Neste artigo, vamos explorar a vetorização, uma técnica fundamental no Processamento de Linguagem Natural (PNL), detalhando seu significado e apresentando um guia abrangente sobre os diversos tipos de vetorização disponíveis.
Anteriormente, abordamos os princípios básicos do pré-processamento em PNL e a limpeza de texto. Exploramos os fundamentos da PNL, suas variadas aplicações e técnicas como a tokenização, normalização, padronização e limpeza de texto.
Antes de nos aprofundarmos na vetorização, vamos recapitular o conceito de tokenização e como ela se diferencia da vetorização.
O que é Tokenização?
A tokenização é o processo de segmentar frases em componentes menores, conhecidos como tokens. Estes tokens facilitam a compreensão e manipulação de texto por parte dos computadores.
Exemplo: ‘Este artigo é ótimo’
Tokens: [‘Este’, ‘artigo’, ‘é’, ‘ótimo’]
O que é Vetorização?
Como sabemos, os modelos de aprendizado de máquina e algoritmos compreendem dados em formato numérico. A vetorização é o processo de converter dados textuais ou categóricos em vetores numéricos. Ao transformar dados em formato numérico, é possível treinar modelos com maior precisão.
Por que a Vetorização é Necessária?
✅ A tokenização e a vetorização desempenham papéis distintos no processamento de linguagem natural (PNL). A tokenização divide as frases em tokens menores, enquanto a vetorização converte esses tokens em um formato numérico que os modelos computacionais/ML podem entender.
✅ A vetorização não se limita apenas à conversão para formato numérico; ela também captura o significado semântico.
✅ A vetorização pode reduzir a dimensionalidade dos dados, tornando-os mais eficientes, o que é particularmente útil ao lidar com grandes conjuntos de dados.
✅ Muitos algoritmos de aprendizado de máquina, como redes neurais, exigem entradas numéricas, e a vetorização torna isso possível.
Existem diversas técnicas de vetorização, que serão detalhadas ao longo deste artigo.
Saco de Palavras
Se você tem um conjunto de documentos ou frases e deseja analisá-los, o Saco de Palavras (Bag of Words) simplifica esse processo, tratando cada documento como um “saco” contendo palavras.
Esta abordagem é útil em tarefas como classificação de texto, análise de sentimentos e recuperação de documentos.
Em um cenário de trabalho com grandes volumes de texto, um Saco de Palavras ajuda a representar os dados textuais através da criação de um vocabulário com palavras únicas encontradas. Após a criação do vocabulário, cada palavra é codificada em um vetor baseado na frequência com que ela aparece no texto.
Esses vetores consistem em números não negativos (0, 1, 2…) que indicam o número de ocorrências de cada palavra no documento.
O processo do Saco de Palavras envolve três etapas:
Etapa 1: Tokenização
Divide os documentos em tokens.
Exemplo: (Frase: “Adoro pizza e também adoro hambúrgueres”)
Etapa 2: Criação do vocabulário/separação de palavras únicas
Cria uma lista de todas as palavras únicas que aparecem nas frases.
[‘Eu’, ‘adoro’, ‘pizza’, ‘e’, ‘hambúrgueres’]
Etapa 3: Contagem de ocorrências/criação de vetores
Nesta etapa, contamos quantas vezes cada palavra do vocabulário é repetida e armazenamos essa informação em uma matriz esparsa. Em cada linha da matriz, temos um vetor de sentença cujo comprimento (as colunas da matriz) é igual ao tamanho do vocabulário.
Importar CountVectorizer
Vamos importar o CountVectorizer para treinar nosso modelo Bag of Words.
from sklearn.feature_extraction.text import CountVectorizer
Criar vetorizador
Nesta etapa, vamos criar nosso modelo usando o CountVectorizer e treiná-lo com um documento de texto de exemplo.
# Documentos de texto de exemplo
documents = [
"Este é o primeiro documento.",
"Este documento é o segundo documento.",
"E este é o terceiro.",
"Este é o primeiro documento?",
]
# Criar um CountVectorizer
cv = CountVectorizer()
# Ajustar e Transformar X = cv.fit_transform(documents)
Converter para um array denso
Nesta etapa, vamos converter nossas representações em um array denso e obter os nomes ou palavras dos recursos.
