Está a ter dificuldades em depurar o seu código? Procura soluções de registo que simplifiquem a depuração? Continue a ler para saber mais.
O desenvolvimento de software atravessa diversas etapas: recolha de requisitos, análise, codificação, testes e manutenção. De todas estas etapas, a codificação/desenvolvimento é a que requer mais tempo e esforço. Os engenheiros de software lidam com erros de sintaxe, erros lógicos e erros de tempo de execução. Os erros de sintaxe são identificados durante a compilação e ocorrem quando o código não segue as regras de uma linguagem de programação.
Por outro lado, os erros lógicos e de tempo de execução não são detetados pelo Ambiente de Desenvolvimento Integrado (IDE) e são, geralmente, difíceis de depurar e corrigir. A resolução de erros é um processo demorado que exige muita depuração.
A depuração é o processo de tentar compreender por que o código escrito não funciona como esperado. É fácil resolver o problema quando se conhece o erro e as linhas exatas de código onde este ocorre. Portanto, o registo é bastante útil na depuração do código.
O que é o Registo?
O registo é uma técnica onde as mensagens são capturadas enquanto um programa está em execução. É preciso registar apenas as mensagens que o podem ajudar na depuração. Portanto, saber quando adicionar instruções de registo ao código é muito importante. Além disso, diferenciar as instruções de registo é igualmente essencial. Existem vários níveis de registo, como informação, aviso, erro, depuração e detalhado. As instruções de erro e aviso são usadas para o tratamento de exceções.
Dados retornados de funções, resultados após manipulação de matrizes, dados recuperados de APIs, etc., são exemplos de dados que podem ser registados usando instruções de informação. Os registos de depuração e detalhados são usados para fornecer uma descrição aprofundada dos erros.
O registo de depuração fornece informações sobre o rastreamento de pilha, parâmetros de entrada e saída, etc. O nível “detalhado” não é tão detalhado quanto o registo de “depuração”, mas fornece uma lista de todos os eventos que ocorreram. Os registos são escritos na consola, em ficheiros e no fluxo de saída. As ferramentas de gestão de registos podem ser usadas para um registo estruturado e formatado.
Registo no Node.js
O Node.js é um ambiente de tempo de execução JavaScript. As aplicações Node.js são assíncronas e não bloqueadoras e são usadas em sistemas com uso intensivo de dados e em tempo real. A melhor forma de aprender mais sobre o Node.js é consultando os tutoriais e a sua documentação. O registo é necessário para melhorar o desempenho, a resolução de problemas e o rastreamento de erros. O registo no Node.js pode ser feito usando a função incorporada console.log. Além disso, a função de depuração está interligada com vários pacotes e pode ser usada de forma eficaz.
O middleware é usado para gerenciar pedidos e respostas. O middleware pode ser uma aplicação ou qualquer outra estrutura JavaScript. O registo no middleware pode ser feito por meio de aplicações e roteadores. Qualquer registrador Node.js precisa usar o comando npm ou yarn install para instalar os registradores.
Npm significa “Node Package Manager” e YARN significa “Yet Another Resource Negotiator”. No entanto, o Yarn é preferível ao npm, pois é mais rápido e instala pacotes paralelamente.
Abaixo, estão listados alguns dos melhores registradores Node.js:
Pino
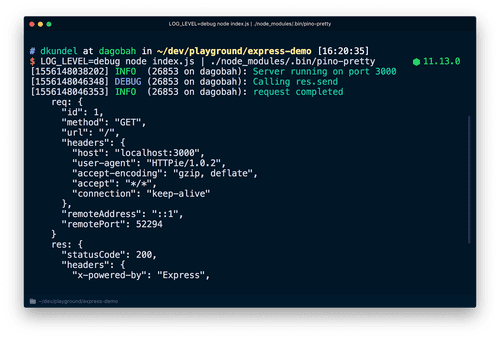
O Pino é uma biblioteca que é um dos melhores registradores para aplicações Node.js. É de código aberto, extremamente rápido e regista as instruções num formato JSON de fácil leitura. Alguns dos níveis de registo do Pino são – mensagens de depuração, aviso, erro e informação. Uma instância de registo Pino pode ser importada para o projeto e as instruções console.log devem ser substituídas por instruções logger.info.

Use o seguinte comando para instalar o Pino:
$ npm install pino
Os registos gerados são detalhados e em formato JSON, destacando o número da linha do registo, o tipo de registo, a hora em que foi registado, etc. O Pino causa uma sobrecarga mínima de registo numa aplicação e é extremamente flexível no processamento de registos.
