Prometheus é um sistema de monitoramento de código aberto que opera com base em métricas. Ele realiza a coleta de dados provenientes de diversos serviços e hosts, efetuando requisições HTTP a pontos de extremidade específicos para métricas. Os resultados obtidos são então armazenados em um banco de dados de séries temporais, tornando-os acessíveis para análises e a geração de alertas.
A Importância do Monitoramento
- O monitoramento possibilita a ativação de alertas em situações de anomalia, idealmente antes que problemas se manifestem, permitindo a intervenção de equipes responsáveis.
- Ele oferece informações cruciais para a análise, depuração e resolução de problemas técnicos.
- O acompanhamento contínuo permite a identificação de tendências e mudanças ao longo do tempo, como a contagem de sessões ativas em um determinado momento, auxiliando nas decisões de projeto e planejamento de capacidade.
Geralmente, o monitoramento está associado a eventos, que podem incluir o recebimento de uma solicitação HTTP, o envio de uma resposta, operações de leitura em disco ou o login de um usuário. Um sistema de monitoramento pode englobar atividades como a criação de perfis, registro, rastreamento, coleta de métricas, geração de alertas e visualização de dados.
Monitoramento de Caixa Preta versus Caixa Branca
O monitoramento se divide em duas abordagens principais:
Monitoramento de Caixa Preta
Nessa modalidade, o monitoramento ocorre no nível do aplicativo ou do host, analisando-os externamente. Essa abordagem pode apresentar certas limitações.
Monitoramento de Caixa Branca
O monitoramento de caixa branca envolve a análise dos componentes internos de um serviço, expondo dados sobre seu estado e desempenho.
Os Quatro Sinais Dourados
Segundo o Google, se a medição de um sistema voltado para o usuário puder ser restrita a quatro métricas, o foco deve ser dado aos seguintes sinais, conhecidos como os quatro sinais de ouro:
#1. Latência
Este sinal representa o tempo necessário para atender a uma requisição, seja ela bem-sucedida ou não. É fundamental monitorar tanto as requisições bem-sucedidas quanto as que falharam.
#2. Tráfego
Esta métrica quantifica a demanda imposta ao sistema. Em um serviço web, geralmente se refere ao número de solicitações HTTP por segundo.
#3. Erros
Esta métrica indica a taxa de requisições que resultaram em falha.
#4. Saturação
Esta métrica avalia o nível de utilização do serviço. O aumento da latência frequentemente sinaliza a aproximação da saturação. Muitos sistemas começam a apresentar degradação de desempenho bem antes de atingir a capacidade total.
Tipos de Métricas no Prometheus
As métricas do Prometheus se classificam em quatro tipos principais:
#1. Contador
O valor de um contador sempre se incrementa, nunca diminui, embora possa ser resetado para zero. Uma falha na coleta de dados acarreta a perda de um único ponto de dados, mas o incremento cumulativo estará disponível na próxima coleta. Exemplos incluem o número total de requisições HTTP recebidas ou a quantidade de exceções ocorridas.
#2. Medidor
Um medidor captura um instante específico no tempo, podendo aumentar ou diminuir seu valor. Se a coleta de dados falhar, a amostra é perdida, e a próxima leitura pode exibir um valor diferente. Exemplos incluem o espaço livre em disco e o uso de memória.
#3. Histograma
Um histograma agrupa as observações em intervalos configuráveis. Ele é utilizado para analisar dados como a duração de requisições ou o tamanho de respostas. Por exemplo, ao medir a duração de uma requisição HTTP, o histograma pode possuir intervalos como 1 ms, 10 ms e 25 ms. Em vez de armazenar todas as durações individuais, o Prometheus armazena a frequência de requisições que se encaixam em cada intervalo.
#4. Resumo
Semelhante aos histogramas, os resumos coletam amostras de observações, geralmente referentes a durações de requisições ou tamanhos de respostas. Eles fornecem a contagem total de observações e a soma dos valores observados, permitindo o cálculo da média. Por exemplo, em um minuto, se três requisições demoraram 2, 3 e 4 segundos, a soma seria 9 e a contagem 3, resultando em uma latência média de 3 segundos.
Componentes do Ecossistema Prometheus
O Servidor Prometheus
Este componente é responsável pela coleta, armazenamento e disponibilização das métricas para consulta, além de enviar alertas com base nos dados coletados.
Raspagem (Scraping)
Prometheus adota um modelo de coleta de dados por “pull”. Para obter as métricas, o Prometheus envia requisições HTTP, chamadas de “scraping”, a alvos específicos, conforme sua configuração.
Cada alvo, seja definido estaticamente ou descoberto dinamicamente, é “raspado” em um intervalo regular. Cada “raspagem” consulta o endpoint HTTP “/metrics” para obter o estado atual das métricas do cliente, persistindo os valores no banco de dados de séries temporais do Prometheus.
É importante notar que existem outras opções de bancos de dados de séries temporais que podem ser exploradas para soluções de monitoramento.
Bibliotecas de Cliente
Para monitorar um serviço, é necessário instrumentar o código. Existem bibliotecas de cliente disponíveis para várias linguagens e ambientes de execução. Ao adicionar algumas linhas de código, o código pode começar a emitir métricas. Essa abordagem é conhecida como instrumentação direta. Essas bibliotecas permitem definir métricas internas e expô-las via um endpoint HTTP. Quando o Prometheus “raspa” o endpoint, a biblioteca do cliente envia as métricas para o servidor.
