A Relevância Crescente dos Dados Sintéticos
Atualmente, os dados assumem um papel primordial na construção de modelos de aprendizado de máquina, na fase de teste de aplicativos e na extração de informações estratégicas para negócios. No entanto, a necessidade de cumprir rigorosas regulamentações de proteção de dados muitas vezes impõe barreiras, resultando em armazenamento e proteção estrita desses ativos. O processo de obtenção de acesso a tais dados pode levar meses devido à complexidade das aprovações necessárias. Em alternativa a este cenário, as empresas podem optar por utilizar dados sintéticos.
O que são Dados Sintéticos?

Dados sintéticos referem-se a dados gerados artificialmente que replicam estatisticamente as características de um conjunto de dados original. Eles podem ser empregados em conjunto com dados reais para fortalecer e aprimorar modelos de inteligência artificial (IA), ou podem ser utilizados como um substituto completo. Devido à sua natureza, não pertencem a um titular específico e não contêm informações pessoais identificáveis ou dados confidenciais, como números de segurança social. Assim, apresentam-se como uma alternativa para a proteção de privacidade quando comparados com dados de produção reais.
Distinções entre Dados Reais e Sintéticos
- A principal diferença reside na forma como os dois tipos de dados são criados. Dados reais são derivados de indivíduos cujas informações foram coletadas durante pesquisas ou através do uso de aplicativos. Dados sintéticos, por outro lado, são gerados artificialmente, mas mantêm uma semelhança estatística com o conjunto de dados original.
- Outra distinção importante está relacionada às regulamentações de proteção de dados. Dados reais exigem que os sujeitos estejam cientes de quais informações estão sendo coletadas, o propósito da coleta e que existem restrições sobre como esses dados podem ser utilizados. Estas regras não se aplicam a dados sintéticos, uma vez que não podem ser associados a indivíduos e não incluem informações pessoais.
- Por fim, a quantidade de dados disponíveis difere significativamente. Com dados reais, a quantidade é limitada pela disponibilidade dos usuários em fornecer informações. No caso de dados sintéticos, é possível gerar a quantidade necessária para os fins desejados.
Por que Considerar o Uso de Dados Sintéticos
- A produção é geralmente mais econômica, pois permite criar conjuntos de dados extensos que se assemelham a conjuntos de dados menores já existentes. Isso resulta em modelos de aprendizado de máquina com mais dados para treinamento.
- Os dados gerados são automaticamente rotulados e limpos, poupando tempo e esforço na preparação manual de dados para aprendizado de máquina ou análise.
- Não há problemas de privacidade, pois os dados não contêm informações pessoais identificáveis e não pertencem a nenhum indivíduo. Isso proporciona liberdade para utilizá-los e compartilhá-los.
- A possibilidade de garantir uma representação adequada das classes minoritárias ajuda a superar o viés da IA, auxiliando no desenvolvimento de uma IA justa e responsável.
Como Gerar Dados Sintéticos
O processo de geração de dados sintéticos pode variar dependendo da ferramenta utilizada, mas geralmente começa com a conexão de um gerador a um conjunto de dados existente. Em seguida, são identificados os campos que contêm informações pessoais identificáveis, os quais são rotulados para exclusão ou ofuscação. O gerador então procede à identificação dos tipos de dados nas colunas restantes e dos padrões estatísticos presentes nessas colunas. A partir disso, é possível gerar a quantidade de dados sintéticos desejada.
É comum comparar os dados gerados com o conjunto de dados original para avaliar a similaridade entre os dados sintéticos e os dados reais.
A seguir, exploraremos algumas ferramentas para gerar dados sintéticos para treinar modelos de aprendizado de máquina.
Mostly AI
A plataforma Mostly AI oferece um gerador de dados sintéticos baseado em IA, que aprende a partir dos padrões estatísticos do conjunto de dados original. A IA gera então personagens fictícios que refletem os padrões aprendidos. Com o Mostly AI, é possível criar bancos de dados inteiros com integridade referencial, sintetizando diversos tipos de dados para auxiliar na criação de modelos de IA mais eficazes.
Synthesized.io

