A Importância do MLOps na Construção e Gestão de Modelos de Machine Learning
Desenvolver um modelo de aprendizado de máquina pode parecer simples à primeira vista. No entanto, a complexidade aumenta exponencialmente ao lidar com centenas ou milhares de modelos, exigindo iterações constantes. Esse cenário pode rapidamente se tornar caótico, especialmente em equipes onde o acompanhamento das atividades de todos se torna um desafio. Para colocar ordem nesse processo, é essencial que todos sigam um fluxo de trabalho bem definido e documentem cada etapa, o que é, fundamentalmente, a essência do MLOps.
O que é MLOps?
Segundo o MLOps.org, a Operacionalização de Aprendizado de Máquina visa estabelecer um processo de ponta a ponta para o desenvolvimento de software ML, que seja replicável, testável e adaptável. Em essência, o MLOps é a aplicação dos princípios DevOps ao contexto do Machine Learning.
Assim como no DevOps, a ideia central do MLOps reside na automação para minimizar tarefas manuais e maximizar a eficiência. Além disso, incorpora a Integração Contínua (CI) e a Entrega Contínua (CD). Adicionalmente, o MLOps inclui o Treinamento Contínuo (CT), que envolve o reajuste de modelos com novos dados e sua reimplementação.
O MLOps representa, portanto, uma cultura de engenharia que incentiva uma abordagem metódica para o desenvolvimento de modelos de aprendizado de máquina, automatizando diversas etapas do processo. Este processo abrange a extração, análise e preparação de dados, o treinamento do modelo, a avaliação, a disponibilização e o monitoramento.
Benefícios do MLOps
Os benefícios da implementação do MLOps assemelham-se aos de seguir Procedimentos Operacionais Padrão, proporcionando:
- Um plano bem definido que serve como um guia para todas as etapas cruciais no desenvolvimento de um modelo, garantindo que nenhuma etapa essencial seja negligenciada.
- A identificação e automação de etapas repetitivas, reduzindo a carga de trabalho, acelerando o desenvolvimento e minimizando erros humanos.
- Uma avaliação mais precisa do progresso, permitindo saber em qual fase do pipeline o modelo se encontra.
- Melhoria na comunicação entre as equipes, com um vocabulário compartilhado para o processo de desenvolvimento.
- A capacidade de aplicar o processo repetidamente para construir múltiplos modelos, auxiliando na gestão do fluxo de trabalho.
Em última análise, o MLOps visa fornecer uma abordagem sistemática e automatizada para o desenvolvimento de modelos de machine learning.
Plataformas para a Construção de Pipelines
Para facilitar a implementação do MLOps em seus pipelines, diversas plataformas estão disponíveis. Embora possam diferir em suas funcionalidades específicas, elas geralmente oferecem os seguintes recursos:
- Armazenamento de modelos com seus metadados associados, como configurações, código, precisão, experimentos e versões.
- Armazenamento de metadados de conjuntos de dados, incluindo os utilizados no treinamento dos modelos.
- Monitoramento de modelos em produção para detecção de problemas, como desvio de modelo.
- Implantação de modelos em ambientes de produção.
- Criação de modelos em ambientes com pouco ou nenhum código.
A seguir, vamos explorar algumas das principais plataformas MLOps.
MLflow
O MLflow é uma das plataformas mais populares para o gerenciamento do ciclo de vida do aprendizado de máquina. Ele é gratuito, de código aberto e oferece os seguintes recursos:
- Rastreamento para registrar experimentos, código, dados, configurações e resultados.
- Projetos para organizar o código de maneira replicável.
- Implantação de modelos de aprendizado de máquina.
- Registro centralizado para armazenar todos os modelos.
O MLflow integra-se a bibliotecas de machine learning como TensorFlow e PyTorch, e a plataformas como Apache Spark, H20.asi, Google Cloud, Amazon Sage Maker, Azure Machine Learning e Databricks. Ele também é compatível com diferentes provedores de nuvem, como AWS, Google Cloud e Microsoft Azure.
Azure Machine Learning
O Azure Machine Learning é uma plataforma abrangente de aprendizado de máquina que gerencia as diferentes etapas do ciclo de vida da máquina em pipelines MLOps. Isso inclui a preparação de dados, a criação e treinamento de modelos, a validação e implantação, e o gerenciamento e monitoramento.
O Azure Machine Learning permite a criação de modelos usando IDEs preferenciais e frameworks como PyTorch e TensorFlow.
A integração com ONNX Runtime e Deepspeed otimiza o treinamento e a inferência, melhorando o desempenho. A infraestrutura de IA no Microsoft Azure, que combina GPUs NVIDIA e a rede Mellanox, auxilia na criação de clusters de aprendizado de máquina. Com o AML, você pode estabelecer um registro central para armazenar e compartilhar modelos e conjuntos de dados.
O Azure Machine Learning se integra ao Git e ao GitHub Actions para criar fluxos de trabalho e oferece suporte a configurações híbridas ou multinuvem. Ele também pode ser integrado a outros serviços do Azure, como Synapse Analytics, Data Lake, Databricks e Security Center.
