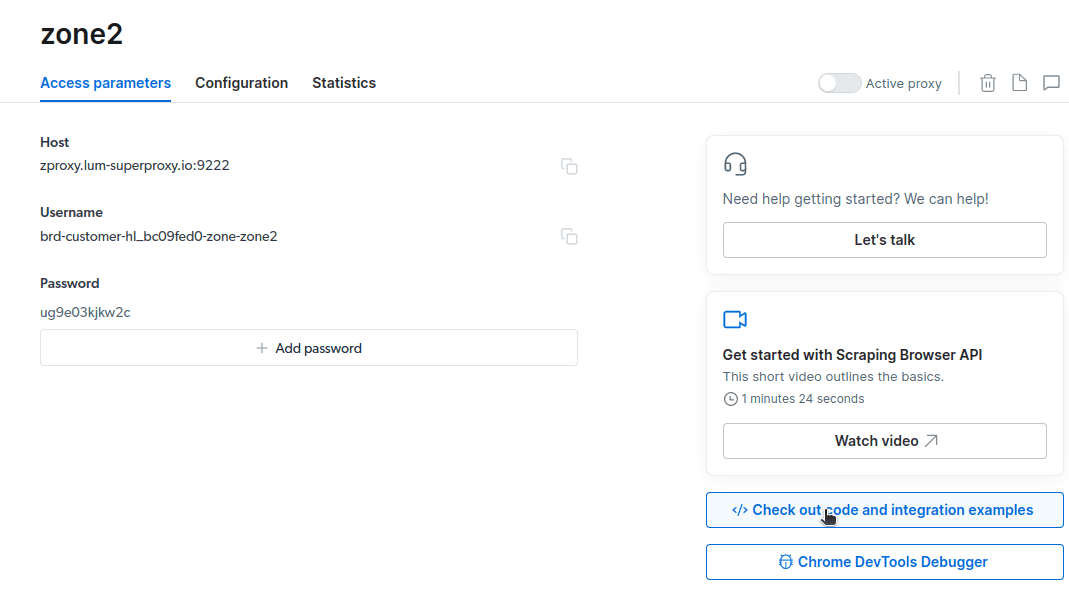
- Clique em “Confira exemplos de código e integração”. Aqui você encontrará exemplos para integrar o proxy para coleta de dados. Você pode usar Node.js ou Python.
Agora você tem tudo para coletar dados de um site. Usaremos etechpt.com.com para exemplificar o funcionamento do Scraping Browser, utilizando node.js. Você pode acompanhar se tiver o node.js instalado.
Siga estes passos:
const puppeteer = require('puppeteer-core');
const auth="USERNAME:PASSWORD";
async function run(){
let browser;
try {
browser = await puppeteer.connect({browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222`});
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2*60*1000);
await page.goto('https://example.com');
const html = await page.evaluate(() => document.documentElement.outerHTML);
console.log(html);
}
catch(e) {
console.error('run failed', e);
}
finally {
await browser?.close();
}
}
if (require.main==module)
run();
Altere a linha 10 do código para:
await page.goto(‘https://etechpt.com.com/authors/‘);
O código final será:
const puppeteer = require('puppeteer-core');
const auth="brd-customer-hl_bc09fed0-zone-zone2:ug9e03kjkw2c";
async function run(){
let browser;
try {
browser = await puppeteer.connect({browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222`});
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2*60*1000);
await page.goto('https://etechpt.com.com/authors/');
const html = await page.evaluate(() => document.documentElement.outerHTML);
console.log(html);
}
catch(e) {
console.error('run failed', e);
}
finally {
await browser?.close();
}
}
if (require.main==module)
run();
node script.js
Você verá o HTML da página no seu terminal.
Como Exportar os Dados
Os dados podem ser exportados de diversas formas. Para este exemplo, vamos exportar para um arquivo HTML chamado data.html, em vez de exibir no console.
Altere o código para:
const puppeteer = require('puppeteer-core');
const fs = require('fs');
const auth="brd-customer-hl_bc09fed0-zone-zone2:ug9e03kjkw2c";
async function run() {
let browser;
try {
browser = await puppeteer.connect({ browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222` });
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2 * 60 * 1000);
await page.goto('https://etechpt.com.com/authors/');
const html = await page.evaluate(() => document.documentElement.outerHTML);
fs.writeFileSync('data.html', html);
console.log('Data export complete.');
} catch (e) {
console.error('run failed', e);
} finally {
await browser?.close();
}
}
if (require.main == module) {
run();
}
Execute o código com o comando:
node script.js
O terminal exibirá a mensagem “Data export complete.”
Na pasta do projeto, um arquivo data.html será criado com o código HTML da página.
Este exemplo ilustra o básico do uso do Navegador de Scraping. É possível refinar o processo para coletar apenas dados específicos, como nomes e descrições dos autores.
Para usar o Navegador de Scraping, identifique os dados desejados e ajuste o código conforme necessário. É possível extrair texto, imagens, vídeos, metadados e links, dependendo da estrutura HTML do site.
Perguntas Frequentes
A coleta de dados e o web scraping são legais?
A legalidade do web scraping é um tema controverso. A legalidade dependerá da natureza dos dados coletados e das políticas do site de destino. Coletar dados pessoais, como endereços e informações financeiras, é geralmente considerado ilegal. Verifique as diretrizes do site antes de coletar dados, e evite coletar informações não disponíveis publicamente.
O Navegador de Scraping é gratuito?
Não, o Navegador de Scraping é um serviço pago. O período de teste oferece um crédito de US$ 5. Os planos pagos começam em US$ 15/GB + US$ 0,1/h, e a opção Pay As You Go começa em US$ 20/GB + US$ 0,1/h.
Qual a diferença entre navegadores de scraping e navegadores headless?
O Navegador de Scraping possui uma interface gráfica (GUI). Navegadores headless não possuem GUI, e são usados para automatizar o web scraping. No entanto, navegadores headless, como o Selenium, podem ter dificuldades com CAPTCHAs e detecção de bots.
Conclusão
O Navegador de Scraping simplifica a coleta de dados de sites, sendo mais simples de usar do que ferramentas como o Selenium. Mesmo quem não é desenvolvedor pode utilizar a ferramenta, graças à sua interface amigável e documentação detalhada. Os recursos de desbloqueio do navegador o tornam eficiente para todos que desejam automatizar processos de coleta de dados.
Você também pode pesquisar sobre como impedir que plugins de ChatGPT coletem dados de seu site.