Este artigo aborda e detalha algumas das principais bibliotecas Python, essenciais para profissionais da área de ciência de dados e aprendizado de máquina.
A linguagem Python se destaca nesses dois campos, principalmente devido à variedade de bibliotecas que oferece.
Essa preferência se justifica pela capacidade das bibliotecas Python em realizar diversas tarefas, como entrada e saída de dados, análise aprofundada e outras operações de manipulação que são cruciais para a exploração e tratamento de dados.
O que são Bibliotecas Python?
Uma biblioteca Python representa um conjunto vasto de módulos, contendo código pré-compilado, incluindo classes e métodos. Isso elimina a necessidade de desenvolvedores escreverem códigos complexos do zero.
A Importância do Python em Ciência de Dados e Aprendizado de Máquina
Python oferece um arsenal de bibliotecas especialmente projetadas para atender às necessidades de especialistas em aprendizado de máquina e ciência de dados.
Sua sintaxe simples torna a implementação de algoritmos complexos mais eficiente, além de facilitar o aprendizado e a compreensão do código.
Além disso, Python é excelente para o desenvolvimento rápido de protótipos e para a realização de testes robustos de aplicações.
A vasta comunidade Python também é um grande trunfo, permitindo que cientistas de dados encontrem soluções para suas dúvidas e desafios.
Qual a Utilidade das Bibliotecas Python?
As bibliotecas Python são ferramentas indispensáveis para a criação de aplicações e modelos em aprendizado de máquina e ciência de dados.
Elas fomentam a reutilização de código, permitindo importar funcionalidades específicas para seu programa, sem precisar reinventar a roda.
Bibliotecas Python Essenciais em Aprendizado de Máquina e Ciência de Dados
Profissionais da área de ciência de dados recomendam várias bibliotecas Python, com as quais os entusiastas devem se familiarizar. A escolha da biblioteca ideal depende da sua aplicação, com diferentes opções para implantação de modelos, mineração e extração de dados, processamento de dados e visualização.
Este artigo apresenta algumas das bibliotecas Python mais usadas nas áreas de ciência de dados e aprendizado de máquina.
Vamos explorar essas ferramentas agora.
Numpy
A biblioteca Numpy, também conhecida como Numerical Python, é construída com código C otimizado. Cientistas de dados a utilizam amplamente por seus recursos de cálculos matemáticos e científicos avançados.
Características
- Numpy possui uma sintaxe de alto nível, tornando-a fácil de usar, mesmo para programadores experientes.
- Seu desempenho é elevado devido ao código C otimizado.
- Inclui ferramentas de computação numérica, como transformação de Fourier, álgebra linear e geradores de números aleatórios.
- É de código aberto, fomentando contribuições de inúmeros desenvolvedores.
Numpy também oferece recursos abrangentes como vetorização de operações matemáticas e indexação, além de conceitos-chave na implementação de arrays e matrizes.
Pandas
Pandas é uma biblioteca popular em aprendizado de máquina, que oferece estruturas de dados de alto nível e ferramentas para análise eficiente de grandes conjuntos de dados. Com poucos comandos, essa biblioteca traduz operações complexas de dados de maneira simplificada.
