O Reconhecimento de Entidades Nomeadas (NER) apresenta uma via eficaz para a compreensão de informações textuais, identificando e categorizando elementos específicos dentro do texto para diversas aplicações.
Desde a classificação de nomes de pessoas até a identificação de datas, organizações, locais e muito mais, o NER abre portas para um entendimento aprimorado da linguagem.
Muitas organizações lidam diariamente com grandes volumes de dados, incluindo conteúdo textual, informações pessoais, opiniões de clientes, detalhes de produtos e outros.
Quando surge a necessidade de informações imediatas, as operações de busca podem demandar tempo, energia e recursos significativos, especialmente quando lidamos com grandes conjuntos de dados.
Para fornecer às organizações uma solução eficaz para busca e localização de dados precisos, o NER se apresenta como uma excelente alternativa.
Neste artigo, abordaremos em detalhes o NER, explorando seu conceito matemático, suas diversas aplicações e outros pontos relevantes.
Vamos começar!
O que é o Reconhecimento de Entidade Nomeada?
O Reconhecimento de Entidades Nomeadas (NER) é uma técnica de Processamento de Linguagem Natural (PNL) capaz de identificar e classificar entidades em dados textuais não estruturados.
Essas entidades englobam uma variedade de informações, como organizações, localidades, nomes de pessoas, valores numéricos, datas e outros. Ele possibilita que as máquinas extraiam essas entidades, tornando-se uma ferramenta útil para aplicações como tradução, respostas a perguntas, e outras, em diversos setores.
Fonte: Scaler
Assim, o NER busca localizar e classificar as entidades dentro de um texto não estruturado em categorias pré-definidas, como organizações, códigos médicos, quantias, nomes de indivíduos, porcentagens, valores monetários, expressões de tempo e muito mais.
Vamos exemplificar:
[William] adquiriu um imóvel da [Z1 Corp.] em [2023]. Os elementos entre colchetes representam as entidades identificadas pelo NER. Elas são classificadas como:
- William – Nome de pessoa
- Z1 Corp. – Organização
- 2023 – Tempo
O NER encontra aplicações em diversas áreas da Inteligência Artificial (IA), incluindo aprendizado profundo, aprendizado de máquina (ML) e redes neurais. É um componente crucial em sistemas de PNL, como ferramentas de análise de sentimento, mecanismos de busca e chatbots. Além disso, é utilizado em finanças, suporte ao cliente, ensino superior, saúde, recursos humanos e análise de mídias sociais.
Em termos simples, o NER identifica, classifica e extrai informações essenciais de textos não estruturados, sem necessidade de análise humana. Ele agiliza a extração de informações relevantes de grandes volumes de dados.
Além disso, o NER fornece insights valiosos para sua organização sobre produtos, tendências de mercado, clientes e concorrência. Por exemplo, instituições de saúde utilizam o NER para extrair dados médicos importantes de registros de pacientes. Muitas empresas o empregam para identificar menções em publicações.
Conceitos Fundamentais: NER

É essencial compreender os conceitos básicos envolvidos no NER. Vamos explorar alguns termos-chave relacionados ao NER que você deve conhecer.
- Entidade Nomeada: Refere-se a qualquer termo que se refira a um local, organização, pessoa ou outra entidade.
- Corpus: É uma coleção de textos diversos utilizada para analisar a linguagem e treinar modelos de NER.
- Marcação POS: É o processo de rotular o texto de acordo com sua função gramatical, como adjetivos, verbos e substantivos.
- Chunking: É o processo de agrupar palavras em frases significativas, com base na estrutura sintática e na classe gramatical.
- Dados de Treinamento e Teste: Refere-se ao processo de treinar um modelo com dados rotulados e avaliar seu desempenho em outro conjunto de dados.
Aplicações do NER em PNL

O NER tem diversas aplicações em PNL, incluindo análise de sentimento, sistemas de recomendação, resposta a perguntas, extração de informações e outras.
- Análise de Sentimento: O NER é utilizado para detectar o sentimento expresso em uma frase ou parágrafo em relação a uma entidade nomeada específica, como um produto ou serviço. Essas informações são utilizadas para melhorar a experiência do cliente e identificar áreas de melhoria.
- Sistemas de Recomendação: O NER é utilizado para identificar as preferências e interesses dos usuários com base nas entidades nomeadas mencionadas em interações online ou consultas de pesquisa. Essas informações são utilizadas para personalizar recomendações.
- Resposta a Perguntas: O NER é utilizado para detectar entidades específicas em um texto, que são posteriormente usadas para responder a uma pergunta específica. Essa técnica é comumente empregada em assistentes virtuais e chatbots.
