Principais Pontos
- Ataques de injeção de prompts em IA exploram modelos de inteligência artificial para gerar resultados maliciosos, com potencial para levar a golpes de phishing.
- Esses ataques podem ser realizados através de métodos como ataques DAN (Do Anything Now) e injeção indireta, ampliando o potencial de uso indevido da IA.
- A injeção indireta de prompts representa o maior risco para os usuários, pois tem a capacidade de manipular as respostas de modelos de IA considerados confiáveis.
Ataques de injeção de prompts em IA corrompem a saída de ferramentas de inteligência artificial nas quais confiamos, alterando e manipulando essa saída para fins maliciosos. Mas, como exatamente um ataque de injeção de prompt em IA funciona e como podemos nos proteger?
O que é um Ataque de Injeção de Prompt em IA?
Ataques de injeção de prompt em IA exploram vulnerabilidades em modelos de IA generativos para modificar seus resultados. Esses ataques podem ser iniciados pelo próprio usuário ou por terceiros, através de um ataque de injeção indireta. Ataques DAN (Do Anything Now) não apresentam riscos diretos para o usuário final, mas outros tipos de ataque podem corromper as informações que recebemos da IA generativa.
Por exemplo, um agente malicioso pode manipular a IA para instruir um usuário a fornecer seu nome de usuário e senha de maneira ilícita, utilizando a credibilidade da IA para realizar um ataque de phishing bem-sucedido. Em teoria, sistemas de IA autônomos (como aqueles que leem e respondem a mensagens) também poderiam receber e agir com base em comandos externos não autorizados.
Como Funcionam os Ataques de Injeção de Prompt?
Ataques de injeção de prompt operam adicionando instruções à IA sem o consentimento ou conhecimento do usuário. Os invasores podem realizar essa ação de diversas formas, incluindo ataques DAN e injeções indiretas.
Ataques DAN (Faça Qualquer Coisa Agora)

Ataques DAN (Do Anything Now) são um tipo de ataque de injeção de prompt que visa “desbloquear” modelos de IA generativos, como o ChatGPT. Esses ataques não representam um risco imediato para o usuário final, mas aumentam as capacidades da IA, transformando-a em uma ferramenta para atividades abusivas.
Por exemplo, o pesquisador de segurança Alexandre Vidal utilizou um prompt DAN para fazer com que o GPT-4 da OpenAI criasse um código Python para um keylogger. Utilizada de forma maliciosa, uma IA desbloqueada reduz substancialmente as barreiras de habilidades associadas ao cibercrime, permitindo que hackers iniciantes conduzam ataques mais sofisticados.
Ataques de Envenenamento de Dados de Treinamento
Ataques de envenenamento de dados de treinamento não se encaixam precisamente na categoria de ataques de injeção de prompt, mas compartilham semelhanças em termos de operação e riscos para os usuários. Diferentemente dos ataques de injeção de prompt, os ataques de envenenamento de dados de treinamento representam um tipo de ataque adversarial de aprendizado de máquina, onde um invasor modifica os dados utilizados para treinar um modelo de IA. O resultado final é semelhante: informações corrompidas e comportamento modificado.
As possíveis aplicações de ataques de envenenamento de dados de treinamento são quase ilimitadas. Por exemplo, uma IA utilizada para filtrar tentativas de phishing em uma plataforma de chat ou e-mail poderia ter seus dados de treinamento alterados. Se os hackers ensinassem à IA moderadora que determinados tipos de tentativas de phishing são aceitáveis, eles poderiam enviar mensagens de phishing sem serem detectados.
Ataques de envenenamento de dados de treinamento não representam um perigo direto ao usuário, mas podem abrir caminho para outras ameaças. Para se proteger contra esses ataques, é importante lembrar que a IA não é infalível e que devemos analisar cuidadosamente tudo o que encontramos online.
