O modelo MapReduce apresenta uma abordagem eficaz, ágil e econômica para o desenvolvimento de aplicações.
Essa estrutura emprega conceitos avançados, como processamento paralelo e localidade de dados, proporcionando inúmeros benefícios a programadores e empresas.
No entanto, a variedade de modelos e frameworks de programação disponíveis no mercado torna a escolha um desafio.
Quando o assunto é Big Data, a seleção não pode ser aleatória. É crucial optar por tecnologias capazes de lidar com grandes volumes de dados.
MapReduce surge como uma solução ideal para essa necessidade.
Neste artigo, exploraremos em detalhes o que é MapReduce e como ele pode trazer vantagens significativas.
Vamos começar!
O que é MapReduce?
MapReduce é um paradigma de programação ou estrutura de software dentro do ecossistema Apache Hadoop. Ele é utilizado na criação de aplicativos que processam grandes conjuntos de dados de forma paralela em milhares de nós (clusters ou grades), com resiliência a falhas e alta confiabilidade.
Esse processamento ocorre diretamente no banco de dados ou sistema de arquivos onde os dados estão armazenados. MapReduce pode interagir com o Hadoop File System (HDFS) para acessar e administrar grandes quantidades de dados.
Essa estrutura foi introduzida pelo Google em 2004 e popularizada pelo Apache Hadoop. É uma camada de processamento ou motor dentro do Hadoop, executando programas MapReduce desenvolvidos em diversas linguagens, como Java, C++, Python e Ruby.
Os programas MapReduce em computação em nuvem são executados de forma paralela, tornando-os ideais para análise de dados em larga escala.
O objetivo do MapReduce é dividir uma tarefa complexa em múltiplas subtarefas menores, utilizando as funções “map” e “reduce”. Cada tarefa é mapeada e reduzida a várias tarefas equivalentes, resultando em menor demanda de poder de processamento e redução da sobrecarga na rede do cluster.
Exemplo: Imagine que você está preparando uma refeição para muitos convidados. Se você tentar fazer todos os pratos e processos sozinho, ficará sobrecarregado e levará muito tempo.
No entanto, se você pedir ajuda a amigos ou colegas (não convidados), distribuindo diferentes processos para cada um, a tarefa será executada simultaneamente por várias pessoas. Nesse cenário, você preparará a refeição de forma mais rápida e fácil enquanto seus convidados ainda estão presentes.
MapReduce funciona de maneira similar, empregando tarefas distribuídas e processamento paralelo para permitir a conclusão de uma tarefa de forma mais rápida e eficiente.
O Apache Hadoop permite que programadores usem MapReduce para executar modelos em vastos conjuntos de dados distribuídos, aplicando técnicas avançadas de aprendizado de máquina e estatística para identificar padrões, realizar previsões, detectar correlações e muito mais.
Recursos do MapReduce
Algumas das principais características do MapReduce incluem:
- Interface do Usuário: Uma interface intuitiva que oferece informações detalhadas sobre cada aspecto da estrutura. Facilita a configuração, aplicação e ajuste de suas tarefas de forma fluida.
- Payload: As aplicações utilizam as interfaces Mapper e Reducer para habilitar as funções de mapeamento e redução. O Mapper transforma os pares de valores-chave de entrada em pares de valores-chave intermediários. O Reducer agrupa os pares de valores-chave intermediários que compartilham uma chave, reduzindo-os a valores menores. Ele executa três ações: ordenar, embaralhar e reduzir.
- Particionador: Controla a divisão das chaves intermediárias de saída do mapa.
- Reporter: Uma função para reportar o progresso, atualizar contadores e definir mensagens de status.
- Contadores: Representa contadores globais que uma aplicação MapReduce define.
- OutputCollector: Esta função coleta dados de saída do Mapper ou Reducer em vez de saídas intermediárias.
- RecordWriter: Grava a saída de dados ou pares chave-valor no arquivo de saída.
- DistributedCache: Distribui de forma eficiente arquivos maiores e somente leitura que são específicos da aplicação.
- Compressão de dados: O gravador de aplicações pode compactar as saídas de trabalho e as saídas de mapas intermediários.
- Ignorando registros incorretos: Permite ignorar registros com erros durante o processamento das entradas do mapa. Esse recurso é controlado pela classe SkipBadRecords.
- Depuração: Oferece a opção de executar scripts definidos pelo usuário e habilitar a depuração. Se uma tarefa no MapReduce falhar, você pode executar seu script de depuração e identificar os problemas.