# Obter os nomes/palavras dos recursos feature_names = vectorizer.get_feature_names_out() # Converter para array denso X_dense = X.toarray()
Vamos imprimir a matriz de termos do documento e os nomes dos recursos.
# Imprimir a DTM e os nomes dos recursos
print("Matriz Documento-Termo (DTM):")
print(X_dense)
print("\nNomes dos recursos:")
print(feature_names)
Matriz Documento-Termo (DTM):

Nomes dos recursos:

Como podemos ver, os vetores são compostos por números não negativos (0, 1, 2…) que representam a frequência das palavras no documento.
Temos quatro documentos de texto como exemplos e identificamos nove palavras únicas neles. Essas palavras únicas são armazenadas no vocabulário, e a elas são atribuídos ‘Nomes de recursos’.
O modelo Bag of Words verifica se a primeira palavra única está presente no primeiro documento. Se presente, atribui o valor 1; caso contrário, atribui 0.
Se a palavra aparece várias vezes (por exemplo, 2 vezes), atribui o valor correspondente.
Por exemplo, no segundo documento, a palavra ‘documento’ se repete duas vezes, então seu valor na matriz será 2.
Se quisermos cada palavra como uma característica chave do vocabulário, teremos uma representação unigrama.
N-gramas = Unigramas, bigramas, etc.
Há muitas bibliotecas disponíveis, como scikit-learn, para implementar o Saco de Palavras, bem como Keras, Gensim e outras. Essa técnica é simples e pode ser útil em diversos casos.
O Saco de Palavras é mais rápido, mas tem algumas limitações:
- Atribui o mesmo peso a cada palavra, independentemente de sua importância. Em muitos casos, algumas palavras são mais significativas do que outras.
- O Saco de Palavras simplesmente conta a frequência com que uma palavra aparece em um documento. Isso pode levar a uma tendência em relação a palavras comuns, como “o”, “e”, “é”, que podem não ter grande significado.
- Documentos mais longos podem ter contagens de palavras mais altas, o que cria vetores maiores. Isso pode tornar a comparação um desafio e gerar uma matriz esparsa, que pode não ser ideal para tarefas complexas de PNL.
Para resolver este problema, podemos optar por abordagens mais avançadas, como o TF-IDF. Vamos detalhar.
TF-IDF
TF-IDF, ou Frequência do Termo – Frequência Inversa do Documento, é uma representação numérica que determina a importância das palavras em um documento.
Por que Precisamos do TF-IDF em Vez do Saco de Palavras?
O Saco de Palavras trata todas as palavras igualmente, considerando apenas a frequência de palavras únicas nas frases. O TF-IDF atribui importância às palavras em um documento, considerando tanto a frequência quanto a exclusividade.
Palavras que se repetem com muita frequência não se sobrepõem a palavras menos frequentes, mas mais importantes.
TF: A frequência do termo mede a importância de uma palavra em uma única frase.
IDF: A frequência inversa do documento mede a importância de uma palavra em toda a coleção de documentos.
TF = Frequência da palavra em um documento / Número total de palavras nesse documento
DF = Número de documentos que contêm a palavra / Número total de documentos
IDF = log (Número total de documentos / Número de documentos que contêm a palavra)
O IDF é o recíproco do DF. A lógica por trás disso é que quanto mais comum a palavra for em todos os documentos, menor será sua importância no documento atual.
Pontuação final do TF-IDF: TF-IDF = TF * IDF
É uma maneira de descobrir quais palavras são comuns em um documento específico e únicas em todos os documentos. Essas palavras podem ser úteis para encontrar o tema principal do documento.
Por exemplo:
Doc1 = “Eu adoro aprendizado de máquina”
Doc2 = “Eu adoro etechpt.com”
Precisamos encontrar a matriz TF-IDF para nossos documentos.
Primeiro, criaremos um vocabulário de palavras únicas.
Vocabulário = [“Eu”, “adoro”, “máquina”, “aprendizado”, “etechpt.com”]
Temos cinco palavras. Vamos encontrar o TF e o IDF para essas palavras.
