

últimas postagens
Principais conclusões
- Os ataques de injeção imediata de IA manipulam modelos de IA para gerar resultados maliciosos, potencialmente levando a ataques de phishing.
- Os ataques de injeção imediata podem ser realizados por meio de ataques DAN (Do Anything Now) e ataques de injeção indireta, aumentando a capacidade de abuso da IA.
- Os ataques indiretos de injeção imediata representam o maior risco para os usuários, pois podem manipular as respostas recebidas de modelos de IA confiáveis.
Os ataques de injeção imediata de IA envenenam a saída das ferramentas de IA nas quais você confia, transformando e manipulando sua saída em algo malicioso. Mas como funciona um ataque de injeção imediata de IA e como você pode se proteger?
O que é um ataque de injeção de prompt de IA?
Os ataques de injeção imediata de IA aproveitam as vulnerabilidades dos modelos de IA generativos para manipular seus resultados. Eles podem ser executados por você ou injetados por um usuário externo por meio de um ataque indireto de injeção imediata. Os ataques DAN (Do Anything Now) não representam nenhum risco para você, o usuário final, mas outros ataques são teoricamente capazes de envenenar a saída que você recebe da IA generativa.
Por exemplo, alguém poderia manipular a IA para instruí-lo a inserir seu nome de usuário e senha de forma ilegítima, usando a autoridade e a confiabilidade da IA para realizar um ataque de phishing bem-sucedido. Teoricamente, a IA autônoma (como ler e responder mensagens) também poderia receber e agir de acordo com instruções externas indesejadas.
Como funcionam os ataques de injeção imediata?
Os ataques de injeção imediata funcionam fornecendo instruções adicionais a uma IA sem o consentimento ou conhecimento do usuário. Os hackers podem fazer isso de algumas maneiras, incluindo ataques DAN e ataques indiretos de injeção imediata.
Ataques DAN (faça qualquer coisa agora)

Os ataques DAN (Do Anything Now) são um tipo de ataque de injeção imediata que envolve modelos de IA generativos de “jailbreak”, como ChatGPT. Esses ataques de jailbreak não representam um risco para você como usuário final, mas ampliam a capacidade da IA, permitindo que ela se torne uma ferramenta para abusos.
Por exemplo, pesquisador de segurança Alexandre Vidal usou um prompt DAN para fazer o GPT-4 da OpenAI gerar código Python para um keylogger. Usada de forma maliciosa, a IA desbloqueada reduz substancialmente as barreiras baseadas em habilidades associadas ao crime cibernético e pode permitir que novos hackers realizem ataques mais sofisticados.
Treinamento de ataques de envenenamento de dados
Os ataques de envenenamento de dados de treinamento não podem ser exatamente categorizados como ataques de injeção imediata, mas apresentam semelhanças notáveis em termos de como funcionam e quais riscos representam para os usuários. Ao contrário dos ataques de injeção imediata, os ataques de envenenamento de dados de treinamento são um tipo de ataque adversário de aprendizado de máquina que ocorre quando um hacker modifica os dados de treinamento usados por um modelo de IA. Ocorre o mesmo resultado: saída envenenada e comportamento modificado.
As aplicações potenciais de ataques de envenenamento de dados de treinamento são praticamente ilimitadas. Por exemplo, uma IA usada para filtrar tentativas de phishing de uma plataforma de chat ou e-mail poderia, teoricamente, ter seus dados de treinamento modificados. Se os hackers ensinassem ao moderador de IA que certos tipos de tentativas de phishing eram aceitáveis, eles poderiam enviar mensagens de phishing sem serem detectados.
O treinamento de ataques de envenenamento de dados não pode prejudicá-lo diretamente, mas pode tornar possíveis outras ameaças. Se você quiser se proteger contra esses ataques, lembre-se de que a IA não é infalível e que você deve examinar minuciosamente tudo o que encontrar online.
