A coleta de dados da web, conhecida como “web scraping”, consiste na extração de informações de um website para posterior utilização. Imagine que você precisa capturar uma tabela de dados de uma página web, convertê-la para o formato JSON e usar esse arquivo para alimentar ferramentas internas. Através do web scraping, é possível coletar dados específicos ao direcionar elementos particulares em uma página. A linguagem Python é uma escolha popular para este fim, pois oferece bibliotecas como BeautifulSoup e Scrapy, que facilitam a extração eficiente de dados.
A habilidade de extrair dados de forma eficaz é crucial para desenvolvedores e cientistas de dados. Este artigo visa elucidar como realizar web scraping de forma eficiente, obtendo o conteúdo desejado para manipulação de acordo com suas necessidades. Para este tutorial, utilizaremos o pacote BeautifulSoup, uma ferramenta moderna para coleta de dados em Python.
Por que usar Python para Web Scraping?
Python é a linguagem preferida de muitos desenvolvedores para a criação de scrapers de web. Diversos fatores contribuem para essa preferência, mas neste artigo abordaremos três razões principais:
Bibliotecas e Suporte da Comunidade: Python oferece diversas bibliotecas robustas, como BeautifulSoup, Scrapy e Selenium, que fornecem funções eficazes para coletar dados de páginas web. O ecossistema para web scraping em Python é excelente e, devido ao grande número de desenvolvedores que utilizam a linguagem, o suporte e ajuda em caso de dificuldades são facilmente encontrados.
Automação: Python é reconhecido por suas capacidades de automação. Para além do web scraping, a automação é essencial na criação de ferramentas complexas que dependem da coleta de dados. Por exemplo, se você deseja desenvolver uma ferramenta para rastrear preços de produtos em lojas online, a automação se faz necessária para monitorar as taxas diariamente e adicionar os dados a um banco de dados. Python possibilita automatizar esses processos de forma simples.
Visualização de Dados: Cientistas de dados utilizam amplamente o web scraping para extrair dados de páginas web. Com o auxílio de bibliotecas como Pandas, Python simplifica a visualização de dados a partir de informações brutas.
Bibliotecas para Web Scraping em Python
Existem diversas bibliotecas em Python que facilitam o processo de web scraping. A seguir, apresentaremos as três mais populares:
#1. BeautifulSoup
Uma das bibliotecas mais conhecidas para web scraping, o BeautifulSoup auxilia desenvolvedores na coleta de dados de páginas web desde 2004. Oferece métodos simples para navegar, pesquisar e modificar a árvore de análise, além de lidar com a codificação de dados de entrada e saída. Possui uma vasta comunidade e é constantemente atualizado.
#2. Scrapy
Outro framework popular para extração de dados, o Scrapy possui mais de 43.000 estrelas no GitHub. Pode ser utilizado para extrair dados de APIs e oferece recursos integrados interessantes, como envio de e-mails.
#3. Selenium
Selenium não é primariamente uma biblioteca para web scraping, mas sim um pacote de automação de navegadores. No entanto, suas funcionalidades podem ser estendidas para coletar dados de páginas web. Utiliza o protocolo WebDriver para controlar diferentes navegadores. Embora esteja no mercado há quase 20 anos, Selenium permite automatizar e extrair dados de páginas web com facilidade.
Desafios do Web Scraping com Python
Ao tentar extrair dados de websites, diversos desafios podem surgir, como redes lentas, ferramentas anti-raspagem, bloqueio baseado em IP, e captchas. Esses problemas podem dificultar a coleta de dados de um site.
No entanto, é possível contornar esses desafios seguindo algumas boas práticas. Por exemplo, em muitos casos, um endereço IP é bloqueado quando um grande número de requisições é enviado em um curto intervalo de tempo. Para evitar o bloqueio, é importante programar o scraper para realizar pausas entre as requisições.
Desenvolvedores também costumam utilizar “honeypots” para detectar scrapers. Esses “honeypots” são armadilhas invisíveis para humanos, mas detectáveis por scrapers. Se o site que você está raspando utilizar tais armadilhas, é necessário programar o scraper para lidar com elas.
Captchas são outro problema comum. A maioria dos sites utiliza captchas para proteger o acesso de bots às suas páginas. Nesses casos, pode ser necessário utilizar um solucionador de captcha.
Raspando um Site com Python
Como mencionado, utilizaremos o BeautifulSoup para realizar o web scraping. Neste tutorial, vamos extrair dados históricos do Ethereum do Coingecko e salvar as informações da tabela em um arquivo JSON. Vamos começar a construir o scraper.
