Desvendando o Mundo do Big Data: Uma Análise de Apache Hive e Impala
Se você está começando a explorar o universo da análise de big data, é provável que o conjunto de ferramentas Apache tenha chamado sua atenção. No entanto, a vasta gama de opções disponíveis pode gerar confusão e, por vezes, sobrecarga.
Este artigo tem como objetivo esclarecer essa confusão, explicando o que são o Apache Hive e o Impala, bem como as principais diferenças entre eles.
Apache Hive: Uma Interface SQL para Hadoop
O Apache Hive é uma ferramenta que oferece uma interface de acesso a dados baseada em SQL para a plataforma Apache Hadoop. Com o Hive, é possível consultar, agregar e analisar dados usando a sintaxe SQL.
O Hive emprega um esquema de leitura na hora para dados armazenados no sistema de arquivos HDFS, permitindo que você trate os dados como se fossem tabelas comuns em um Sistema de Gerenciamento de Banco de Dados (SGBD) relacional. As consultas escritas em HiveQL são convertidas em código Java para serem executadas como tarefas MapReduce.
A linguagem de consulta utilizada pelo Hive é o HiveQL, que se assemelha ao SQL, embora não ofereça suporte completo ao padrão SQL-92.
No entanto, o HiveQL oferece aos programadores a flexibilidade de usar suas próprias consultas quando os recursos nativos do HiveQL se mostrarem inadequados ou ineficientes. Além disso, o HiveQL pode ser expandido com funções escalares definidas pelo usuário (UDFs), agregações (UDAFs) e funções de tabela (UDTFs).
Como o Apache Hive Funciona
O Apache Hive traduz os programas escritos em HiveQL (uma linguagem próxima ao SQL) em uma ou mais tarefas MapReduce, Apache Tez ou Apache Spark. Esses são os três motores de execução que podem ser utilizados no Hadoop. Em seguida, o Hive organiza os dados em uma estrutura para o Hadoop Distributed File System (HDFS), onde as tarefas serão executadas em cluster para gerar uma resposta.
As tabelas no Apache Hive são semelhantes às de um banco de dados relacional, com os dados organizados da unidade mais significativa para a mais granular. Os bancos de dados são estruturas compostas por partições, que podem ser subdivididas em “buckets”.
Os dados são acessados através de consultas HiveQL. Dentro de cada banco de dados, os dados são organizados e cada tabela corresponde a um diretório no HDFS.
A arquitetura do Apache Hive oferece diversas interfaces, como uma interface web, CLI (interface de linha de comando) e clientes externos.
O servidor “Apache Hive Thrift” permite que clientes remotos enviem comandos e solicitações ao Apache Hive usando diversas linguagens de programação. O diretório central do Apache Hive é o “metastore”, que armazena todas as informações.
O mecanismo que impulsiona o funcionamento do Hive é o “driver”, que incorpora um compilador e um otimizador para determinar o plano de execução ideal.
A segurança é garantida pelo Hadoop, que utiliza o Kerberos para autenticação mútua entre cliente e servidor. As permissões para novos arquivos criados no Hive são regidas pelo HDFS, permitindo autorização por usuário, grupo ou outros mecanismos.
Características do Hive
- Suporta os mecanismos de computação Hadoop e Spark
- Utiliza o HDFS e funciona como um data warehouse
- Emprega MapReduce e oferece suporte a ETL
- Possui tolerância a falhas similar ao Hadoop, devido ao uso do HDFS
Benefícios do Apache Hive
O Apache Hive se destaca como uma solução ideal para consultas e análise de dados, proporcionando insights de qualidade que podem gerar vantagens competitivas e aumentar a capacidade de resposta às demandas do mercado.
Entre as principais vantagens do Apache Hive, podemos citar a facilidade de uso, impulsionada pela sua linguagem “amigável ao SQL”. Além disso, agiliza a inserção inicial dos dados, eliminando a necessidade de leitura ou organização dos dados em um formato de banco de dados interno.
Como os dados são armazenados no HDFS, o Hive permite armazenar grandes conjuntos de dados, chegando a centenas de petabytes. Essa solução oferece uma escalabilidade muito superior à de um banco de dados tradicional. Além disso, como um serviço em nuvem, o Apache Hive permite que os usuários iniciem servidores virtuais rapidamente, adaptando-se às flutuações nas cargas de trabalho.
A segurança também é um ponto forte do Hive, com sua capacidade de replicar cargas de trabalho críticas para recuperação em caso de problemas. Por fim, sua capacidade de processamento é notável, suportando até 100.000 solicitações por hora.