O Synthesized.io é amplamente utilizado por empresas líderes em suas iniciativas de IA. Para usar o synthese.io, os requisitos de dados devem ser especificados em um arquivo de configuração YAML. Em seguida, um trabalho é criado e executado como parte de um pipeline de dados. A plataforma também oferece um nível gratuito bastante generoso, permitindo que os usuários experimentem e avaliem se atende às suas necessidades de dados.
YData

Com o YData, é possível gerar dados tabulares, de séries temporais, transacionais, multitabelas e relacionais. Isso ajuda a evitar os problemas comuns associados à coleta, compartilhamento e qualidade de dados. A plataforma inclui uma IA e SDK para interação e um nível gratuito que pode ser usado para demonstrar o produto.
Gretel AI

A Gretel AI oferece APIs para gerar quantidades ilimitadas de dados sintéticos. A Gretel possui um gerador de dados de código aberto que pode ser instalado e usado gratuitamente. Alternativamente, é possível utilizar sua API REST ou CLI, que envolve um custo, com preços razoáveis e adaptados ao tamanho do negócio.
Cópulas
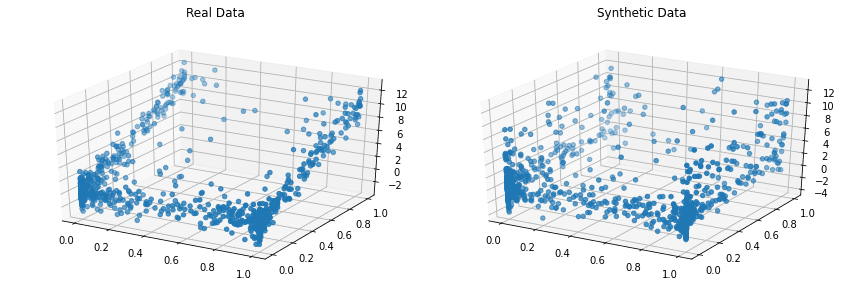
Cópulas é uma biblioteca Python de código aberto para modelagem de distribuições multivariadas utilizando funções de cópula e geração de dados sintéticos que seguem as mesmas propriedades estatísticas. O projeto foi iniciado em 2018 no MIT, como parte do projeto Synthetic Data Vault.
CTGAN
O CTGAN consiste em geradores capazes de aprender a partir de dados reais de uma única tabela e gerar dados sintéticos com base nos padrões identificados. É implementado como uma biblioteca Python de código aberto. Juntamente com o Copulas, o CTGAN faz parte do Projeto Synthetic Data Vault.
Doppelganger
O DoppelGANger é uma implementação de código aberto de Generative Adversarial Networks (GANs) para geração de dados sintéticos. O DoppelGANger é especialmente útil para gerar dados de séries temporais e é utilizado por empresas como a Gretel AI. A biblioteca Python está disponível gratuitamente e é de código aberto.
Synth