O primeiro passo é instalar o BeautifulSoup e a biblioteca Requests. Para este tutorial, utilizaremos o Pipenv, um gerenciador de ambiente virtual para Python. Se preferir, você pode utilizar o Venv. O detalhamento do uso do Pipenv está além do escopo deste artigo, mas você pode consultar este guia se desejar aprender a usá-lo. Caso precise entender o conceito de ambientes virtuais em Python, consulte este guia.
Inicie o shell do Pipenv no diretório do projeto com o comando pipenv shell. Isso abrirá um subshell em seu ambiente virtual. Agora, para instalar o BeautifulSoup, execute o seguinte comando:
pipenv install beautifulsoup4
E, para instalar o Requests, utilize:
pipenv install requests
Com a instalação concluída, importe os pacotes necessários no arquivo principal. Crie um arquivo chamado main.py e importe os pacotes da seguinte forma:
from bs4 import BeautifulSoup import requests import json
O próximo passo é obter o conteúdo da página de dados históricos e analisá-lo utilizando o parser HTML do BeautifulSoup.
r = requests.get('https://www.coingecko.com/en/coins/ethereum/historical_data#panel')
soup = BeautifulSoup(r.content, 'html.parser')
Nesse código, a página é acessada com o método get da biblioteca Requests. O conteúdo analisado é armazenado na variável soup.
A etapa de raspagem propriamente dita começa agora. Primeiramente, é necessário identificar corretamente a tabela no DOM. Ao abrir a página e inspecioná-la usando as ferramentas de desenvolvedor do navegador, você verá que a tabela possui as classes table table-striped text-sm text-lg-normal.
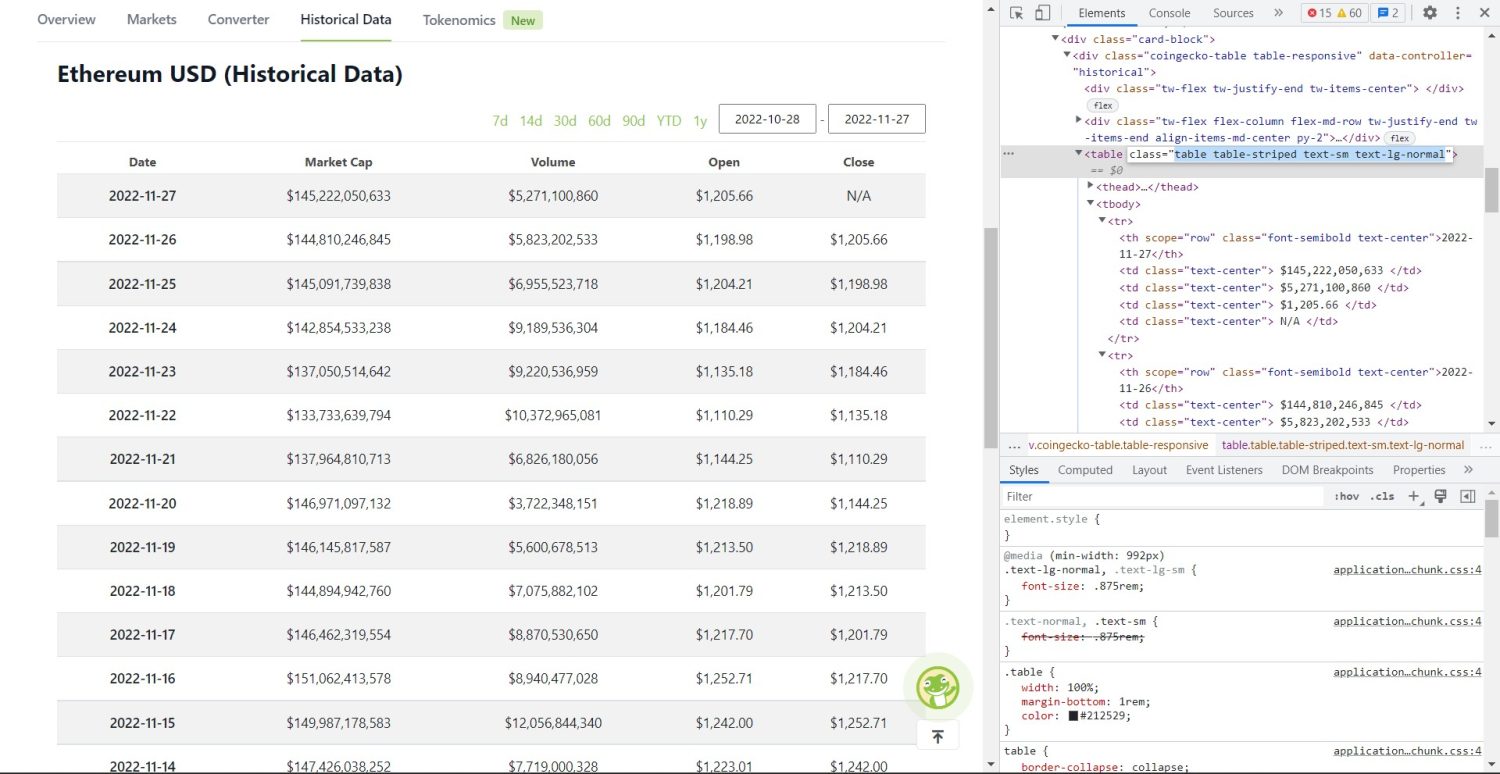
Tabela de dados históricos Coingecko Ethereum
Para selecionar a tabela corretamente, use o método find:
table = soup.find('table', attrs={'class': 'table table-striped text-sm text-lg-normal'})
table_data = table.find_all('tr')
table_headings = []
for th in table_data[0].find_all('th'):
table_headings.append(th.text)
No código acima, a tabela é encontrada utilizando soup.find. Em seguida, find_all é utilizado para selecionar todos os elementos tr dentro da tabela, que são armazenados na variável table_data. A tabela também possui cabeçalhos. Uma nova variável chamada table_headings é inicializada para armazenar os títulos em uma lista.