Google Vertex AI

O Google Vertex AI é uma plataforma unificada de dados e IA que fornece ferramentas para criar modelos personalizados e pré-treinados. Ele também serve como uma solução completa para implementação de MLOps e integra-se com BigQuery, Dataproc e Spark para acesso contínuo aos dados durante o treinamento.
Além da API, o Google Vertex AI oferece ferramentas de baixo código e sem código, permitindo o uso por não desenvolvedores como engenheiros e analistas de negócios e dados. A API permite que os desenvolvedores a integrem a sistemas já existentes.
O Google Vertex AI também possibilita a criação de aplicações de IA generativas com o Generative AI Studio, simplificando a implantação e o gerenciamento de infraestrutura. É ideal para garantir a preparação de dados, engenharia de recursos, treinamento e ajuste de hiperparâmetros, disponibilização de modelos, ajuste e entendimento de modelos, monitoramento e gerenciamento.
Databricks

Databricks é um data lakehouse que permite preparar e processar dados. Com o Databricks, você pode gerenciar todo o ciclo de vida do aprendizado de máquina, desde a experimentação até a produção.
O Databricks oferece o MLFlow gerenciado, incluindo versionamento de registro de dados de modelos de ML, rastreamento de experimentos, veiculação de modelos, registro de modelos e rastreamento de métricas. O registro de modelos permite o armazenamento para reprodutibilidade, e o registro ajuda a acompanhar as versões e o estágio do ciclo de vida.
A implantação de modelos com o Databricks é feita com um único clique, e endpoints de API REST são gerados para previsões. Ele se integra a modelos de linguagem generativos, como os da biblioteca de transformadores do Hugging Face.
O Databricks fornece notebooks colaborativos que suportam Python, R, SQL e Scala, além de simplificar o gerenciamento de infraestrutura com clusters pré-configurados otimizados para tarefas de aprendizado de máquina.
AWS SageMaker
O AWS SageMaker é um serviço da AWS que fornece as ferramentas necessárias para o desenvolvimento, treinamento e implantação de modelos de aprendizado de máquina. Seu principal objetivo é automatizar as tarefas manuais e repetitivas envolvidas na construção de modelos.
O SageMaker oferece ferramentas para criar um pipeline de produção para modelos de aprendizado de máquina usando diversos serviços da AWS, como instâncias do Amazon EC2 e armazenamento do Amazon S3.
O SageMaker utiliza Jupyter Notebooks instalados em instâncias EC2 com os pacotes e bibliotecas necessários para o desenvolvimento de modelos de Machine Learning. Para os dados, ele extrai informações do Amazon Simple Storage Service.
O SageMaker oferece implementações de algoritmos comuns, como regressão linear e classificação de imagens. Ele também inclui um monitor de modelo para ajuste contínuo e automático dos parâmetros, buscando o melhor desempenho. A implantação é simplificada, permitindo disponibilizar modelos na AWS como endpoints HTTP seguros e monitorados com o CloudWatch.
DataRobot
O DataRobot é uma plataforma MLOps que oferece suporte ao gerenciamento de todo o ciclo de vida do Machine Learning, desde a preparação de dados e experimentação até a validação e governança de modelos.
Ele automatiza a execução de experimentos com diversas fontes de dados, testa milhares de modelos e avalia os melhores para implantação em produção. Ele suporta a criação de modelos para diferentes tipos de IA, resolvendo problemas em Séries Temporais, Processamento de Linguagem Natural e Visão Computacional.
Com o DataRobot, é possível construir modelos utilizando modelos prontos, sem a necessidade de codificação. Também é possível optar por uma abordagem mais focada em código, com a implementação de modelos usando código personalizado.
O DataRobot oferece notebooks para edição e escrita de código, ou a API para desenvolvimento em IDEs preferenciais. Uma GUI permite o acompanhamento dos experimentos de modelos.
Run AI

O Run AI aborda o problema da subutilização da infraestrutura de IA, especialmente GPUs, aumentando a visibilidade da infraestrutura e garantindo seu uso eficiente durante o treinamento.
O Run AI atua entre o software MLOps e o hardware da empresa, garantindo que todas as tarefas de treinamento sejam executadas através dele. A plataforma agenda a execução de cada tarefa, sem limitação ao hardware, que pode ser baseado em nuvem (AWS, Google Cloud), local ou híbrido.
Ele fornece uma camada de abstração para as equipes de Machine Learning, funcionando como uma plataforma de virtualização de GPU. As tarefas podem ser executadas a partir do Jupyter Notebook, terminal bash ou PyCharm remoto.
H2O.ai
H2O é uma plataforma de aprendizado de máquina distribuída de código aberto, que permite que equipes colaborem e criem um repositório central de modelos para experimentação e comparação.
Como plataforma MLOps, H2O simplifica a implantação de modelos em servidores como endpoints REST, com opções como teste A/B, modelos Champoion-Challenger e implantação simples de modelo único.
Durante o treinamento, ela armazena e gerencia dados, artefatos, experimentos, modelos e implementações, garantindo a reprodutibilidade. Ela também permite o gerenciamento de permissões em níveis de grupo e usuário para modelos e dados, oferecendo monitoramento em tempo real para desvios e outras métricas operacionais.
