O Google JAX, cujo nome completo é Just After Execution, é uma estrutura desenvolvida pelo Google com o objetivo de otimizar e acelerar as tarefas de aprendizado de máquina.
Pode-se considerá-lo uma biblioteca para a linguagem Python, projetada para agilizar a execução de tarefas, computação científica, transformações de funções, aprendizado profundo, redes neurais e uma ampla gama de outras aplicações.
Entendendo o Google JAX
O pacote computacional mais fundamental em Python é o NumPy, que oferece diversas funcionalidades, tais como agregações, operações vetoriais, álgebra linear, manipulações de matrizes e arrays multidimensionais, entre outras.
Mas, e se fosse possível acelerar ainda mais os cálculos realizados com o NumPy, especialmente para grandes volumes de dados?
E se houvesse uma ferramenta que funcionasse igualmente bem em diferentes processadores, como GPUs ou TPUs, sem a necessidade de alterações no código?
Imagine um sistema capaz de realizar transformações de funções complexas de forma automática e eficiente.
O Google JAX é uma biblioteca (ou framework) que realiza essas tarefas e muito mais. Seu desenvolvimento teve como foco a otimização do desempenho e a execução eficiente de tarefas de aprendizado de máquina (ML) e aprendizado profundo. O Google JAX oferece recursos de transformação que o diferenciam de outras bibliotecas de ML, auxiliando na computação científica avançada para aprendizado profundo e redes neurais:
- Diferenciação automática
- Vetorização automática
- Paralelização automática
- Compilação just-in-time (JIT)
Atributos únicos do Google JAX
Todas as transformações utilizam XLA (Álgebra Linear Acelerada) para otimizar o desempenho e o uso de memória. XLA é um motor de compilação específico que acelera os modelos TensorFlow, executando álgebra linear. A utilização do XLA em seu código Python não requer alterações significativas no código!
Vamos agora explorar detalhadamente cada um desses recursos.
Funcionalidades do Google JAX
O Google JAX oferece funções de transformação que podem ser combinadas para melhorar o desempenho e executar tarefas de aprendizado profundo de forma mais eficiente. Por exemplo, a diferenciação automática permite obter o gradiente de uma função e encontrar derivadas de qualquer ordem. Da mesma forma, a paralelização automática e o JIT permitem executar várias tarefas simultaneamente. Essas transformações são cruciais para aplicações em robótica, jogos e pesquisa.
Uma função de transformação combinável é uma função pura que transforma um conjunto de dados em outra forma. Elas são chamadas de combináveis por serem autocontidas e não possuírem estado (a mesma entrada sempre gera a mesma saída).
Y(x) = T: (f(x))
Na equação acima, f(x) representa a função original onde a transformação é aplicada. Y(x) é a função resultante após a aplicação da transformação.
Por exemplo, se você tiver uma função chamada ‘valor_total_da_conta’ e desejar obter o resultado como uma transformação de função, basta usar a transformação desejada, como gradiente (grad):
grad_total_da_conta = grad(valor_total_da_conta)
Ao transformar funções numéricas usando funções como grad(), podemos obter suas derivadas de ordem superior, que são utilizadas em algoritmos de otimização de aprendizado profundo, como o gradiente descendente, tornando os algoritmos mais rápidos e eficientes. Da mesma forma, usando jit(), podemos compilar programas Python just-in-time (de forma preguiçosa).
#1. Diferenciação Automática
Python usa a função autograd para diferenciar automaticamente o código NumPy e Python nativo. JAX utiliza uma versão modificada de autograd (ou seja, grad) e a combina com XLA (Accelerated Linear Algebra) para realizar diferenciação automática e encontrar derivadas de qualquer ordem para GPUs (Unidades de Processamento Gráfico) e TPUs (Unidades de Processamento Tensorial).
Nota sobre TPUs, GPUs e CPUs: A CPU, ou Unidade Central de Processamento, gerencia todas as operações do computador. A GPU é um processador adicional que aumenta o poder de computação e executa operações avançadas. Já a TPU é uma unidade poderosa, desenvolvida especificamente para cargas de trabalho complexas e pesadas, como IA e algoritmos de aprendizado profundo.
De forma semelhante à função autograd, que é capaz de diferenciar por meio de loops, recursões e ramificações, o JAX utiliza a função grad() para obter gradientes no modo reverso (backpropagation). Além disso, é possível diferenciar uma função de qualquer ordem usando grad:
grad(grad(grad(sen θ)))) (1.0)
Diferenciação automática de ordem superior
Como mencionado, o grad é útil para encontrar as derivadas parciais de uma função. Uma derivada parcial pode ser utilizada para calcular o gradiente descendente de uma função de custo em relação aos parâmetros da rede neural no aprendizado profundo, visando minimizar as perdas.