TF = Frequência da palavra em um documento / Número total de palavras nesse documento
TF:
- Para “Eu” = TF para Doc1: 1/4 = 0,25 e para Doc2: 1/3 ≈ 0,33
- Para “adoro”: TF para Doc1: 1/4 = 0,25 e para Doc2: 1/3 ≈ 0,33
- Para “máquina”: TF para Doc1: 1/4 = 0,25 e para Doc2: 0/3 ≈ 0
- Para “aprendizado”: TF para Doc1: 1/4 = 0,25 e para Doc2: 0/3 ≈ 0
- Para “etechpt.com”: TF para Doc1: 0/4 = 0 e para Doc2: 1/3 ≈ 0,33
Agora, vamos calcular o IDF.
IDF = log (Número total de documentos / Número de documentos que contêm a palavra)
IDF:
- Para “Eu”: IDF é log(2/2) = 0
- Para “adoro”: IDF é log(2/2) = 0
- Para “máquina”: IDF é log(2/1) = log(2) ≈ 0,69
- Para “aprendizado”: IDF é log(2/1) = log(2) ≈ 0,69
- Para “etechpt.com”: IDF é log(2/1) = log(2) ≈ 0,69
Agora, vamos calcular a pontuação final do TF-IDF:
- Para “Eu”: TF-IDF para Doc1: 0,25 * 0 = 0 e TF-IDF para Doc2: 0,33 * 0 = 0
- Para “adoro”: TF-IDF para Doc1: 0,25 * 0 = 0 e TF-IDF para Doc2: 0,33 * 0 = 0
- Para “máquina”: TF-IDF para Doc1: 0,25 * 0,69 ≈ 0,17 e TF-IDF para Doc2: 0 * 0,69 = 0
- Para “aprendizado”: TF-IDF para Doc1: 0,25 * 0,69 ≈ 0,17 e TF-IDF para Doc2: 0 * 0,69 = 0
- Para “etechpt.com”: TF-IDF para Doc1: 0 * 0,69 = 0 e TF-IDF para Doc2: 0,33 * 0,69 ≈ 0,23
A matriz TF-IDF fica assim:
Eu adoro máquina aprendizado etechpt.com Doc1 0.0 0.0 0.17 0.17 0.0 Doc2 0.0 0.0 0.0 0.0 0.23
Os valores em uma matriz TF-IDF indicam a importância de cada termo em cada documento. Valores altos indicam que um termo é importante em um documento específico, enquanto valores baixos sugerem que o termo é menos importante ou comum nesse contexto.
O TF-IDF é utilizado principalmente em tarefas como classificação de texto, construção de sistemas de recuperação de informação para chatbots e resumo de texto.
Importar TfidfVectorizer
Vamos importar o TfidfVectorizer do scikit-learn.
from sklearn.feature_extraction.text import TfidfVectorizer
Criar vetorizador
Como você pode ver, vamos criar nosso modelo TF-IDF usando o TfidfVectorizer.
# Documentos de texto de exemplo
text = [
"Este é o primeiro documento.",
"Este documento é o segundo documento.",
"E este é o terceiro.",
"Este é o primeiro documento?",
]
# Criar um TfidfVectorizer
cv = TfidfVectorizer()
Criar Matriz TF-IDF
Vamos treinar nosso modelo usando texto. Em seguida, converteremos a matriz representativa em um array denso.
# Ajustar e transformar para criar a matriz TF-IDF X = cv.fit_transform(text)
# Obter os nomes/palavras dos recursos feature_names = vectorizer.get_feature_names_out() # Converter a matriz TF-IDF para um array denso para facilitar a manipulação (opcional) X_dense = X.toarray()
Imprimir a matriz TF-IDF e os nomes dos recursos
# Imprimir a matriz TF-IDF e os nomes dos recursos
print("Matriz TF-IDF:")
print(X_dense)
print("\nNomes dos recursos:")
print(feature_names)
Matriz TF-IDF:
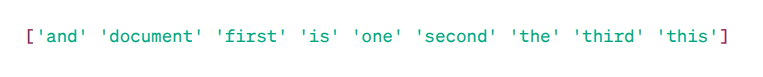
Nomes dos recursos:
Como podemos observar, esses números decimais indicam a importância das palavras em documentos específicos.
Além disso, você pode combinar palavras em grupos de 2, 3, 4, etc., usando n-gramas.
Existem outros parâmetros que podemos incluir: min_df, max_feature, sublinear_tf, etc.
Até agora, exploramos técnicas básicas baseadas em frequência.
No entanto, o TF-IDF não fornece significado semântico e compreensão contextual do texto.