Arquitetura MapReduce
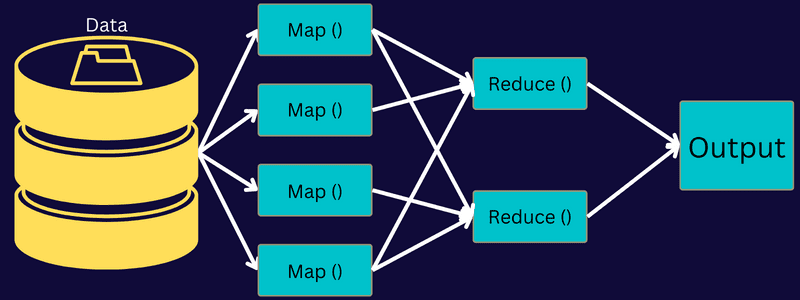
Vamos analisar a arquitetura do MapReduce detalhando seus componentes:
- Trabalho: Um trabalho no MapReduce representa a tarefa que o cliente MapReduce deseja realizar. Ele é composto por diversas tarefas menores que se combinam para formar a tarefa final.
- Job History Server: Um processo daemon que armazena e salva todos os dados históricos sobre uma aplicação ou tarefa, como logs gerados antes ou após a execução de um trabalho.
- Cliente: Um cliente (programa ou API) envia um trabalho para o MapReduce para execução ou processamento. No MapReduce, um ou mais clientes podem enviar continuamente trabalhos ao MapReduce Manager para processamento.
- MapReduce Master: Um MapReduce Master divide um trabalho em várias partes menores, garantindo que as tarefas avancem simultaneamente.
- Partes do Trabalho: As subtarefas ou partes do trabalho são obtidas dividindo-se o trabalho principal. Elas são processadas e combinadas para criar a tarefa final.
- Dados de entrada: O conjunto de dados alimentado ao MapReduce para processamento de tarefas.
- Dados de saída: O resultado final obtido após o processamento da tarefa.
O processo nessa arquitetura se inicia quando o cliente envia um trabalho para o MapReduce Master, que o divide em partes menores e equivalentes. Isso agiliza o processamento, pois tarefas menores levam menos tempo para serem concluídas do que tarefas maiores.
É importante garantir que as tarefas não sejam divididas em partes excessivamente pequenas, pois isso pode gerar uma sobrecarga de gerenciamento das divisões e perda de tempo significativa.
As partes do trabalho são disponibilizadas para prosseguir com as tarefas Mapear e Reduzir. Além disso, as tarefas Mapear e Reduzir utilizam um programa adequado com base no cenário de uso em que a equipe está trabalhando. O programador desenvolve o código baseado na lógica para atender aos requisitos.
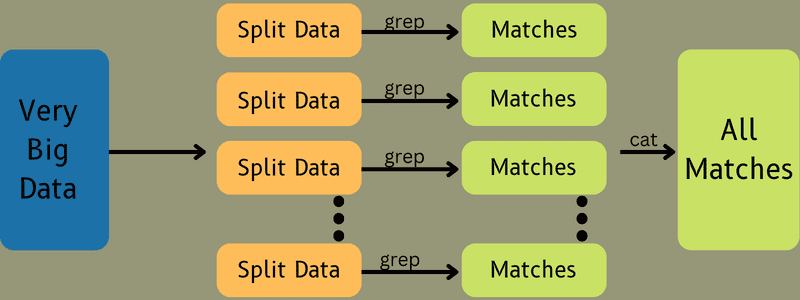
Em seguida, os dados de entrada são direcionados à Tarefa de Mapa, permitindo que o Mapa gere rapidamente a saída como um par chave-valor. Em vez de armazenar esses dados no HDFS, um disco local é utilizado, eliminando a chance de replicação.
Após a conclusão da tarefa, a saída pode ser descartada. A replicação torna-se desnecessária ao armazenar a saída no HDFS. A saída de cada tarefa de mapa é direcionada à tarefa de redução, e a saída do mapa é fornecida à máquina que executa a tarefa de redução.
A saída é então mesclada e encaminhada para a função de redução definida pelo usuário. Finalmente, a saída reduzida é armazenada em um HDFS.
O processo pode incluir várias tarefas de Mapa e Redução para processamento de dados, dependendo do objetivo final. Os algoritmos Map e Reduce são otimizados para manter a complexidade de tempo e espaço mínima.
Como o MapReduce se concentra principalmente nas tarefas Mapear e Reduzir, é fundamental entender melhor essas etapas. Vamos agora discutir as fases do MapReduce para obter uma visão clara desses tópicos.
Fases do MapReduce
Mapa
Nesta fase, os dados de entrada são mapeados para pares de saída ou chave-valor. A chave pode se referir ao ID de um endereço, enquanto o valor pode ser o valor real desse endereço.