Calculando a derivada parcial
Imagine uma função com múltiplas variáveis, como x, y e z. Encontrar a derivada de uma variável, mantendo as outras constantes, é chamado de derivada parcial. Considere a seguinte função:
f(x,y,z) = x + 2y + z2
Exemplo de derivada parcial
A derivada parcial de x será ∂f/∂x, que informa como a função se modifica em relação a uma variável, mantendo as outras constantes. Se realizássemos esse cálculo manualmente, seria necessário escrever um programa para diferenciar, aplicá-lo para cada variável e, então, calcular o gradiente descendente. Isso se tornaria uma tarefa complexa e demorada para múltiplas variáveis.
A diferenciação automática decompõe a função em um conjunto de operações elementares, como +, -, *, / ou sin, cos, tan, exp, etc., e aplica a regra da cadeia para calcular a derivada. Isso pode ser feito nos modos direto e reverso.
E não para por aí! Todos esses cálculos ocorrem de forma extremamente rápida. XLA garante velocidade e desempenho.
#2. Álgebra Linear Acelerada
Vamos analisar a equação anterior. Sem o XLA, a computação demandaria três ou mais kernels, com cada um executando uma tarefa menor. Por exemplo:
Kernel k1 -> x * 2y (multiplicação)
k2 -> x * 2y + z (adição)
k3 -> Redução
Se a mesma tarefa for executada pelo XLA, um único kernel cuida de todas as operações intermediárias, unindo-as. Os resultados intermediários das operações elementares são transmitidos em vez de serem armazenados na memória, economizando memória e aumentando a velocidade.
#3. Compilação Just-in-Time
O JAX utiliza internamente o compilador XLA para aumentar a velocidade de execução, tanto na CPU, quanto na GPU e TPU. Isso é possível graças à execução de código JIT. Para usar o JIT, podemos importar a função jit:
from jax import jit def minha_funcao(x): …………linhas de código minha_funcao_jit = jit(minha_funcao)
Outra forma é utilizar o decorador jit na definição da função:
@jit def minha_funcao(x): …………linhas de código
Esse código é muito mais rápido, pois a transformação retornará a versão compilada do código para o chamador, em vez de utilizar o interpretador Python. Isso é particularmente útil para entradas vetoriais, como arrays e matrizes.
O mesmo vale para todas as funções Python existentes. Por exemplo, funções do pacote NumPy. Nesse caso, devemos importar jax.numpy como jnp, em vez de NumPy:
import jax import jax.numpy as jnp x = jnp.array([[1,2,3,4], [5,6,7,8]])
Após essa importação, o objeto principal de matriz JAX, denominado DeviceArray, substitui a matriz NumPy padrão. DeviceArray é preguiçoso – os valores são mantidos no acelerador até serem necessários. Isso significa também que o programa JAX não espera que os resultados retornem ao programa de chamada (Python), seguindo um despacho assíncrono.
#4. Vetorização Automática (vmap)
Em cenários típicos de aprendizado de máquina, trabalhamos com conjuntos de dados que podem conter milhões ou mais pontos de dados. Geralmente, precisamos realizar cálculos ou manipulações em cada um ou na maioria desses pontos – o que pode ser uma tarefa demorada e que consome muita memória! Por exemplo, se você deseja obter o quadrado de cada ponto em um conjunto de dados, a primeira ideia é criar um loop e calcular o quadrado um por um. Que frustração!
Se criarmos esses pontos como vetores, poderíamos calcular todos os quadrados de uma vez, realizando manipulações de vetores ou matrizes com o NumPy. E se o seu programa pudesse fazer isso automaticamente? Isso é exatamente o que o JAX faz! Ele pode vetorizar automaticamente todos os pontos de dados para que você possa executar facilmente qualquer operação neles, tornando seus algoritmos mais rápidos e eficientes.
O JAX utiliza a função vmap para vetorização automática. Considere a seguinte matriz:
x = jnp.array([1,2,3,4,5,6,7,8,9,10]) y = jnp.square(x)
Ao fazer apenas o código acima, o método square será executado para cada ponto da matriz. Mas, se você fizer o seguinte:
vmap(jnp.square(x))
O método square será executado apenas uma vez, porque os pontos de dados são automaticamente vetorizados com o método vmap antes da execução da função, e o loop é levado para o nível elementar da operação, resultando em uma multiplicação de matriz em vez de uma multiplicação escalar, melhorando o desempenho.
#5. Programação SPMD (pmap)
A programação SPMD, ou Programa Único de Dados Múltiplos, é crucial em contextos de aprendizado profundo. Frequentemente, aplicamos as mesmas funções em diferentes conjuntos de dados que residem em várias GPUs ou TPUs. O JAX possui uma função chamada pmap, que permite a programação paralela em várias GPUs ou em qualquer acelerador. Assim como o JIT, programas que utilizam pmap serão compilados pelo XLA e executados simultaneamente nos sistemas. Essa paralelização automática funciona tanto para cálculos diretos quanto reversos.