Um loop for itera sobre a primeira linha da tabela. Nesta linha, todos os elementos th são selecionados e seus valores de texto são adicionados à lista table_headings. O texto é extraído usando o método text. Se você imprimir a variável table_headings neste momento, verá a seguinte saída:
['Date', 'Market Cap', 'Volume', 'Open', 'Close']
O próximo passo é raspar os demais elementos, gerar um dicionário para cada linha e adicionar as linhas a uma lista.
table_details = []
for tr in table_data:
th = tr.find_all('th')
td = tr.find_all('td')
data = {}
for i in range(len(td)):
data.update({table_headings[0]: th[0].text})
data.update({table_headings[i+1]: td[i].text.replace('n', '')})
if data.__len__() > 0:
table_details.append(data)
Esta é a parte central do código. Para cada tr em table_data, os elementos th são selecionados. Os elementos th representam a data mostrada na tabela. Os elementos th são armazenados na variável th. Da mesma forma, todos os elementos td são armazenados em td.
Um dicionário vazio chamado data é criado. Em seguida, o código itera sobre o intervalo dos elementos td. Para cada linha, o primeiro campo do dicionário é atualizado com o primeiro item de th. O código table_headings[0]: th[0].text atribui um par chave-valor com a data e o primeiro elemento.
Após inicializar o primeiro elemento, os demais elementos são atribuídos utilizando data.update({table_headings[i+1]: td[i].text.replace('n', '')}). Aqui, o texto dos elementos td é extraído com text, todos os caracteres ‘n’ são substituídos por vazio com replace, e o valor é atribuído ao i+1-ésimo elemento de table_headings, pois o i-ésimo elemento já foi atribuído.
Se o tamanho do dicionário data for maior que zero, o dicionário é adicionado à lista table_details. Você pode imprimir a lista table_details para verificar. No entanto, vamos salvar os valores em um arquivo JSON. Acompanhe o código para isso:
with open('table.json', 'w') as f:
json.dump(table_details, f, indent=2)
print('Data saved to json file...')
Aqui, utilizamos o método json.dump para gravar os valores em um arquivo JSON chamado table.json. Após a gravação, a mensagem “Data saved to json file…” é impressa no console.
Agora, execute o arquivo com o seguinte comando:
python run main.py
Após algum tempo, a mensagem “Data saved to json file…” será exibida no console. Um novo arquivo chamado table.json será criado no diretório de trabalho. O conteúdo do arquivo será semelhante a:
[
{
"Date": "2022-11-27",
"Market Cap": "$145,222,050,633",
"Volume": "$5,271,100,860",
"Open": "$1,205.66",
"Close": "N/A"
},
{
"Date": "2022-11-26",
"Market Cap": "$144,810,246,845",
"Volume": "$5,823,202,533",
"Open": "$1,198.98",
"Close": "$1,205.66"
},
{
"Date": "2022-11-25",
"Market Cap": "$145,091,739,838",
"Volume": "$6,955,523,718",
"Open": "$1,204.21",
"Close": "$1,198.98"
},
// ...
// ...
]
Você implementou com sucesso um web scraper utilizando Python. O código completo está disponível neste repositório do GitHub.
Conclusão
Este artigo apresentou como implementar um web scraper simples em Python. Explicamos como o BeautifulSoup pode ser utilizado para extrair dados de um site de forma rápida. Também abordamos outras bibliotecas disponíveis e por que Python é a linguagem preferida por muitos desenvolvedores para web scraping.
Você também pode explorar esses outros frameworks de web scraping.