Apache Impala: Consultas SQL em Tempo Real no Hadoop
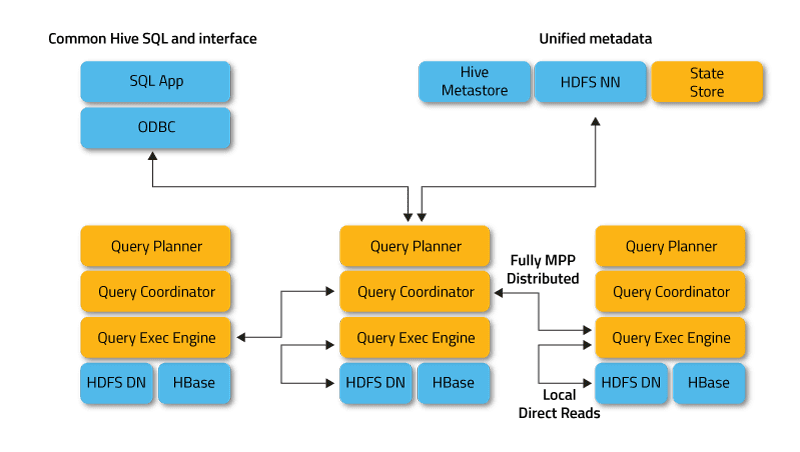
O Apache Impala é um mecanismo de consulta SQL massivamente paralelo, projetado para executar consultas SQL de forma interativa sobre dados armazenados no Apache Hadoop. Ele é escrito em C++ e distribuído sob a licença Apache 2.0.
O Impala também é conhecido como mecanismo MPP (processamento massivamente paralelo), SGBD distribuído e até mesmo banco de dados SQL-on-Hadoop.

O Impala opera em modo distribuído, com instâncias de processo sendo executadas em diferentes nós do cluster, recebendo, agendando e coordenando as solicitações dos clientes. Isso permite a execução paralela de fragmentos de consultas SQL.
Os clientes, como usuários e aplicativos, enviam consultas SQL para dados armazenados no Apache Hadoop (HBase e HDFS) ou Amazon S3. A interação com o Impala pode ser feita através da interface web HUE (Hadoop User Experience), ODBC, JDBC e o shell de linha de comando do Impala Shell.
O Impala depende da infraestrutura de outra ferramenta SQL-on-Hadoop popular, o Apache Hive, utilizando seu metastore. O Hive Metastore permite que o Impala conheça a disponibilidade e estrutura dos bancos de dados.
Ao criar, modificar ou excluir objetos de esquema ou ao carregar dados em tabelas por meio de instruções SQL, as alterações correspondentes nos metadados são propagadas automaticamente para todos os nós do Impala, utilizando um serviço de diretório especializado.
Os principais componentes do Impala são:
- Impalad ou daemon Impala: um serviço de sistema que agenda e executa consultas sobre dados em HDFS, HBase e Amazon S3. Um processo impalad é executado em cada nó do cluster.
- Statestore: um serviço de nomenclatura que rastreia a localização e o status de todas as instâncias impalad no cluster. Uma instância desse serviço é executada em cada nó e no servidor principal (Nó de Nome).
- Catálogo: um serviço de coordenação de metadados que propaga as alterações provenientes de instruções Impala DDL e DML para todos os nós Impala afetados. Isso garante que novas tabelas ou dados recém-carregados fiquem imediatamente visíveis para qualquer nó do cluster. É recomendado que uma instância do Catálogo seja executada no mesmo host do daemon Statestored.
Como o Apache Impala Funciona
Assim como o Apache Hive, o Impala utiliza uma linguagem de consulta declarativa semelhante, o Hive Query Language (HiveQL), que é um subconjunto do SQL92, e não o SQL completo.
A execução real de uma solicitação no Impala ocorre da seguinte forma:
O aplicativo cliente envia uma consulta SQL, conectando-se a qualquer impalad através de interfaces de driver ODBC ou JDBC padronizadas. O impalad conectado se torna o coordenador da solicitação atual.
A consulta SQL é analisada para determinar as tarefas para as instâncias impalad no cluster. Em seguida, é construído o plano de execução de consulta ideal.
O Impalad acessa diretamente o HDFS e o HBase utilizando instâncias locais de serviços do sistema para obter os dados. Ao contrário do Apache Hive, essa interação direta economiza tempo de execução, pois os resultados intermediários não são armazenados.
Em seguida, cada daemon retorna os dados para o impalad coordenador, que envia os resultados de volta para o cliente.
Características do Impala
- Suporte a processamento em memória em tempo real
- Compatível com SQL
- Suporta sistemas de armazenamento como HDFS, Apache HBase e Amazon S3
- Suporta integração com ferramentas de BI, como Pentaho e Tableau
- Utiliza a sintaxe HiveQL
Benefícios do Apache Impala
O Impala evita sobrecargas de inicialização, pois todos os processos daemon do sistema são iniciados no momento da inicialização. Isso resulta em uma significativa economia de tempo de execução das consultas. O aumento na velocidade do Impala se deve também ao fato de que, ao contrário do Hive, essa ferramenta SQL para Hadoop não armazena resultados intermediários e acessa diretamente o HDFS ou HBase.
Além disso, o Impala gera o código do programa em tempo de execução, e não na compilação, como faz o Hive. No entanto, uma consequência do alto desempenho do Impala é uma menor confiabilidade.