Vamos entender técnicas mais avançadas que revolucionaram o campo de embeddings de palavras e que oferecem melhor significado semântico e compreensão contextual.
Word2Vec
Word2Vec é uma técnica popular de incorporação de palavras (um tipo de vetor de palavras útil para capturar semelhanças semânticas e sintáticas) em PNL. Foi desenvolvido por Tomas Mikolov e sua equipe no Google em 2013. O Word2vec representa palavras como vetores contínuos em um espaço multidimensional.
O Word2vec visa representar palavras de uma forma que capture seu significado semântico. Os vetores de palavras gerados pelo Word2vec são posicionados em um espaço vetorial contínuo.
Exemplo: Os vetores de ‘Gato’ e ‘Cachorro’ estariam mais próximos do que os vetores de ‘Gato’ e ‘Menina’.
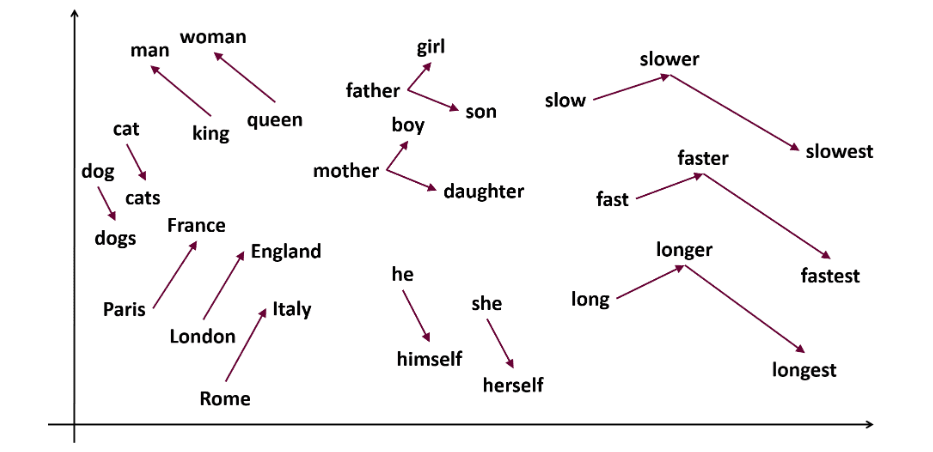 Fonte: usna.edu
Fonte: usna.edu
Duas arquiteturas de modelo podem ser utilizadas pelo Word2vec para criar incorporações de palavras.
CBOW: O Saco Contínuo de Palavras (CBOW) tenta prever uma palavra calculando a média do significado das palavras próximas. Ele pega um número fixo, ou janela, de palavras ao redor da palavra alvo, converte-as para a forma numérica (incorporação), calcula a média de tudo e usa essa média para prever a palavra alvo com a rede neural.
Exemplo: Alvo previsto: ‘Raposa’
Palavras da frase: ‘A’, ‘rápida’, ‘marrom’, ‘pula’, ‘sobre’, ‘o’
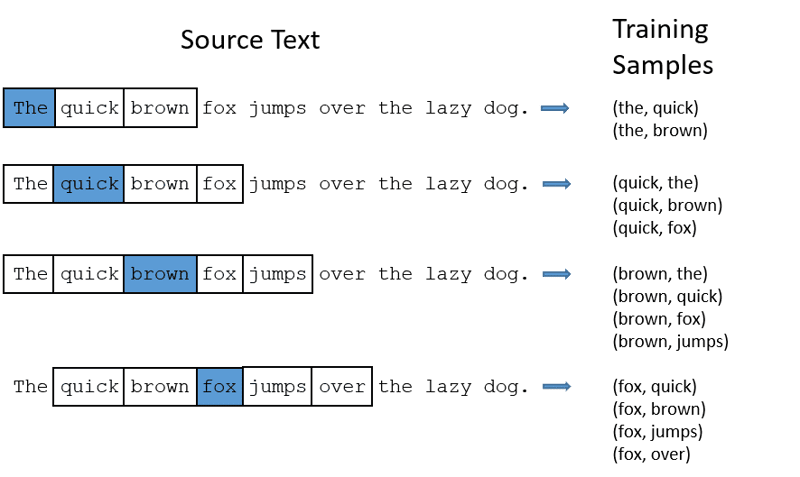 Word2Vec
Word2Vec
- O CBOW usa uma janela de tamanho fixo (número) de palavras, como 2 (2 à esquerda e 2 à direita).