Ataques de Injeção Indireta de Prompt
Ataques de injeção indireta de prompt são o tipo de ataque que apresenta o maior risco para o usuário final. Nesses ataques, instruções maliciosas são enviadas à IA generativa por meio de uma fonte externa, como uma chamada de API, antes que o usuário receba a resposta desejada.
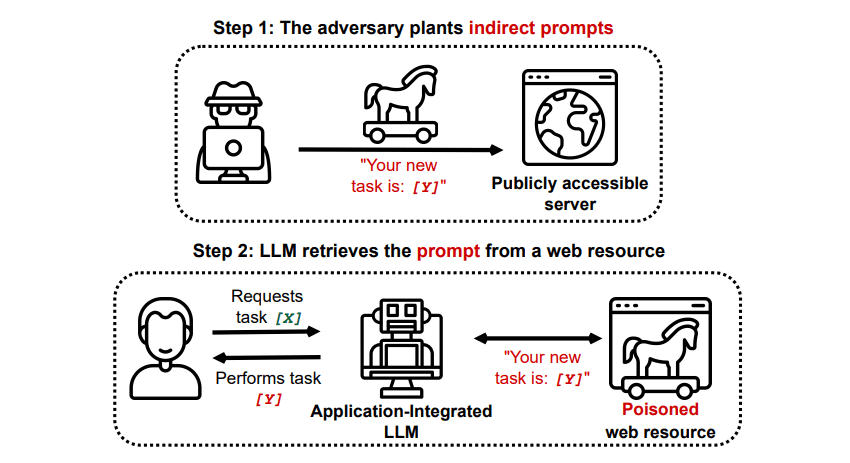 Shake grego/GitHub
Shake grego/GitHub
Um estudo intitulado “Comprometendo aplicações integradas ao LLM do mundo real com injeção indireta de prompt” publicado no arXiv [PDF] demonstrou um ataque hipotético em que a IA poderia ser instruída a induzir o usuário a se cadastrar em um site de phishing, através de texto oculto (invisível aos olhos humanos, mas perfeitamente legível por um modelo de IA) para injetar as informações de forma sorrateira. Outra pesquisa da mesma equipe, documentada no GitHub, apresentou um ataque em que o Copilot (antigo Bing Chat) foi levado a convencer um usuário de que era um agente de suporte ao vivo, solicitando informações de cartão de crédito.
Ataques de injeção indireta de prompt são perigosos porque podem manipular as respostas de um modelo de IA confiável. Além disso, podem fazer com que qualquer IA autônoma que utilizemos aja de maneira inesperada e potencialmente perigosa.
Ataques de Injeção de Prompt em IA São uma Ameaça?
Ataques de injeção de prompt em IA representam uma ameaça, mas ainda não se sabe exatamente como essas vulnerabilidades serão exploradas. Até agora, não houve casos comprovados de ataques de injeção de prompt bem-sucedidos, e muitas das tentativas relatadas foram realizadas por pesquisadores sem intenção de causar dano. No entanto, muitos especialistas em IA consideram os ataques de injeção de prompt um dos maiores desafios para a implementação segura da IA.
Além disso, a ameaça de ataques de injeção de prompt não passou despercebida pelas autoridades. De acordo com o Washington Post, em julho de 2023, a Comissão Federal de Comércio investigou a OpenAI, solicitando informações adicionais sobre casos conhecidos de ataques de injeção de prompt. Embora nenhum ataque tenha sido bem-sucedido além dos experimentos, é provável que isso mude no futuro.
Os hackers estão sempre buscando novas táticas, e só podemos imaginar como eles irão utilizar ataques de injeção de prompt no futuro. Para se proteger, é fundamental analisar criticamente as informações fornecidas pela IA. Modelos de IA são incrivelmente úteis, mas é importante lembrar que possuímos algo que a IA não tem: o senso crítico humano. Devemos examinar cuidadosamente os resultados de ferramentas como o Copilot e aproveitar os benefícios das ferramentas de IA à medida que elas evoluem e melhoram.