Vantagens do Apache Parquet sobre o CSV no Armazenamento de Dados
O Apache Parquet apresenta diversas vantagens na forma como dados são armazenados e recuperados, especialmente quando comparado a abordagens mais tradicionais como o CSV.
Este formato, o Parquet, foi desenvolvido para acelerar o processamento de dados mais complexos. Neste artigo, vamos explorar como ele se adapta às demandas atuais por dados, que estão em constante crescimento.
Antes de nos aprofundarmos nas particularidades do Parquet, é importante entendermos o que são dados CSV e quais os desafios que eles impõem para o armazenamento de informações.
O que é o Armazenamento CSV?
O formato CSV (Comma Separated Values), ou “valores separados por vírgula” é um formato comum para organizar e formatar dados. O armazenamento de dados CSV é organizado em linhas, com arquivos salvos com a extensão .csv. Estes arquivos podem ser abertos e visualizados em ferramentas como Excel, Planilhas Google ou qualquer editor de texto, com os dados sendo facilmente apresentados.
Entretanto, essa simplicidade não é ideal para um formato de banco de dados.
Além disso, conforme o volume de dados aumenta, consultar, gerenciar e recuperar informações torna-se cada vez mais difícil.
Um exemplo de dados armazenados em um arquivo .CSV é apresentado abaixo:
EmpId,Nome,Sobrenome,Departamento 2012011,Sam,Butcher,TI 2013031,Mike,Johnson,Recursos Humanos 2010052,Bill,Matthew,Arquitetura 2010079,Jose,Brian,TI 2012120,Adam,James,Soluções
Se abrirmos este arquivo no Excel, veremos uma estrutura com linhas e colunas, como esta:
Desafios do Armazenamento CSV
Formatos de armazenamento baseados em linha como o CSV são convenientes para operações de criação, atualização e exclusão (CRUD).
Mas, e a leitura (o “R” do CRUD)?
Imagine um arquivo .csv com milhões de linhas. Abrir este arquivo e procurar dados específicos pode levar um tempo considerável. Além disso, muitos serviços de nuvem, como a AWS, cobram com base na quantidade de dados escaneados ou armazenados, e arquivos CSV podem ocupar muito espaço.
O armazenamento CSV também não oferece um lugar específico para metadados, o que torna a verificação dos dados uma tarefa demorada.
Qual seria a solução ideal e econômica para realizar todas as operações CRUD? Vamos descobrir.
O que é o Armazenamento de Dados Parquet?
Parquet é um formato de armazenamento de código aberto, bastante utilizado em ecossistemas como Hadoop e Spark. Arquivos Parquet são salvos com a extensão .parquet.
O Parquet é um formato altamente estruturado, ideal para otimizar dados brutos e complexos presentes em grandes volumes em data lakes, reduzindo significativamente o tempo de consulta.
O Parquet otimiza tanto o armazenamento quanto a recuperação de dados graças a uma combinação de formatos de armazenamento em linha e coluna (híbrido). Os dados são divididos tanto horizontal quanto verticalmente, e o formato também elimina grande parte da sobrecarga da análise.
Este formato limita o número total de operações de entrada/saída (E/S), diminuindo os custos.
O Parquet também armazena metadados, como o esquema de dados, quantidade de valores, localização das colunas, valores mínimo e máximo, número de grupos de linhas e tipo de codificação. Estes metadados são armazenados em diferentes níveis do arquivo, agilizando o acesso aos dados.
Em acessos baseados em linha como o CSV, a recuperação de dados é mais lenta, já que a consulta precisa percorrer cada linha para obter valores de colunas específicas. Já no armazenamento Parquet, todas as colunas necessárias podem ser acessadas simultaneamente.
Em resumo:
- O Parquet utiliza uma estrutura colunar para armazenamento de dados.
- É um formato otimizado para armazenar dados complexos em grandes volumes em sistemas de armazenamento.
- O formato Parquet oferece diferentes métodos de compressão e codificação de dados.
- Ele diminui consideravelmente o tempo de verificação de dados e o tempo de consulta, além de ocupar menos espaço em disco comparado a outros formatos de armazenamento, como o CSV.
- O Parquet minimiza o número de operações de E/S, reduzindo o custo de armazenamento e execução de consultas.
- Inclui metadados que facilitam a localização de dados.
- Oferece suporte de código aberto.
Formato de Dados do Parquet
Para entender melhor como os dados são armazenados no formato Parquet, vamos explorar os detalhes:
Um arquivo pode conter várias partições horizontais, chamadas de grupos de linhas. Dentro de cada grupo, o particionamento vertical é aplicado: as colunas são divididas em blocos, onde os dados são armazenados como páginas, contendo valores codificados e metadados. Os metadados de todo o arquivo também são armazenados no rodapé, no nível do grupo de linhas.
Como os dados são divididos em blocos de colunas, fica mais fácil adicionar novos dados: os novos valores são codificados em um novo bloco e adicionados ao arquivo, com os metadados sendo atualizados para os arquivos e grupos de linhas afetados. Assim, o Parquet é um formato bastante flexível.
O Parquet oferece suporte nativo à compressão de dados, usando técnicas de compressão de página e codificação de dicionário. Veja um exemplo simples de compressão de dicionário:
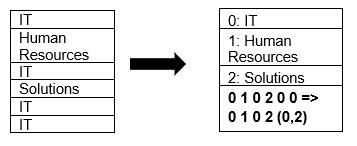
No exemplo acima, a divisão “TI” aparece quatro vezes. Ao armazenar usando um dicionário, o formato codifica os dados com um valor fácil de armazenar (0,1,2…) junto com o número de vezes que ele se repete. Ou seja, “TI” é transformado em “0,2”, economizando espaço. Consultar dados compactados também leva menos tempo.
Comparação Direta
Com uma ideia clara sobre os formatos CSV e Parquet, vamos às comparações:
| Característica | CSV | Parquet |
| Formato de armazenamento | Baseado em linha. | Híbrido: baseado em linha e em coluna. |
| Consumo de espaço | Ocupa muito espaço, sem opções de compressão padrão. Ex: 1 TB ocupa o mesmo espaço em um serviço como o Amazon S3. | Comprime dados durante o armazenamento, consumindo menos espaço. Ex: 1 TB no formato Parquet ocupa apenas 130 GB. |
| Tempo de consulta | Lento, devido à busca baseada em linha. Cada linha de dados deve ser acessada para cada coluna. | Cerca de 34 vezes mais rápido, graças ao armazenamento baseado em colunas e à presença de metadados. |
| Verificação de dados | Requer que mais dados sejam verificados para cada consulta. | Verifica cerca de 99% menos dados para executar uma consulta, otimizando o desempenho. |
| Custos de armazenamento | A maioria dos dispositivos de armazenamento cobra pelo espaço de armazenamento; o formato CSV implica em altos custos. | Menores custos, já que os dados são armazenados de forma compactada e codificada. |
| Esquema do arquivo | Precisa ser inferido (levando a erros) ou fornecido (o que pode ser tedioso). | Armazenado nos metadados. |
| Tipos de dados | Adequado para tipos de dados simples. | Ideal para tipos complexos, como esquemas aninhados, arrays e dicionários. |
Conclusão 👩💻
Com exemplos práticos, fica claro que o Parquet é mais eficiente que o CSV em termos de custo, flexibilidade e desempenho. Este formato é uma ferramenta poderosa para armazenar e recuperar dados, especialmente em um cenário onde o armazenamento em nuvem e a otimização do espaço são cada vez mais importantes. As principais plataformas, como Azure, AWS e BigQuery, oferecem suporte ao formato Parquet.