- Converter para incorporação de palavras.
- O CBOW calcula a média da incorporação de palavras.
- O CBOW calcula a média da incorporação de palavras das palavras no contexto.
- O vetor médio tenta prever uma palavra alvo usando uma rede neural.
Agora, vamos entender como o skip-gram difere do CBOW.
Skip-gram: É um modelo de incorporação de palavras, mas funciona de forma diferente. Em vez de prever a palavra-alvo, o skip-gram prevê as palavras de contexto, dadas as palavras-alvo.
O skip-gram é melhor para capturar as relações semânticas entre as palavras.
Exemplo: ‘Rei – Homens + Mulheres = Rainha’
Se você quiser trabalhar com Word2Vec, tem duas opções: treinar seu próprio modelo ou usar um modelo pré-treinado. Vamos usar um modelo pré-treinado.
Importar Gensim
Você pode instalar o Gensim usando pip install:
pip install gensim
Tokenizar a frase usando word_tokenize:
Primeiro, converteremos as frases para letras minúsculas. Em seguida, vamos tokenizar as frases usando word_tokenize.
# Importar bibliotecas necessárias
from gensim.models import Word2Vec
from nltk.tokenize import word_tokenize
# Frases de exemplo
sentences = [
"Eu adoro o thor",
"Hulk é um membro importante dos Vingadores",
"Homem de Ferro ajuda o Homem-Aranha",
"Homem-Aranha é um dos membros populares dos Vingadores",
]
# Tokenizar as frases
tokenized_sentences = [word_tokenize(sentence.lower()) for sentence in sentences]
Vamos treinar nosso modelo:
Treinaremos nosso modelo fornecendo frases tokenizadas. Estamos usando uma janela de 5 para este modelo, mas você pode adaptá-la conforme sua necessidade.
# Treinar um modelo Word2Vec
model = Word2Vec(sentences=tokenized_sentences, vector_size=100, window=5, min_count=1, sg=0)
# Encontrar palavras semelhantes
similar_words = model.wv.most_similar("vingadores")
# Imprimir palavras semelhantes
print("Palavras semelhantes a 'vingadores':")
for word, score in similar_words:
print(f"{word}: {score}")
Palavras semelhantes a ‘vingadores’:
 Similaridade Word2Vec
Similaridade Word2Vec
Estas são algumas das palavras semelhantes a “vingadores”, baseadas no modelo Word2Vec, juntamente com suas pontuações de similaridade.
O modelo calcula uma pontuação de similaridade (principalmente similaridade de cosseno) entre os vetores de palavras de “vingadores” e outras palavras no vocabulário. A pontuação de similaridade indica o quão relacionadas as duas palavras estão no espaço vetorial.
Exemplo:
Aqui, a palavra ‘ajuda’ tem uma similaridade de cosseno de -0,005911458611011982 com a palavra ‘vingadores’. O valor negativo sugere que elas podem ser diferentes entre si.
Os valores de similaridade de cosseno variam de -1 a 1, onde:
- 1 indica que os dois vetores são idênticos e possuem similaridade positiva.
- Valores próximos de 1 indicam alta similaridade positiva.
- Valores próximos de 0 indicam que os vetores não estão fortemente relacionados.
- Valores próximos de -1 indicam alta dissimilaridade.
- -1 indica que os dois vetores são totalmente opostos e possuem uma similaridade negativa perfeita.
Visite este link se quiser uma melhor compreensão dos modelos Word2vec e uma representação visual de como funcionam. É uma ferramenta muito útil para ver o CBOW e o skip-gram em ação.
Assim como o Word2Vec, temos o GloVe. O GloVe pode produzir embeddings que exigem menos memória em comparação com o Word2Vec. Vamos detalhar o GloVe.
GloVe
Vetor Global para Representação de Palavras (GloVe) é uma técnica similar ao Word2vec. É usado para representar palavras como vetores em um espaço contínuo. O conceito por trás do GloVe é o mesmo do Word2Vec: produzir embeddings contextuais de palavras, levando em consideração o desempenho superior do Word2Vec.
Por que Precisamos do GloVe?