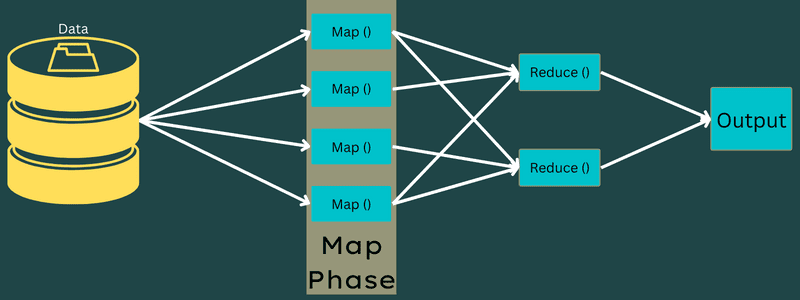
Existem duas tarefas nesta fase: divisões e mapeamento. Divisões referem-se às subpartes ou partes do trabalho divididas do trabalho principal, também conhecidas como divisões de entrada. Uma divisão de entrada é, portanto, uma porção de entrada consumida por um mapa.
Em seguida, ocorre a tarefa de mapeamento. É a primeira fase durante a execução de um programa de redução de mapa. Os dados contidos em cada divisão são passados para uma função de mapa para processar e gerar a saída.
A função Map() é executada no repositório de memória nos pares chave-valor de entrada, gerando um par chave-valor intermediário. Este novo par chave-valor servirá como entrada para a função Reduce() ou Reducer.
Reduzir
Os pares chave-valor intermediários obtidos na fase de mapeamento servem como entrada para a função Reduce ou Reducer. Assim como na fase de mapeamento, duas tarefas estão envolvidas: embaralhar e reduzir.
Os pares chave-valor obtidos são ordenados e embaralhados para serem encaminhados ao Redutor. Em seguida, o Redutor agrupa ou agrega os dados de acordo com seu par chave-valor, com base no algoritmo do redutor que o desenvolvedor escreveu.
Nesta fase, os valores da etapa de embaralhamento são combinados para retornar um valor de saída. Essa fase resume todo o conjunto de dados.
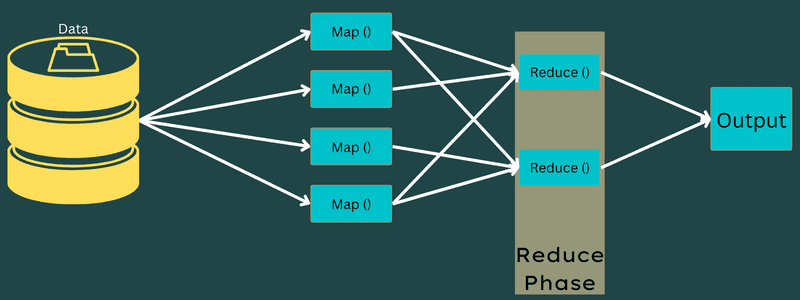
O processo completo de execução das tarefas Mapear e Reduzir é controlado por algumas entidades, que incluem:
- Job Tracker: Em termos simples, um job tracker atua como um mestre responsável por executar completamente um trabalho enviado. O rastreador de trabalhos gerencia todos os trabalhos e recursos em um cluster. Além disso, o rastreador de tarefas agenda cada mapa adicionado no rastreador de tarefas que é executado em um nó de dados específico.
- Vários rastreadores de tarefas: Vários rastreadores de tarefas atuam como escravos, executando tarefas seguindo as instruções do Job Tracker. Um rastreador de tarefas é implantado em cada nó do cluster, executando as tarefas Mapear e Reduzir.
O processo funciona porque um trabalho é dividido em várias tarefas que são executadas em diferentes nós de dados de um cluster. O Job Tracker é responsável por coordenar a tarefa, agendando as tarefas e executando-as em vários nós de dados. O Task Tracker, localizado em cada nó de dados, executa partes do trabalho e supervisiona cada tarefa.
Os rastreadores de tarefas enviam relatórios de progresso para o rastreador de tarefas. Além disso, o Task Tracker envia periodicamente um sinal de “pulsação” para o Job Tracker, notificando-o sobre o status do sistema. Em caso de falha, um rastreador de tarefas é capaz de reprogramar o trabalho em outro rastreador de tarefas.
Fase de saída: Ao atingir esta fase, você terá os pares chave-valor finais gerados pelo Redutor. Você pode usar um formatador de saída para traduzir os pares chave-valor e gravá-los em um arquivo com a ajuda de um gravador de registros.
Por que usar o MapReduce?