O Pino pode ser integrado com estruturas web como Hapi, Restify, Express, etc. Os registos gerados pelo Pino também podem ser armazenados em ficheiros. Ele usa threads de trabalho para a operação e é compatível com TypeScript.
Winston
O Winston oferece suporte ao registo para várias estruturas da Web, com foco principal na flexibilidade e extensibilidade. Suporta vários tipos de transporte e pode armazenar registos em diversos locais de arquivo. Os transportes são os locais onde as mensagens de registo são armazenadas.
Juntamente com alguns transportes integrados, como Http, Console, File e Stream, ele suporta outros transportes, como Cloud watch e MongoDB. Ele faz o registo em vários níveis e formatos. Os níveis de registo indicam a gravidade do problema.

Os vários níveis de registo são mostrados abaixo:
{
error: 0,
warn: 1,
info: 2,
http: 3,
verbose: 4,
debug: 5,
silly: 6
}
O formato de saída do registo pode ser personalizado, filtrado e combinado. Os registos incluem informações sobre o carimbo de data/hora, rótulos associados a um registo, milissegundos decorridos do registo anterior, etc.
O Winston também lida com exceções e promessas não atendidas. Ele fornece recursos adicionais, como arquivamento de tempo de execução de consultas, registos de streaming, etc. Em primeiro lugar, é preciso instalar o Winston. Em seguida, um objeto de configuração Winston, juntamente com o transporte, é criado para armazenar o registo. Um objeto logger é criado usando a função createLogger() e a mensagem de registo é passada para ele.
Node-Bunyan
O Bunyan é usado para registo rápido em node.js no formato JSON. Também fornece uma ferramenta CLI (Command Line Interface) para visualizar os registos. É leve e suporta vários ambientes de tempo de execução, como Node.js, Browserify, WebPack e NW.js. O formato JSON dos registos é ainda mais enriquecido usando a função de impressão bonita. Os registos têm vários níveis como fatal, erro, aviso, informação, depuração e rastreamento; cada um está associado a um valor numérico.

Todos os níveis acima do nível definido para a instância são registados. O fluxo Bunyan é um local onde as saídas são registadas. Os subcomponentes de uma aplicação podem ser registados usando a função log.child(). Todos os registradores filhos estão vinculados a uma aplicação pai específica. O tipo de fluxo pode ser um arquivo, arquivo rotativo, dados brutos, etc. O exemplo de código para definir um fluxo é mostrado abaixo:
var bunyan = require('bunyan');
var log = bunyan.createLogger({
name: "foo",
streams: [
{
stream: process.stderr,
level: "debug"
},
...
]
});
O Bunyan também oferece suporte ao registo do DTrace. Os probes envolvidos no registo do DTrace incluem log-trace, log-warn, log-error, log-info, log-debug e log-fatal. O Bunyan usa serializadores para produzir os registos no formato JSON. As funções do serializador não lançam exceções e são defensivas.
Nível de Registo
O Loglevel é usado para registar em aplicações Javascript. É também um dos melhores registradores do Node.js, pois é leve e simples. Regista o nível fornecido e usa um único arquivo sem dependências para o registo. O nível de registo padrão é “aviso”. As saídas de registo são bem formatadas juntamente com os números de linha. Alguns métodos usados para o registo são rastreamento, depuração, aviso, erro e informação.
Eles são resistentes a falhas em qualquer ambiente. getLogger() é o método usado para recuperar o objeto logger. Também pode ser combinado com outros plugins para ampliar os seus recursos. Alguns dos plugins incluem loglevel-plugin-prefix, loglevel-plugin-remote, ServerSend e DEBUG. O plugin para adicionar mensagens de prefixo ao registo é mostrado abaixo:
var originalFactory = log.methodFactory;
log.methodFactory = function (methodName, logLevel, loggerName) {
var rawMethod = originalFactory(methodName, logLevel, loggerName);
return function (message) {
rawMethod("Newsflash: " + message);
};
};
log.setLevel(log.getLevel()); // Be sure to call setLevel method in order to apply plugin
As compilações são executadas usando o comando npm run dist e os testes podem ser executados usando o comando npm test. O nível de registo suporta pacotes Webjar, Bower e Atmosphere. Uma nova versão do Loglevel é lançada sempre que novos recursos são adicionados.