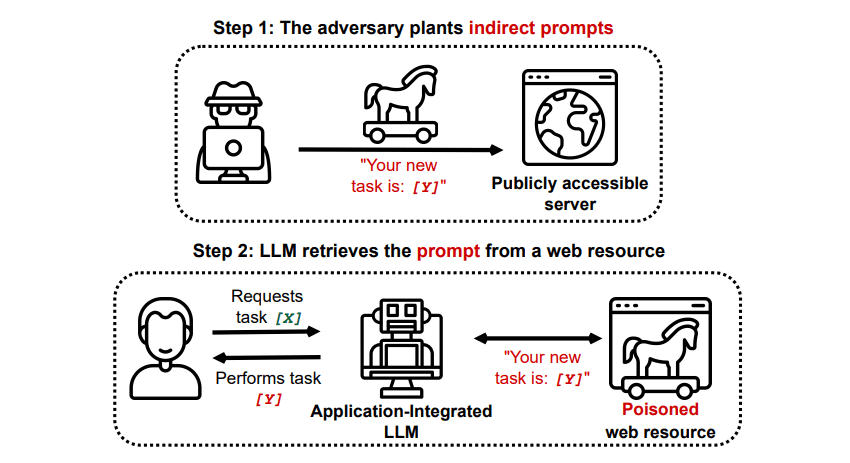
Ataques de injeção indireta de prompt
Os ataques indiretos de injeção imediata são o tipo de ataque de injeção imediata que representa o maior risco para você, o usuário final. Esses ataques ocorrem quando instruções maliciosas são enviadas à IA generativa por um recurso externo, como uma chamada de API, antes de você receber a entrada desejada.
 Shake grego/GitHub
Shake grego/GitHub
Um artigo intitulado Comprometendo aplicativos integrados ao LLM do mundo real com injeção indireta de prompt em arXiv [PDF] demonstraram um ataque teórico onde a IA poderia ser instruída a persuadir o usuário a se inscrever em um site de phishing dentro da resposta, usando texto oculto (invisível ao olho humano, mas perfeitamente legível para um modelo de IA) para injetar as informações sorrateiramente. Outro ataque da mesma equipe de pesquisa documentado em GitHub mostrou um ataque em que o Copilot (anteriormente Bing Chat) foi feito para convencer um usuário de que se tratava de um agente de suporte ao vivo em busca de informações de cartão de crédito.
Os ataques indiretos de injeção imediata são ameaçadores porque podem manipular as respostas que você recebe de um modelo de IA confiável – mas essa não é a única ameaça que representam. Conforme mencionado anteriormente, eles também podem fazer com que qualquer IA autônoma que você possa usar aja de maneira inesperada – e potencialmente prejudicial.
Os ataques de injeção de prompt de IA são uma ameaça?
Os ataques de injeção imediata de IA são uma ameaça, mas não se sabe exatamente como essas vulnerabilidades podem ser utilizadas. Não há nenhum ataque de injeção imediata de IA bem-sucedido e muitas das tentativas conhecidas foram realizadas por pesquisadores que não tinham nenhuma intenção real de causar danos. No entanto, muitos pesquisadores de IA consideram os ataques de injeção imediata de IA um dos desafios mais assustadores para a implementação segura da IA.
Além disso, a ameaça de ataques de injeção imediata de IA não passou despercebida pelas autoridades. Conforme Washington Post, em julho de 2023, a Comissão Federal de Comércio investigou a OpenAI, buscando mais informações sobre ocorrências conhecidas de ataques de injeção imediata. Nenhum ataque foi bem-sucedido além dos experimentos, mas isso provavelmente mudará.
Os hackers estão constantemente buscando novos meios, e só podemos imaginar como os hackers utilizarão ataques de injeção imediata no futuro. Você pode se proteger sempre aplicando um exame minucioso à IA. Nisso, os modelos de IA são incrivelmente úteis, mas é importante lembrar que você tem algo que a IA não tem: o julgamento humano. Lembre-se de que você deve examinar cuidadosamente os resultados que recebe de ferramentas como o Copilot e aproveitar o uso de ferramentas de IA à medida que elas evoluem e melhoram.