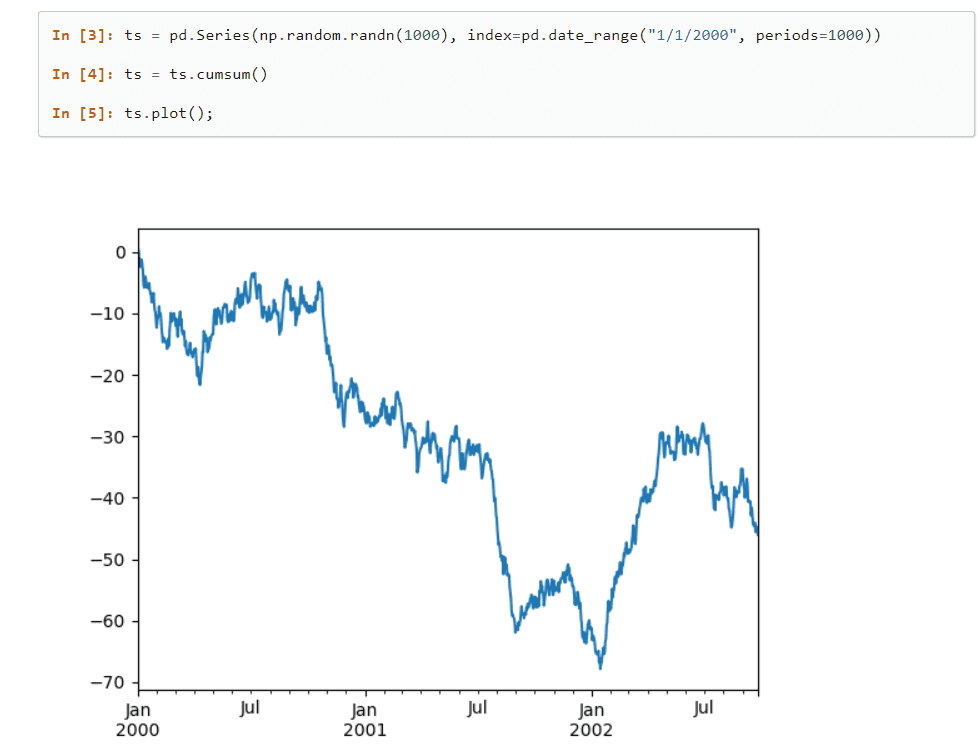
A biblioteca oferece métodos embutidos para agrupar, indexar, recuperar, dividir, reestruturar e filtrar dados, antes de inseri-los em tabelas únicas e multidimensionais.
Principais Recursos da Biblioteca Pandas
- Pandas facilita a rotulagem de dados em tabelas e alinha e indexa automaticamente os dados.
- Pode carregar e salvar formatos de dados como JSON e CSV rapidamente.
Pandas se destaca por sua eficiência em análise de dados e alta flexibilidade.
Matplotlib
Matplotlib é uma biblioteca gráfica 2D que permite manipular dados de diversas fontes. As visualizações criadas são estáticas, animadas e interativas, oferecendo ao usuário a possibilidade de zoom, o que é essencial para a criação de gráficos eficazes. Permite também a personalização de layouts e estilos visuais.
Sua documentação é de código aberto e oferece uma ampla gama de ferramentas necessárias para implementação.
Matplotlib importa classes auxiliares para implementar ano, mês, dia e semana, facilitando a manipulação de dados de séries temporais.
Scikit-learn
Se você busca uma biblioteca para auxiliar no trabalho com dados complexos, Scikit-learn é uma excelente escolha. Amplamente utilizada por especialistas em aprendizado de máquina, ela se integra com outras bibliotecas como NumPy, SciPy e Matplotlib. Scikit-learn oferece algoritmos de aprendizado supervisionado e não supervisionado que podem ser aplicados em produção.

Recursos da Biblioteca Python Scikit-learn
- Identificação de categorias de objetos, por exemplo, usando algoritmos como SVM e floresta aleatória em aplicações como reconhecimento de imagem.
- Previsão de atributos de valor contínuo associados a um objeto, uma tarefa conhecida como regressão.
- Extração de recursos.
- Redução de dimensionalidade, que consiste em diminuir o número de variáveis aleatórias consideradas.
- Agrupamento de objetos semelhantes em conjuntos.
Scikit-learn é eficiente na extração de recursos de conjuntos de dados de texto e imagem. Além disso, permite verificar a precisão de modelos supervisionados em dados não vistos. A grande variedade de algoritmos disponíveis facilita a mineração de dados e outras tarefas de aprendizado de máquina.
SciPy
SciPy (Scientific Python Code) é uma biblioteca de aprendizado de máquina que oferece módulos para funções matemáticas e algoritmos amplamente aplicáveis. Seus algoritmos são usados para resolver equações algébricas, interpolação, otimização, estatística e integração.