- Extração de Informações: O NER é usado para extrair informações essenciais de grandes volumes de texto não estruturado, incluindo posts em mídias sociais, avaliações online, artigos de notícias e outros. Essas informações são usadas para gerar insights valiosos e tomar decisões baseadas em dados.
Conceitos Matemáticos: NER
O processo de NER envolve diversos conceitos matemáticos, incluindo aprendizado de máquina, aprendizado profundo, teoria da probabilidade e outros. Abaixo estão algumas técnicas matemáticas:
- Modelos Ocultos de Markov: Modelos Ocultos de Markov (HMMs) são uma abordagem estatística para tarefas de classificação sequencial, como o NER. Eles envolvem representar uma sequência de palavras em um texto como diferentes estados, onde cada estado representa uma entidade nomeada específica. A análise das probabilidades permite identificar as entidades nomeadas no texto.
- Aprendizado Profundo: Técnicas de aprendizado profundo, como redes neurais, são empregadas em tarefas de NER. Isso permite identificar e categorizar entidades nomeadas com eficiência e precisão.
- Campos Aleatórios Condicionais: São modelos gráficos usados em tarefas de rotulagem de sequências. Eles oferecem modelagem de probabilidade condicional de cada tag, considerando a sequência de palavras, o que possibilita a identificação de entidades nomeadas em um texto.
Como o NER Funciona?
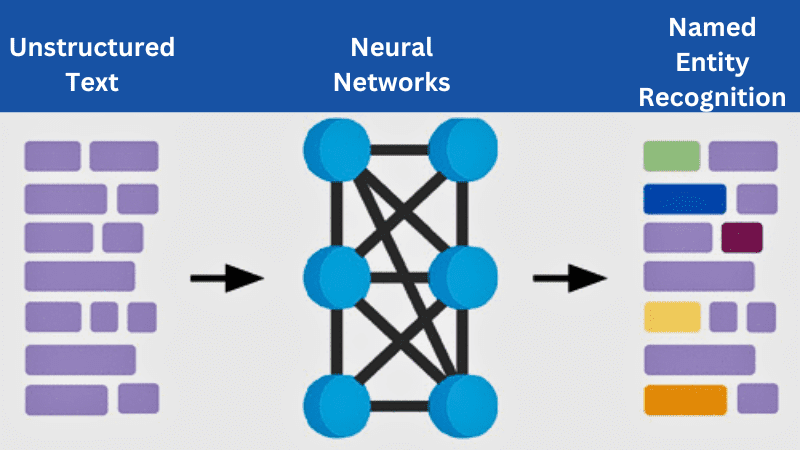 Fonte: Publicações ACS
Fonte: Publicações ACS
O Reconhecimento de Entidades Nomeadas (NER) funciona como uma extração de informações. Seu funcionamento é dividido em etapas principais:
#1. Pré-Processamento do Texto
Nesta primeira etapa, o NER prepara as informações textuais para análise. Isso geralmente envolve tarefas como a tokenização, onde o texto é inicialmente dividido em unidades (tokens) antes que o NER comece a identificar as entidades.
Por exemplo, a frase “Bill Gates fundou a Microsoft” pode ser dividida em tokens como “Bill”, “Gates”, “fundou” e “Microsoft”.
#2. Identificação de Entidades
Entidades nomeadas potenciais são detectadas utilizando métodos estatísticos ou regras linguísticas. Esta etapa envolve o reconhecimento de padrões, como formatos específicos (datas) ou letras maiúsculas em nomes (“Bill Gates”). Após o pré-processamento, os algoritmos de NER examinam o texto em busca de palavras ou sequências que correspondam a entidades.
#3. Classificação de Entidades
Depois que o NER identifica as entidades, ele as categoriza em tipos, classes ou grupos. As categorias mais comuns são organização, data, local, pessoa e outras. Isso é feito utilizando modelos de aprendizado de máquina treinados com dados rotulados.
Por exemplo, “Bill Gates” seria reconhecido como uma “pessoa” e “Microsoft” como uma “organização”.
#4. Análise Contextual
O NER não se limita apenas a reconhecer e classificar entidades. Ele também considera o contexto para aumentar a precisão. Esta etapa analisa o contexto em que as entidades aparecem, para fornecer uma categorização precisa.
Por exemplo, na frase “Bill Gates fundou a Microsoft”, o contexto permite que o sistema identifique “Bill” como o nome de uma pessoa e não como uma fatura de pagamento.