O Word2vec é um método baseado em janelas e utiliza palavras próximas para entendê-las. Isso significa que o significado semântico da palavra alvo é afetado apenas pelas palavras que a cercam nas frases, o que é um uso ineficiente das estatísticas.
Enquanto o GloVe captura estatísticas globais e locais para incluir na incorporação de palavras.
Quando Usar GloVe?
Use o GloVe quando desejar a incorporação de palavras que capture relações semânticas mais amplas e associações globais de palavras.
O GloVe é melhor do que outros modelos em tarefas de reconhecimento de entidades nomeadas, analogia de palavras e similaridade de palavras.
Primeiro, precisamos instalar o Gensim:
pip install gensim
Etapa 1: instalar bibliotecas essenciais
# Importar as bibliotecas necessárias import numpy as np import matplotlib.pyplot as plt from sklearn.manifold import TSNE import gensim.downloader as api
Etapa 2: importar o modelo GloVe
import gensim.downloader as api
glove_model = api.load('glove-wiki-gigaword-300')
Etapa 3: obter a representação vetorial da palavra ‘fofo’
glove_model["fofo"]
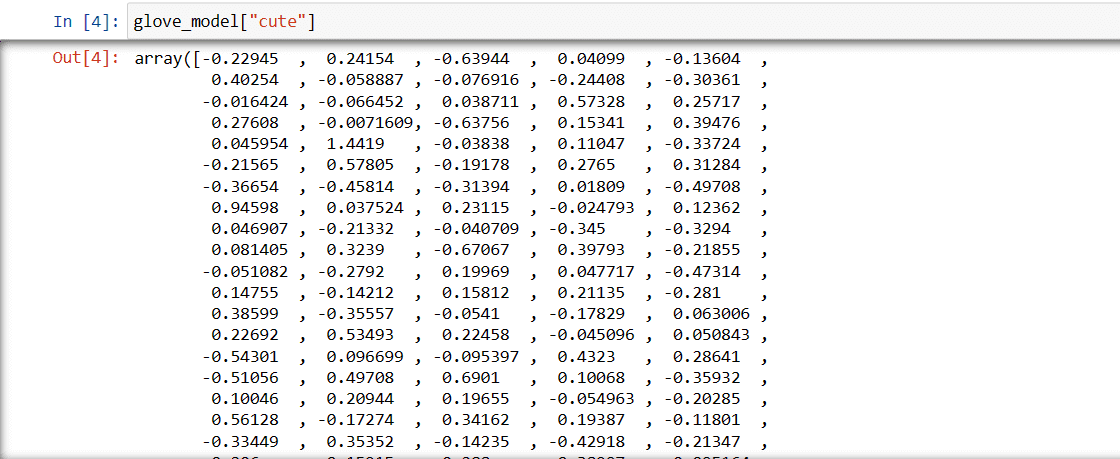 Vetor para a palavra ‘fofo’
Vetor para a palavra ‘fofo’
Esses valores capturam o significado da palavra e suas relações com outras palavras. Valores positivos indicam associações positivas com certos conceitos, enquanto valores negativos indicam associações negativas com outros conceitos.
Em um modelo GloVe, cada dimensão do vetor de palavras representa um certo aspecto do significado ou contexto da palavra.
Os valores negativos e positivos nessas dimensões contribuem para o quão ‘fofo’ está semanticamente relacionado a outras palavras no vocabulário do modelo.
Os valores podem variar para modelos diferentes. Vamos encontrar algumas palavras semelhantes à palavra ‘menino’.
As 10 palavras mais semelhantes que o modelo considera mais parecidas com a palavra ‘menino’.
# encontrar palavras semelhantes
glove_model.most_similar("menino")
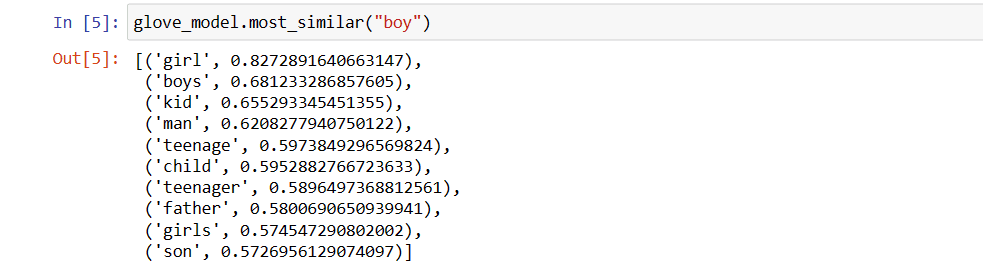 As 10 principais palavras semelhantes a ‘menino’
As 10 principais palavras semelhantes a ‘menino’
Como podemos ver, a palavra mais semelhante a ‘menino’ é ‘menina’.