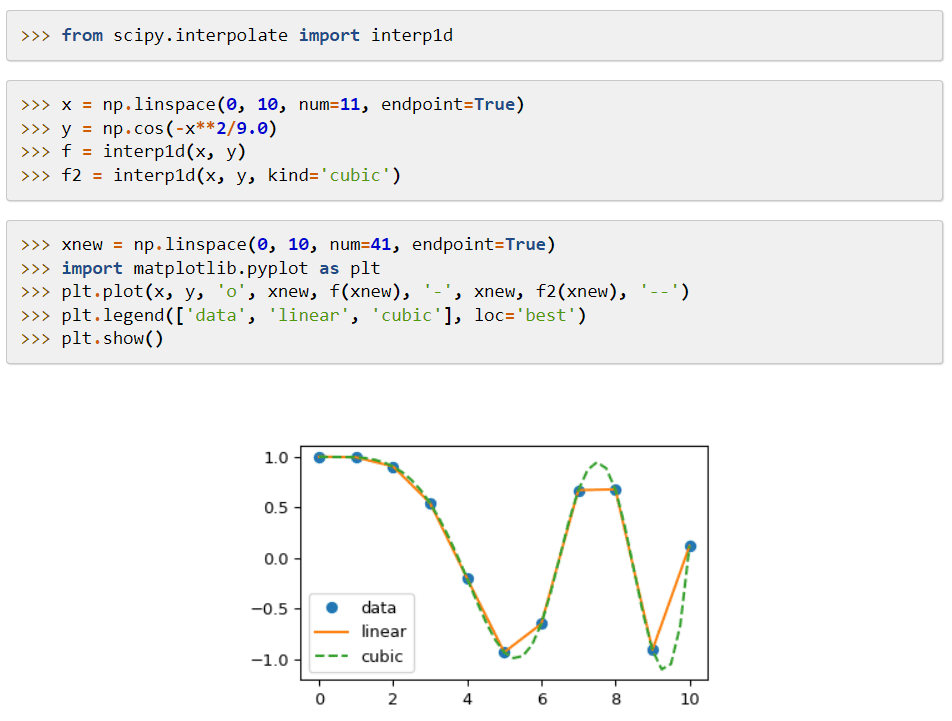
Sua principal característica é sua extensão ao NumPy, adicionando ferramentas para resolver funções matemáticas e fornecendo estruturas de dados como matrizes esparsas.
SciPy utiliza comandos e classes de alto nível para manipular e visualizar dados. Seus sistemas de prototipagem e processamento de dados o tornam uma ferramenta ainda mais eficaz.
Além disso, a sintaxe de alto nível do SciPy facilita o uso por programadores de todos os níveis de experiência.
A principal desvantagem do SciPy é seu foco exclusivo em objetos numéricos e algoritmos, sem oferecer funções de plotagem.
PyTorch
Esta biblioteca de aprendizado de máquina implementa cálculos de tensores com aceleração de GPU, cria gráficos computacionais dinâmicos e cálculos automáticos de gradientes. A biblioteca Torch, desenvolvida em C, serve como base para o PyTorch.

Principais Recursos:
- Desenvolvimento suave e dimensionamento flexível devido ao suporte nas principais plataformas de nuvem.
- Um ecossistema robusto de ferramentas e bibliotecas apoia o desenvolvimento de visão computacional e áreas como Processamento de Linguagem Natural (NLP).
- Transição entre modos ansioso e gráfico usando Torch Script, além do TorchServe para acelerar a produção.
- O backend distribuído do Torch permite treinamento distribuído e otimização de desempenho em pesquisa e produção.
PyTorch pode ser usado no desenvolvimento de aplicativos de PNL.
Keras
Keras é uma biblioteca de aprendizado de máquina de código aberto usada para experimentar redes neurais profundas.