Em particular, se um nó de dados falhar durante a execução de uma consulta SQL, a instância do Impala será reiniciada. Enquanto isso, o Hive manterá a conexão com a fonte de dados, oferecendo maior tolerância a falhas.
Outros benefícios do Impala incluem suporte integrado para o protocolo de autenticação de rede Kerberos, priorização e gerenciamento da fila de solicitações e suporte a formatos populares de Big Data, como LZO, Avro, RCFile, Parquet e Sequence.
Hive vs. Impala: Semelhanças
Tanto o Hive quanto o Impala são distribuídos gratuitamente sob a licença Apache Software Foundation e são ferramentas SQL para trabalhar com dados armazenados em um cluster Hadoop. Ambos também utilizam o sistema de arquivos distribuído HDFS.
O Impala e o Hive implementam diferentes tarefas, mas compartilham o mesmo objetivo: processar dados de big data armazenados em um cluster Apache Hadoop usando SQL. O Impala fornece uma interface semelhante ao SQL, permitindo que você leia e grave tabelas do Hive, facilitando a troca de dados.
O Impala oferece operações SQL rápidas e eficientes no Hadoop, tornando-o adequado para projetos de pesquisa e análise de big data. Sempre que possível, o Impala utiliza a infraestrutura existente do Apache Hive, já usada para executar consultas em lote SQL de longa duração.
Além disso, o Impala armazena suas definições de tabela em um metastore, que pode ser um banco de dados MySQL ou PostgreSQL, ou seja, no mesmo local onde o Hive armazena seus metadados. Isso permite que o Impala acesse as tabelas do Hive, desde que todas as colunas usem os tipos de dados, formatos de arquivo e codecs de compactação suportados pelo Impala.
Hive vs. Impala: Diferenças

Linguagem de Programação
O Hive é escrito em Java, enquanto o Impala é escrito em C++. No entanto, o Impala também utiliza algumas UDFs (Funções Definidas pelo Usuário) do Hive baseadas em Java.
Casos de Uso
Engenheiros de dados utilizam o Hive em processos de ETL (extrair, transformar, carregar), por exemplo, para trabalhos em lote de longa duração sobre grandes conjuntos de dados. Por sua vez, o Impala é direcionado principalmente para analistas e cientistas de dados, sendo utilizado em tarefas como inteligência de negócios.
Desempenho
O Impala executa consultas SQL em tempo real, enquanto o Hive se caracteriza pela baixa velocidade de processamento de dados. Em consultas SQL simples, o Impala pode ser executado de 6 a 69 vezes mais rápido que o Hive. No entanto, o Hive se sai melhor em consultas mais complexas.
Latência/Throughput
O rendimento do Hive é significativamente maior do que o do Impala. O recurso LLAP (Live Long and Process), que permite o armazenamento em cache de consultas na memória, oferece ao Hive um bom desempenho em baixo nível.
O LLAP inclui serviços de sistema de longa duração (daemons), que permitem a interação direta com nós de dados HDFS e substituem a estrutura de consulta DAG totalmente integrada (gráfico acíclico direcionado), um modelo de gráfico usado ativamente na computação de Big Data.
Tolerância a Falhas
O Hive é um sistema tolerante a falhas, que preserva todos os resultados intermediários. Isso impacta positivamente a escalabilidade, mas leva a uma redução na velocidade de processamento de dados. Por outro lado, o Impala não pode ser considerado uma plataforma tolerante a falhas, pois é mais limitado pela memória.
Conversão de Código
O Hive gera expressões de consulta em tempo de compilação, enquanto o Impala as gera em tempo de execução. O Hive apresenta um problema de “inicialização a frio” na primeira execução do aplicativo, com as consultas sendo convertidas lentamente devido à necessidade de estabelecer conexão com a fonte de dados.
O Impala não apresenta essa sobrecarga de inicialização. Os serviços de sistema necessários (daemons) para processar consultas SQL são iniciados no momento da inicialização, acelerando o trabalho.
Suporte a Armazenamento
O Impala oferece suporte aos formatos LZO, Avro e Parquet, enquanto o Hive trabalha com Texto Simples e ORC. No entanto, ambos suportam os formatos RCFile e Sequence.
| Apache Hive | Apache Impala | |
| Linguagem | Java | C++ |
| Casos de Uso | Engenharia de Dados | Análise |
| Desempenho para consultas simples | Comparativamente baixo | Alto |
| Latência | Mais latência devido ao armazenamento em cache | Menos latente |
| Tolerância a falhas | Mais tolerante devido a MapReduce | Menos tolerante devido a MPP |
| Conversão | Lenta devido a inicialização a frio | Conversão mais rápida |
| Suporte a armazenamento | Texto simples e ORC | LZO, Avro, Parquet |
Considerações Finais
Hive e Impala não competem entre si, mas se complementam de forma eficaz. Embora existam diferenças significativas entre os dois, também há muitos pontos em comum e a escolha entre eles dependerá dos dados e dos requisitos específicos de cada projeto.
Você também pode explorar outras comparações diretas, como entre Hadoop e Spark.