Agora, vamos tentar descobrir com que precisão o modelo obterá o significado semântico das palavras fornecidas.
glove_model.most_similar(positive=['menino', 'rainha'], negative=['menina'], topn=1)
 A palavra mais relevante para ‘rainha’
A palavra mais relevante para ‘rainha’
Nosso modelo é capaz de encontrar relações perfeitas entre as palavras.
Definir lista de vocabulário:
Agora, vamos tentar entender o significado semântico ou a relação entre as palavras usando um gráfico. Defina a lista de palavras que deseja visualizar.
# Define a lista de palavras que você deseja visualizar vocab = ["menino", "menina", "homem", "mulher", "rei", "rainha", "banana", "maçã", "manga", "vaca", "coco", "laranja", "gato", "cachorro"]
Criar uma matriz de incorporação:
Vamos escrever o código para criar a matriz de incorporação.
# Seu código para criar a matriz de incorporação
EMBEDDING_DIM = glove_model.vectors.shape[1]
word_index = {word: index for index, word in enumerate(vocab)}
num_words = len(vocab)
embedding_matrix = np.zeros((num_words, EMBEDDING_DIM))
for word, i in word_index.items():
embedding_vector = glove_model[word]
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector
Definir uma função para visualização t-SNE:
Com este código, definiremos a função para nosso gráfico de visualização.
def tsne_plot(embedding_matrix, words):
tsne_model = TSNE(perplexity=3, n_components=2, init="pca", random_state=42)
coordinates = tsne_model.fit_transform(embedding_matrix)
x, y = coordinates[:, 0], coordinates[:, 1]
plt.figure(figsize=(14, 8))
for i, word in enumerate(words):
plt.scatter(x[i], y[i])
plt.annotate(word,
xy=(x[i], y[i]),
xytext=(2, 2),
textcoords="offset points",
ha="right",
va="bottom")
plt.show()
Vamos ver como fica nosso gráfico:
# Chame a função tsne_plot com sua matriz de incorporação e lista de palavras tsne_plot(embedding_matrix, vocab)
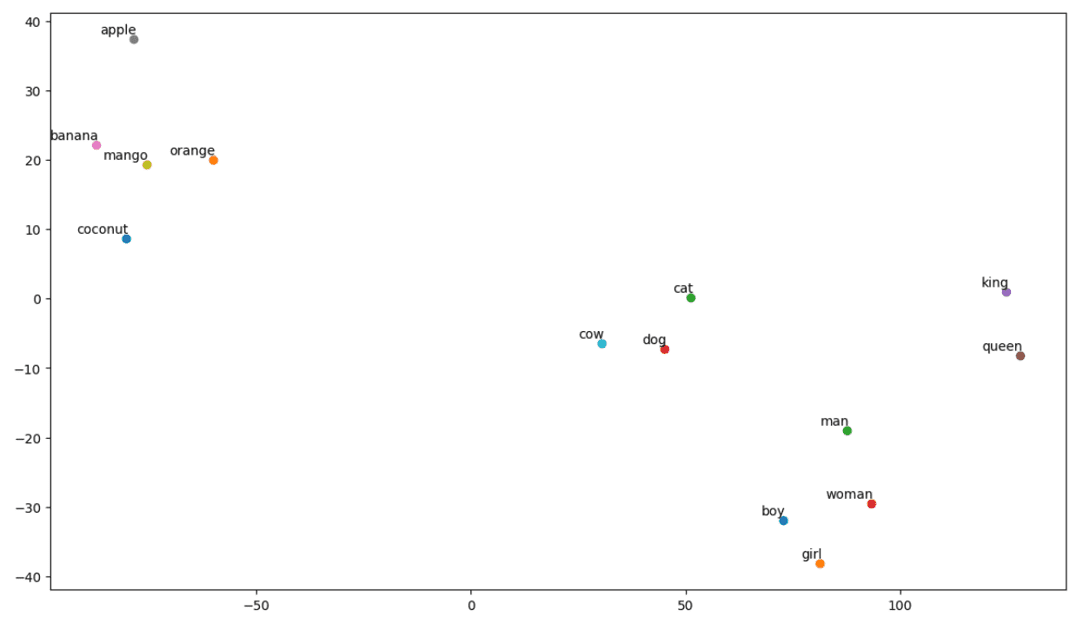 Gráfico t-SNE
Gráfico t-SNE
Como podemos ver, há palavras como ‘banana’, ‘manga’, ‘laranja’, ‘coco’ e ‘maçã’ do lado esquerdo do nosso gráfico. Enquanto ‘vaca’, ‘cachorro’ e ‘gato’ são semelhantes entre si, por serem animais.