#5. Pós-Processamento
Após a identificação e categorização inicial, é necessário um pós-processamento para refinar os resultados finais. Isso envolve a resolução de ambiguidades, o uso de bases de conhecimento, a fusão de entidades com vários tokens e outros procedimentos para aprimorar os dados das entidades.
O interessante sobre o NER é sua capacidade de interpretar e compreender textos não estruturados, que podem conter dados essenciais para seu negócio. Ele obtém dados relevantes de artigos de notícias, páginas web, artigos de pesquisa, posts em mídias sociais e outras fontes.
Ao reconhecer e categorizar entidades nomeadas, o NER adiciona uma camada extra de significado e estrutura ao conteúdo textual.
Métodos de NER

Os métodos mais comumente utilizados são os seguintes:
#1. Método Baseado em Aprendizado de Máquina Supervisionado
Este método utiliza modelos de aprendizado de máquina treinados em textos pré-rotulados por humanos com categorias de entidades nomeadas.
Essa abordagem utiliza algoritmos, incluindo entropia máxima e campos aleatórios condicionais, para obter modelos de linguagem estatística complexos. É eficaz na resolução de ambiguidades linguísticas e outras complexidades, mas exige grandes volumes de dados de treinamento para funcionar adequadamente.
#2. Sistemas Baseados em Regras
Este método utiliza diversas regras para coletar informações. Inclui títulos ou letras maiúsculas, como “Dr.”. Este método requer muita intervenção humana para fazer sugestões, monitorar e ajustar as regras. Ele pode perder variações textuais que não estão incluídas nas anotações de treinamento. É por isso que os sistemas baseados em regras são incapazes de lidar com a complexidade e os modelos de aprendizado de máquina.
#3. Sistemas Baseados em Dicionário
Neste método, um dicionário que contém uma grande quantidade de sinônimos e um vocabulário extenso é utilizado para identificar e verificar identidades nomeadas. Este método apresenta dificuldades na categorização de entidades nomeadas que possuem diversas variações de grafia.
Além desses, existem muitos outros métodos de NER emergentes. Vamos explorá-los também:
#4. Sistemas de Aprendizado de Máquina Não Supervisionados
Esses sistemas de ML utilizam modelos de aprendizado de máquina que não são pré-treinados em dados textuais. Modelos de aprendizado não supervisionado são capazes de executar tarefas mais complexas do que modelos supervisionados.
#5. Sistemas de Bootstrapping
Sistemas de bootstrapping, também conhecidos como sistemas autossupervisionados, categorizam entidades nomeadas dependendo de características gramaticais, incluindo marcas de classes gramaticais, letras maiúsculas e outras categorias pré-treinadas.
Um profissional então ajusta o sistema de bootstrapping, marcando as previsões do sistema como incorretas ou corretas, e adicionando as corretas ao novo conjunto de treinamento.
#6. Sistemas de Redes Neurais
Ele constrói o modelo de reconhecimento de entidade nomeada utilizando modelos de aprendizado de arquitetura bidirecional (representações de codificador bidirecional de transformadores), redes neurais e técnicas de codificação. Este método minimiza a necessidade de interação humana.
#7. Sistemas Estatísticos
Este método utiliza modelos probabilísticos treinados em relações e padrões textuais. Ele auxilia na previsão de entidades nomeadas com base em novos dados de texto.
#8. Sistemas de Rotulagem de Papéis Semânticos
Este sistema pré-processa um modelo de reconhecimento de entidade nomeada utilizando técnicas de aprendizado semântico que ensinam a relação entre as categorias e o contexto.
#9. Sistemas Híbridos
Este método é interessante pois utiliza aspectos de diversas abordagens de maneira combinada.
Benefícios do NER
Os modelos de NER oferecem inúmeros benefícios.
- O NER automatiza o processo de extração de dados de grandes volumes de informação.
- É utilizado em diversas áreas para extrair informações importantes de texto não estruturado.
- Economiza tempo para você e seus funcionários na execução de tarefas de extração de dados.
- Aumenta a precisão dos processos e tarefas de PNL.
- Garante a segurança de dados, hospedando modelos de NER personalizados, eliminando a necessidade de compartilhar informações confidenciais com fornecedores terceirizados.
- Acomoda novos tipos de entidades e terminologias à medida que o domínio evolui.
Desafios do NER
- Ambiguidade: Muitas palavras podem ser ambíguas dentro de um texto. Por exemplo, a palavra “Amazonas” pode se referir a uma empresa, um rio ou uma floresta. A diferenciação pode ser feita com base no contexto, o que torna o reconhecimento de entidades mais desafiador.