Signale
O Signale consiste em 19 registradores para aplicações Javascript. Suporta TypeScript e registo com escopo. Consiste em temporizadores que ajudam a registar a data e hora, os dados e o nome do ficheiro. Além dos 19 registradores, como await, complete, fatal, fav, info, etc., é possível criar registos personalizados.
Os registos personalizados são criados definindo um objeto JSON e campos com os dados do registrador. Registradores interativos também podem ser criados. Quando um registrador interativo é definido como verdadeiro, os novos valores dos registradores interativos substituem os antigos.
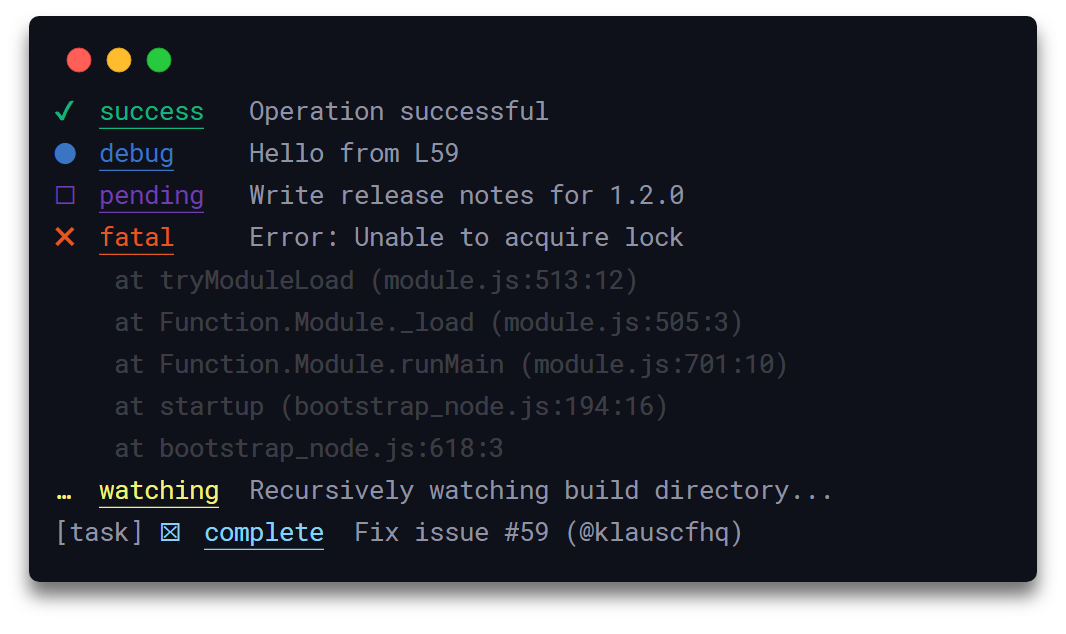
A melhor parte do Signale é a capacidade de filtrar informações confidenciais. Vários segredos são armazenados numa matriz. addSecrets() e clearSecrets() são as funções usadas para adicionar e limpar os segredos da matriz. Boostnote, Docz, Shower, Taskbook e Vant usam o Signale para registo. A sintaxe para chamar APIs do Signale é a seguinte:
signale.<logger>(message[,message]|messageObj|errorObj)
O número de downloads do Signale é superior a 1 milhão no momento em que este artigo foi escrito.
Tracer
O Tracer é usado para produzir mensagens de registo detalhadas. As mensagens de registo consistem em carimbos de data/hora, nomes de ficheiros, números de linha e nomes de métodos. Os pacotes auxiliares podem ser instalados para personalizar o formato de registo de saída. Os pacotes auxiliares podem ser instalados usando o seguinte comando.
npm install -dev tracer
O Tracer é compatível com transporte de arquivo, fluxo e MongoDB. Suporta consola de cores e condições de filtro no registo. Inicialmente, o rastreador deve ser instalado usando npm install. Em segundo lugar, um objeto logger deve ser criado e o tipo de consola deve ser selecionado. Em seguida, os vários níveis ou tipos de registo podem ser especificados sobre o objeto para mais registo.
Filtros personalizados podem ser criados definindo funções síncronas com a lógica de negócio presente no corpo da função. Micromodelos, como o tinytim, também podem ser usados para o registo do sistema.