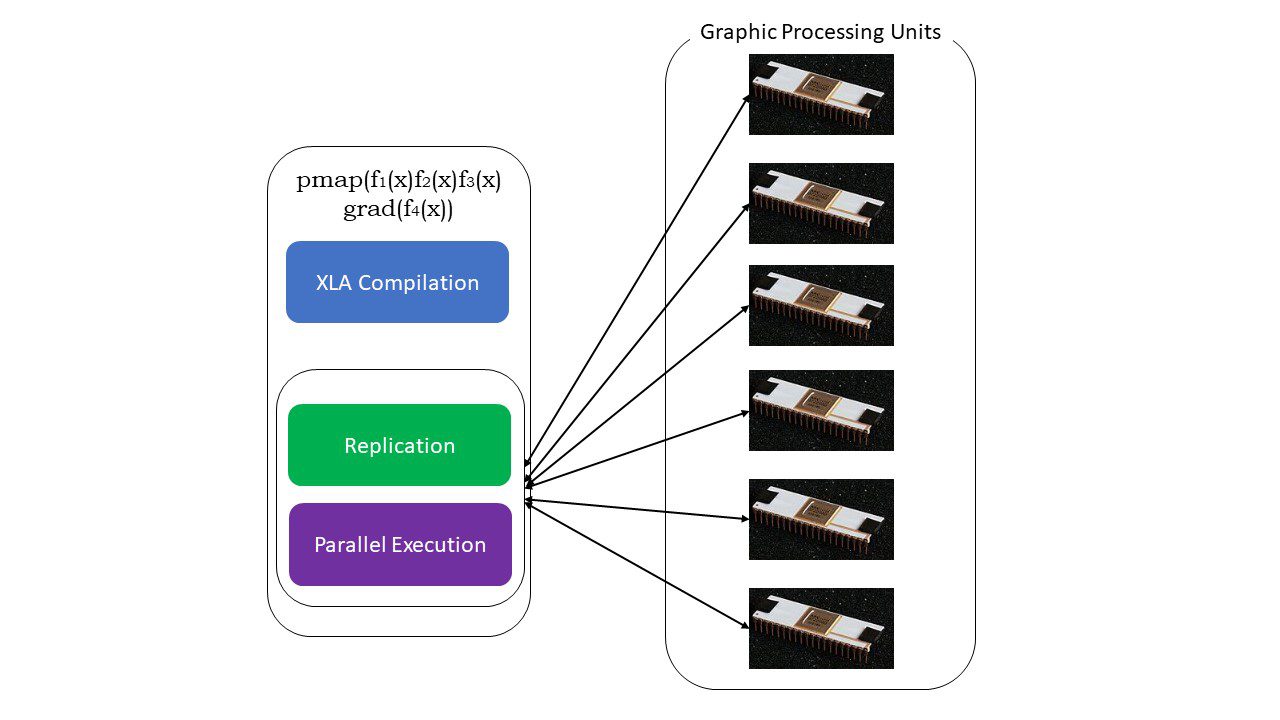 Como funciona o pmap
Como funciona o pmap
Também podemos aplicar várias transformações em qualquer ordem em qualquer função como:
pmap(vmap(jit(grad(f(x))))))
Múltiplas transformações compostas
Limitações do Google JAX
Os desenvolvedores do Google JAX se concentraram em acelerar os algoritmos de aprendizado profundo ao introduzir essas transformações. As funções e os pacotes de computação científica seguem o padrão do NumPy, o que facilita o aprendizado. No entanto, o JAX possui algumas limitações:
- O Google JAX ainda está em fase inicial de desenvolvimento e, embora o seu foco principal seja a otimização de desempenho, ele não oferece grandes benefícios para a computação em CPU. O NumPy parece ter um desempenho melhor e o uso do JAX pode apenas aumentar a sobrecarga.
- O JAX está em fase de pesquisa ou inicial e necessita de mais ajustes para atingir os padrões de infraestrutura de frameworks como o TensorFlow, que são mais estabelecidos e possuem mais modelos predefinidos, projetos de código aberto e material de aprendizado.
- Atualmente, o JAX não é compatível com o sistema operacional Windows. Para fazê-lo funcionar, você precisaria de uma máquina virtual.
- O JAX funciona apenas com funções puras, ou seja, aquelas que não têm efeitos colaterais. Para funções com efeitos colaterais, o JAX pode não ser uma boa opção.
Como instalar o JAX em seu ambiente Python
Se você tiver uma configuração Python em seu sistema e quiser executar o JAX em sua máquina local (CPU), utilize os seguintes comandos:
pip install --upgrade pip pip install --upgrade "jax[cpu]"
Se você deseja executar o Google JAX em uma GPU ou TPU, siga as instruções fornecidas na página do GitHub JAX. Para configurar o Python, visite a página oficial de downloads do Python.
Conclusão
O Google JAX é uma excelente ferramenta para desenvolver algoritmos eficientes de aprendizado profundo, robótica e pesquisa. Apesar de suas limitações, ele é amplamente utilizado em conjunto com outros frameworks, como Haiku e Flax. Você poderá perceber o poder do JAX ao executar programas e comparar os tempos de execução de código com e sem JAX. Você pode começar lendo a documentação oficial do Google JAX, que é bastante completa.