- Dependência de Contexto: Palavras derivadas do contexto podem ter significados diferentes. Por exemplo, “Apple” em um texto sobre tecnologia se refere à empresa, enquanto em outro contexto pode se referir à fruta. Identificar a entidade correta pode ser difícil.
- Escassez de Dados: Para métodos de NER baseados em ML, a disponibilidade de dados rotulados é fundamental. No entanto, extrair esses dados, especialmente para domínios especializados ou idiomas menos comuns, pode ser um desafio.
- Variações Linguísticas: A língua humana possui formas diferentes, dependendo de dialetos, diferenças regionais e gírias. Extrair textos de diferentes línguas pode ser um desafio.
- Generalização de Modelo: Modelos de NER podem ser excelentes na classificação de entidades em um domínio específico, mas podem apresentar dificuldades ao generalizar para outro domínio. Portanto, modelos de NER podem se comportar de maneira diferente em diferentes domínios.
Esses desafios podem ser superados com a combinação de algoritmos avançados, conhecimento linguístico e dados de qualidade. Como a área de NER está em constante evolução, equipes de pesquisa e desenvolvimento devem continuar aperfeiçoando diversas técnicas para enfrentar esses desafios.
Casos de Uso do NER
#1. Categorização de Conteúdo

Editoras e agências de notícias produzem um grande volume de conteúdo online. Gerenciar esse conteúdo de maneira eficiente é fundamental para maximizar o valor de cada artigo ou notícia.
O Reconhecimento de Entidades Nomeadas verifica o conteúdo de forma automática e extrai dados como organizações, locais e nomes de pessoas mencionados. Conhecer as tags relevantes de cada artigo ajuda a categorizá-los dentro de uma hierarquia definida, melhorando a entrega do conteúdo.
#2. Algoritmos de Busca
Imagine um algoritmo de busca interno para uma editora online com milhões de artigos. A cada busca, o algoritmo precisa reunir todas as palavras de cada artigo, o que pode consumir muito tempo.
Utilizando o NER, a editora pode obter as entidades principais de cada artigo e armazená-las separadamente, agilizando o processo de busca.
#3. Recomendações de Conteúdo
Automatizar o processo de recomendação é um caso de uso importante do NER. Sistemas de recomendação auxiliam na descoberta de novas ideias e conteúdos.
A Netflix é um excelente exemplo disso. A construção de um sistema de recomendação eficiente ajuda a aumentar o engajamento do usuário.
Para editoras de notícias, o NER pode ser usado para recomendar artigos semelhantes. Isso pode ser feito coletando tags de um artigo específico e recomendando outros conteúdos que possuam entidades similares.
#4. Suporte ao Cliente

O suporte ao cliente é essencial para qualquer organização. Por isso, existem várias maneiras de facilitar o tratamento do feedback do cliente. O NER é uma delas. Vamos analisar um exemplo:
Imagine que um cliente deixe um feedback como: “A equipe da loja da Adidas em San Diego não tinha informações detalhadas sobre calçados esportivos”. O NER identifica as tags “San Diego” (local) e “calçados esportivos” (produto).
Assim, o NER é utilizado para classificar cada reclamação e encaminhá-la ao departamento apropriado da organização para que a situação seja resolvida. É possível desenvolver um banco de dados com feedback categorizado e analisar cada feedback.
#5. Artigos de Pesquisa
Publicações online ou sites de periódicos contêm muitos artigos acadêmicos e trabalhos de pesquisa. É possível encontrar centenas de artigos similares sobre temas semelhantes, com pequenas variações. Organizar todos esses dados de forma estruturada pode ser uma tarefa complicada.
Para agilizar esse processo, os artigos podem ser separados com base nas tags relevantes.
Por exemplo, existem milhares de artigos sobre aprendizado de máquina. Para encontrar um que mencione o uso de redes neurais convolucionais (CNNs), é necessário colocar entidades nos artigos. Isso ajudará a encontrar o artigo rapidamente.
Conclusão
A técnica de PNL chamada Reconhecimento de Entidades Nomeadas (NER) auxilia na identificação de entidades em textos não estruturados, classificando-as em grupos pré-definidos como locais, nomes de pessoas, produtos e outros.
O objetivo principal do NER é reunir informações estruturadas de textos não estruturados e apresentá-las em um formato legível. Ele envolve diversos modelos e processos, trazendo inúmeros benefícios para profissionais e empresas. Além disso, é utilizado em diversas aplicações fora do campo da PNL.
Espero que a explicação detalhada sobre essa técnica tenha sido útil para você implementá-la em seu negócio e obter informações valiosas e relevantes em tempo hábil.
Você também pode explorar alguns dos melhores cursos de PNL para aprender mais sobre processamento de linguagem natural.