Synth é um gerador de dados de código aberto que auxilia na criação de dados realistas, de acordo com as especificações do usuário, ocultando informações pessoais identificáveis e desenvolvendo dados de teste para aplicativos. Pode ser utilizado para gerar dados de séries temporais e dados relacionais para necessidades de aprendizado de máquina. Synth é independente de banco de dados, permitindo a utilização com bancos de dados SQL e NoSQL.
SDV.dev
SDV (Synthetic Data Vault) é um projeto de software iniciado no MIT em 2016 que criou diferentes ferramentas para geração de dados sintéticos. Essas ferramentas incluem Cópulas, CTGAN, DeepEcho e RDT. Todas são implementadas como bibliotecas Python de código aberto, disponíveis para uso.
Tofu
Tofu é uma biblioteca Python de código aberto para geração de dados sintéticos com base em dados de biobancos do Reino Unido. Diferentemente de outras ferramentas que geram diversos tipos de dados com base em conjuntos de dados existentes, o Tofu gera dados semelhantes apenas aos do biobanco. O UK Biobank é um estudo sobre as características fenotípicas e genotípicas de 500.000 adultos de meia-idade do Reino Unido.
Twinify
Twinify é um pacote de software usado como biblioteca ou ferramenta de linha de comando para criar dados gêmeos de dados confidenciais, produzindo dados sintéticos com distribuições estatísticas idênticas. Para usar o Twinify, os dados reais são fornecidos como um arquivo CSV e um modelo é criado a partir deles, o qual pode ser usado para gerar dados sintéticos. A plataforma é totalmente gratuita para uso.
Datanamic
A Datanamic auxilia na criação de dados de teste para aplicações orientadas a dados e aprendizado de máquina, gerando dados com base em características de colunas como email, nome e número de telefone. Os geradores de dados da Datanamic são personalizáveis e suportam a maioria dos bancos de dados, como Oracle, MySQL, MySQL Server, MS Access e Postgres, garantindo a integridade referencial dos dados gerados.
Benerator
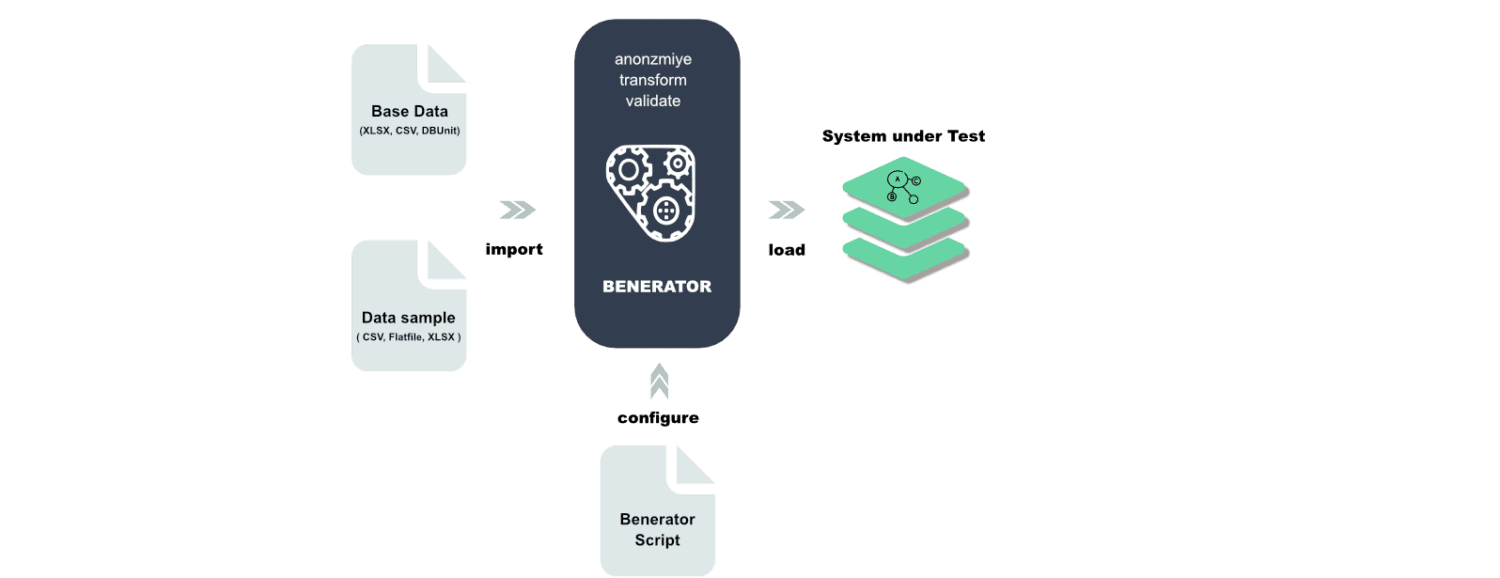
Benerator é um software para ofuscação, geração e migração de dados para fins de teste e treinamento. Com ele, os dados são descritos usando XML (Extensible Markup Language) e gerados por meio da ferramenta de linha de comando. Projetado para ser usado por não desenvolvedores, o Benerator pode gerar bilhões de linhas de dados. É gratuito e de código aberto.
Considerações Finais
Estima-se que, até 2030, a utilização de dados sintéticos para aprendizado de máquina ultrapassará o uso de dados reais, segundo projeções da Gartner. Isso se deve, em grande parte, aos custos e às preocupações com a privacidade associadas aos dados reais. Portanto, é fundamental que as empresas se familiarizem com dados sintéticos e com as diversas ferramentas disponíveis para sua geração.
A seguir, confira as ferramentas de monitoramento sintéticas para o seu negócio online.