Cabin.js
O Cabin é usado para registo do lado do servidor e do cliente de aplicações node.js. É usado onde é necessário o mascaramento de informações confidenciais e críticas. Isso inclui números de cartão de crédito, cabeçalhos BasicAuth, salts, senhas, tokens CSRF e números de contas bancárias. O excerto de código abaixo mostra a geração de registos usando Cabin.js.
const Cabin = require('cabin');
const cabin = new Cabin();
cabin.info('hello world');
cabin.error(new Error('oops!'));
Consiste em mais de 1600 nomes de campo. Também segue o princípio de “Bring Your Own Logger” (BYOL). Isso o torna compatível com vários outros registradores, como Axe, Pino, Bunyan, Winston, etc. Reduz os custos de armazenamento em disco devido ao fluxo automático e buffers de cabine. É compatível com várias plataformas e fácil de depurar.
O registo do lado do servidor requer o uso de middleware para roteamento e registo de saída automático. O registo no navegador requer solicitações e scripts XHR. Usa o Axe que exibe metadados, ou seja, dados sobre dados, rastreamentos de pilha e outros erros. SHOW_STACK e SHOW_META são variáveis booleanas definidas como true ou false para mostrar ou ocultar rastreamentos de pilha e metadados.
Npmlog
O Npmlog é um tipo básico de registrador que o npm usa. Alguns dos métodos de registo usados são nível, registo, maxRecordSize, prefixStyle, título e fluxo. Também suporta registo colorido. Os vários níveis de registo são tolo, detalhado, informação, aviso, http e erro. Um excerto de código de exemplo para usar o registo npm é mostrado abaixo.
var log = require('npmlog')
// additional stuff ---------------------------+
// message ----------+ |
// prefix ----+ | |
// level -+ | | |
// v v v v
log.info('fyi', 'I have a kitty cat: %j', myKittyCat)
Todas as mensagens são suprimidas se “Infinity” for especificado como o nível de registo. Se “-Infinity” for especificado como o nível de registo, a opção para ver as mensagens de registo deve ser ativada para ver os registos.
Eventos e objetos de mensagem são usados para registo. As mensagens de prefixo são emitidas quando os eventos de prefixo são usados. Objetos de estilo são usados para formatar os registos, como adicionar cor ao texto e ao fundo, estilo de fonte, como negrito, itálico, sublinhado, etc. Alguns pacotes de registo npm são brolog, npmlogger, npmdate log, etc.
Roarr
Roarr é um agente de registo para Node.js que não requer inicialização e produz dados estruturados. Possui CLI e variáveis ambientais. É compatível com o navegador. Pode ser integrado com Fastify, Fastify, Elastic Search, etc. Pode distinguir entre código de aplicação e código de dependência. Cada mensagem de registo consiste num contexto, mensagem, sequência, hora e versão. Vários níveis de registo incluem rastreamento, depuração, informação, aviso, erro e fatal. Um excerto de código de amostra sobre como o registo é feito em Roarr é o seguinte:
import {
ROARR,
} from 'roarr';
ROARR.write = (message) => {
console.log(JSON.parse(message));
};
Além disso, a serialização de erros pode ser feita, o que significa que a instância com o erro pode ser registada juntamente com o contexto do objeto. Algumas das variáveis ambientais específicas para Node.js e Roarr são ROARR_LOG e ROARR_STREAM. “adopt” é uma função que é usada com node.js para passar as propriedades de contexto para vários níveis. As funções filhas também podem ser usadas com middleware durante o registo.
Considerações finais
O registo é um método de acompanhar várias atividades e eventos durante a execução de um programa. O registo desempenha um papel vital na depuração de código. Também ajuda a aumentar a legibilidade do código. O Node.js é um ambiente de tempo de execução javascript de código aberto. Alguns dos melhores registradores Node.js são Pino, Winston, Bunyan, Signale, Tracer, Npmlog, etc. Cada tipo de registrador tem os seus próprios recursos, como criação de perfil, filtragem, streaming e transporte.
Alguns registradores suportam consolas coloridas e alguns são adequados para lidar com informações confidenciais. Registos detalhados e formatados ajudam mais os desenvolvedores enquanto tentam corrigir erros no seu código. O formato JSON é geralmente preferido para registo porque regista dados na forma de pares de valores-chave, tornando-o fácil de usar.
Os registradores também podem ser integrados a outras aplicações e são compatíveis com vários navegadores. É sempre aconselhável examinar as necessidades e as aplicações que está a construir antes de escolher o tipo de registrador que deseja usar.
Pode também ver como instalar o Node.js e o NPM no Windows e no macOS.