O Prometheus oferece bibliotecas de cliente oficiais para Go, Java, Python e Ruby, além de um ecossistema aberto com bibliotecas criadas pela comunidade para C, PHP, Node.js, C#/.NET e outras linguagens.
Exportadores
Muitos aplicativos expõem métricas em formatos não compatíveis com o Prometheus. Em situações como essas, ou quando o código-fonte não está acessível, não é possível adicionar instrumentação direta. Nesses cenários, são utilizados exportadores.
Um exportador é uma ferramenta que atua como um proxy entre o aplicativo e o Prometheus. Ele recebe requisições do servidor Prometheus, coleta dados de logs de acesso ou erros do aplicativo, formata os dados e os envia ao servidor Prometheus.
Alguns exportadores populares incluem:
- Windows – para métricas de servidores Windows.
- Node – para métricas de servidores Linux.
- Blackbox – para métricas de desempenho de sites e DNS.
- JMX – para métricas de aplicativos Java.
Após instrumentar os aplicativos ou instalar os exportadores, é preciso informar ao Prometheus seus locais. Isso pode ser feito através de configuração estática ou, em ambientes dinâmicos, através de descoberta de serviço.
Alertas
O sistema de alertas do Prometheus é composto por duas partes:
Regras de alerta que enviam alertas para o Alertmanager.
O Alertmanager que gerencia esses alertas, enviando notificações por e-mail, Slack, Hipchat e PagerDuty, além de realizar silenciamento ou agregação para reduzir a quantidade de notificações.
Para aprender como monitorar um servidor Linux usando Prometheus e Dashboards, acesse este guia.
Visualização com Dashboards
O Prometheus oferece APIs que utilizam consultas PromQL para gerar dados brutos para visualização.
Embora o Prometheus inclua um navegador de expressões para consultas ad hoc, a melhor ferramenta para essa finalidade é o Grafana. O Grafana se integra totalmente ao Prometheus e permite a criação de diversos dashboards.
É necessário configurar o Prometheus como fonte de dados no Grafana.
É possível adicionar painéis:
- Importando painéis criados pela comunidade
- Criando painéis personalizados
- Utilizando painéis predefinidos
A seguir, um exemplo de um painel predefinido para um exportador de nó:
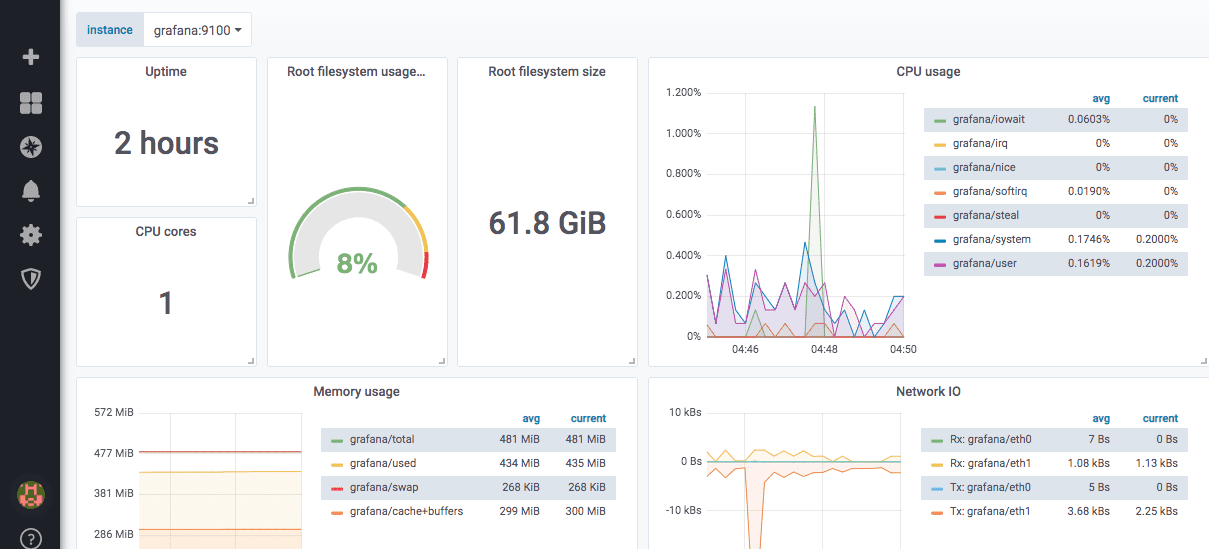
O Grafana também oferece um módulo WorldPing que permite monitorar métricas de desempenho de sites e DNS em diferentes locais do mundo.
Resumo
Prometheus tem poucos requisitos de sistema e é fácil de executar, pois é um binário único com um arquivo de configuração. Ele é capaz de lidar com milhares de alvos e ingerir milhões de amostras por segundo. O Prometheus foi concebido para acompanhar a integridade geral e o comportamento de sistemas.
O Grafana é a ferramenta mais adequada para a visualização de métricas e se integra de forma eficaz com o Prometheus.