É conhecida por oferecer utilitários para compilação de modelos e visualização de gráficos, entre outras funcionalidades. Utiliza o Tensorflow como backend, mas também permite usar Theano ou redes neurais como CNTK. Essa infraestrutura de backend auxilia na criação de gráficos computacionais usados para implementar operações.
Principais Características da Biblioteca
- Pode ser executado eficientemente tanto na Unidade Central de Processamento quanto na Unidade de Processamento Gráfico.
- A depuração é mais fácil com Keras, pois é baseada em Python.
- Keras é modular, expressivo e adaptável.
- Pode ser implementado em qualquer lugar, exportando diretamente seus módulos para JavaScript para execução no navegador.
As aplicações de Keras incluem blocos de construção de redes neurais, como camadas e objetivos, entre outras ferramentas que facilitam o trabalho com imagens e dados de texto.
Seaborn
Seaborn é uma ferramenta valiosa na visualização de dados estatísticos.
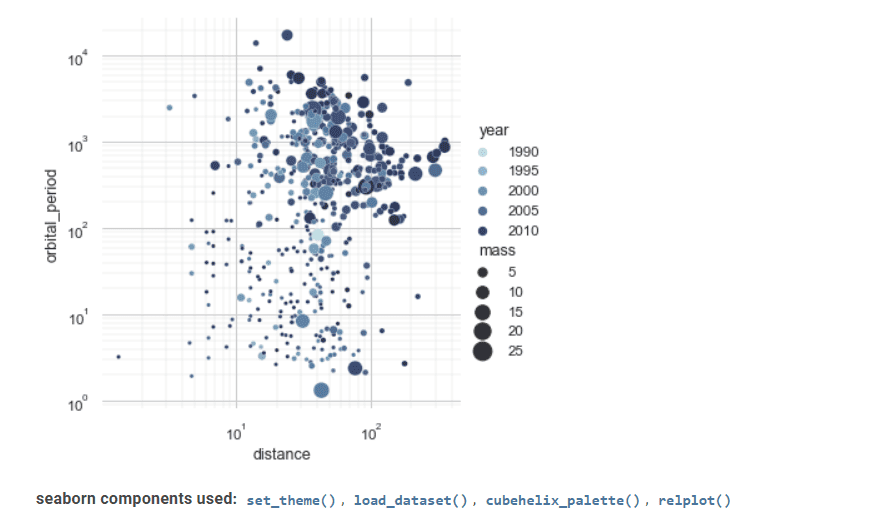
Sua interface avançada implementa gráficos estatísticos atraentes e informativos.
Plotly
Plotly é uma ferramenta de visualização 3D baseada na web, construída sobre a biblioteca Plotly JS. Possui suporte para vários tipos de gráficos, como gráficos de linhas, gráficos de dispersão e mini gráficos de tipos de caixa.
Sua aplicação inclui a criação de visualizações de dados baseadas na web em notebooks Jupyter.
Plotly é adequado para visualização, pois pode identificar valores discrepantes ou anormalidades no gráfico com sua ferramenta de foco. Permite também personalizar os gráficos de acordo com suas preferências.
A documentação do Plotly pode ser desatualizada, tornando o uso como guia um desafio para o usuário. Além disso, possui muitas ferramentas, o que pode dificultar o controle de todas elas.
Recursos da Biblioteca Plotly Python
- Os gráficos 3D disponíveis permitem vários pontos de interação.
- Tem uma sintaxe simplificada.
- É possível manter a privacidade do código enquanto se compartilham seus pontos.
Simple ITK
SimpleITK é uma biblioteca de análise de imagens que oferece uma interface para o Insight Toolkit (ITK). É baseado em C++ e é de código aberto.
Recursos da Biblioteca SimpleITK
- Seu sistema de entrada e saída de arquivos de imagem suporta e converte até 20 formatos de arquivos de imagem, como JPG, PNG e DICOM.
- Oferece filtros para fluxos de trabalho de segmentação de imagens, incluindo Otsu, conjuntos de níveis e bacias hidrográficas.