Portanto, nosso modelo também pode encontrar significado semântico e relações entre as palavras!
Apenas alterando o vocabulário ou criando seu modelo do zero, você pode experimentar palavras diferentes.
Você pode usar esta matriz de incorporação como quiser. Ela pode ser aplicada apenas a tarefas de similaridade de palavras ou inserida na camada de incorporação de uma rede neural.
O GloVe treina em uma matriz de coocorrência para derivar o significado semântico. Ele se baseia na ideia de que as coocorrências palavra-palavra são uma peça essencial de conhecimento e que seu uso é uma maneira eficaz de utilizar estatísticas para produzir incorporações de palavras. É assim que o GloVe consegue adicionar “estatísticas globais” ao produto final.
E isso é GloVe; outro método popular de vetorização é o FastText. Vamos detalhá-lo.
FastText
FastText é uma biblioteca de código aberto introduzida pela equipe de pesquisa de IA do Facebook para classificação de texto e análise de sentimentos. O FastText fornece ferramentas para treinar a incorporação de palavras, que são palavras densas representadas por vetores. Isso é útil para capturar o significado semântico do documento. O FastText suporta classificação de vários rótulos e multiclasse.
Por que FastText?
O FastText é melhor do que outros modelos devido à sua capacidade de generalizar para palavras desconhecidas, o que era uma limitação em outros métodos. O FastText fornece vetores de palavras pré-treinados para diferentes idiomas, o que pode ser útil em diversas tarefas que exigem conhecimento prévio sobre as palavras e seus significados.
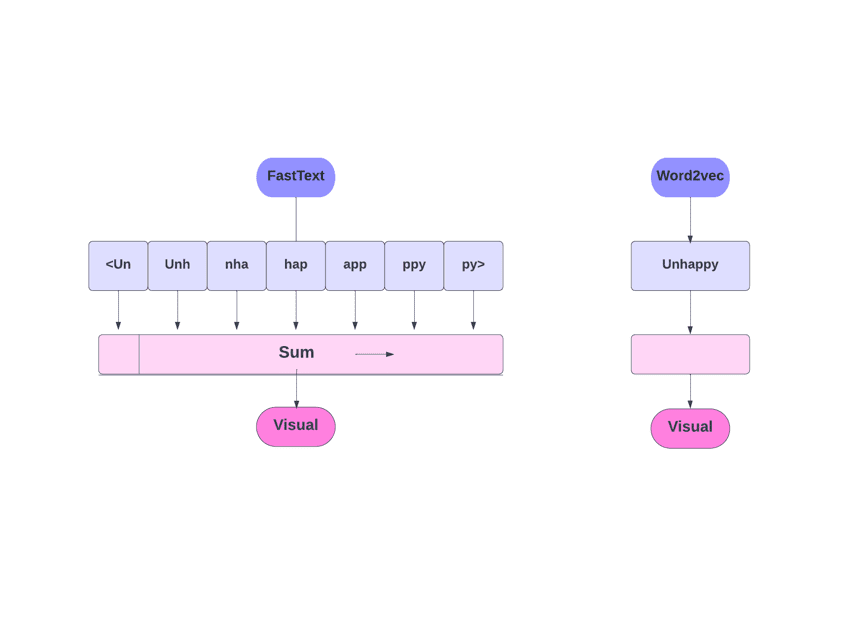 FastText versus Word2Vec
FastText versus Word2Vec
Como Funciona?
Como vimos, outros modelos como Word2Vec e GloVe utilizam palavras para a incorporação de palavras. No entanto, o FastText se baseia em letras em vez de palavras, ou seja, usa letras para a incorpor