Gradient do Paperspace
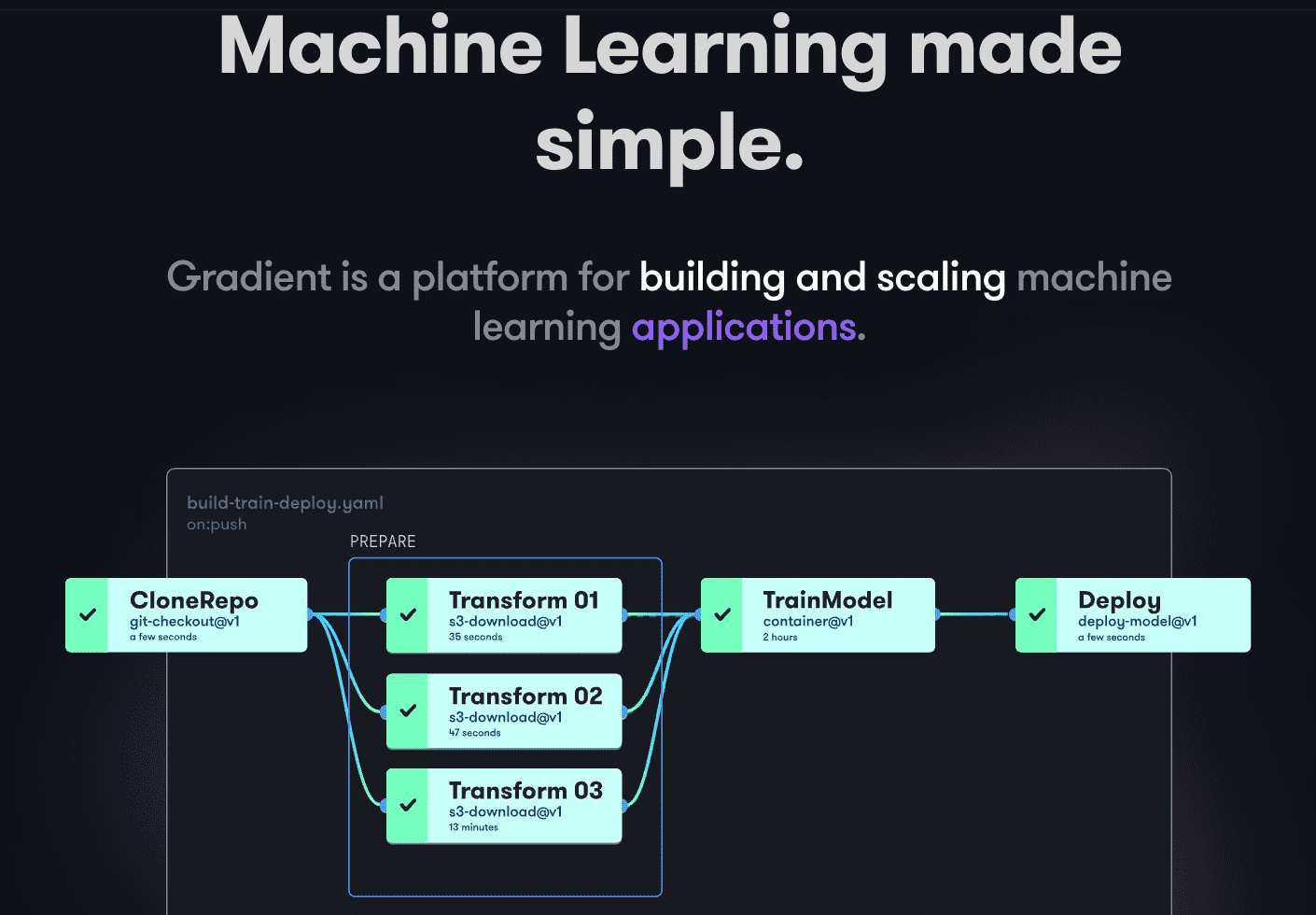
O Gradient auxilia desenvolvedores em todas as etapas do ciclo de desenvolvimento de Machine Learning, com notebooks baseados em Jupyter de código aberto para desenvolvimento e treinamento de modelos na nuvem com GPUs potentes, facilitando a exploração e prototipagem rápidas.
Os pipelines de implantação podem ser automatizados com fluxos de trabalho definidos em YAML, facilitando a replicação e escalabilidade. O Gradient gerencia contêineres, máquinas, dados, modelos, métricas, logs e segredos, e seus pipelines podem ser executados em clusters Gradient no Paperspace Cloud, AWS, GCP, Azure ou outros servidores, com interação via CLI ou SDK.
Considerações Finais
O MLOps é uma abordagem poderosa e versátil para construir, implantar e gerenciar modelos de aprendizado de máquina em escala. Sua facilidade de uso, escalabilidade e segurança o tornam ideal para organizações de todos os portes.
Neste artigo, exploramos o MLOps, sua importância, os processos envolvidos e as plataformas mais populares para sua implementação.
Recomendamos que você leia nossa comparação entre Dataricks e Snowflake para expandir seus conhecimentos.