- Interpreta imagens como objetos espaciais, em vez de matrizes de pixels.
Sua interface simplificada está disponível em várias linguagens de programação, como R, C#, C++, Java e Python.
Statsmodel
Statsmodel estima modelos estatísticos, implementa testes estatísticos e explora dados estatísticos usando classes e funções.
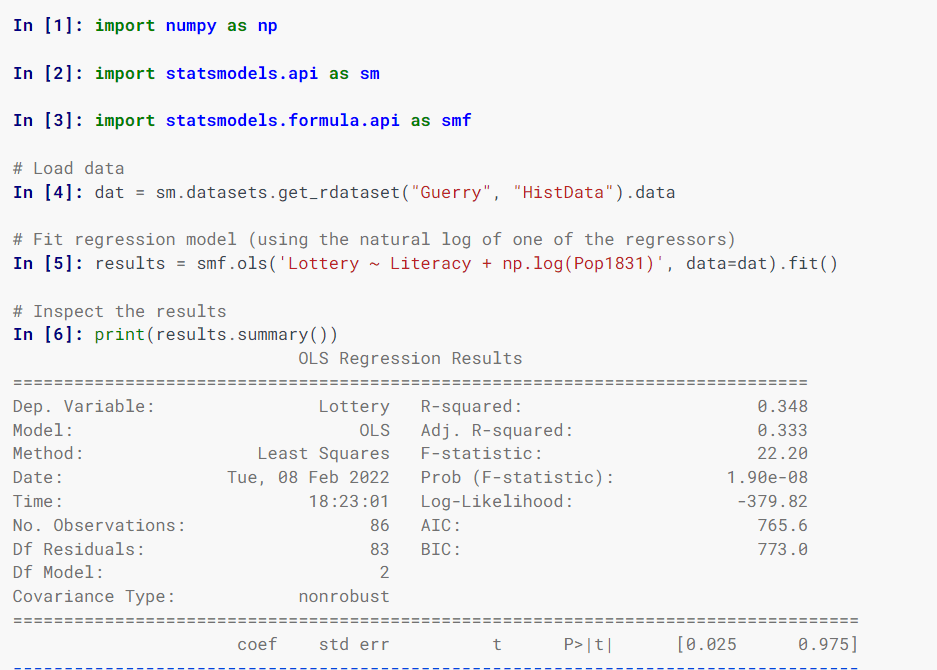
A especificação de modelos usa fórmulas no estilo R, matrizes NumPy e quadros de dados Pandas.
Scrapy
Este pacote de código aberto é uma ferramenta para recuperar (scraping) e rastrear dados de um site. É assíncrono e, portanto, relativamente rápido. Scrapy possui arquitetura e recursos que o tornam eficiente.
No entanto, sua instalação varia para diferentes sistemas operacionais. Além disso, não pode ser utilizado em sites construídos em JS, e só funciona com Python 2.7 ou versões posteriores.
Especialistas em ciência de dados o aplicam em mineração de dados e testes automatizados.
Características
- Pode exportar feeds em JSON, CSV e XML e armazená-los em vários back-ends.
- Possui funcionalidade integrada para coletar e extrair dados de fontes HTML/XML.
- Uma API bem definida permite estender o Scrapy.
Pillow
Pillow é uma biblioteca Python de imagens que manipula e processa imagens.
Expande os recursos de processamento de imagem do interpretador Python, suporta vários formatos de arquivo e oferece uma representação interna eficiente.
Os dados armazenados em formatos de arquivo básicos são facilmente acessíveis graças ao Pillow.
Concluindo
Este artigo abordou algumas das principais bibliotecas Python para cientistas de dados e especialistas em aprendizado de máquina.
Python oferece uma variedade de pacotes úteis para aprendizado de máquina e ciência de dados, além de outras bibliotecas que podem ser aplicadas em outras áreas.
Você pode se interessar por conhecer alguns dos melhores notebooks para ciência de dados.
Bons estudos!