A seguir, alguns dos benefícios do MapReduce, explicando as razões pelas quais você deve usá-lo em seus aplicativos de big data:
Processamento paralelo
Com o MapReduce, um trabalho pode ser dividido em diferentes nós, onde cada nó manipula simultaneamente uma parte desse trabalho. Dividir tarefas maiores em menores diminui a complexidade. Além disso, como diferentes tarefas são executadas em paralelo em máquinas diferentes em vez de em uma única máquina, o tempo necessário para processar os dados é significativamente reduzido.
Localidade dos dados
No MapReduce, você pode mover a unidade de processamento para os dados, e não o contrário.
Tradicionalmente, os dados eram levados para a unidade de processamento para processamento. No entanto, com o rápido crescimento dos dados, esse processo começou a apresentar muitos desafios, como custo mais alto, mais tempo gasto, sobrecarga do nó mestre, falhas frequentes e desempenho de rede reduzido.
MapReduce ajuda a superar esses problemas seguindo uma abordagem inversa, levando uma unidade de processamento para os dados. Dessa forma, os dados são distribuídos entre diferentes nós, onde cada nó pode processar uma parte dos dados armazenados.
Como resultado, essa abordagem é econômica e reduz o tempo de processamento, pois cada nó trabalha em paralelo com sua parte de dados correspondente. Além disso, como cada nó processa uma parte desses dados, nenhum nó fica sobrecarregado.
Segurança

O modelo MapReduce oferece maior segurança, protegendo seu aplicativo contra dados não autorizados e melhorando a segurança do cluster.
Escalabilidade e Flexibilidade
MapReduce é uma estrutura altamente escalável que permite executar aplicativos em várias máquinas, utilizando dados com milhares de terabytes. Oferece flexibilidade no processamento de dados, que podem ser estruturados, semiestruturados ou não estruturados, em qualquer formato ou tamanho.
Simplicidade
É possível escrever programas MapReduce em diversas linguagens de programação, como Java, R, Perl, Python, etc. Isso facilita o aprendizado e a escrita de programas, garantindo que os requisitos de processamento de dados sejam atendidos.
Casos de uso do MapReduce
- Indexação de texto completo: MapReduce é utilizado para realizar a indexação de texto completo. O Mapeador pode mapear cada palavra ou frase em um documento, enquanto o Redutor grava todos os elementos mapeados em um índice.
- Cálculo do Pagerank: O Google utiliza MapReduce para calcular o Pagerank.
- Análise de log: MapReduce pode analisar arquivos de log, dividindo um grande arquivo de log em várias partes e utilizando o mapeador para procurar páginas da web acessadas.
Um par chave-valor é encaminhado ao redutor se uma página da web for identificada no log. A página da web será a chave e o índice “1” será o valor. Após fornecer um par de valores-chave ao Redutor, várias páginas da web são agregadas. A saída final é o número total de acessos para cada página da web.

- Gráfico de links da web reverso: A estrutura também é utilizada no Gráfico de links da web reverso. O Map() produz o destino da URL e a origem, recebendo a entrada da origem ou da página da web.
O Reduce() agrega a lista de cada URL de origem associada ao URL de destino, gerando finalmente as fontes e o destino.
- Contagem de palavras: MapReduce é usado para contar quantas vezes uma palavra aparece em um determinado documento.
- Aquecimento global: Organizações, governos e empresas podem usar MapReduce para resolver problemas de aquecimento global.
Por exemplo, se você deseja saber sobre o aumento do nível de temperatura do oceano devido ao aquecimento global, é possível coletar milhares de dados em todo o mundo, incluindo dados de alta temperatura, baixa temperatura, latitude, longitude, data, hora, etc. Várias tarefas de mapa e redução serão necessárias para calcular a saída usando MapReduce.
- Testes de medicamentos: Tradicionalmente, cientistas de dados e matemáticos trabalhavam juntos para formular novos medicamentos para combater doenças. Com a disseminação de algoritmos e MapReduce, os departamentos de TI das organizações podem resolver questões que antes eram tratadas apenas por supercomputadores e cientistas com doutorado. Agora é possível inspecionar a eficácia de um medicamento em um grupo de pacientes.
- Outras aplicações: MapReduce pode processar dados em larga escala que não caberiam em um banco de dados relacional. Ele também utiliza ferramentas de ciência de dados, permitindo executá-las em diferentes conjuntos de dados distribuídos, o que antes era possível apenas em um único computador.
Devido à sua robustez e simplicidade, MapReduce encontra aplicações em diversas áreas, como militar, empresarial e científica.
Conclusão
MapReduce representa um avanço significativo na tecnologia, oferecendo um processo mais rápido, simples, econômico e menos demorado. Suas vantagens e uso crescente sugerem uma maior adoção em todos os setores e organizações.
Você também pode explorar alguns dos melhores recursos para aprender sobre Big Data e Hadoop.